标记的表格对象分为带有知识的表格,和用于页面布局或导航的非知识表格,互联网中88%的HTML表不含有知识。借鉴互联网表格分类工作中的方法[12,13],我们使用梯度提升树模型GBDT,作为非知识表过滤器。(3)表格解析:将HTML格式的表格解析为csv格式,在内存中以二维数组的形式表示。同时在另外的数组中存储了单元格中的属性,如span和href。我们把带span属性,跨行跨列的单元格拆分。对于带href属性的单元格,我们使用其所指页面的标题作为链接实体。
(4)知识表类型识别:关系表和键值对的识别,采用了我们提出的基于模式特征在线更新的识别器训练算法,在识别的过程中,在线更新特征值,重新训练识别器。枚举列表的识别采取基于概念(分类)树辅助的启发式方法。
(5)关系表与知识库匹配:我们使用T2K[11]算法对关系表进行实体链接和属性对齐。此外,加入了我们提出的表格聚类算法,以及使用我们提出的“公共上位概念”进行候选集生成。
(6)三元组抽取:根据表1给出的三种表格的定义,按照相应的规则抽取知识。对于键值对表,所在百科页面的标题就是每个三元组的主语,表中每一行的键值对就是三元组的谓语和宾语。对于关系表,表格实体以行为单位,所链接的实体是每个三元组的主语,除主键所在列外每一列对齐到的属性是谓语,属性值是宾语。对于枚举列表,百科页面的标题就是每个三元组的主体,而表格中的每个实体名称则是每个关系三元组的宾语(尾实体),尾实体链接采用与关系表实体链接相同的方法。谓语通过每个实体对在知识库中存在謂语的数量投票决定。
(7)融合模型:采用我们提出的针对百科表格数据集的融合策略。
4 关键技术分析(Key technical analysis)
在这一节,我们介绍了框架中三个关键技术的细节,它们是(1)知识表类型识别;(2)关系表与知识库匹配;(3)融合模型。
4.1 知识表类型识别
这一节中我们提出了识别三种表格类型的方法。表格中有两种类型的信息,属性信息和属性值信息。如果已知一些表格属性,那么我们可以利用它来识别表格的结构,从而能够帮助我们把属性对应到正确的属性值单元。由于表格是半结构化的数据,它的属性通常连续地出现在一整行或一整列。定位表格的属性会帮助我们识别表格正确的结构。对于键值对表和关系表,我们发现,表格属性与知识库中的属性有相同处,并且表格属性集合与由知识库属性构成的模式库存在交集。对此,我们将表格属性属于模式库的比例和个数作为模式得分特征,为键值对表和关系表分别训练了一个单层决策树,作为初始的表格识别器。在使用表格识别器识别表格后,将会含有一些不属于模式库的属性出现在表格中,但这些属性可能是其他表格的属性。于是,我们使用这些属性扩充模式库。模式库扩充后,训练集中表格的模式得分特征可能发生变化,需要更新,进而分类器模型又需要重新训练。如此往复,这是一个迭代的过程。如算法1所示,我们提出了基于特征在线更新的表格识别器训练算法。
算法1基于模式特征在线更新的识别器训练
输入:模式库predictkg,知识表模式集合Predicttable,单层决策树DStump
输出:单层决策树DStump,扩充后的模式库predictkg
1.next_iteration=False
2.for predicttable in Predicttable? do
3. computer Scoretable
4. if DStump(Scoretable) is True then
5. if then
6.
7. next_iteration=True
8. end if
9. end if
10.end for
11.if next_iteration is True then
12. update training set with new Scoretable and resume the training
13. if DStump performs better in testing set then
14. repeat 1 to 10
15 end if
16.else return DStump and predictkg
17.end if
在算法1的输入中,模式库初始化为知识库中属性的集合;每个知识表的模式按行或按列获得(以属性表为例,它的模式由第一列中的每个属性构成);识别器采用单层决策树模型,使用初始的得分特征进行训练。算法1的第3行计算了表格的两个模式得分,一个是属性属于模式库的比例,即,另一个是属性属于模式库的个数。算法的第2行到第10行,计算每个未识别知识表的模式得分,如果有新的表被识别,则扩充模式库。每经过一轮迭代,都会重新训练一次识别器,原来的假负例在模式得分提高后会被识别为真正例,识别器的召回率会得到提升。当经过若干轮迭代后,模式库属性数量不再增加或识别器F1值不再提高时,我们将识别器和模式库返回。另外,可以在使用算法1完成弱学习器的训练后引入剩下的表格特征(如布局特征和内容特征),通过boosting的方式训练一个更强的识别器。考虑到需要多次重复训练,于是我们选择单层决策树这样一个弱学习器作为识别模型,并且不引入其他特征。
在剩下未识别的知识表中,我们使用强规则识别枚举列表。我们把表格中每个单元格的内容假设为实体名称,通过知识库查找该实体名称对应的实体(实体和实体别称满足多对多的关系),若每个实体别称都能映射到至少一个实体,则启发性地认为该表格为枚举列表。
4.2 关系表与知识库匹配
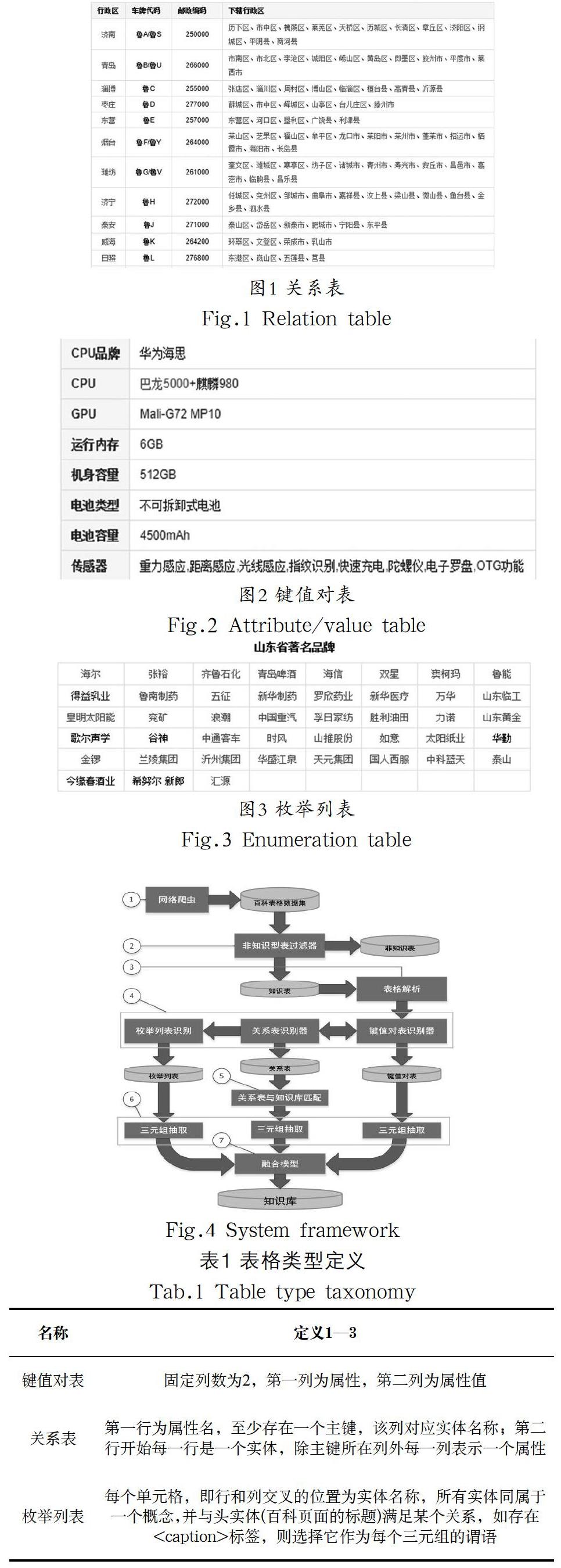
这一节,在T2K算法框架[11]中加入我们提出的基于概念(本体)树的表格聚类和基于公共上位概念的候选集生成方法。
4.2.1 T2K匹配框架
T2K算法框架将每个关系表视为一个小型关系型数据库,将关系表中的实体、属性和概念与知识库匹配。图5描述了T2K算法框架的主要步骤。它首先从知识库中获得候选实体,通过基于属性值的匹配得到候选实体的实体链接得分。然后以列为单位,选择属性值相似度的和最高的属性作为属性相似度,并计算这个属性对应的每个概念的得分,用得分最高的概念过滤候选实体。在过滤掉一些实体后,属性相似度发生了变化,需要重新选择,这是一个迭代的过程。T2K算法的先进之处在于,不同于传统数据库模式匹配,它在匹配过程中加入了概念(本体)的匹配,而概念(本体)是实体和属性的迭代匹配的桥梁。
4.2.2 基于概念的表格聚类
根据HTML表格与知识库匹配的经验,表格中实体数量越大,它们与知识库匹配的效果越理想。于是,在T2K框架的基础上将关系表内容整合。表格内容整合分为表格聚类和表格合并两个部分,前者采取了我们提出的算法2的方式,后者则是利用表格聚类的结果,将同类表格中相似属性合并到同一表格。这一节重点介绍了我们提出的基于概念的表格聚类算法。
此聚類算法以表格实体所属概念为特征,首先将每个表格表示为一个向量,其中j是知识库中概念的数量。每一个维度对应的计算公式为:,其中,Ti.E表示表格Ti的实体名集合,I(Cj)表示知识图谱中概念Cj的实体名集合。接着,我们计算表格向量间的余弦相似度,然后采用如算法2所示的方法将表格聚类。
算法2基于概念(本体)树的表格聚类
输入:表格集合Table,相似度阈值threshold
输出:聚类簇C
1.Initialize clusters C=
2.for table in Table do
3. get vector Ti for table
4. initialize flag f=False
5. for cluster c in C do
6. get vector Tc of the first table in c
7. if then
8. add table to c
9. f=True
10. break
11. end if
12. end for
13. if f=False then
14. initialize new cluster c={table}
15. add c to C
16. end if
17.end for
18.return C
可见,算法2是一种简单且有效的聚类算法,它的时间复杂度为O(m×n),其中n是表格的总数,m是聚类簇的数目,它远小于n。
4.2.3 基于公共上位概念的候选集生成
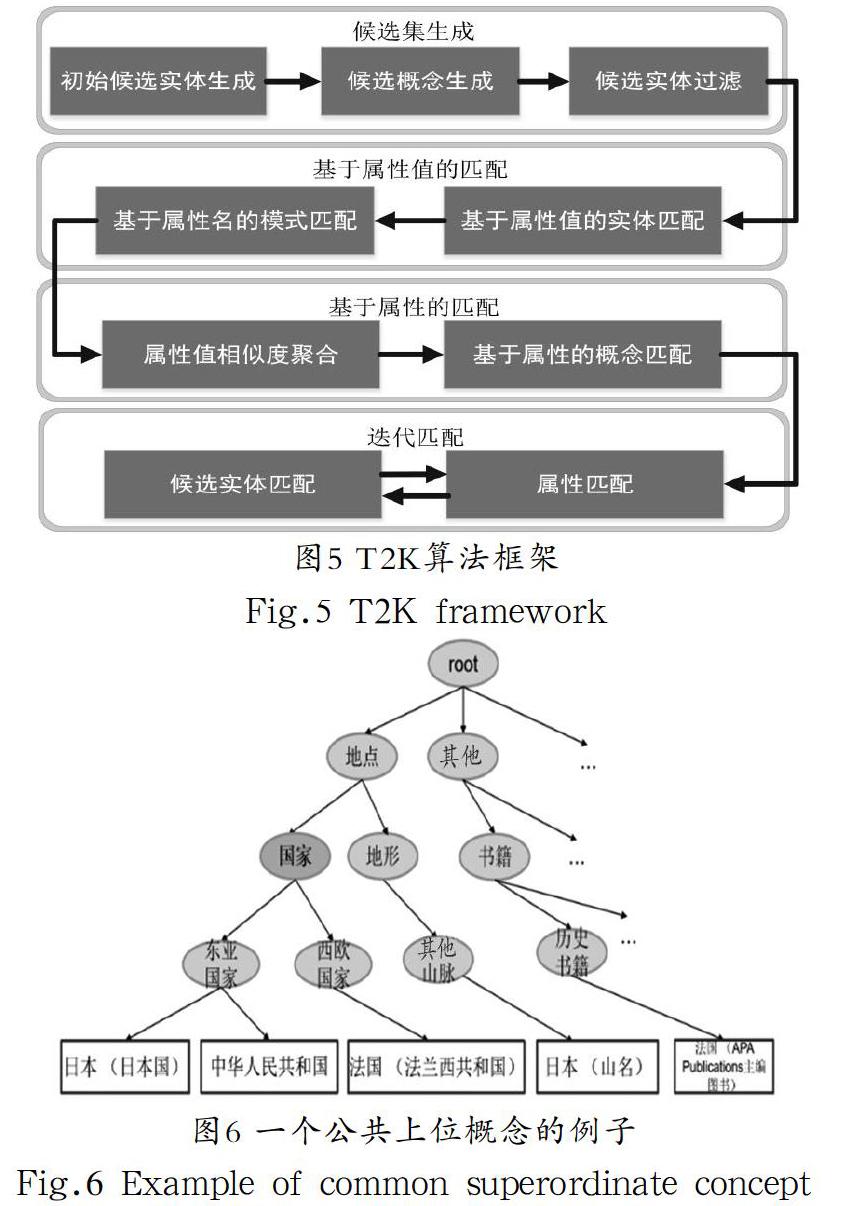
T2K[11]算法在候选集生成中,首先通过计算表格实体名与知识库实体名的相似度为每个实体生成top k个候选实体;然后为每个实体选择所属频率最高的概念,过滤不属于这些概念的初始候选实体。根据百科表格数据知识分布的特点,系统偏向于扩充长尾概念下的知识,使用高频概念不能有效地过滤初始候选实体。于是,我们提出了使用“公共上位概念”过滤初始候选实体的方法。
定義4(公共上位概念Cp)在概念树T中,如存在一个概念,其子概念构成的集合Cp.children与由每个候选实体集合Ei对应的概念集合Ci构成的集合Ciset都存在交集,我们把这个概念称为公共上位概念Cp,形式化为下列公式:
以图6为例,表格中存在中国、法国、日本三个实体名称,它们的候选实体集Ei分别为:{中华人民共和国}{法国(法兰西共和国),法国(APA publications主编图书)}和{日本(日本国),日本(山名)},对应的概念集合Ci分别为分别为{东亚国家}{其他山脉,东亚国家}和{西欧国家,历史书籍},则“国家”是这三个实体的公共上位概念Cp。而地形概念下的实体数量更多,它更可能成为高频概念。技术上,我们采用回溯算法遍历概念树得到Cp,过滤掉不属于Cp的候选实体。
4.3 融合模型
由于互联网资源可信度较低,以往的工作在融合策略上采用了基于知识库[21]或者网页排名的先验信任机制。而百科表格中的知识按领域分布均匀,属于长尾的较多,如果直接使用先验信任机制,那么这些长尾知识(知识库中的孤立节点)都不能被融合。考虑到百科资源具有很高的可信度,我们不需要采用先验信任机制,而应该以抽取器的准确率为指标,即识别器得分和实体链接相似度得分。我们将表格识别概率和实体链接相似度得分作为特征,为每种类型的表格分别训练一个逻辑回归模型。模型学习了两个特征的权重,以此得到知识的可信度。由于枚举列表和键值对表不需额外进行实体链接,他们的实体链接相似度得分均取1。
5 实验 (Experiment)
本文提出的方法已用于国内某个中文百科知识库的构建和扩充,采用的表格数据集来自百度百科和互动百科。由于百度百科与互动百科不提供转储文件,本文通过网络爬虫获得所有带
标签的HTML表格及对应页面信息。其中,互动百科的infobox信息同样采用标签标记。在剔除互动百科340万个实体的infobox并过滤了15万个非知识表后,我们得到126万个中文百科知识表。同时,为了在公开数据集中验证实验有效性,本文使用中文百科格数据集扩充CN-DBpedia[4],并且将实验结果与Ritze[11]的方法进行比较。5.1 表格识别结果评估
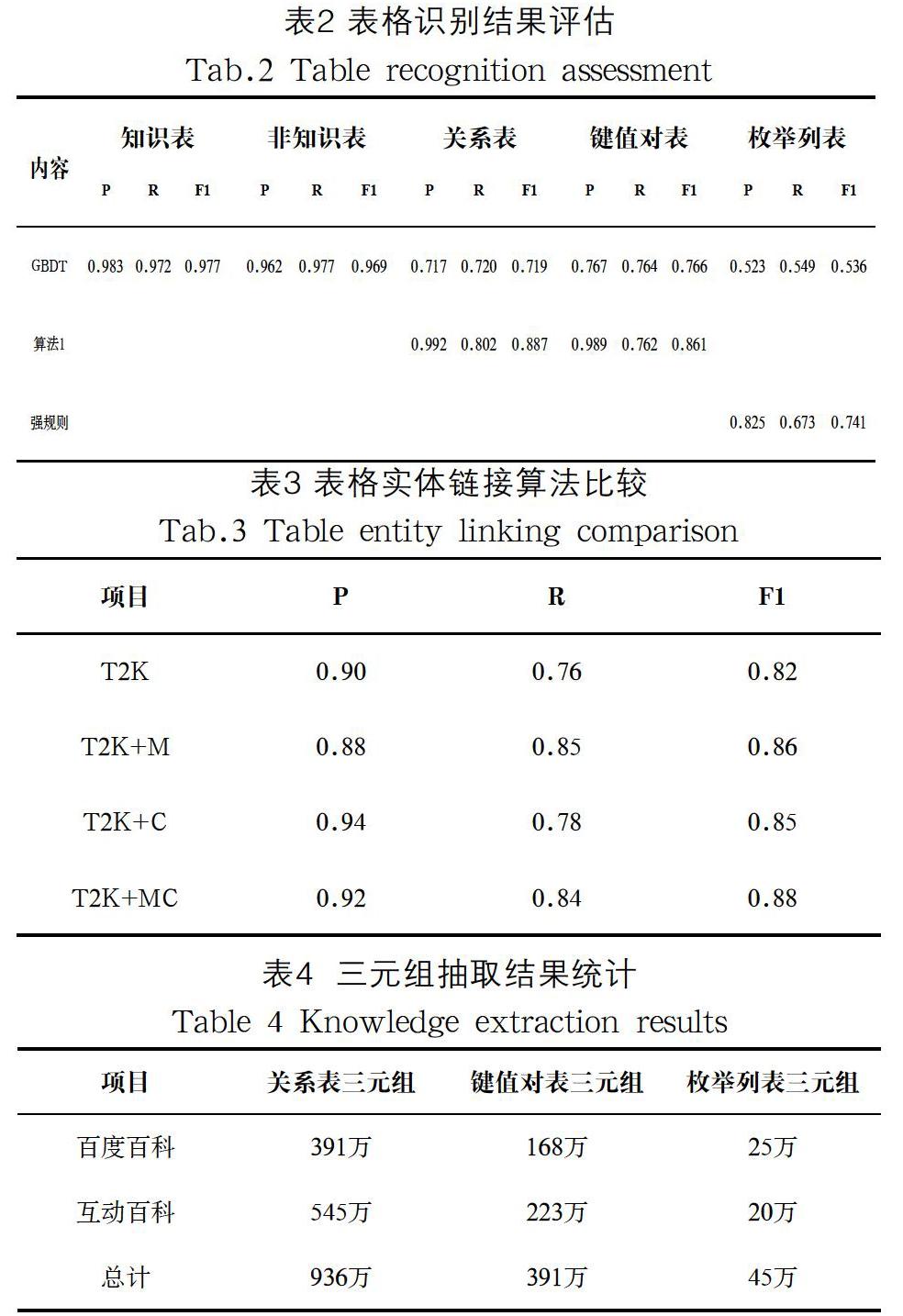
非知识表过滤器模型20折交叉验证了5000个公开的已标注互联网表格和我们标注的1000个从中文在线百科中随机采样的表格,共获得126万知识表和15万非知识表。各类型表格识别器分别获得关系表34万,键值对表21万,枚举列表5万,剩下66万个表格属于复杂类型或难以融入知识库的表格。实验中,我们比较了使用算法1训练的单层梯度决策树表格识别器和未使用模式特征的梯度提升树识别器[12,13](记为GBDT)。我们的报告评估了准确率(P)、召回率(R)和F1值。表格识别评估结果如表2所示,实验证明使用我们的方法训练的识别器效果明显提升,尤其是准确率。
5.2 关系表与知识库匹配结果评估
在4.2节中,我们在T2K[10]算法中加入了表格内容整合和利用公共上位概念的候选集生成的步骤。与Ritze[11]的工作不同的是,我们将中文百科表格与CN-DBpedia匹配。由于WDC Web Tables corpus[11]是来自全网的跨语言表格数据集,所以中文百科表格数据集可以认为是它的子集,同时CN-DBpedia也可以认为是跨语言知识库DBpedia的子集。在实验中,我们首先标注了100个关系表的实体链接结果,然后分别比较了这两个步骤对T2K算法中实体链接的影响。表3中T2K+M、T2K+C和T2K+MC表示分别加入表格内容整合,利用公共上位概念和综合利用两个步骤的T2K算法。如表3所示,表格内容整合使得更多的实体参与到与知识库的匹配过程中进而提升了召回率,而利用公共上位概念可以为实体选择语义相似度更高的候选实体集合,进而提升了准确率。
5.3 融合结果
如表4所示,我们挖掘出了近1400万的三元组知识。在最终入库时,除了要保证三元组的可靠度,还需要去重。我们采取了一个启发式方法,对于关系三元组(宾语是实体),若头实体链接的知识库实体不含该三元组的尾实体,则直接入库。对于属性三元组(宾语不是实体),若头实体链接的知识库实体的属性或属性值,与该三元组的属性,或属性值在相对编辑距离或基于字典的语义相似度上小于阈值则可以直接入库。去重后,我们可以向CN-DBpedia扩充约1000万三元组。
6 结论(Conclusion)
我们的工作提出了基于在线百科表格数据的知识库扩充框架,解决了表格识别和知识融合的挑战。实验结果证明了从百科中抽取的三元组的数量和质量能够用于知识库的扩充。
参考文献(References)
[1] Bollacker K.,Cook R.,Tufts P.Freebase:A Shared Database of Structured General Human Kowledge[C].AAAI Conference on Artificial Intelligence,Vancouver,2007(22-26):1962-1963.
[2] Mahdisoltani,F.,Biega,et al.YAGO3:a knowledge base from multilingual wikipedias[C].Proceedings of the Conference on Innovative Data Systems Research,Asilomar,2015:4-7.
[3] Lehmann,J.,Isele,R.,Jakob,et al.DBpedia-a large-scale,multilingual knowledge base extracted from Wikipedia[M].Semantic Web,2015,6(2):167-195.
[4] Xu B.,Xu Y.,Liang J.,et al.CN-DBpedia:A Never-Ending Chinese Knowledge Extraction System[J].In International Conference on Industrial,Engineering and Other Applications of Applied Intelligent Systems,Springer,Cham,2017:428-438.
[5] Boya Peng,Yejin Huh,Xiao Ling,et al.Improving Knowledge Base Construction from Robust Infobox Extraction[J].NAACL-HLT,2019(2):138-148.
[6] Dong X.,Gabrilovich E.,Heitz G.,et al.Knowledge vault:a web-scale approach to probabilistic knowledge fusion[C].The International Conference on Knowledge Discovery and Data Mining,New York,2014:601-610.
[7] Ritze D.,Lehmberg O.,Oulabi Y.,et al.Profiling the Potential of Web Tables for Augmenting Cross-domain Knowledge Bases[C].International Conference on World Wide Web,2016.
[8] Zhihu Qian,Jiajie Xu,Kai Zheng,et al.Semantic-aware top-k spatial keyword queries[J].World Wide Web,2018,21(3):573-594.
[9] Venetis,P.,Halevy A.,Madhavan,J.,Pasca,M.,et al.Recovering semantics of tables on the web[J].Proceedings of the Vldb Endowment,2011,4(9):528-538.
[10] Cafarella M J.,Halevy A.,Wang D Z.,et al.WebTables:exploring the power of tables on the web[J].Proceedings of the Vldb Endowment,2008,1(1):538-549.
[11] Ritze D.,Lehmberg O.,Bizer C.Matching HTML Tables to DBpedia[C].International Conference on Web Intelligence,Mining and Semantics,Cyprus,2015.
[12] Crestan E.,Pantel P.Web-scale table census and classification[C].International Conference on Web Search & Data Mining.ACM,2011:545.
[13] Crestan E.,Pantel P.Web-scale knowledge extraction from semi-structured tables[J].ACM Press the 19th international conference Raleigh,North Carolina,USA Proceedings of the 19th international conference on World wide web,2010:1081.
[14] Yoshida M.,Torisaw K.,Tsujii J.A Method to Integrate Tables of the World Wide Web[C].In:Proceedings of the First International Workshop on Web Document Analysis,2001:31-34.
[15] Fan J.,Lu M.,Ooi B C.,et al.A hybrid machine-crowdsourcing system for matching web tables[C].2014 IEEE 30th International Conference on Data Engineering.IEEE Computer Society,2014.
作者简介:
宋曉兆(1995-),男,硕士生.研究领域:自然语言处理,知识图谱.
郑 新(1990-),男,硕士,工程师.研究领域:自然语言处理,知识图谱.
李直旭(1983-),男,博士,副教授.研究领域:数据挖掘,知识图谱.
许佳捷(1983-),男,博士,副教授.研究领域:数据挖掘,时空数据库.