基于Node.js的分布式爬虫系统
2019-11-16高玉民翟浩然
文/高玉民 翟浩然
当今世界,互联网飞速发展,数据量呈指数级高速增长,企业和个人对于快速获得有效信息的需求也越来越强烈。在数据采集方面,网络爬虫系统的应用,特别是基于Node.js技术的分布式爬虫系统的应用,大大提升了数据采集的广度和深度。
1 概述
本系统是基于Node.js技术、采用消息队列通信的可配置的分布式爬虫系统。系统采用主从架构、系统耦合度较低、可灵活配置多项任务,也可根据需要快速部署新爬虫,系统可扩展性较强。
系统整体架构采用Master-worker方式,即由Master节点监控系统运行,接收用户控制,存储最终数据;Worker节点接受任务运行,完成网页下载和信息抽取工作。
如图1所示,每一个爬虫系统有且只有1个Master节点,该系统下Worker节点的数量受到消息队列效率、数据抓取和存储效率的限制,理论上可以有无限多个。Master和Worker节点采用消息队列的方式进行通信,Worker节点之间互不通信。
同时,每一个爬虫系统需要配置一个Redis实例;不同爬虫系统之间可以共享一个Mongodb数据库,且最好使用一个Mongodb实例,以提高系统的运行效率。
2 Master节点描述
每一个爬虫系统由一个Master节点统一进行管理和控制,Master节点主要功能包括监控各节点工作状态,接收、分配和管理爬虫任务,数据存储等。
2.1 系统启动和通信
系统启动时,Master节点会依次启动自身的Http服务、数据库连接和消息队列连接。完成消息队列连接后,系统会收到项下所有Worker节点的上线信息,并将这些节点的相关信息存储在自身Worker列表中,以方便任务调用。
Master和Worker之间使用消息队列进行通信,通信消息格式如表1所示。
本系统的消息队列通过Redis推送/订阅模块实现,若选用其他消息队列系统,可重新编写通信格式。
2.2 节点监控
每当有新的Worker节点上线,Master节点都会收到并记录该Worker节点的信息,并通过分配任务和任务回调,判断节点当前是否空闲。若节点掉线,Master会将该Worker移除Worker列表。用户可通过Master提供的网络API查询当前所有节点的信息和运行状态,但不可指定Worker节点任务分配,不可指定Worker结束运行。
若Master节点掉线,其所属所有Worker节点都将记录当前工作状态,正在执行任务的节点会停止当前工作,等待Master重新上线。
2.3 任务的接收、分配和管理
Master节点提供一系列的网络API方便用户提交任务并监控任务状态。
2.3.1 任务提交
在系统上线后,用户可通过Master节点提供的网络API上传爬取任务。每个任务都需要填写统一的任务信息,以便爬虫能够识别任务、过滤URL和网页元素、合成最终数据。
任务数据包含的内容具体如表2所示。
用户填写好上述信息后,封装成Json格式,向/New_task发起Post请求;若任务被成功接收,系统会返回成功信息和任务当前状态。
2.3.2 任务运行和状态
Master获得任务后,会通过下属Worker节点的信息来分配任务。一般来说,Master总是选择第一个空闲Worker来分配任务;若没有空闲Worker节点,则接收到的任务进入任务等待队列。
分配好的任务会将自身状态设置为“运行中”,并记录负责该任务的Worker节点信息。用户可通过查询任务来获取Worker信息,然后通过查看Worker当前状态来获取该任务的进度。
用户可以随时取消等待队列中的任务,取消后,该任务状态设置为“已取消”,不再被任何Worker运行。用户也可以取消正在运行中的任务,即,通过取消负责该任务的Worker当前工作来完成这一动作;取消正在进行的任务时,Worker会等待该任务当前最后一个URL抓取成功后再取消任务的运行,避免异常情况的发生;任务取消后,Worker会通知Master任务已经取消,Master会将该Worker节点置为空闲状态。
Worker在完成任务后,会向Master节点返回任务完成信息;Master节点将该Worker状态置为空闲。
在任务完成或进行中任务被取消后,Master节点向任务等待队列询问是否有等待任务;若发现等待任务,则进入新的任务分配和运行环节。如图2所示。
2.3.3 定时任务
对于需要定时爬取的任务,不必通过网络API指定,仅需要将其配置在Master启动任务文件中,由Master节点按时调用。具体任务的创建、分配及管理过程如上文所示。

表1
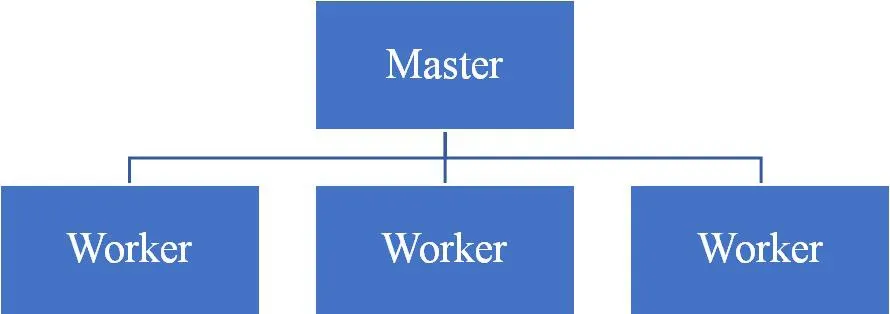
图1:系统整体架构图
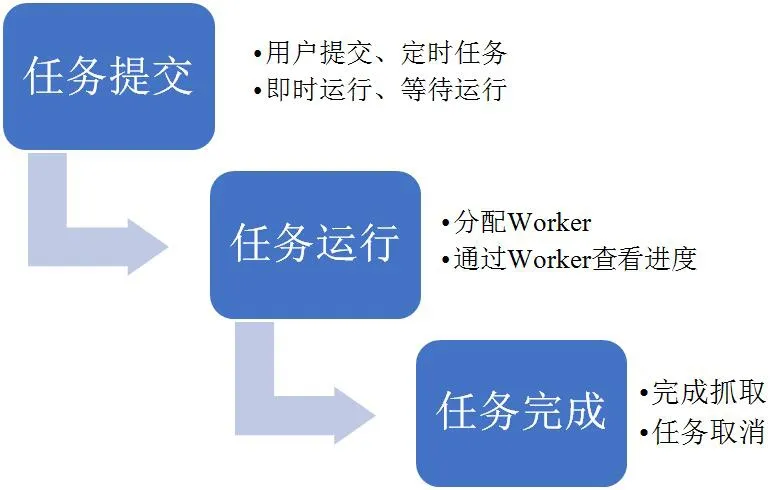
图2
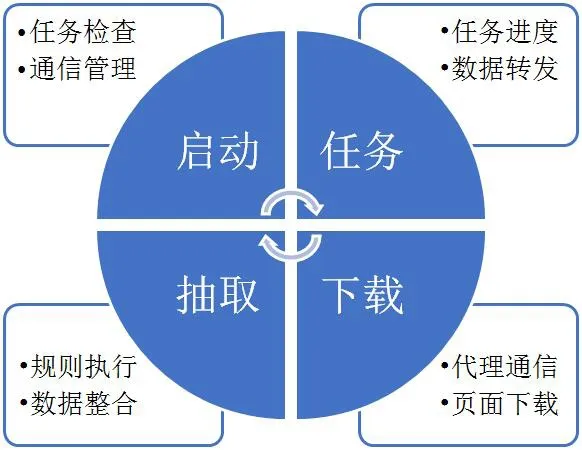
图3
2.4 数据存储
每当Worker节点抓取到一条符合要求的数据后,都会将抓取后的数据按照一定的格式返回Master,由Master节点负责数据存储。由于系统运行速度和数据格式的不断变化,本系统数据存储采用Mongodb数据库。数据存储格式如表3所示。
用户可根据爬取任务域和主题从本数据库中提取数据,以便进行深层次的分析和应用。
3 Worker节点描述
Worker节点负责从Master接受任务、爬取信息,并将用户所需的结果返回至Master。Worker节点由任务调度器、网页下载器、内容抽取器组成。
3.1 启动和通信
Worker启动时,会自动启动一个Redis客户端,用于和Master进行消息通信。同时,检查自身是否存在未完成任务,避免异常退出重启导致任务丢失。完成前述动作后,Worker会根据配置好的信息源爬取代理IP信息,并存入任务调度模块中。
启动完成后,Worker会向Master发送注册请求,将自身信息注册到Master上,具体通信格式请参照上文相关内容。若Worker发现存在未完成的任务,则直接进行任务中余下的网页爬取,并在注册时提交自身“非空闲”的信息。
若Master节点掉线,在工作中的Worker节点收到通知后会立即暂停当前任务,等待Master节点上线后重新启动任务。
3.2 任务调度器
任务调度器负责跟踪任务URL列表,根据爬取记录添加新的URL、删除已经抓取过的URL。任务调度器会直接丢弃新爬取的网页链接中已经抓取过的URL。在分配网页抓取任务时,从代理IP列表中随机抽取一个,供网页下载器使用。
网页抓取完成后,任务调度器负责处理抓取信息,从中提取URL所在网站的其他未抓取的URL,完成计数、统计代理IP是否失效、将处理好的结果发送给Master节点的相关工作。总体来说,任务调度器可以看作是任务和爬取结果的一个中间层设置。
3.3 网页下载器
为灵活应对不同情形,本系统采用三种方式进行网页下载,具体如下:
(1)当网页中不存在反爬取功能时,系统使用Request模块进行网页请求和内容获取;
(2)当网页中存在反爬取功能,需要渲染出整个网页或在其中需要模拟鼠标键盘事件的,系统会通过进程间通信,使用Phantomjs软件进行渲染和网页内容获取;
(3)当信息源提供公开的网络API时,可通过网络API绕过内容抽取器直接获取对应信息。
以上三种方法均支持通过代理IP向目标服务通信。其中,在使用Phantomjs时,支持调用Phantomjs脚本,以便更好地模拟真人试用网页的情况。

表2

表3
3.4 内容抽取器
内容抽取器是Worker节点的最核心模块,负责将下载好的网页信息按照用户配置的方法从DOM元素中提取相应的字段、搜集URL目标网站包含的其他链接,并按照用户规定的模式,从相应DOM中获取数据,按照标题组合形成Object实体;最后将抽取组合好的信息返回给任务调度器,由任务调度器作出最终处理,返回给Master。
3.5 Worker组件图
如图3所示。
4 结语
需求,随时增加或减少Worker节点,提升系统的运营效率。
(2)本系统支持用户根据网页特性和数据分布,自定义信息提取的DOM标记,并分配给每个信息项目一个标题,自动完成面向数据的规范化过程,大幅度减少数据应用和分析的ETL时间,从源头上加快信息收集的效率。即,一切任务以用户所想的方式进行,一切数据以用户所需的形式处理。
(3)本系统采用Mongodb作为数据存储的工具,其Schema-free的特征保证了在完全兼容多变的数据结构的情况下,最大程度地保持数据的规范性,并能够在快速运行时兼顾多Worker同时工作场景下的数据存储要求。
(4)本系统通过代理访问目标源,防止目标源根据请求发起IP限制访问;本系统规定了每个IP访问目标源的最小时间间隔,不会对目标服务进行过度请求,保证了目标源的运营安全;同时,对于采取了轻度反爬措施的网站,本系统也有相应的处理方法,增强了系统的可用性。
(1)本系统基于Node.js技术开发,与其他技术框架相比,能够更好地处理由Javascript渲染的网页信息、支持Json这种应用最广泛的网络数据格式。
同时,由于Javascript本身的特性,本系统在保持与Python开发效率相当的情况下,实现更快速度的运行。此外,Node.js框架与Java技术在网页内容抓取的效率相当,但该框架在IO方面的性能更加高效,占用的机器资源更少,有利于降低开发和使用成本。
本系统使用PM2模块进行部署和管理,同时,由于采用了分布式架构,可以根据业务
