基于风电场SCADA系统的云平台设计
2019-11-16梁涛李燕超许琰杨改文
梁涛 李燕超 许琰 杨改文

摘要:为充分利用风电场集控中心采集爆炸式增长的海量数据,解决风电场SCADA系统数据存储和处理能力不足的问题,设计基于SCADA系统的云计算平台,实现数据的高效分布式存储以及处理。传统LS-SVM适用于小样本数据,对风电场海量数据的处理比较乏力,针对此问题,采用MapReduce云计算平台实现算法并行化,并用遗传算法对其进行参数寻优。最后利用某实际风电场SCADA系统的历史数据,实现短期风功率预测功能。在数据不断增加的情况下,采用MapReduce云计算平台实现LS-SVM算法并行化训练比单机LS-SVM训练缩短的时间十分显著,可增强SCADA系统的实时性;当数据增加到1.2 GB时,时间缩短一半,而准确度相差0.1%。
关键词:SCADA;云计算LS-SVM;并行;风功率预测;遗传算法
中图分类号:TP277 文献标志码:A 文章编号:1674-5124(2019)10-0114-06
收稿日期:2018-08-31;收到修改稿日期:2018-10-09
基金项目:河北省科技计划项目(16214510D)
作者简介:梁涛(1975-),男,河北石家庄市人,教授,研究方向为风力发电、大数据、人工智能、自动控制。
0 引言
随着风电场数据爆炸式的增长,传统的风电场SCADA系统数据存储和串行处理能力不足的问题日益凸显,如何高效处理复杂且异构的风电大数据,挖掘隐藏在风电大数据背后的价值,是传统的风电场SCADA系统面临的巨大挑战。在数字信息化时代的推动下,云计算技术应运而生,为风电大数据的处理带来了曙光。文献[1]设计了一个基于云平台大数据的风电集中控制系统,实现了实时数据的采集和上传,但没有做进一步的数据挖掘。Lee等[2]提出一种基于SVM的检测模型来寻找T型整流器开路故障的位置。SVM可以用来解决两类(正常或异常)和多类问题。Zhang等[3]提出了一种基于光伏发电数据和部分气象数据预测天气类型的新方法,通过数据分析推导出天气类型。Rahulamathavan等[4]指出SVM在许多实际应用中具有强大的数学基础和高度的可靠性。然而,传统的SVM模型有着高时间成本消耗。
近几年来,Hadoop分布式云计算平台不断发展,传统算法的性能问题可以通过用多个计算节点进行并行计算来解决。杨博等[5]在大数据环境下对支持向量机进行并行化,指出了支持向量机的理论研究方向与背景,并没有实际的验证。陈珍等[6]提出了一种基于MapReduce的SVM(MR-SVM)态势评估方法,实验结果表明并行化后的SVM更适用于大数据态势评估,但是并没有对SVM参数进行寻优。Zhang PeiYun等[7]提出了一种基于支持向量机(SVM)的SVM-Grid系统参数搜索方法在线检测模型,并提出了预测云故障和更新故障样本数据库的策略,以优化模型并提高其性能。本文将风电场集中控制中心与云计算平台相结合,解决传统风电场SCADA系统数据存储成本昂贵、数据处理能力不足等缺点,同时完成风电场SCADA系统大数据的回归,以及优化短期风功率预测功能,并验证并行化LS-SVM的优越性。
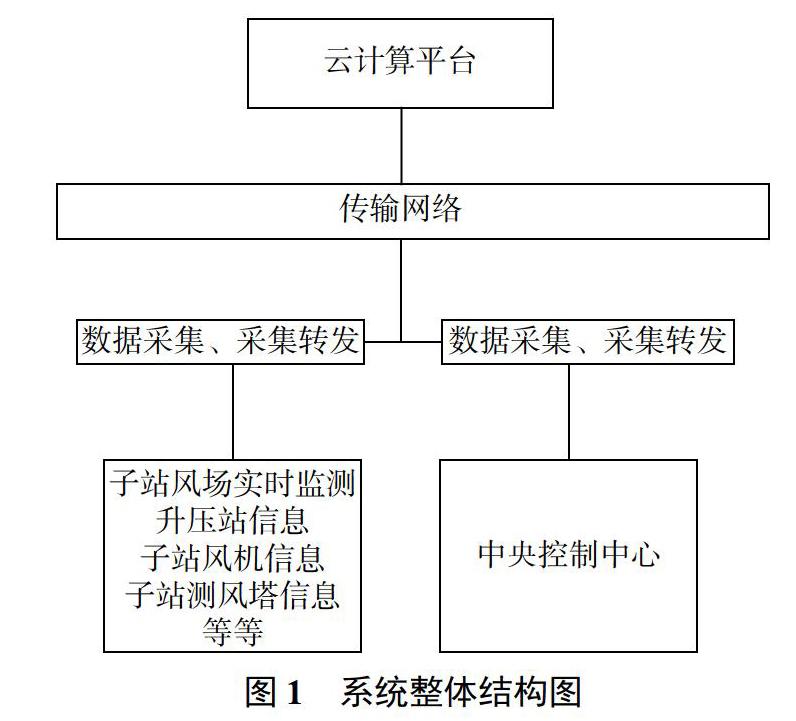
1 系统整体结构
此系统结构图如图1所示。如图所示,该架构分为3个部分:每个风电场侧,中央控制中心侧和云计算平台侧。它们相互之间通过电力调度专网来进行通信。
风电场侧的设计应做到采集不同厂家不同设备设施的信息数据,同时能够进行各种通信协议的自由转换,为集控中心的统一监控、统一调度和分析评测奠定基础。
风电场侧包括以下功能:
1)风机实时运行数据采集与控制(安全Ⅰ区);
2)升压站实时运行数据采集与控制(安全Ⅰ区);
3)功率控制系统(AGC/AVC)数据采集与控制(安全Ⅰ区):
4)风功率(wind power)预测系統数据采集(安全Ⅱ区区);
5)保护及故障信息子站数据采集(安全Ⅱ区区);
6)电能量计量信息采集(安全Ⅱ区区)。
集控中心主站能够读取各个风电场风机监控系统、电站综合自动化系统、功率预测系统、风机振动监视系统等系统所有数据、画面、图形。工作人员可以在集中监控和调度集中控制中心内所有风电场的设备和设施。
在安全Ⅰ、Ⅱ区区主要实现的监控功能:
I)状态监测功能;
2)可定制数据展现功能;
3)生产运行及设备故障实时报警功能;
4)统计分析与专家诊断功能;
5)关键仪表盘功能:显示相关指标,如发电、风机故障、风机可利用率。
在安全Ⅲ区区主要实现的各关键指标图表功能:
1)生产运行类指标:有效风速小时、平均空气密度、发电量、并网电量、等效利用小时数、输电线路损耗率、风机计划停电系数、运行系数、计划外风机中断因子、暴露率等;
2)可利用率性能类指标:风机设备可用性、风电场可用性、机组运行和维护成本、故障报警日志可用性、运行时可用性、风能利用率等;
3)故障统计类指标:平均拆卸间隔时间、设备故障停机率、致命故障、主变压器故障率、风机维修总时间、无功调节设备故障率、平均故障间隔时间、故障发电损失量、平均无故障间隔时间、平均修复时间等任务时间。
本文设计的云计算平台可以在廉价的计算机集群上存储和处理PB级数据,处理后的数据结果传给集中控制中心,以便于集中控值中心的工作人员做出决策。
2 云计算平台
基于以上架构,在Ⅲ区搭建云平台,内部结构如图2所示。搭建云平台需要两个主要部分:ONE套的云基础设备;2)底层的数据采集。云计算平台是一个大数据处理平台,采用Hadoop+MapReduce的分布式数据处理技术[4,8]。与传统的数据处理方式相比,该平台基于灵活多变的开源框架,根据需要随时改变组件,且支持水平扩展,具有互联网属性、更加开放安全等明显优势。
2.1 分布式文件系统(HDFS)
HDFS为Hadoop云计算平台提供了一个可靠、安全、高可用的分布式文件系统,是分布式计算的基础。HDFS以流数据访问模式存储非常大的文件,并不需要在昂贵且高可靠的硬件上运行。HDFS采用主从架构,以管理节点-工作节点模式运行,即NameNode(管理节点)和多个DataNode(工作节点)。NameNode管理文件系统的命名空间,它维护文件系统树以及整个树中的所有文件和目录,此信息将作为两个文件永久保存在本地磁盘L。DataNode是文件系统的工作节点,它们定期将它们存储的块列表发送到NameNode。
在图3中,客户端必须经过NameNode的确认才能访问文件系统,在已获得相关信息情况下,才能够对整个文件系统进行读写,可以说NameNode是整个文件系统的人口。
2.2 分布式计算框架(MapReduce)
MapReduce由Java开发,是一个用于处理大量数据的分布式并行编程模型。它将数据的计算过程划为mapper()函数和reduce()函数实现。每个阶段都将键值对作为输入和输出。第一阶段(Map阶段):将输入的数据平均划分成大小相等的切片,并将每个切片分解成键值对的形式作为正式输入,执行mapper()函数生成中间结果;然后按照k2的值排序,将具有相同k2值的相应的v2值组合在一起以形成新列
第二阶段(Reduce阶段):对Map任务的输出整合排序,将输出到Hadoop的HDFS上。
2.3 云计算平台数据处理
云计算平台的核心是数据处理,Hado即是与云计算平台最契合的分布式并行的运行架构,支持各种数据算法[9]。风电场云计算平台是以风电大数据为输入,按照算法给定的规则进行处理,并输出对应的结果。
本文采用支持向量机(SVM),可以实现风电场SCADA系统大数据的回归分析,根据预测模型的预测值,既可以对风机未来一段时间内运行趋势进行预测,还可以基于实际值和预测值的偏差,来预测故障的发生。
核函数是支持向量机和关键组成模块的核心,可以有效地解决系统非线性问题,解决维数灾难。由Hilbert-Schmidt理论得知,只要某个对称函数满足Mercer条件都可以被定义为核函数。建立回归模型时核函数有很多种,模型选择不同的核函数会对结果的精度以及泛化性产生不同影响。例如:径向基函数:
径向基核函数的表达式如下
其构造的SVM的判别函数表达式如下
除此之外,核函数还有Sigmoid函数、小波核函数、线性核函数等等。在这些函数中,径向基核函数的结构简单,泛化能力好适用于解析复杂模型的高度非线性关系,基于此,本文采用径向基核函数。
3 基于遗传算法的LS-SVM核函数参数的选择
最小二乘支持向量机(LS-SVM)是一种特殊的核函数学习机,遵循结构风险最小化(SRM)原则。该算法不仅可以简化求解过程,而且可以提高求解收敛速度[10]。本文核函数选择径向基函数,LS-SVM主要有两个参数,一个是惩罚因子,另一个是径向基函数参数,这两个参数直接影响到支持向量机的训练结果。
遗传算法是基于达尔文生物进化论的自然选择和遗传学机理提出的一种寻求最优解的算法[11]。其主要过程是将解决问题的解(称为“染色体”)进行编码,常见个体的编码方式有两种,它们分别是二进制编码和实数编码,其基本就是把解空间映射到染色体空间。随后在这些解空间中产生合理的初始种群,根据适应度函数以及遗传中的选择、交叉和变异的操作对个体进行选择。保留适应度值高的个体。这样新产生的后代之中保留了上一代优点,且又有了上一代没有的优点,多次迭代,直至得到最优解。
3.1 基于MapReduce并行LS-SVM算法
训练集被分成子集并分发到每个节点用于训练以获得相应的子支持向量。第一阶段(Map阶段):将每个计算节点的子训练集合与全局支持向量進行合并,然后通过遗传算法训练和测试统一的数据集,以选取最优参数与惩罚因子。第二阶段(Reduce阶段):每个计算节点使用由第一阶段获得的参数对(C,gama)来训练数据集以获得每个节点子支持向量。然后合并每个节点的新子支持向量与全局支持向量,以产生新的全局支持向量。当全局支持向量满足多次迭代后的条件时,循环结束,表示已获得最优的回归函数,具体流程如图4所示。其中,S表示全局支持的变量,S1表示每个节点中训练数据集的子集。
4 实验及结果分析
为验证本文提出的并行LS-SVM算法的性能,本文在Hadoop 2.0平台下对风电场数据集处理效果进行了测试。
在某风电场集控中心搭建的Hadoop 2.0云计算平台由7台华为的服务器组成,是由1个主节点和6个从节点组成的主从结构。每个节点服务器的标准配置是Intel(R)Xeon(R)CPU E5-2630 v4@2.20GHz 2.19GHz(2处理器),32GB,网络速率为100Mb/s。本文选择的Linux版本为CentOS 6.5,Hadoop版本为Hadoop 2.0。
实验搭建的Hadoop 2.0云计算平台如图5所示,主节点用于完全分布式系统元数据的管理与调度任务,从节点用于完全分布式系统的数据存储和计算。
选取经过清洗之后的风电场SCADA系统历史数据库中的风速、有功功率和转子转速,通过LS-SVM回归算法的设计,建立风电场SCADA大数据的回归预测模型,落实短期风力预测功能。风电场SCADA大数据的回归结果如图6和图7所示。
如图可知,蓝色点分别表示风电机组实际运行的风速一有功功率和风速一转子转速的散点图,红色曲线表示经LS-SVM回归算法处理获得散点图拟合曲线,实现了云计算平台中风电场SCADA大数据回归预测模型的建立。通过拟合的曲线,不仅可以预测未来一段时间内风力发电机组的运行情况,而且若某一时刻有功功率和转子转速的实际运行值与拟合曲线的值有较大偏差,说明此时风力发电机组可能发生了故障,需要值班人员进行预检修等。这为机组维护人员提供了技术支持,保证了风电场正常安全的运行。
基于上述风速一有功功率的回归预测模型,进行短期风力预测,得到实际运行风电场3d的有功功率预测结果,如图8所示。
由预测曲线可知,预测值和实际值相差不大,表明数据清洗之后的回归预测模型可以实现短期风功率的预测。
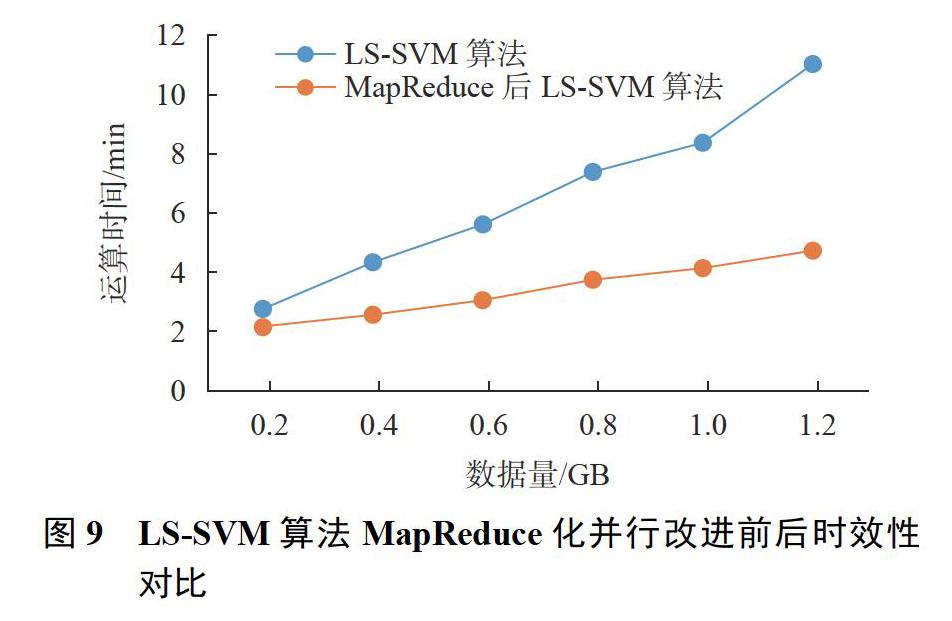
1)时效性
为了进一步验证该平台的优越性,本文使用建立的6个有效节点,在不断增加数据集的情况下,比较了MapReduce并行改进前后的LS-SVM算法的时效性,如图9所示。
由图可知,LS-SVM算法MapReduce化并行改进前后在不同数据集上的运算时间是不同的,在数据量比较小的情况下运算时间差距不大,但是随着数据量的增加MapReduce并行化改进的算法明显缩短了运算时间,并且随着数据集的越来越多,MapReduce并行化改进LS-SVM算法在回归分析的时效性方面变得越来越有优势。
2)正确率
正确率(accuracy)表达式如下式所示:
accuracy=(TP+TN)/(P+N)(3)
正确率测试的目的是比较LS-SVM算法MapReduce化并行改进前后回归结果的精确度,选用风电场SCADA系统历史数据库100MB、200MB、500MB和1GB数据作为测试数据集,回归结果的正确率对比如图10所示。
通过上图回归结果可以看出,随着测试数据量的增加,LS-SVM算法的回归的正确率都逐步上升,说明了数据量越大,容错能力越强。虽然MapReduce化并行改进后LS-SVM算法与LS-SVM算法相比回歸正确率变化不大,但是MapReduce化并行改进后LS-SVM算法的时效性增强,相同时间下可以运算更多的数据,间接提高了回归结果的正确率。
5 结束语
本文设计了一个基于风电场SCADA系统的云计算平台,实现数据的高效存储,利用云计算平台的架构实现了短期风功率预测功能。利用MapReduce结构实现了算法的并行化,通过设计主要的Map函数和Reduce函数,并结合遗传算法,在保证正确率的前提下,显著地缩短了算法的训练时间。
参考文献
[1]丛智慧.基于云平台大数据技术的风电集控系统的设计与应用[J].内蒙古科技与经济,2016(19):61-63.
[2]LEE J S,LEE K B.An open-switch fault detection methodand tolerance controls based on SVM in a grid-connected T-type rectifier with unity power factor[J].IEEE Trans.Ind.Electron.,2014,61(12):7092-7104.
[3]ZHANG W Y,ZHANG H G,LIU J H,et al.Weatherprediction with multiclass support vector machines in the faultdetection of photovoltaic system[J].IEEE/CAA J.Autom.Sinica,2017,4(3):520-525.
[4]RAHULAMATHAVAN Y,PHAN R C W,VELURU S,et al.Privacy-preserving multi-class support vector machine foroutsourcing the data classification in cloud[J].IEEETrans.Dependable Secure Comput,2014,11(5):467-479.
[5]杨博,黄斌.大数据环境下的支持向量机算法研究[J].信息化建设,2016(3):349.
[6]陈珍,夏靖波,杨娟,等.基于MapReduce的支持向量机态势评估算法[J].计算机应用,2016,36(1):133-137.
[7]ZHSANG P Y,SHU S,ZHOU M C.An online fault detectionmodel and strategies based on SVM-grid in clouds[J].IEEE/CAA Journal of Automatica Sinica,2018,5(2):445-456.
[8]崔红艳,曹建芳,史昊.一种基于MapReduce的并行PSO-BP神经网络算法[J].科技通报,2017,33(4):110-115.
[9]罗贤缙,岳黎明,甄成刚.风电场数据中心Hadoop云平台作业调度算法研究[J].计算机工程与应用,2015,51(15):266-270.
[10]马跃峰,梁循,周小平.一种基于全局代表点的快速最小二乘支持向量机稀疏化算法[J].自动化学报,2017,43(1):132-141.
[11]HONG Y Y,CHEN Y Y.Placement of power qualitymonitors using enhanced genetic algorithm and wavelettransform[J].IET Generation,Transmission&Distribution,2011,5(4):461-466.
(编辑:刘杨)
