分布式计算框架下的大数据机器学习
2019-11-16田彬
文/田彬
1 引言
大数据机器学习并不是简单机器学习,而不是大数据处理的问题,是机器学习、大数据处理等技术难题相互结合和攻克的问题。在此过程中,研究人员要重视机器学习函数算法与方法,并且研究全新且高效化算法,保证实际运行过程中结果精准性得到提高。在大数据机器学习系统和研究过程中,要与并行化和分布式大数据处理技术相互结合,基于可接收时间范围中计算。
2 Spark方法特点
Spark的主要特点就是:
(1)计算效率比较高。利用有向无环图支持循环数据流,将中间数据存储到内存中,迭代运算效率较高;
(2)使用方便,对多开发语言兼容;
(3)具有较强通用性,组件较为丰富。Spark能够提供给开发人员强大且完整组件库,比如流失计算、sql查询、机器学习等组件。
Spark中的计算建模中的有向无环图的所有顶点为弹性分布式数据集RDD,所有边RDD为RDD实际的操作。Spark用户为有向无环图建模的计算,从而对RDD中运行的动作进行转换。有向无环图DAG能够分布式的执行操作,通过机器有向无环图分块,在Driver中设置两个调度组件,有向无环图与任务的调度器能够实现Workews分配的任务与协调。
3 分布式计算框架下的机器学习算法
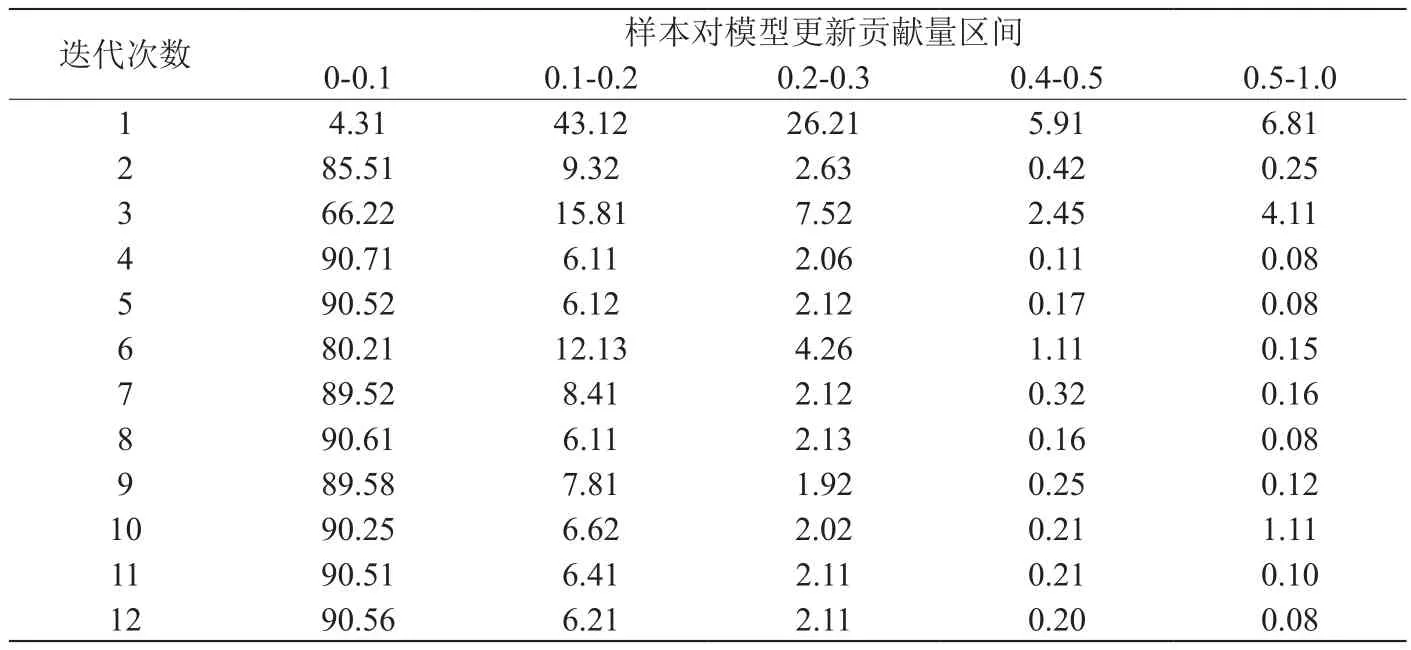
表1:迭代过程中样本对于模型更新贡献量
3.1 机器学习算法的迭代计算
分布式计算框框架为多次迭代计算结构,每次迭代需要对模型参数向量实施更新,图1为模型参数向量的改变。
通过图1可以看出来,不同迭代在迭代后会缩小模型参数向量。以此,设置阈值参数a。这个时候最优质逐渐的接近迭代,迭代会缩小模型参数的该变量。
3.2 迭代计算的样本差异性
计算本地训练样本xi之后得出梯度向量gi,在本地全部梯度向量下将服务器节点发送出去。结合服务器节点和所有节点梯度向量,从而得出总体度g,图2为样本梯度向量的合成。之后通过此梯度对模型参数向量进行更新,将其在下次迭代计算中使用。
在计算迭代过程中,将训练样本xi作为基础计算梯度向量,全部梯度向量合成得出总体度g。通过样本相应梯度向量gi长度||gi||指的是总梯度g贡献,此值越大,对于总体度g贡献也就会越大,也就是样本对于模型参数也具有更大的改变。表1指的是迭代过程中样本对于模型更新贡献量。
通过表1可以看出来,在迭代逐渐开展过程中,大部分样本对于总体度贡献比较小,只有小部分样本影响总体度。另外,在各迭代过程中对于模型参数更新贡献比较小样本的集合交际超过99%,以此表示在样本某次迭代过程中对于总体度贡献比较小的时候,在后续迭代过程中对于总体度贡献比较小。所以,整体迭代计算中,大部分的样本的模型收敛与贡献比较小,只有少部分样本对于模型收敛与更新具有更大的影响。
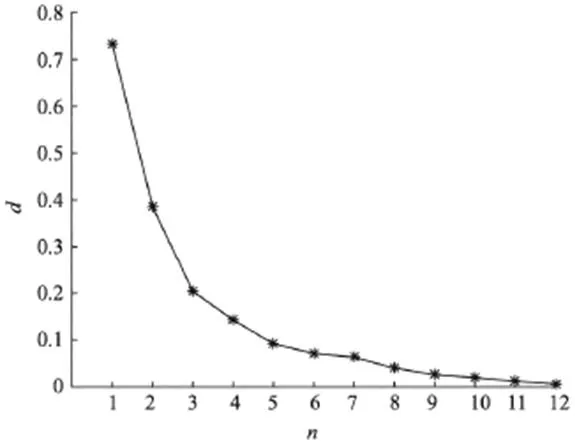
图1:模型参数向量的改变
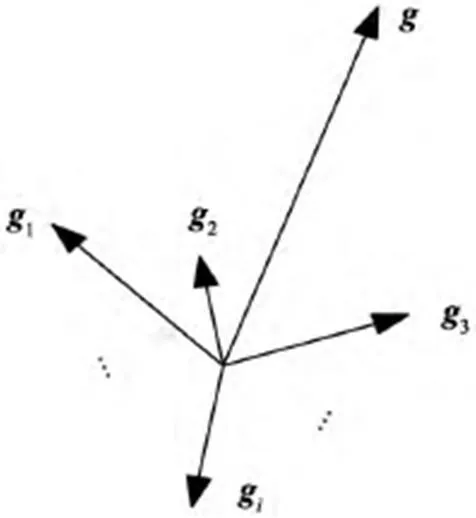
图2:样本梯度向量的合成
3.3 算法的优化
将目前分布式机器学习系统中样本差异性导致分配计算机不均衡性,本文的算法为:
输出:α、β、flag←false
输出:模型参数向量w
方法:对结点r第t次迭代计算过程进行计。
通过此算法表示,在样本对于模型具有较大贡献的时候,在每次迭代过程中都要对此样本精准梯度进行计算,要不然在微调过程中不对此样本梯度计算,使用梯度向量,以此得出梯度向量虽然存在误差,但是因为此梯度向量对于模型更新贡献比较小。在梯度向量重用出现大误差的时候,迭代就会到粗调的阶段中,这个时候要对全部样本精准梯度进行计算,对计算结果正确性进行保证。
4 实验验证
本文在实验过程中,使用两种具备代表性数据集实现算法训练与实验,数据集具体信息为:
(1)动态气体混合中气体传感器数据集(Gas sensot数据集),包括18个特征值与1个lable值;
(2)美国航天局地球交换降尺度气候预测数据集(NEX-DCP30),每行数据包括360个特征值与1个label值。
本文利用多层神经网络使用单层神经网络实现数据集训练,对均方误差和改变迭代时间进行对比。通过试验结果表示,低于最高的均方误差,提高收敛速度。简单来说,所实现多层神经网络能够精准预测数据集。
5 结语
基于大数据机器学习算法研发能够有效解决大规模系统协同和关联的问题,对比传统的机器学习,基于大数据机器学习系统扩大机器训练的样本数量,使学习训练结构和过程多样化得到提高,对隐藏信息进行挖掘。以上通过实验结果表示,算法基于分布式集群环境中能够降低模型训练计算量,并且提高训练模型精准度,使大数据挖掘实时性得到提高。
