基于深度学习的机器视觉目标检测算法及在票据检测中应用
2019-11-15刘桂雄刘思洋吴俊芳罗文佳
刘桂雄 刘思洋 吴俊芳 罗文佳


摘要:基于深度学习的目标检测是机器视觉应用的重要方面。该文系统总结基于区域候选的目标检测算法、基于回归方法的目标检测算法及其他优化算法的算法思想、网络架构、演进过程、技术指标、应用场景,指出在机器视觉系统应用中,应充分考虑检测对象、检测精度、实时性能要求,结合不同目标检测算法特点,选择最合适的检测算法。最后,面向票据检测需求,分析目标检测算法在票据图像位置检测、防伪特征检测、文本信息检测中的应用。
关键词:机器视觉;目标检测;深度学习;卷积神经网络;票据检测
中图分类号:TP302一 文献标志码:A 文章编号:1674-5124(2019)05-0001-09
0 引言
在智能制造與装备等产业中,机器视觉检测技术因其实时性好、准确性高、适用性广而得到广泛应用。目标检测作为机器视觉系统主要任务之一,在工业相机采集高分辨率图像信息基础上,实现多目标物体识别、位置预测,并关联目标物体位置信息与世界坐标信息,控制视觉检测系统驱动器进行相应机器检测操作[1]。机器视觉目标检测算法由目标特征提取器、目标分类器与目标位置区域搜索方法构成[2-5]。其中,目标特征提取器由人为设计,提取目标图像颜色、形状、纹理等信息,如方向梯度直方图特征[6](histogram of oriented gradient,HOG)、尺度不变特征[7](scale-invariant feature transform,SIFT)等;目标分类器则是基于提取器得到信息进行特征计算,确定目标类别,代表性的有基于支持向量机(support vector machine,SVM)分类器[8]、adaboost分类器[9];目标位置区域搜索方法通常是采用滑动窗口(slding window)在图像上滑动,对每个滑动区域进行特征提取与分类,判断该区域存在目标概率及其位置[10]。机器视觉目标检测算法的目标特征提取器、目标分类器、目标位置区域搜索方法独立设计,实现目标检测,在特定场景下检测效果良好,但通用性较差、开发周期较长。
卷积神经网络(convolutional neural networks,CNN)具有特征学习与归纳能力强特点,深度学习采用端到端学习策略(end-to-end learning),将特征提取、目标分类、目标定位任务整合到神经网络架构中,实现从图像输入到目标分类与定位检测结果输出的统一过程[11],与经典目标检测算法相比,有效地简化算法过程,提高检测效率,以CNN为代表的深度学习方法成为目标检测领域研究热点[12]。目前,基于深度学习的目标检测算法与机器视觉系统结合,已经在无人机巡[13]、工业CT图像缺陷检测[14]、车辆检测[15]、移动端人脸检测[16]等领域取得较大进展,但在复杂多变的目标检测场景中应用存在问题,如在票据检测应用领域,目前多采用传统目标检测方法完成票据某一防伪特征检测[17-18],而实现票据完整检测涉及多光照条件票据检测[19]、票据多防伪特征检测[20]、票据文本信息检测[21]等多项任务,票据在不同光照条件下又呈现复杂多变图像特征,传统目标检测方法在票据多目标检测中应用复杂、实现困难。基于深度学习的目标检测算法在高特征维度中具有强大分辨能力[22],非常适合应用于票据检测的机器视觉系统中。
本文系统总结基于深度学习的机器视觉目标检测算法,对比各种算法在VOC2012[23]目标检测数据集中的性能,指出不同目标检测算法适用的机器视觉任务场景,并结合基于深度学习的票据检测技术加以分析与应用。
1 目标检测算法准确性评价指标
基于深度学习的目标检测算法以经典CNN作为骨干网络,包括输入层、卷积层、池化层、全连接层、输出层[24]。输入层以固定分辨率图像作为输入,由多层卷积层进行图像逐层卷积运算,完成从颜色、纹理等低级特征到图像高级语义特征提取,全连接层则根据输出层具体任务,对高层特征进行映射,再由SVM、SoftMax等分类器输出目标类别置信度、目标包围框(bounding box)坐标参数。典型CNN网络包括AlexNef25]、GoogleNet[26]、VGG16[27]、ResNet[28]等。算法结合目标位置区域搜索方法,采用端对端训练策略,完成图像从输入到目标类别、目标位置坐标输出的统一过程[29]。
在多类别目标检测任务中,算法在一幅图像上对某种待测目标的检测结果存在4种情况(图1为算法检测结果示意图),情况1为算法检测得到的样本属于待测目标样本TP,数量为N即;情况2为算法检测得到的样本不属于待测目标样本FP,数量为NFP;情况3为未被算法成功检测的其他目标样本TN,数量为NTN;情况4为未被算法成功预测的待测目标样本FN,数量为NFN。
目标检测算法准确性评价指标可用查准率Pprection、查全率Precall表示。其中,查准率Pprection定义为算法检测得到样本总数NTp+N即中,待测目标样本数NTP所占比率,即:
Pprection=NTP/NTPNFP(1)
查全率Precall定义为图像上存在的所有待测目标样本数NTP+NFN中,算法检测的待测目标样本数NTP占比率,即:
Precall=NTP/TP+NFN
在保证查全率Precall处于较高水平前提下,查准率Pprection越高,算法性能越好。以Precall为横坐标,以Pprection为纵坐标建立曲线,曲线与坐标轴中所包围面积即为算法在单类目标检测中的准确性评价指标AP(average precision),对于多类别目标检测,则求各类目标检测结果准确性指标平均值mAP(meanaverage precision)作为算法准确性评价指标。
2 基于深度学习的机器视觉目标检测算法
基于深度学习的机器视觉目标算法按实现原理可分为基于区域候选的目标检测算法[30]、基于回归方法的目标检测算法[31],两者区别主要在于是否采用区域候选方法(region proposals)。此外,一些算法从损失函数设计、网络优化人手,提高算法检测能力[32]。
2.1 基于区域候选的目标检测算法
基于区域候选的目标检测算法首先为待检测目标选取候选区域;其次,在候选区域上进行特征提取、目标分类、位置调整;最终输出检测结果。
1)R-CNN
Girshick(2014)将CNN引入目标检测任务,提出R-CNN算法[33](region-convolutional neural net-work),是基于深度学习的目标检测算法奠基之作。图2为R-CNN算法流程,利用选择性搜索策略(selective search)提取约2000个目标候选区域,将候选区域大小改变为统一尺寸,输入由AlexNet作为骨干网络实现自浅而深的图像特征提取,由SVM分类器对每个候选区域特征向量进行分类,最后采用非极大值抑制策略(non-maximum suppression,NMS)完成目标包围框位置修正。
R-CNN通过区域候选方法将目标检测问题转化为图像区域的分类问题,相较于经典算法,大幅度提高算法检测性能,具有简单、通用性强优点,但其在2000个区域候选与特征提取中进行多次重复运算,影响算法时间性能。在ILSVRC2013数据集上,R-CNN将mAP从之前最佳算法OverFeat的24.3%提升至31.4%,在VOC2012数据集上达到53.3%。
2)SPP-Net
为弥补R-CNN对2000个区域候选区域尺寸改变、特征提取出现重复操作、冗余运算问题,KaimingHe等(2015)提出SPP-Net(spatial pyramid poolingnetwork),一次性完成整张图片卷积特征提取,且无需固定图片尺寸,极大减小R-CNN算法卷积运算量[34],图3为SPP-Net算法流程。相较于R-CNN算法网络结构,SPP-Net在卷积层最后一层与全连接层间加入空间金字塔池化层,它将选择性搜索策略得到的候选区域对应至卷积特征图上,并全部以金字塔池化方式形成大小一致的特征图进入全连接层进行进一步计算。
SPP-Net在R-CNN基础上,采用空间金字塔池化方式解决候选区域归一化问题,并在一次卷积运算基础上实现所有候选区域特征提取,在检测速度上比R-CNN提高38~102倍,准确性上略有提高。但SPP-Net对象分类与边界框回归两部分任务依然是分离进行,计算空间占用率高,计算效率较低。
3)Fast R-CNN
Girshick(2015)借鉴SPP-Net空间金字塔池化层思想,提出R-CNN升级版本Fast R-CNN[35](fastregion-convolutional neural network),图4为Fast R-CNN算法流程图,其在卷积层之后引入ROIPooling层,与空间金字塔池化层产生相同效果,保证在不同分辨率候选区域输入下得到相同维度特征向量,满足网络输出对图像分辨率的要求,并可使用反向传播(back propagation,BP)[36]实现网络端对端学习。同时,Fast R-CNN构造多任务损失函数,将分类与边界框回归统一于一个损失函数中,实现分类与定位结果的统一输出。此外,Fast R-CNN采用VGG16作为骨干网络,更为优异的特征提取网络一定程度上提高目标检测准确率。
Fast R-CNN作为R-CNN升级版本,在VOC2012数据集上mAP达到66.0%,同时,端对端的统一学习架构使得Fast R-CNN的训练时间、检测时间有效缩短,在不包括区域候选过程条件下,单张图片检测时间为0.3s。但选择性搜索这一区域候选方法仍然严重影响Fast R-CNN的实时性能,是Fast R-CNN的工业应用瓶颈。
4)Faster R-CNN
SPP-Net与Fast R-CNN均从特征提取、候选区域尺寸归一化角度提升目标检测算法性能,而Girsh-ick(2017)提出的Faster R-CNN(faster region-con-volutional neural network则从算法另一瓶颈——区域候选策略改进算法[37],Faster R-CNN提出RPN网络(region proposal network)代替选择性搜索作为区域候选方法。图5为Faster R-CNN算法流程图,RPN网络在图像卷积特征图上通过滑动窗口方法,采用预设尺度为特征图上每个锚点生成9个锚点框并映射至图像原图,即为候选区域。其中,RPN与全连接层共享输入卷积特征图,极大降低运算量。
Faster R-CNN采用RPN代替选择性搜索方法完成区域候选任务,充分利用骨干网络提取的图像特征。Faster R-CNN在VOC2012数据集上mAP达到75.9%,时间性能达到5f/s,即is内可检测5张图像(包括区域候选过程);但算法在小目标检测任务中效果较差,这是由于选取的锚点框经过多次下采样操作,再返回至原图时,对应于原图中区域较大部分,使得小目标的定位准确性下降。
综合以上分析,基于区域候选的目标检测算法采用区域候选方法预测目標位置,通过合并有效区域、去除冗余区域策略实现目标位置调整,实现目标高精度定位,但区域候选方法耗费较长时间,适用于检测精度要求高、检测实时性要求不高场合。
2.2 基于回归方法的目标检测算法
基于回归方法的目标检测算法不同于基于区域候选的目标检测算法“区域候选+分类”思路,将目标检测过程简化为端到端的回归问题,通过网格划分、像素合并等操作减少图像处理操作,直接获得目标类别与位置信息,提高算法实时性。
1)YOLO系列
针对基于区域候选的目标检测操作繁复、实时性不佳的缺点,Redmon J等(2016)提出YOLO(youonly look once)算法[38]。图6为YOLO算法流程图,其将图像划分为S×S网格(cel1),在提取卷积特征图基础上,若目标中心落在某网格中,则该网格为目标预测若干个目标边界框与置信度,最后通过边界框交并比IOU(intersection over union)等指标去除、合并边界框,最终获得检测结果。
YOLO采用以网格划分为基础的多尺度区域代替区域候选步骤,以牺牲部分检测精度为代价提高检测速度,实现在线实时检测,检测时间性能达到45f/s,在VOC2012数据集上mAP为57.9%。YOLO受检测精度影响,其目标定位较为粗糙,小物体检测效果差,易出现漏检情况。
Redmon J等(2017)在YOLO算法基础上研究YOL09000算法[39]。针对YOLO检测精度问题,YO_L09000在卷积网络架构上进行优化,设计DarkNet-19网络并引入批归一化层[40](batch normalization,BN),一定程度上解决训练过程过拟合问题,从图像特征提取质量角度提高检测精度。在小目标检测效果不佳问题上,YOL09000采用多尺度训练策略(multi-scale training),即网络训练过程中调整输入图像分辨率,使得网络具有不同分辨率图像的检测能力。YOL09000在45f/s检测速度下达到mAP值为63.4%的检测效果。由于YOL09000算法仅使用最后一层特征图作为特征输入,特征信息多样性不足,限制其检测效果。
Redmon J等(2018)再次研究YOLO系列新算法YOLOv3[41],CNN研究结果表明,具备深度、宽度的特征提取网络在特征多样性、层次性表达效果更好[42]。YOLOv3借鉴该思想,设计更深的特征提取网络DarkNet-53,以及面向工业应用的轻量化网络Tiny-DarkNet,进一步弥补YOLO系列算法在检测精度上的缺陷。
2)SSD
Liu Wei等(2015)在以POLO为代表的目标检测算法思路基础上,借鉴Faster R-CNN在提高检测精度方面采取的方法,提出SSD(single shot multiBoxDetector)目标检测算法[43]。图7为SSD算法核心思想示意图,SSD算法与YOLO系列算法思想一致,将原始图像划分为若干个网格,同时借鉴FasterR-CNN关于锚点框设置方法,为每个网格设置特定长宽比先验框,以适应目标形状与大小,减少训练难度。另外,SSD采用多尺度训练策略,大尺度特征图用于检测小目标,小尺度特征图用于检测大目标,提高目标检测精度。
SSD算法结合YOLO算法、Faster R-CNN算法优点,兼具实时性与准确性,在当时是最先进算法之一,在VOC2012数据集上达到72.4%检测精度及59f/s检测速度。同时,SSD采用多尺度训练策略,使得SSD在小目标检测上取得重大突破,适用于小目标检测场景。
基于回归方法的目标检测算法与基于区域候选的目标检测算法相比,减少区域候选步骤,直接在原图图像上划分网格、分类、位置调整,提高检测速度,但由于网格划分不具备目标位置的任何先验信息,导致该类算法在检测精度上略有欠缺,适用于在线、实时检测场合。
2.3 其他相关改进算法
除基于区域候选、基于回归方法的目标检测算法思想外,一些目标检测算法从损失函数优化、神经网络加速等方面进一步提高算法检测准确性与实时性。
1)RetinaNet
T.Lin等(2017)指出目标检测算法精度难以进一步提升主要由类别不平衡问题导致,即在算法生成的大量目标边界框中,大部分边界框包含的是图像背景类别,只有少部分边界框包含待测目标。若分类器将所有边界框分类为背景类别,将导致分类器往错误方向训练学习,检测效果下降。在此问题分析基础上,T.Lin等设计新损失函数,提出RetinaNet目标检测算法[44],它在损失函数设计中加入损失权重参数,当检测结果为背景时具有较小损失权重值,当检测结果为待测目标时具有较大损失权重值,达到背景类别、待测目标类别整体样本损失值平衡。
2)RefineDet
S.Zhang等(2018)指出CNN在执行下采样步骤时,将丢失目标边界等细节信息且在高特征维度中无法恢复,产生目标定位误差,从多卷积特征融合角度对算法完成改进,提出RefineDet(refinementneural network for object detection)目标检测算法[45],借鉴ResNet卷积层跳跃连接(short connection)思路,引入特征融合模块transfer connection block),将网络中多个卷积层输出特征图进行连接,实现从底层轮廓、边界特征到高层语义特征融合。此外,RefmeDet引入样本过滤机制,对于属于图像背景类别且置信度高的样本,算法直接舍去该样本,以缓解样本不平衡问题,提高训练速度。在VOC2012数据集上,RefmeDet在24.1f/s的时间性能下达到80.1%的mAP值。
表1为各种目标检测算法及其效果比较表。可以看出,基于区域候选的目标检测算法在检测精度上表现优异,基于回归方法的目标检测算法在时间性能上效果良好,在工业应用中,应根据应用场景、任务要求选择算法。
3 目标检测算法在票据檢测中的应用
在用于票据检测的机器视觉系统中,系统首先由工业相机获取包含票据目标的高分辨率图像,检测票据目标在图像上位置并确定其票据类别、光源激发条件信息;其次,完成票据目标所有局部防伪特征检测,并与该光源条件下标准票据防伪特征比对,判定票据真伪[48];最后,系统采用图像文本检测方法读取票据票号、数额等信息,完成票据信息检测。在票据检测过程中,涉及目标检测算法的应用包括多光源激发条件下图像位置、防伪特征、文本信息等检测。
3.1 票據图像位置检测
在开放式票据防伪鉴别仪器中,票据图像在视觉系统视野中位置存在偏移、旋转情况,其在视野中位置影响票据局部防伪特征检测。传统方法采用检测票据图像局部角点、颜色特征等实现票据图像位置检测。Young P等(2015)采用SURF(speeded-up robust features)角点特征检测方法定位票据特征位置,在可见光条件下实现票据识别[49];Liu X W等(2014)首先利用模糊集理论对纸币目标与背景进行对比度增强,然后用最小二乘法拟合出纸币像素边缘,根据像素边缘线角度校正纸币图像,完成纸币位置区域检测[50]。该类方法在特定检测条件下的票据位置检测效果良好,但在不同检测条件下通用性较差,而票据完整检测要求在自然光、紫外光、透光、红外光条件下分别检测(见图8),要求票据图像位置检测方法具有通用性。
票据图像位置检测是在高分辨率图像中对票据目标的粗定位,是票据局部防伪特征检测基础。因此,票据图像位置检测精度要求不高,只需获取票据目标的边缘、类别信息,允许一定位置误差,但要求算法时间性能佳,检测速度快。基于回归方法的目标检测算法既满足多光源条件下票据位置检测算法通用性要求,又具备实时性检测特点,是该任务场景下首选算法。
3.2 票据防伪特征检测
票据防伪特征检测是票据检测的核心内容,是通过视觉方法鉴别票据真伪的关键手段[51]。票据在不同光源下呈现不同防伪特征(如图8所示),如紫外光下的荧光图案特征、透光下的油墨特征、红外光下则隐去大部分特征,仅保留某些文字、编码特征,复杂多变的票据特征为所有防伪特征检测增加难度。传统图像算法针对票据一种或某几种防伪特征设计相应检测鉴别算法[52],Roy A等(2015)将荧光特征、安全线特征作为检测目标,结合阈值分割等图像处理方法完成特征检测,并计算检测特征与标准特征的图像欧式距离,判定真伪[53];Bruna A等(2013)研发红外光下欧元伪币检测系统,系统利用红外相机获取的钞票图像,通过图像降噪、SIFT特征提取,SVM分类方法评判红外光下整张纸币真伪情况[54]。
以Faster R-CNN为代表的基于区域候选的目标检测算法在多目标检测任务中表现优异,检测精度高,适用于票据多防伪特征检测任务场景。
3.3 票据文本信息检测
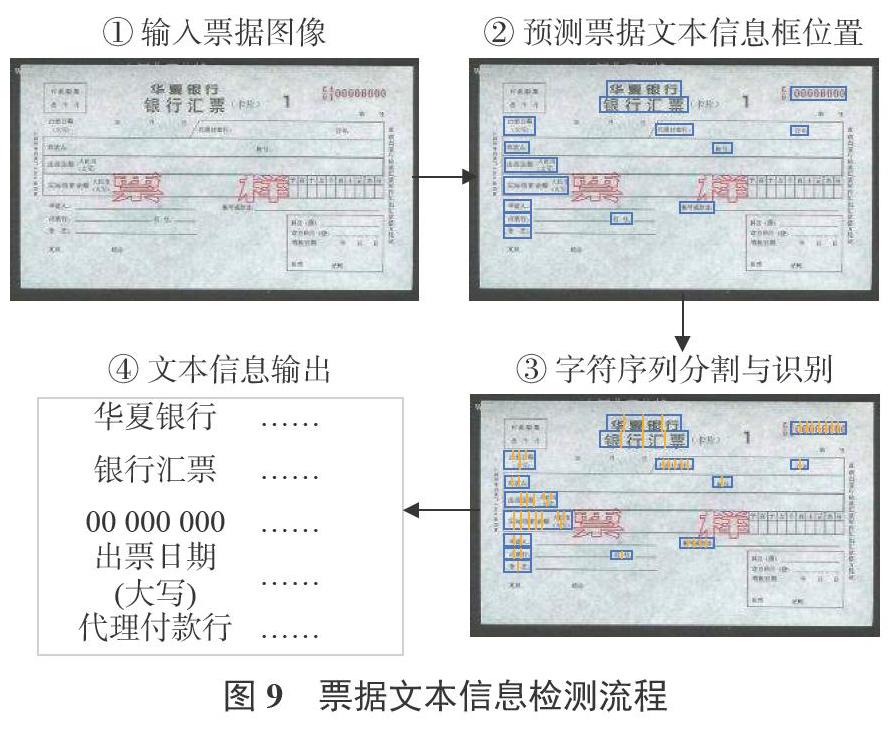
票据文本信息检测完成票据编码、数额、类型等关键信息检测与读取,是实现票据信息自动保存记录的基础。图9为基于深度学习的票据文本信息检测流程,在输入票据图像基础上,采用目标检测算法预测票据信息文本框位置,其次在文本框内对字符序列进行分割,依次对每个字符内容进行分类识别,最终合并字符序列,输出票据文本信息。
票据文本信息处于票据图像很小区域范围内,属于小目标检测任务范围,应选用类似SSD在小目标检测中又快又准的算法[55]。
在面向票据检测的目标检测算法应用中,根据票据检测不同阶段、不同任务场景,结合不同类别目标检测算法特点,选用最为合适算法。基于回归方法的目标检测算法用于票据图像快速定位,基于候选区域的目标检测算法用于票据防伪特征精准检测,票据文本信息检测则使用SSD等小目标检测算法。
4 结束语
目标检测是机器视觉检测的一部分,实现图像上目标的分类与定位,可分为基于区域候选的目标检测算法、基于回归方法的目标检测算法、其他改进算法。其在票据检测领域具有广泛应用前景,总结如下:
1)基于区域候选的目标检测算法采用“区域候选+分类”的实现思路,区域候选策略为目标检测提供先验定位,降低算法在目标定位选择的盲目性,然后通过位置精修获得目标准确位置,其特点是检测精度高,适用于图像精密检测场景;
2)基于回归方法的目标检测算法则将目标检测视为回归问题解决,减少区域候选步骤,简化算法流程,直接在图像特征提取基础上输出目标类别置信度与位置信息,有效提高检测实时性,适用于动态在线检测场景;
3)一些目标检测算法研究基于深度学习的目标检测机理,从图像特征提取网络优化、训练损失函数设计、多层卷积特征融合等方面实现目标检测算法优化,提高检测精度;
4)在票据检测的机器视觉系统中,包括图像位置、防伪特征、文本信息等检测,在应用过程中,应结合不同场景检测需求与目标检测算法特点,选择适用算法,提高票据检测精度、实时性能,构建面向票据检测应用的智能检测系统。
参考文献
[1]尹仕斌,任永杰,刘涛,等.机器视觉技术在现代汽车制造中的应用综述[J].光学学报,2018,38(8):11-22.
[2]GUO Y,LIU Y,OERLEMANS A,et al.Deep learning forvisual understanding:A review[J].Neurocomputing,2016,187:27-48.
[3]FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al.Object detection with discriminatively trained part-basedmodels[J].IEEE Transactions on Pattern Analysis andMachine Intelligence,2010,32(9):1627-1645.
[4]REN X,RAMANAN D.Histograms of sparse codes for objectdetection[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2013.
[5]FELZENSZWALB P,GIRSHICK R,MCALLESTER D,et al.Visual object detection with deformable part models[J].Communications of the ACM,2013,56(9):97-105.
[6]DALAL N,TRIGGS B.Histograms of oriented gradients forhuman detection[C]//International Conference on ComputerVision&Pattern Recognition(CVPR'05),2005.
[7]LOWE D G.Distinctive image features from scale-invariantkeypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[8]CHEN P,LIN C,SCHOLKOPF,B.A tutorial on v-supportvector machines[J].Applied Stochastic Models in Business&Industry,2005,21(2):111-136.
[9]WANG P,SHEN C,BARNES N,et al.Fast and robust objectdetection using asymmetric totally corrective boosting[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(1):33-46.
[10]尹宏鹏,陈波,柴毅,等.基于视觉的目标检测与跟踪综述[J].自动化学报,2016,42(10):1466-1489.
[11]方路平,何杭江,周国民.目标检测算法研究综述[J].计算机工程与应用,2018,54(13):11-18,33.
[12]于进勇,丁鹏程,王超.卷积神经网络在目标检测中的应用综述[J].计算机科学,2018,45(S2):17-26.
[13]张明江,李红卫,赵卫虎,等.深度学习在军用光缆线路无人机巡检中的应用[J].光通信研究,2018(6):61-65.
[14]常海涛,苟军年,李晓梅.Faster R-CNN在工业CT图像缺陷检测中的应用[J].中国图象图形学报,2018,23(7):129-139.
[15]王卫东,程丹.监控场景下的实时车辆检测方法[J].电子测量与仪器学报,2018(7):83-88.
[16]魏震宇,文畅,谢凯,等.光流估计下的移动端实时人脸检测[J].计算机应用,2018,38(4):1146-1150.
[17]张玉杰,张媛媛.便携式票据数字水印检测系统的研究[J].自动化仪表,2013,34(3):41-43.
[18]陶锐,孙彦景.金融票据混沌水印加密算法研究与实现[J].电子器件,2017,40(5):1297-1303.
[19]PHAM T D,NGUYEN D T,KINI W,et al.Deep leaming-based banknote fitness classification using the reflectionimages by a visible-light one-dimensional line imagesensor[J].Sensors,2018,18(2):472.
[20]LEE J,HONG H,KIM K,et al.A survey on banknoterecognition methods by various sensors[J].Sensors,2017,17(2):313.
[21]PHAM T,LEE D,PARK K.Multi-national banknoteclassification based on visible-light line sensor andconvolutional neural network[J].Sensors,2017,17(7):1595.
[22]LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436.
[23]EVERINGHAM M,ESLAMI S M A,VAN GOOL L,et al.The PASCAL visual object classes challenge:aretrospective[J].International Journal of Computer Vision,2015,111(1):98-136.
[24]陳超,齐峰.卷积神经网络的发展及其在计算机视觉领域中的应用综述[J].日算机科学,2019,46(3):63-73.
[25]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenetclassification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012.
[26]SZEGEDY C,LIU W,JIA Y,et al.Going deeper withconvolutions[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2015.
[27]SIMONYAN K,ZISSERMAN A.Very deep convolutionalnetworks for large-scale image recognition[C]//2015International Conference on Learning Representations,2015.
[28]HE K,ZHANG X,REN S,et al.Deep residual learning forimage recognition[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2016.
[29]張荣,李伟平,莫同.深度学习研究综述[J].信息与控制,2018,47(4):385-397,410.
[30]吴帅,徐勇,赵东宁.基于深度卷积网络的目标检测综述[J].模式识别与人工智能,2018,31(4):335-346.
[31]昊加莹,杨赛,堵俊,等.自底向上的显著性目标检测研究综述[J].日算机科学,2019,46(3):48-52.
[32]ZHAO Z Q,ZHENG P,XU S,et al.Object detection withdeep learning:A review[C]//IEEE Transactions on NeuralNetworks and Learning Systems,2019.
[33]GIRSHICK R,DONAHUE J,DARRELL T,et al.Richfeature hierarchies for accurate object detection and semanticsegmentation[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition.2014.
[34]HEK,ZHANG X,REN S,et al.Spatial pyramid pooling indeep convolutional networks for visual recognition[J].IEEETransactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[35]GIRSHICK R.Fast R-CNN[C]//Proceedings of theIEEEInternational Conference on Computer Vision,2015.
[36]RUMELHART D E.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536.
[37]REN S,HE K,GIRSHICK R et al.Faster R-CNN:Towardsreal-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems,2015.
[38]REDMON J,DIVVALA S,GIRSHICK R,et al.You onlylook once:Unified,real-time object detection[C]//Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition,2016.
[39]REDMON J,FARHADI A.YOL09000:better,faster,stronger[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2017.
[40]IOFFE S,SZEGEDY C.Batch normalization:acceleratingdeep network training by reducing internal covariateshift[C]//International Conference on Machine Learning,2015.
[4]]REDMON J,FARHADI A.Yolov3:An incrementalimprovement[J].CoRR,2018.abs/1804.02767.
[42]SZEGEDY C,VANHOUCKE V,IOFFE S,et al.Rethinkingthe inception architecture for computer vision[C]//Proceedingof the IEEE Conference on Computer Vision and PatternRecognition,2016.
[43]LIU W,ANGUELOV D,ERHAN D,et al.Ssd:Single shotmultibox detector[C]//European Conference on ComputerVision,2016.
[44]LIN T Y,GOYAL P,GIRSFIICK R,et al.Focal loss for denseobject detection[C]//Proceedings of theIEEE InternationalConference on Computer Vision,2017.
[45]ZHANG S,WEN L,BIAN X,et al.Single-shot refinementneural network for object detection[C]//Proceedings of theIEEE Conference on Computer Vision and PatternRecognition,2018.
[46]葛动元,姚锡凡,向文江,等.面向齿廓偏差等精密检测的机器视觉关键技术[J].机械传动,2019,43(2):171-176.
[47]郭雪梅,刘桂雄,黄坚,等.面向标准件装配质量的PI-SURF检测区域划分技术[J].中国测试,2017,43(8):101-105.
[48]广州市银科电子有限公司.一种基于红外油墨标志智能识别的票据防伪鉴别方法:CN201710536627.2[P].2017-11-10.
[49]YOUNG P,SEUNG K,TUYEN P,et al.A high performancebanknote recognition system based on a one-dimensionalvisible light line sensor[J].Sensors,2015,15(6):14093-14115.
[50]LIU X W,LIU C Y.Paper currency CIS image fuzzyenhancement and boundary detection[J].Applied Mechanicsand Materials,2014,651-653:2356-2361.
[51]广州市银科电子有限公司.基于防伪材料光谱特性的票据鉴伪方法及装置:CN201710516001.5[P].2017-10-24.
[52]广州市银科电子有限公司一种智能识别水印特征的票据防伪鉴别方法:CN201710337615.7[P].2017-09-05.
[53]ROY A,HALDER B,GARAIN U,et al.Machine-assistedauthentication of paper currency:an experiment on Indianbanknotes[J].International Journal on Document Analysisand Recognition(IJDAR),2015,18(3):271-285.
[54]BRUNA A,FARINELLA G,GUARNERA G,et al.Forgerydetection and value identification of Euro banknotes[J].Sensors,2013,13(2):2515-2529.
[55]LIAO M,SHI B,BAI X,et al.Textboxes:A fast text detectorwith a single deep neural network[C]//Proceedings of theThirty-First AAAI Conference on Artificial Intelligence,2017.
(編辑:李刚)
收稿日期:2019-03-29;收到修改稿日期:2019-04-15
基金项目:广州市产学研重大项目(201802030006);广东省现代几何与力学计量技术重点实验室开放课题(SCMKF201801)
作者简介:刘桂雄(1968-),男,广东揭阳市人,教授,博导,主要从事测控技术及仪器研究。
