基于迁移学习的语言文本识别分类研究与实现
2019-11-16杨显华丁春利
文/杨显华 丁春利
随着社会科技发展,人类基础科学知识积累速度不断加快,现代社会中,信息的流动已经越超书刊等有介媒体,以电子媒介为主体。如何快速有效的找到所需的信息,自动化信息分类是需要解决的第一步,通过分类,所有的信息得以有效的管理,同时为使用过程中的快速准确定位提供基础条件。
传统的分类学习,通过训练得到的分类模型必须要具备准确性和可用性。在样本训练过程中,要求具备两个基础条件:
(1)训练样本和测试样本是独立同分布的;
(2)必须要有大量的训练样本才能得到一个高准确率的分类模型。
在实际工作中,这两个条件比较难以满足。首先,由于文本使用环境和本身语义特性,相互之间相互关联;其次,由于对文本的标注费时费力,很难得到大量高质量标注的少数民族语言训练样本。如何利用少量的少数民族语言文本作为训练样本,建立一个可靠的模型对实际应用中积累的大量少数民族文档进行预测(源领域数据和目标领域数据可以不具有相同的数据分布),是解决上述问题的关键。文献[1]给出的结论是,在小样本情况下,使用迁移学习依然可以得到比较满意的结果。
随着深度学习的广泛关注和研究,迁移学习也成为深度学习的重要研究部分。迁移学习依赖原有知识和模型的积累,在深度学习方向,迁移学习是抽取神经网络的特定层作为解决相关领域问题的解决方法。迁移学习放宽了传统机器学习中的两个基本假设,目的是迁移已有的知识来解决目标领域中仅有少量有标签样本数据甚至没有的标签问题[2]。通过对成熟分类模型的分析和层次抽取,结合迁移学习方法,可在极小训练样本上得到一个最优模型。
1 相关知识
1.1 词向量
自然语言理解需要转为为机器学习问题,首先需要把文字语言中的词进行数学化表达,常用的方法是将每个词表示为一个高维的向量,维度特定维为1的向量表示当前词,这样的向量定义为词向量[3]。词向量表达方式比较简单,得到一个稀疏矩阵,但是造成了维度过多。在实际使用过程中,使用词嵌入实现,词嵌入避免大量词汇的数据稀疏行,同时对数据进行了降维,并在句子加入了词与词的相互关系,直接通过向量之间的余弦距离度量来确定。词向量可以和深度学习神经网络融合,可以直接将词向量作为神经网络模型的输入层,将训练好的词向量作为输入,用前馈网络和卷积网络完成词性标志、语义角色标注等任务。
1.2 特征降维
在前文中提到,在词向量生成过程中,生成一个高维的稀疏矩阵,而在深度学习中,过多的维度会造成维度灾难,维度灾难会造起过拟合,即训练集效果很好,但是测试集效果很差。特征降维有两种方法[4]:
(1)特征选择,特征选择在原有的向量空间选择有效的特征子向量,去掉不相干和冗余的特征子向量。特征选择的目的是压缩向量空间,减少特征的数量,从而提高模型精度。特征选择后,因为特征值没有变量,所有压缩后的特征向量空间保留了原来的特性;
(2)特性抽取,特征抽取将改变原有特征向量空间,将原向量空间通过特征函数映射到一个新的特征向量空间。特征抽取将学习一个映射函数y=f(x),其中x是高维原始数据点,y是映射后低维向量表达。特征映射之后,特征值数据发生变化,维度也降低,且维度之间更加独立。常用的降维方法包括如下:主成分分析(Principal Component Analysis,PCA),奇异值分解(Singular Value Decomposition,SVD),T 分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)等。
1.3 半监督学习
传统意义的监督学习是通过大量的已标记训练样本进行学习,完成模型建立并用于对新输入的预测。真实分类环境中,由于信息技术的快速发展,产生了大量的领域数据,进行大量的数据标注已经变得越来越困难。在深度学习的发展中,逐渐从监督式学习向半监督式学习进化。半监督学习是指学习中的样本包含大量未标记数据,在训练过程中,同时使用标记数据和未标记数据。半监督学习要求更少的已标记训练数据,并也可以得到很好的分类效果。从学习场景可以将半监督学习分为如下4类[5]:
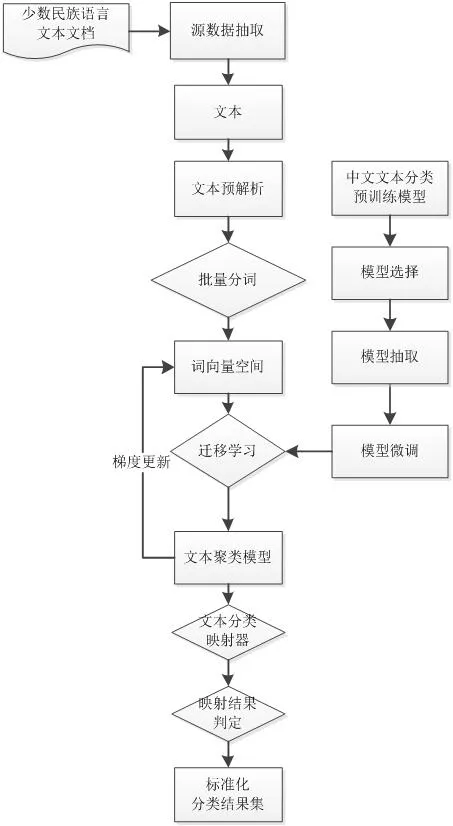
图1:少数民族文本分类迁移学习模型
(1)半监督分类(Semi-Supervised Classif i cation),半监督分类是在监督类分类问题中,使用无分类标签的样本辅助训练有分类标签的数据,得到比只用有分类标签的样本数据训练产生更优的分类器;
(2)半监督回归(Semi-Supervised Classif i cation),半监督回归是在深度学习中线性回归的应用,通过无标记样本数据辅助训练有标签样本数据,得到比只通过有标记样本数据训练产生的更准确的分类器;
(3)半监督聚类(Semi-Supervised Clustering),半监督聚类在聚类算法过程中,使用无标签训练数据辅助有标签训练数据进行聚类分析,得到更好的类簇,提高聚类方法的精度;
(4)半监督降维(Semi-Supervised Dimensionality Reduction),在有标签训练数据信息辅助下得到高维数据的低维结构,同时保留高维数据成对约束特效结构不变,满足高维空间中正相关的样本数据在低维空间中距离相对较近,在高维空间中满足负相关的样本数据在低维空间中距离相对较远。
1.4 迁移学习
迁移学习是深度学习的一种应用模式,在进行一个数据迁移学习分类任务时,迁移任务的目标域数据较小,但已经有一个包含大量训练数据的相似分类任务,此训练数据与迁移学习分类任务的测试数据特征分布不同。在这种情况下,如果可以采用合适的迁移学习方法对目标域数据进行分类识别,即为迁移学习过程[6]。迁移学习可以描述为,给定一个源域Ds,一个原任务Ts。一个目标域Dt,一个目标任务Tt。迁移学习的目的是借助源域和原分类模型提高目标函数fT(*)在目标域的分类效果。根据迁移学习场景不同,迁移学习分为[6]:
(1)实例知识迁移学习(Transferring knowledge of instances),应用于目标域数据和源域数据中部分标签数据相似的情况,实例知识迁移的目的是在目标域中找到适合的标签测试数据的实例,并将这些实例迁移到源训练数据学习中;
(2)特征知识迁移(Transferring knowledge of feature representations),特征知识迁移通过计算目标域数据和源域数据的特征最小域得到迁移模型;
(3)相关知识迁移(Transferring relational knowledge),当目标域和源域数据具有相关性时,使用相关知识迁移。
2 少数民族文本分类迁移学习模型
本文关注在深度学习中,基于迁移学习模型在少数民族语言文本分类中的应用。文本分类由H.P.Luhn教授1957年提出,经过多年的研究和实践,机器学习和统计方法被引入,分类结果准确率得到了较大的提升。在国内有关文本分类研究起步较晚,由于中文文本的特殊性,更多的语言基本以词组表单,同英文单词的语义分隔有较大的差异性,所以在中文文本分类之前,需要进行预处理,需要将原始文本进行分词处理,得到文本的分词词组特征向量组。中文文本的语法、语句要比英文复杂很多,通过采用最大熵模型建立了较好的分类模型。随着深度学习研究的深入,深度学习被应用到传统的文本分类领域,通过建立多层次的卷积神经网络,可以实现对文本内容的高精度分类模型。本文将通过现有卷积神经网络进行迁移学习实现对少数民族语言文本分类模型的建立。如图1所示。
2.1 文本抽取与预处理
进行文本分类时,第一步需要对文本数据进行预处理,预处理包括:
(1)源数据抽取,源数据可能来源于互联网、word文件、PDF文件等,源数据抽取将有格式的富文本文件转换为纯文本文件;
(2)文本切分,切分为可选操作,部分源数据可能有多篇不同类别的主题文本构成,切分之后的文本具有更强的主题意义;
(3)文本分词,分词是预处理的必要操作,后续的词向量生成需要分词结果来表征,常见分词算法有正向最大匹配、反向最大匹配、双向最大匹配、语言模型方法、最短路径算法等;
(4)去停用词,停用包括标点、数字、单字和其它一些无意义的词;
(5)词频统计,词频是文本内容的重要表征,如果一个单词在文中出现频率高,那么这个词越有可能代表这个文档的主题意义,词频也是构造词向量空间的必要元素[7];
(6)文本向量化,用数学上的多维特征向量来表示一个文本,这个向量化文本作为源域数据。
2.2 预训练模型
预训练模型的备选模型是解决中文文本分类时设计并实现的模型,采用中文文本分类模型的原因是:
(1)大量研究者中文文本分类训练模型有深入的研究,作为预训练模型的备选模型丰富;
(2)有比较丰富的已标记中文训练数据集,可以进行大量测试。通过使用预训练模型,避免从零开始训练一个新的模型。同时由于人类语言是具有共性的,通过中文分类模型可以很好的适应其他语言的分类处理。
2.3 模型选择
预训练的源模型是从研究者发布的可用模型中挑选出来的。很多研究机构都发布基于超大数据集的模型,这些都可以作为源模型的备选模型。经过确定的预训练模型将作为第二个任务的模型学习起点,这可能涉及到全部或者部分使训练模型,即进行模型抽取,抽取取决于所用的模型训练技术。
2.4 模型抽取
模型抽取的目的是使用之前在中文文本数据集上经过训练的预训练模型,从而可以直接使用相应的结构和权重,将它们应用到少数民族语言文本分类问题上。模型的抽取与应用即是“迁移”,即将预训练的模型“迁移”到正在处理的特定问题中。
2.5 模型微调
模型微调是使用中文文本分类模型,经过调整后在小集合训练样本的少数民族语言文本分类上也具备较高在准确率[1]。模型微调有三种方式:
(1)特征提取,由于预训练模型和目标模型都是应用于文本分类,人类语言描述具备相似性和通用性(模型可以探知到这种相似性),所有可以将预训练模型作为特征提取装置使用,这种特征提取的有效性是源于它的实现是语言无关的;
(2)预训练模型适配,采用预训练模型的结构,所有层次模型的权重随机化,然后依据目标域的数据集进行训练;
(3)冻结抽取层,训练特定层。将模型起始层和中间层保持权重不变,使用目标域训练数据对后端的层进行重新训练,得到新的模型权重。在实际应用中,采用方式(3)作为微调方式,方式(3)能生效的原因是深度学习网络的前端层次会根据语言特性进行结构化学习,学习的结果与语言含义是无关的,所有具备一定的通用性,模型抽取和微调效果受预训练的数据集和目标训练数据集的相似度影响。
在少数民族文本分类迁移学习模型中,场景特点是数据集小,数据相似度高。在这种情况下,目标训练数据与预训练模型的训练数据相似度很高,不需要重新训练模型。只需要将输出层改成符合问题情境的结构。
2.6 文本聚类模型
K-Means聚类算法有称为k均值聚类算法,K-Means算法的基本思想是把训练集的数据根据特征聚类成K个簇。K-Means算法对连续性数据有很好的适应性,时间复杂度低,聚类效果较好。在主流聚类算法中,K-Means算法基本优于K-Means BisectingHAC和KNN聚类算法[8,9,10]。k-means算法的工作步骤如下:
(1)将全体样本点看成一个簇;
(2)计算当前簇的数量N,当N小于需要分类的簇数K时,进行误差计算;
(3)循环遍历当前所有簇,计算当前簇全体样本的总误差;
(4)在当前簇上进行k-均值聚类操作;
(5)计算将该簇划分成两个簇的误差值;
(6)选择小误差值的簇进行划分操作。
2.6.1 K值及聚类中心点选择
k-meams算法简单并使用广泛,同时能保证收敛,但是算法的两个缺陷将影响算法的效果,本文提出改进。
(1)K值需要初始确定,K值的求解属于经验知识,在通常情况下,K值的估计是很困难的,当采用随机值进行初始化时,分类结果可能得到的是局部最优解而非全局最优解,在少数民族文本分类的应用下,需要特定的专业人员辅助处理,为分类文本确定明确的类簇;
(2)K-means对初始选择的中心点敏感,不同的初始中心点,得到不同的类簇。本文使用如下过程选取k-means的中心点[11,12,13]:1)以专业人员确定的初始k个文档作为质心;2)使用经过特征降维后的词向量,计算当前文档与初始K个质心的距离,得到最近质心距离;3)根据匹配文档和匹配质心重新计算得到新的质心;4)重复2)至3)步,得到新质心和原始质心相等或者小于设置的阈值,更新结束。
2.6.2 K-means算法嵌入迁移学习步骤
迁移学习包含预训练模型、模型选择、模型抽取、模型微调四个步骤。预训练模型使用大量的中文训练数据得到,在模型选择后,使用预训练模型的神经网络参数来初始目标神经网络模型的参数,再使用少量的少数民族语言文本训练数据进行微调。为避免过拟合,仅对少量神经网络的少量层进行训练,模型的关键部分是选取正确的层进行微调,不同的任务选取的层不同。通常在语音识别训练中选择前面的层训练,在图片识别选择后面的层训练。由于人类语言是结构性数据,表达是具有相似性,在深度学习中,神经网络在前面的层将分析记忆这些相似性,在后面的层进行更深入的语义类别的分析,所以在少数民族语言文本分析中,固定前面的层,微调最后一层,最后接基于K-means的分类预测层。最后通过人工辅助分类的少数民族语言文本进行微调训练,训练产生的参数即作为最终的分类参数。
3 结束语
本文提出基于迁移学习的少数民族语言文本识别分类研究与实现模型,设计了一套符合实际情况的小训练样本环境下少数民族语言文本分类的处理步骤和方法,能够有效的文本分类,同时对有标签数据要求很少。本文所研究的迁移学习与K-means算法结合训练少数民族语言文本的处理模型,为少数民族语言文本知识分类、文档分析、文档评价等提供初步分类参考,极大减少人工分类工作,提升分类效率。
