基于随机性分析的虚假趋势时间序列判别
2019-11-15李建勋马美玲郭建华严峻
李建勋 马美玲 郭建华 严峻

摘 要:针对符合一定数据模式或规律的虚假数据识别问题,提出一种基于随机性分析的虚假趋势时间序列判别方法。该方法在分析时间序列组成的基础上,首先探索虚假趋势时间序列的简单伪造和复杂伪造方式,并将其分解为虚假趋势和虚假随机两部分;然后通过基函数逼近进行时间序列虚假趋势部分的提取,采用随机性理论开展虚假随机部分的分析;最终借助单比特频数和块内频数对虚假随机部分是否具备随机性进行检测,为具有一定趋势特征的虚假时间序列的判别提供了一个解决方案。实验结果表明:该方法能够有效地分解虚假时间序列和提取虚假趋势部分,实现简单伪造数据和复杂伪造数据的判别,支持对通过观测手段或者检测设备所获取的数值型数据的真伪分析,进一步提高了虚假数据可判别范围,平均判别正确率可达74.7%。
关键词:虚假数据;时间序列;趋势性;随机性分析;基函数
中图分类号:TP399
文献标志码:A
Abstract: Focusing on the detection problem of false data that conform to a certain pattern or rule, a false trend time series detection method based on randomness analysis was proposed. Based on the analysis of time series composition, firstly the simple forgery method and complex forgery method of false trend time series were explored, and decomposed into two parts: false trendness and false randomness. Then the false trend of time series was extracted by the approximation of base function, the false random of time series was analyzed with the randomness theory. Finally, monobit frequency and frequency within a block were adopted to test whether the false random part has randomness, which established a detection method of false time series with a certain trend feature. The simulation results show that proposed method can decompose the false time series and extract the false trend part effectively, meanwhile realize thedetectionof simple and complex forged data. It also supports the authenticity analysis for the numerical data obtained by means of observation or monitoring equipment, which improves the discrimination range of false data with average detection accuracy of 74.7%.Key words: false data; time series; trend; randomness analysis; base function
0 引言
虛假数据是为了达到一种预期目标而人工伪造的带有一定虚假价值的数据,它的存在严重影响了数据分析结果,并给数据处理、信息安全、资源利用、控制决策等工作带来了巨大威胁。随着大数据时代的到来,信息资源的利用频率急剧增长,虚假数据分析作为改善数据质量、提高管控能力、增强安全性、提升数据价值的关键环节愈来愈被人们所重视,众多学者更是从网络服务、控制系统、多媒体信息等视角开展了虚假数据识别的研究。在网络服务方面,已有大量文献探讨了虚假评论、虚假消息、虚假账户等问题,典型的有:王琢等[1]基于评论图的虚假评论人检测方法,李雨桥等[2]利用社交图谱的虚假评论识别方法,以及Xiao等[3]的在线社会网络虚假账户检测方法。考虑到无法通过先验知识有效识别虚假评论,任亚峰等[4]采用狄利克雷过程混合模型和多核学习算法提高了真假数据的分类能力。段大高等[5]还提出了一种决策树方案,提高了微博虚假消息检测的准确率。针对虚假新闻,Shu等[6]开展了在线媒体大数据的分析工作,并利用数据挖掘构建了社会媒体中虚假新闻的检测方案。另外,Singh等[7]还利用机器学习方法实现了在线社会网络虚假资料的识别。此类研究分别从特征设计、模型方法、数据集、评级指标等方面,良好地解决了虚假评论文本、虚假评论发布者及虚假评论群组的分析与辨别问题[8]。在控制系统方面,相关研究主要是针对传感器网络和电力系统中的攻击性虚假数据的检测与处理,如李素君等[9]提出的传感器中鲁棒性虚假数据识别与过滤方案,曹燕华等[10]基于信任管理的虚假数据检测方案。考虑到协作伪造的检测难度,刘志雄等[11]提出了一种基于双重认证和位置关系校验的虚假数据过滤策略。聚焦于电力系统的稳定性,Ashok等[12]则给出了电力系统中虚假生物特征的检测方法。另外,Khalaf等[13]还面向自动控制系统建立了基于卡尔曼滤波器的虚假数据注入检测算法。在多媒体信息方面,针对于空间轨迹信息处理,杨斌等[14]探索了基于聚类思想的虚假轨迹分析方法。在图像信息上,Vigneshwaran等[15]则给出了一种基于支持向量机(Support Vector Machine,SVM)的虚假图像检测体系。另外,操文成[16]面向语音数据,设计了一种以峰度统计矩阵为基础的语音音调篡改盲检测算法。除此而外,Galbally等[17-18]研究了应用于虹膜、指纹等虚假生物特征的检测方法,给出了面向服务系统安全的虚假数据判别方案。
综上所述,经过多年的研究,人们已经充分认识了虚假数据的产生机理,并从数据模型、数据应用、数据安全等视角分析了虚假数据特征,建立了多种类、多场景的虚假数据判别方案。然而,此类研究的重点是探索特定应用环境、安全需求和处理目标的虚假数据识别、过滤、分析等问题,缺乏对符合一定数据模式或规律的虚假数据的研究,仅有部分学者采用数理统计、语义模型、特征提取、变换域分析等开展了部分研究工作,对于通过观测手段或者检测设备所获取的数值型数据的讨论则更为匮乏。此类数据通常表现为具有一般性的趋势性时间序列,为了有效甄别其真伪,本文在虚假趋势时间序列的虚假趋势和虚假随机分解的基础上,利用随机性检测,构建了一个虚假趋势时间序列的判别方法,支撑了相关数据伪造行为的甄别以及数据质量的提升。
1 虚假趋势时间序列分析
时间序列是按照时间顺序记录的社会经济、自然现象的数量指标,其数值随时间发展变化,起伏不定,具备某种趋势。通常时间序列可表示为x*t(t=0,1,…,n),并由长期趋势量d*、季节变动量s*、周期变动量c*、随机变动量r*四个部分构成,亦即x*t= f(d*t,s*t,c*t,r*t),t=0,1,…,n,并可分解为x*t=d*t+s*t+c*t+r*t。当被测对象依时间变化呈现某种上升或下降态势,且没有明显的季节波动、周期变动时,时间序列简化为一种趋势时间序列x*t=d*t+r*t,此时可构造一个合适的函数曲线反映这种变化趋势。虚假趋势时间序列则是指为了到达商业欺诈、掩蓋事实等目的,由不诚信者在已知历史数据资料基础上伪造的趋势时间序列,以实现恶意的利益诉求。虚假趋势时间序列类似趋势时间序列,也包含长期趋势量和随机变动量两部分,但这两部分中至少一部分是虚假的。对虚假趋势时间序列进行分析,就是探索该虚假序列的长期趋势量和随机变动量的构建动机和方法,以便通过相应检测手段予以甄别。
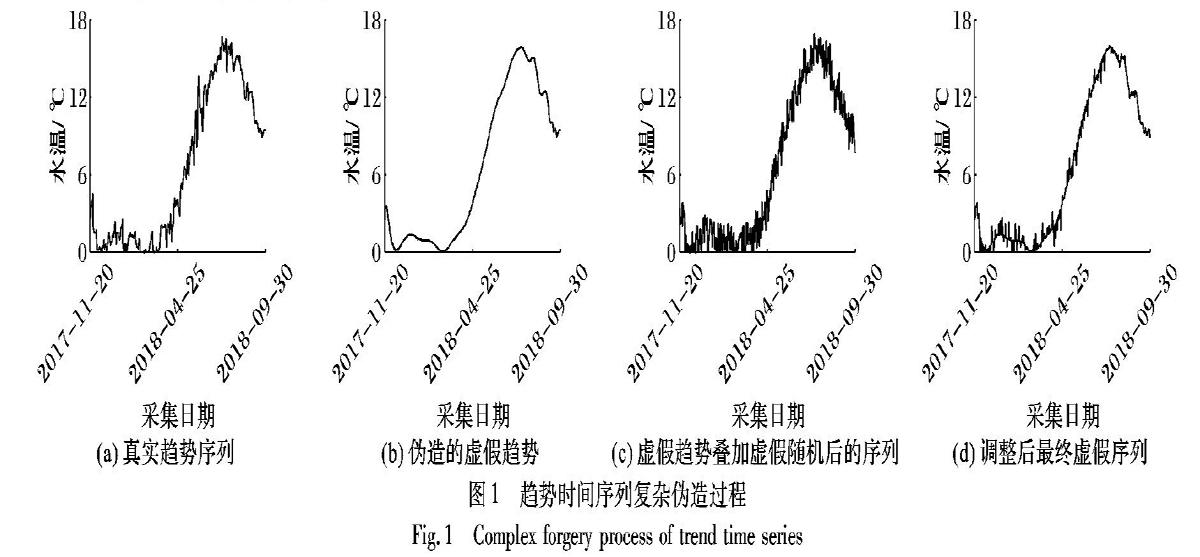
虚假趋势时间序列并不是观测得到的真实数据,而通常由伪造者按照某一企图而构建。为了便于区分不同伪造能力,此处将伪造者分为简单伪造者和复杂伪造者两类。其中,简单伪造者大多对照历史数据凭借个人经验以及预期目标估计出一系列虚假数值xt。受限于人工的编制效率和构造能力,一般来说序列xt仅部分含有虚假随机成分rt,因此主要体现为对虚假趋势时间序列中随机变动量的一种简单伪造。而复杂伪造者则运用程序算法按照预期目标构造一个虚假趋势dt,然后再按照随机生成规则构造虚假随机rt,并将其叠加到dt上,因此体现为对虚假趋势时间序列中长期趋势量和随机变动量两部分的复杂伪造。如图1所示,依照来自美国加州米克斯湾(Meeks Bay;经纬度-120.11,39.05;编号:10336645)水质数据库的水温真实序列图1(a),手工给出伪造目标趋势的关键点位并进行样条插值获得一个虚假趋势图1(b),然后将均匀分布的随机数据叠加到该虚假趋势上,最后为了增强虚假数据的逼真性,对图1(c)手工调整获得最终伪造序列如图1(d)。
无论是简单伪造者还是复杂伪造者,其目标均是按照恶意预期构造一个xt=dt+rt来虚假表示真值x*t。然而由于真值通常未知或被隐藏,故而只能通过构成虚假趋势时间序列xt的虚假趋势dt和虚假随机rt两部分加以分析:
1)虚假趋势。虚假趋势dt是虚假趋势时间序列中的长期趋势量部分。它是由伪造者参考历史数据、背景信息、经验估算、推演分析等,按照预期目标建立且类似于真实的序列。通常在未知d*t的情况下难以辨别真伪,而只有在虚假序列出现违背常理、突发跳跃等时可通过M-K等突变检测加以判别,或者在特定滑动窗口下通过与历史数据之间的相似性分析来加以初判,因此采用虚假趋势甄别序列的真伪并不具有代表性。
2)虚假随机。虚假随机rt是虚假趋势时间序列中的随机变动量部分。通常,自然的数据序列受到观测手段、周边环境等多种因素影响势必带有以误差为主要特征的随机信息,它也体现为被测数据量受到各种偶然因素影响而呈现出方向不定、时起时伏、时大时小的变动。简单伪造者往往通过简单推理计算、数值估计形成带有部分虚假随机特性的虚假趋势时间序列xt,由于其随机变动量部分伪造方法过于简单,难以满足自然的随机特征,故可以通过随机性检测来判别真伪。而对于复杂伪造者而言,虽然可以通过各种算法构造出满足随机规律的rt,但将其叠加到dt后就必然导致了数据量的改变,原本的趋势性受到rt的影响在部分时刻将无法保证预期目标,或呈现出不符合伪造者意图的起伏变化,因此需要对叠加后的序列进行手工调整,然而这种调整却往往会打破序列的随机性,故而可以通过分析该部分的随机性检测来判别趋势时间序列的真伪。
2 趋势时间序列的趋势抽取
考虑到虚假趋势难以识别,而虚假随机又融合在虚假趋势内形成虚假序列,可见判别虚假趋势时间序列的首要工作便是从假定存在虚假数据的xt=dt+rt中,剔除趋势性部分dt。如果从数据观测角度来看,趋势时间序列由具有趋势变化的真值部分和误差部分构成,而真值和误差恰好分别对应序列的趋势部分和随机部分。因此对于虚假序列来说,一个可行的抽取方案是探寻能够表征xt趋势的逼近函数ψ(t),让ψ(t)最大限度地符合虚假趋势数据dt,而剩余的误差部分xt-ψ(t)则作为序列中的随机量。为了增强逼近效果、减少时间t自然增长对数据分析的干扰,首先采用Min-Max标准化方法(t-tmin)/(tmax-tmin)将t标准化至区间[0,1],而xt的标号t保持不变,然后给定线性无关基函数集合Θ=span{ψ0(t),ψ1(t),…,ψm(t)},对于虚假趋势时间序列xt若获得一个由基函数和待定系数b^0,b^1,…,b^m所构成的线性组合(t)=b^0ψ0(t)+b^1ψ1(t)+…+b^mψm(t),使得(t)满足∑nt=0((t)-xt)2=minx(t)∈Θ∑nt=0(x(t)-xt)2,则称(t)为曲线簇Θ上序列xt的最佳趋势。此处,待定系数b^0,b^1,…,b^m可通过多元函数J(b0,b1,…,bm)=∑nt=0(x(t)-xt)2的最小值求得。令b^=(b^0,b^1,…,b^m)T,=(x0,x1,…,xn)T,按照极值必要条件J(b0,b1,…,bm)bi=0(i=0,1,…,m),则可以得到:
3 虚假随机数据的真伪判别
真实序列的随机部分是随着偶然因素影响而改变的随机过程,或者在测量、观察过程中因某些不可控制因素影响而造成的变化,具备明显的随机特征。虚假随机则是由人工编制结合程序算法构造,不完全具有随机特征。另外,考虑到对于一个随机事件可以探讨其可能出现的概率来反映该事件发生可能性大小,因此要检测趋势时间序列的真伪,则只需要检查序列的随机部分是否符合随机性要求。此处,借助随机性检测最为常用的单比特频数检测和块内频数检测作为虚假趋势时间序列的判别方案。通过单比特频数检测确保随机部分rt中0、1比特的数量大致相同,通过块内频数检测确保将随机部分rt分组长度为k的子序列中1所占的比例接近于整体的1/2。频数测试是随机性分析的基础方法,应首先进行。
4 实验与分析
为了验证本文方法的有效性和实用性,使用来自USGS(U.S. Geological Survey)[19] 美国加州2016年10月9日至2018年10月9日的水质数据作为参考开展分析。选择该区域内3108个测站中信息资源丰富的513个测站,从中提取测站名、测站编号、测站地理位置等基本信息,以及与水质相关的水温、电导率、 pH值、硝酸盐、总磷、铁、悬浮物、浑浊度、溶解氧、氯化物、输沙量、叶绿素等12项观测量,共计66081条数据记录,数据采集时间间隔为24h。为了避免人为因素导致的分析误差,虚假数据依靠实测数据进行编制。编制时,采用简单伪造和复杂伪造两种方案,即模拟简单伪造者和复杂伪造者两种来构建虚假趋势时间序列。其中:简单伪造根据历史数据资料、预期目标、个人经验直接编制出每个时刻的数据值;而复杂伪造则首先给出符合预期目标的关键数据点位,绘制出趋势曲线,然后通过计算机模拟产生幅度在10%历史数据最大值范围内的随机数据,并将其叠加到趋势曲线上,最后手动调整各数据点位使之呈现出逼真于历史数据的曲线过程。为了便于描述,本文将通过简单伪造和复杂伪造两种方案构建的虚假趋势时间序列分别简称为简单伪造序列和复杂伪造序列,在其上开展实验如下。
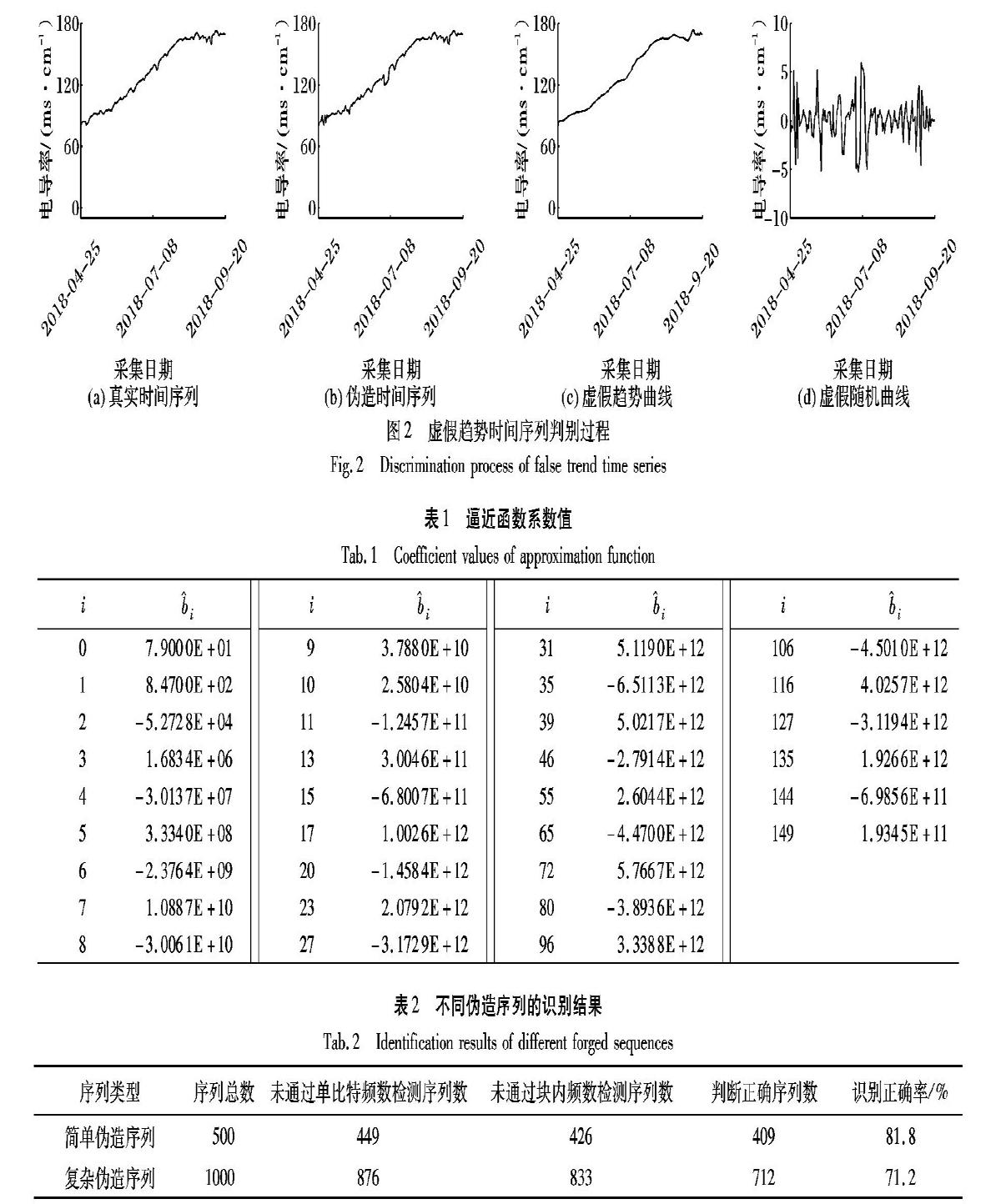
1)以加州波特维尔测站(Porterville,经纬度:-118.65,36.05,编号:11203580)的电导率数据为基础,在2018年4月25日— 9月20日之间产生n=149个数据点,形成复杂伪造序列。该时间段实测数据如图2(a)所示,伪造数据预期目标与实测数据相同,即虚假序列的趋势沿用实测序列,伪造随机部分使用计算机产生10%幅度内的均匀分布随机数,将该随机部分叠加到趋势部分并进行人工调整后得到虚假序列如图2(b)所示。令基函数表示为Θ=span{1,t,t2,…,t149},采用式(1)
进行虚假趋势提取得到待定系数{b^0,b^1,…,b^149}如表1所示(未给出的b^i值为0),绘制虚假趋势部分曲线如图2(c)所示,与图2(b)比较可见其有效地表征了原本数据的趋势部分,剔除虚假趋势后得到虚假随机部分如图2(d)所示。观察曲线可知该部分并无趋势规则,似乎符合一定随机特征,其随机部分处于[-5.266,5.964]范围内,均值为5.290×10-5。令k=20,α=0.1,得到h=7,根据式(3)、(4)求得V1=1.7204, p1-value=0.085,V2=2.600, p2-value=0.081,可见p1-value和p2-value均小于α=0.1,因此未通过测试,故而判断为虚假数据,这说明本文方法能够有效识别虚假趋势时间序列。
2)依照美国加利福尼亚州区域的513个水质测站数据,简单伪造序列500组,复杂伪造序列1000組。
分别对每组数据采用本文方法进行测试,获得结果如表2所示。判断简单伪造序列的正确率为81.8%,而对于复杂伪造序列而言则为71.2%。综合两种序列其整体判断正确率为74.7%。由此可见,本文方法在判断人工根据预期目标构造的趋势时间序列时具有相对更高的准确率,而对复杂伪造序列判断正确率较弱,这是复杂伪造者为了增强序列的随机性而使用了模拟算法生成一定分布随机数据的缘故。
5 结语
虚假数据的检测与分析一直在改善数据质量、提高系统能力、保障信息安全等方面占据重要地位,并随着大数据技术的不断发展和数据资源使用频率的增加,成为了信息技术领域的研究热点。为了实现对具有一定趋势性特征的虚假时间序列的判别,本文在探讨虚假趋势时间序列构成的基础上,给出了一个采用基函数逼近的虚假序列分解方案,将其划分为虚假趋势和虚假随机两部分,并采用随机性分析对虚假随机部分加以检测,形成了虚假趋势时间序列的判别方法。实验结果表明,该方法能够有效地检测出简单伪造序列和复杂伪造序列,判别正确率分别为81.8%和71.2%。考虑到复杂伪造序列往往和历史数据之间关系密切,因此下一步的工作任务主要是尝试增加相似性分析,进一步提高虚假趋势提取精度,进而提升判别正确率。
参考文献(References)
[1] 王琢, 李准, 徐野, 等. 基于评论图的虚假产品评论人的检测[J]. 计算机科学, 2014, 41(10): 295-299, 305. (WANG Z, LI Z, XU Y, et al. Detecting product review spammers based on review graphs[J]. Computer Science, 2014, 41(10): 295-299, 305.)
[2] 李雨桥, 符红光. 基于社交图谱模型的虚假评论识别[J]. 计算机应用, 2014, 34(S2): 151-153. (LI Y Q, FU H G. Fake comments recognition based on social network graph model[J]. Journal of Computer Applications, 2014, 34(S2): 151-153.)
[3] XIAO C, FREEMAN D M, HWA T. Detecting clusters of fake accounts in online social networks[C]// Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security. New York: ACM, 2015: 91-101.
[4] 任亞峰, 姬东鸿, 张红斌, 等. 基于PU学习算法的虚假评论识别研究[J]. 计算机研究与发展, 2015, 52(3): 639-648. (REN Y F, JI D H, ZHANG H B, et al. Deceptive reviews detection based on positive and unlabeled learning[J]. Journal of Computer Research and Development, 2015, 52(3): 639-648.)
[5] 段大高, 盖新新, 韩忠明, 等. 基于梯度提升决策树的微博虚假消息检测[J]. 计算机应用, 2018, 38(2): 410-414. (DUAN D G, GAI X X, HAN Z M, et al. Micro-blog misinformation detection based on gradient boost decision tree[J]. Journal of Computer Applications, 2018, 38(2): 410-414.)
[6] SHU K, SLIVA A, WANG S, et al. Fake news detection on social media: a data mining perspective[J]. ACM SIGKDD Explorations Newsletter, 2017, 19(1): 22-36.
[7] SINGH N, SHARMA T, THAKRAL A, et al. Detection of fake profile in online social networks using machine learning[C]// Proceedings of the 2018 International Conference on Advances in Computing and Communication Engineering. Piscataway: IEEE, 2018: 231-234.
[8] 李璐旸, 秦兵, 刘挺. 虚假评论检测研究综述[J]. 计算机学报, 2018, 41(4): 946-968. (LI L Y, QIN B, LIU T. Survey on fake review detection research[J]. Chinese Journal of Computers, 2018, 41(4): 946-968.)
[9] 李素君, 周波清, 羊四清. 传感器网络中鲁棒性虚假数据过滤方案[J]. 计算机工程与应用, 2012, 48(35): 67-70, 232. (LI S J, ZHOU B Q, YANG S Q. Robust filtering false data scheme in sensor networks[J]. Computer Engineering and Applications, 2012, 48(35): 67-70, 232.)
[10] 曹燕华, 章志明, 余敏. 基于信任管理机制的无线传感器网络虚假数据过滤方案[J]. 计算机应用, 2014, 34(6): 1567-1572. (CAO Y H, ZHANG Z M, YU M. False data filtering scheme based on trust management mechanism in wireless sensor networks[J]. Journal of Computer Applications, 2014, 34(6): 1567-1572.)
[11] 刘志雄, 黎梨苗. 传感器网络中一种基于双重认证的虚假数据过滤方案[J]. 小型微型计算机系统, 2018, 39(6): 1276-1280. (LIU Z X, LI L M. Dual authentication based false report filtering in sensor networks[J]. Journal of Chinese Computer Systems, 2018, 39(6): 1276-1280.)
[12] ASHOK A, GOVINDARASU M, AJJARAPU V. Online detection of stealthy false data injection attacks in power system state estimation[J]. IEEE Transactions on Smart Grid, 2018, 9(3): 1636-1646.
[13] KHALAF M, YOUSSEF A, EL-SAADANY E. Detection of false data injection in automatic generation control systems using Kalman filter[C]// Proceedings of the 2007 IEEE Electrical Power and Energy Conference. Piscataway: IEEE, 2017: 1-6.
[14] 楊斌, 陆余良, 杨国正, 等. 一种基于聚类的路径伪造检测方法[J]. 计算机科学, 2014, 41(8): 158-163. (YANG B, LU Y L, YANG G Z, et al, Path forging detection approach based on aggregation[J]. Computer Science, 2014, 41(8): 158-163.)
[15] VIGNESHWARAN S, SURESH M, MEENAKUMARI R. An SVM based statistical image quality assessment for fake biometric detection[J]. International Journal for Trends in Engineering & Technology, 2015, 4(1): 5-12.
[16] 操文成. 语音伪造盲检测技术研究[D]. 成都: 西南交通大学, 2017: 1-38. (CAO W C. Research on blind speech forgery detection technology[D]. Chengdu: Southwest Jiaotong University, 2017: 1-38.)
[17] GALBALLY J, MARCEL S, FIERREZ J. Image quality assessment for fake biometric detection: application to iris, fingerprint, and face recognition[J]. IEEE Transactions on Image Processing, 2014, 23(2): 710-724.
[18] KULKARNI N A, SANKPAL L J. Efficient approach determination for fake biometric detection[C]// Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation. Piscataway: IEEE, 2017: 1-4.
[19] USGS water data support team. USGS water data for the nation help [EB/OL]. [2018-10-9]. https://www.usgs.gov/ products/ data-and-tools/ real-time-dat.
