分布式环境下多关键词并行密文检索方案
2019-11-15戴厚乐杨庚闵兆娥
戴厚乐 杨庚 闵兆娥

摘 要:对于可搜索加密需要均衡数据的安全性和检索效率。针对SSE-1密文检索方案中检索性能低、单关键词检索模式不足和传统单服务器架构中的单机资源局限性等问题,设计并实现了一种多关键词并行密文检索系统。该系统采用不同的索引加密方式提高密文检索性能;通过对密文倒排索引的切分实现倒排索引的分块检索,克服了单机资源的局限性并提高了检索效率;通过结合分布式特点扩展了传统单机检索架构并实现了多关键词的并行检索。实验结果表明,与SSE-1方案相比,在保证密文数据安全性的前提下所提方案能够提高检索、更新等操作的效率,实现多关键词的检索,同时动态扩展系统分布式架构以提高系统负载能力。
关键词: 可搜索加密;多关键词;分布式检索;倒排索引;索引切分
中图分类号:TP309.2
文献标志码:A
Abstract: For searchable encryption, balancing the security and retrieval efficiency of data is important. Aiming at the low retrieval performance and the lack of single keyword search mode in SSE-1 ciphertext retrieval scheme, and the problems such as the limitation of single-machine resources in the traditional single-server architecture, a multi-keyword parallel ciphertext retrieval system was designed and implemented. Different index encryption strategies were used to improve the ciphertext retrieval performance. The block search of the inverted index was realized by partitioning the ciphertext inverted index, which solves the limitation of single-machine resources and improves the retrieval efficiency. The traditional single-machine retrieval architecture was extended and the parallel retrieval of multiple keywords was realized by combining the characteristic of distribution. Experimental results show that compared with the SSE-1 scheme, the proposed scheme has the efficiency of retrieval and update operations improved under the premise of ensuring ciphertext data security and realizes multi-keyword retrieval. At the same time, the distributed architecture of the system is dynamically expanded to improve the system load capacity.
Key words: searchable encryption; multi-keyword; distributed search; inverted index; index partition
0 引言
隨着信息技术的发展,人们在日常生活和工作中产生和使用的数据规模不断增大。数据量由PB的规模向着EB和ZB的规模发展。为了能够从海量的数据中高效地筛选出有意义的数据,文件检索技术得到了广泛的应用。近年来,数据规模的爆发式增长导致用户本地的计算和存储资源已经无法满足对庞大数据量的存储和管理需求。由于云服务方便、快捷和灵活的特点,越来越多的用户选择将本地的数据迁移到云端存储和管理[1],以此来节省本地数据管理开销。然而由于云服务的开放性、分布性等特性,数据脱离了用户的物理控制而存储在云端,使得数据的安全性和隐私性问题日益突出,大数据的安全性越来越受到关注和重视[2-3]。数据加密存储可以在一定程度上保证数据的安全隐私[4],但加密数据使得检索操作变得十分困难[5-7]。为了在保证数据安全性和用户隐私的基础上实现数据的检索操作,可搜索加密技术(Searchable Encryption,SE)应运而生。
可搜索加密作为当前隐私保护机制之一,得到了广泛的研究和应用。针对非结构化数据的可搜索加密,基于构造索引的SE方案[8]能够高效地支持关键词检索,因而成为了SE方案的主要构造策略。在开放系统中,由用户或者可信第三方生成文档的索引,并将密文数据和密文索引上传至服务器。用户通过检索安全索引获得目标文档,整个检索过程是在不解密文档数据和索引文件的情况下进行的。因此,基于索引的可搜索加密方案既保证了密文数据的安全性,又利用索引实现了数据的高效可检索性。近年来,倒排索引作为最高效的索引结构之一,由于其高效的检索特性被广泛应用于明文数据的检索。同时,倒排索引结构在一定程度上能够节省磁盘空间,提高检索效率,并且支持增量更新和删除。因此,基于倒排索引的可搜索加密方案[13-15]也已成为目前主要的可搜索加密方案之一。
尽管基于倒排索引的可搜索加密方案具备一定的优势,但该方案仍然存在着一些明显的不足:一方面是SSE-1方案中的局限性。方案中对索引指针加密导致检索过程中产生过多的计算量影响了检索性能,同时单关键词的检索模式已无法满足用户的检索需求。另一方面是单机资源的局限性。当索引文件的规模随着数据量的增长而增长,索引可检索数据规模受限于单机内存资源,检索效率受限于单机计算资源。最后是倒排索引结构的局限性:对于多关键词的检索请求,倒排索引结构的串行检索,严重影响了多关键词的检索效率。
针对上述不足,本文使用了不同的索引加密方式,扩展了传统的单服务器模型架构,设计并实现了一种基于倒排索引的多关键词并行检索的可搜索加密方案。在本文方案中设计了倒排索引的分布式管理和检索架构,相较于传统的单机模型架构,这种架构模型能够提高单机资源的有效利用率,具有良好的可扩展性,能避免可检索数据规模的局限性问题。同时,本文方案能够在一定程度上实现多关键词的并行检索,弥补倒排索引结构在多关键词检索效率中的不足。
1 相关工作
可搜索加密技术不仅仅实现了密文数据的可檢索性,同时丰富了密文数据的检索形式、检索结构和用户管理等功能以满足更加安全、精准、高效的检索需求。2000年,文献[9]首次研究了可搜索加密问题,并且提出了SWP的线性密文扫描方案。
虽然该方案能够基本上实现单词搜索,但该方案需要通过对所有文档进行线性扫描,造成的开销与文件大小呈线性关系,因而其检索效率低下。针对文献[9]中提出的SE方案检索效率低下等缺陷,后续的加密可搜索方案通常是构建一个安全的可搜索索引,通过密钥生成匹配索引的陷门,用陷门匹配隐藏在云端的索引内容从而获得密文的检索结果。基于这一思想,文献[10]设计了新的索引结构,而文献[13-15]则基于倒排索引构建了安全索引结构。2003年,文献[10]提出了一种基于安全索引的Z-IDX方案来快速实现对海量密文数据的搜索。文献[11]使用布隆过滤器(Bloom Filter)构建每篇文档的索引。该方案虽然具有高效检索的优点,但是由于Hash函数具有碰撞性(Collision)导致此方案存在误识别。针对这一问题,文献[12]提出了一种安全性定义和结构的替代方案,这一方案弥补了误码率的缺陷。2006年,文献[13]规范化了对称可搜索加密(Symmetric Searchable Encryption, SSE)及其安全目标,首次提出了基于倒排索引的加密可搜索方案。该方案中每个关键词对应的文档列表都要经过加密和模糊处理成一个数组;但是关键词检索之后,对应的倒排列表的位置和内容将暴露给云服务器。因此在重新生成索引之前,一个关键词只能检索一次。基于文献[13]方案的不足,文献[15]中提出了动态可搜索加密的概念,并构建了一个加密的反向索引,支持动态操作,如文档更新等。2016年,文献[16]中提出了一个可以动态进行文件的增、删、改、查的多关键词检索方案。
早期的SE机制只能支持单个关键词的检索,因此这些方案具有相同的局限性:不支持联合多关键字检索。为了对查询方式进行扩展实现更精确的查询,文献[17]分别基于对称密码学和公钥密码学提出了两种实现连接关键字搜索的高效SE机制,但是都需要保证检索请求中没有重复的关键字。在基于对称密码学的SE机制中,要求陷门的大小和文件数量呈线性关系。而基于公钥密码学的SE机制,通过使用双线性映射使得陷门的大小固定,解决了这个问题。之后,文献[18]的工作能够让服务器在多关键词检索的基础上,根据每个文件对于所请求关键字的相关度排序,并将相关度最高的k个文件返回给用户,实现更准确的检索。2017年,文献[19]中引入加权平均分的概念,对文件中不同区域的关键词设置不同的权重表示重要程度,针对文献[18]方案的不足,提出了更加高效的多关键词排序检索方案。对于多关键词的检索除了相关度排序查询,文献[19-21]中提出的模糊查询也是可搜索加密研究的重要的一部分。为了丰富可搜索加密方案的应用场景,文献[22-24]中对于多用户共享场景的密文检索提出了相关方案。
上述方案都是基于单服务器模型架构的SE机制,随着索引文件规模的增大,单服务器架构模型的内存、计算资源已经不能满足如今庞大的数据量的检索和管理,导致检索效率降低。2016年,文献[25]中提出了对于并行密文倒排索引的相关研究,利用分布式框架在服务器端并行构建密文倒排索引。虽然提高了索引构建和检索效率,但密文索引构建过程中将明文数据和密钥暴露给服务器,缺乏安全性;并且检索模式为单用户单关键字,应用场景具有局限性。同时对于多关键词的检索方案,更加严重的影响了检索效率。针对这一问题,多关键字的并行可搜索加密方案成为热点研究方向。2013年,文献[26]在文献[15]方案的基础上,引入了红黑树结构作为索引结构,使动态的SSE能够支持多处理器的并行检索。
针对基于倒排索引结构的多关键词检索效率问题,本文提出了一种分布式并行检索方案,从计算机资源的局限性和数据检索的安全性出发,充分利用有限的单机计算和内存资源实现数据检索规模的扩展和检索效率的优化。
2 分布式多关键词并行密文检索方案设计
云端数据规模的急剧增长严重影响了密文数据的检索效率,而单服务器模型架构的可搜索加密方案由于单机资源的局限性已经无法适用于大数据环境下的密文检索。在此基础上,本章利用倒排索引切分和分布式模型架构实现了分布式环境下多关键词并行密文检索方案。利用分布式平台实现可搜索加密模型架构的扩展,提高多关键词检索的效率。
分布式多关键词并行密文检索系统结构如图1所示,该方案基于倒排索引的检索结构实现,由客户端、服务器端组成,服务器端包含了一个主节点和多个分布式从节点。客户端构建密文索引、提交检索请求;服务器端实现索引的分布式管理和检索。其中服务器主节点切分索引和检索请求,并将子索引和子请求分发至分布式平台各个从节点,交由各个从节点实现索引的管理和检索。各从节点将检索结果交由主节点处理结果集,主节点将处理结果返回给客户端。
对于多关键词的检索请求,依据关键词切分成多个独立且不重叠的检索请求,分发检索请求至相应分布式节点实现并行检索。为了实现倒排索引的分布式管理,需要完成四个步骤:用户端基于对称密钥构建密文倒排索引与数据加密;提交密文倒排索引与密文数据至服务端主节点;服务器端主节点将密文倒排索引切分成多个完整且独立的子索引;分发子索引由各个计算节点分布管理。
2.1 倒排索引构建与加密
在本文检索方案中,利用倒排索引实现高效的检索。为了保证数据的安全传输与检索,在上传数据和索引文件之前需要完成两个操作:一是用户在客户端对待上传的文档数据构建倒排索引;二是在上传数据之前,利用本地密钥对文档数据和索引文件进行加密。
2.1.1 倒排索引
倒排索引由词典(Lexicon)和倒排列表文件(Inverted Lists)构成。词典中保存了所有的关键词以及指向倒排列表的逻辑指针和其他一些信息。倒排列表由包含了关键词的所有文档标识构成。通过查找词典,找到对应检索关键词的逻辑指针,遍历相关倒排列表即可获取目标文档。倒排索引结构如图2所示。
从倒排索引的结构来看,攻击者很可能通过词典文件的关键词和倒排列表的文档标识等索引信息来重现整个文档的内容。为了保证数据检索的安全性,必须要对倒排索引文件进行加密上传。
2.1.2 倒排索引加密
针对明文倒排索引的安全性威胁,需要将倒排索引加密上传,从而保证密文数据检索的安全性。基于数组、链表、查找表等一些数据结构,对于索引文件的加密,要利用对称加密将索引加密形成安全倒排索引,从而在不改变索引结构的基础上对文档相关信息加密,隐藏索引中的信息,以此实现密文数据的检索。密文倒排索引的结构如图3所示。
En(term)对词典的加密是对词典中的关键词进行加密,对于索引中关键词与到排列表的关联指针不加密;
En(post)对于到排列表的加密是对到排列表中的每一个倒排项的信息进行加密,对于到排列表中的指针信息不加密。
虽然密文倒排索引文件保证了检索过程中数据的安全性,但数据量的增长和索引的加密都会造成索引文件规模的增长,导致内存与计算资源影响和限制了检索效率;所以对于大规模密文数据的检索,有必要实现索引文件的分布式管理和检索。
2.1.3 密文倒排索引的构建算法
Luence是一个全文检索引擎的架构,提供了完整的查询引擎、索引引擎和部分文本分析引擎,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和检索。本文利用Luence实现文本数据的倒排索引的构建与数据检索,并在此基础上利用加密处理构建密文倒排索引。
2.2 倒排索引的切分与分发
针对大规模索引文件中单机资源的局限性,将倒排索引切分成多个子索引,实现索引文件的分布式管理和检索。每一个计算节点负责一部分索引文件,可以在有限的单机计算机资源的基础上扩展检索的数据规模和提高系统负载能力,从而充分提高单机内存和计算资源的有效利用率。为了实现索引文件分布式管理,需要完成兩个操作:一是将整体的密文倒排索引依据关键词切分成多个完整且独立的子索引;二是将子索引分发至各个分布式节点。
2.2.1 密文索引切分算法
1)计算切分标准。
计算倒排索引文件中所有倒排列表Pi(1≤i≤n)中包含的倒排项p的总数量,根据式(1)计算出每一个子索引中包含的倒排项的数量,以确定切分标准。
2)词典切分。
以SLoad(Sm)为切分标准,依据关键词有序编号和对应倒排列表中的倒排项的数量|Pi|,根据式(2)将词典中的关键词顺序切分成k个集合,构成k个关键词词典。
3)倒排列表切分。
依据对词典关键词的切分方案和关键词ti与倒排列表Pi的映射关系,实现对倒排列表文件的范围切分。
2.2.2 子索引分发
依据对词典关键词的与倒排列表的切分,得到k个完整且相互独立的子索引集合{Enkey(Ω1),Enkey(Ω2),…,Enkey(Ωk)}。索引切分示意图如图4所示。图4中的每行ti代表一个关键词,每列dj代表一个文档,包含关键词ti的文档集合组成了ti的倒排列表。
2.3 数据检索
密文倒排索引的切分与分发实现了索引文件的分布式管理,为了实现完整的多关键词分布式检索,需要完成三个操作:一是对用户提交的多关键词检索请求切分并封装成与子索引对应的多个子检索请求;二是将子检索请求分发至管理对应子索引的节点,实现数据的分布式检索,并将结果集交由主节点进行相关度处理后返回给用户;三是用户端收到检索结果后,对结果集解密,得到明文数据。用户检索流程如图5所示。
2.3.1 多关键词检索请求划分算法
1)切分检索请求,将用户提交的检索请求依据其中检索词顺序分解成多个独立的密文关键词td。
2)关键词匹配,依据词典中关键词的切分方案,计算并确定该关键词td所属的子索引文件Ωj,其中1≤ j≤k,并将所属相同子索引的检索词组合成检索词集合。
3)封装检索词子集,为每一个检索关键词匹配好子索引之后,将各个检索词集合再封装成子检索请求Qi={tdi1,tdi2,…,tdim},得到子检索请求集合{Q1,Q2,…,Qk}。其中:Qi是与子索引Ωi对应的子检索请求;tdim表示子检索请求Qi中的第m个密文检索词。
4)分发检索请求,检索请求切分好之后,主节点将各个子检索请求独立地分发至对应子索引的分布式节点。
2.3.2 分布式检索算法
定义4 Ri是第i个节点的检索结果集,dim是第i个节点的结果集中的第m篇检索结果文档。
算法4 分布式检索算法。
输入 子检索请求Qi。
输出 检索结果集R。
2)各个分布式节点得到检索结果后,将检索结果Ri={di1,di2,…,dim}回送至主节点。主节点接收到各节点检索结果集集合{R1,R2,…,Rk}后,对结果集取交集操作,得到用户检索请求Q的最终检索结果集R。
3)回传检索结果,主节点取得最终检索结果集后,将结果集回传至客户端。
2.3.3 数据解密
用户收到检索得到的密文检索结果集数据后,利用密钥对数据解密,得到明文数据。
2.4 系统可行性分析
由于密文索引构建过程的计算量较大,需要通过并行计算提高索引构建效率。传统方案是将数据上传至服务器端利用分布式平台构建索引,虽然能够提高效率,但是需要提供可信的第三方服务器和安全的通信信道以保证数据安全。本文选择在客户端进行索引的构建和加密,基于新的加密方案和检索方案,使得系统更具有优势。系统的可行性和优势主要体现在以下几个方面:
1)客户端构建索引和加密能够在分散服务器端集中构建密文索引的计算量的同时保证明文数据不对外暴露,保证了数据的安全性,不需要提供可信的第三方服务器和通信信道。2)本文中的索引加密方案在构建过程中只对词典中关键词信息和倒排项中相关文档信息加密,保留了倒排索引的索引结构,在密文索引的检索过程中不需要同SSE-1方案中一样进行相关解密操作,保证了倒排索引切分方案的可行性,并且使得倒排索引的检索优势得以体现。3)索引切分和检索请求的切分算法使得各个子索引和检索词之间相互独立,多关键词的检索请求能够在不同的子索引上并行独立地检索,避免多关键词耦合造成的重复性计算。服务器端将检索任务的调度和检索过程的计算解耦。由于检索的独立性和并行性等特性使得多关键词的检索效率提高,系统结构便于随着数据量的增长而扩展。
3 系统实现及性能分析
本文首先在单机模型架构中对比了SSE-1方案与本文方案中索引加密方案的检索效率;单索引检索方案和切分多索引检索方案在单关键词下的密文检索效率。同时对比了两种方案下,每个索引文件大小随着数据量增长的变化趋势。之后在分布式模型架构中实现了多关键词的分布式检索方案,对比了不同数量的检索词的检索效率,验证了本文提出的分布式方案的可行性。
3.1 实验平台
本文基于Luence4.10实现了密文倒排索引的构建和检索,数据和索引使用AES对称加密,系统编程采用Java实现。计算机配置为CPU Inter Celeron 2955U 1.40GHz,内存4GB,硬盘500GB,操作系统为Windows 7。实验数据来自网络中各大故事网站文本数据,包含了各种类型的名著与小说故事,数据的格式为txt文本。
分布式架构模型包括了一个Broker主节点和多个Search-server子节点。Broker主节点负责检索任务的监控和调度,倒排索引的切分与管理。子节点为计算节点,负责数据的检索与索引文件的管理。其配置均为CPU Inter Celeron 2955U 1.40GHz,内存4GB,硬盘500GB,操作系统为Windows 7。
3.2 性能测试与分析
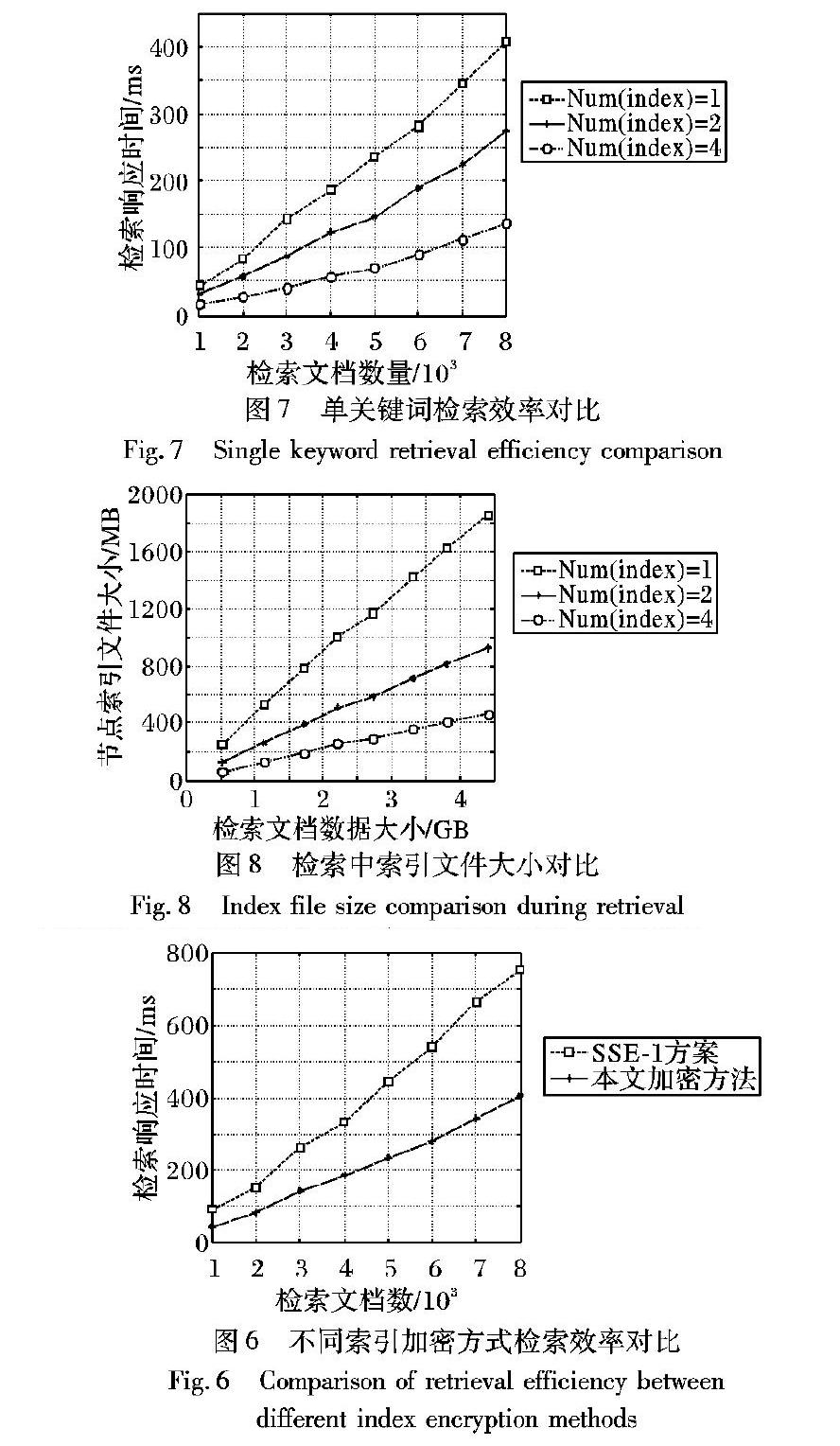
密文数据的检索效率是可搜索加密方案中的一个非常重要的性能指标,本文首先对于不同數量的文档集合分别进行SSE-1索引方案和本文索引加密方案在单索引文件、单关键词场景下的检索效率对比,实验数据如图6所示。
通过图6可发现:1)本文中的加密方案检索时间要少于SSE-1方案。这是因为SSE-1方案中倒排索引的指针也要加密,检索过程中,必须要首先解密前一个节点才能访问下一个节点的内容;而本文方案只对倒排索引中的关键词和文档信息加密,整个索引的指针和结构不加密,从而能实现更高效的检索。2)随着文档数量的增加,本文中的索引加密方案检索效率优势更加明显,这是因为文档数量的增加使得检索词相关的文档增多,倒排索引中的倒排项链表更长,导致SSE-1方案中对指针的解密计算量增加,降低了检索效率。对不同数据量的文档集合在本文的索引加密方案下分别基于单索引方案和切分多索引方案在单机单关键词下的文档检索效率进行对比,实验结果如图7所示。
通过图7可发现:检索时间消耗随着文档数量的增加而不断增大,这是由于文档数量的增加导致索引文件规模增大,造成索引加载和检索的时间消耗增多。此外,基于索引切分的多索引检索方案检索的效率更高,而且随着文档数据量的增加和切分数量的增加,检索的优势也更加明显。这是因为在检索过程中,单索引方案需要加载完整的索引文件进行计算处理,而基于索引切分的检索方案只需要在内存中精确加载检索词对应的子索引,减少了索引数据的加载和计算时间消耗,从而实现了高效率的检索。
通过对不同数据量的文档构建密文索引,分析在不同索引方案下,数据量的规模对检索操作过程中索引文件规模的变化趋势,实验结果如图8所示。
通过图8可发现:在单关键词检索、单索引方案中,数据量的增加导致了索引文件规模的急剧增长,而在基于索引切分的方案中,随着切分数量的增加,每个子索引文件规模的增长速度逐渐缓慢。在同等计算资源下,基于索引切分的子索引检索方案在检索过程中能够有效提高单机资源利用率和数据检索规模的扩展,更加适应大数据的检索场景。
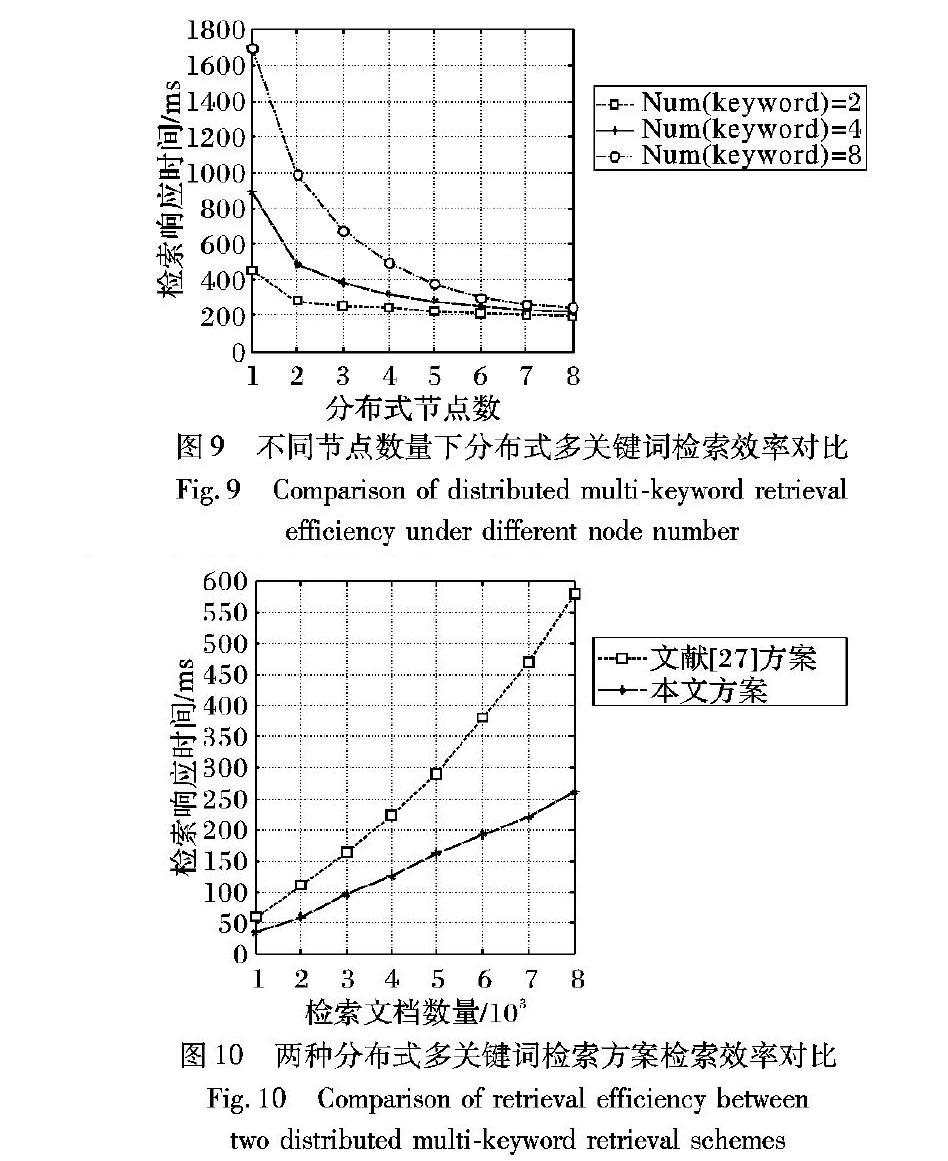
图9描述了在不同节点数量的分布式检索系统中,多关键词的检索时间消耗情况。
通过对图9的对比结果的分析发现:1)对于多关键词的密文检索,利用索引切分实现的分布式检索模型架构能够有效提高检索效率。这是因为随着计算节点和索引切分数量的增多,检索关键词更加分散,每个节点检索的关键词更少,从而以并行的检索模式提高了检索效率。2)随着检索请求中关键词的增多,检索效率逐渐下降。这是因为关键词的增多导致各个节点检索的计算量增加;同时主节点Broker在切分检索请求、合并检索结果的计算量增加,从而导致了整体检索过程的效率降低。3)随着切分节点的增多,不同数量检索词的检索效率趋于稳定,这是因为随着节点的增多,每个节点计算量减少,在各节点检索时间消耗不占主导的情况下,时间消耗主要集中在主节点Broker的索引切分和子索引匹配处理阶段,因此使总体检索时间趋于稳定。
通过图10的对比结果发现,本文中的多关键词检索方案比文献27]方案更具有优势,并且随着文档数量的增长,优势逐渐明显。这主要是因为本文检索方案中多个检索词相互独立,并且检索陷门的生成不依赖于索引文件。而文献27]中的检索方案在生成检索陷门的过程中,需要将多个检索词耦合在一起生成多项式,依据多项式矩阵来实现多关键词的检索。无论是索引构建还是检索过程,都需要经历大量的多项式矩阵计算,严重影响了检索效率;并且检索陷门的多项式矩阵的计算依赖于倒排索引的词典文件,文档数量的增加会导致索引中词典文件规模的增长,从而使得检索陷门的计算更为复杂,导致检索效率降低,不适用于数据量急剧增长的应用场景。
实验结果表明,使用索引切分的分布式检索方案,能够有效解决单机资源的局限性问题和提高多关键词的密文数据检索效率;并且随着数据规模的不断增长,分布式模型架构具有良好的可扩展性,能更好地适应数据量急剧增长的应用场景。
4 结语
可搜索加密是实现密文数据检索的重要手段。本文基于关键词的倒排索引切分提出了密文倒排索引的切分方案,通过索引切分与精确加载子索引文件,解决单服务器模型架构中存在的单机资源局限性问题,提高单机内存资源和计算的有效利用率。针对多关键词的检索模式,提出了分布式环境下的多关键词并行密文檢索方案,实现了索引文件的分布式管理和关键词的并行检索,提高了多关键词的检索效率,同时使得密文检索模型架构具有了可扩展性和灵活性等特性。实验结果说明,该分布式密文检索系统可以实现密文数据的高效检索操作,系统是有效的、可行的。
参考文献(References)
[1] LIANG K, SUSILO W. Searchable attribute-based mechanism with efficient data sharing for secure cloud storage[J]. IEEE Transactions on Information Forensics and Security, 2015, 10(9): 1981-1992.
[2] 胡坤, 刘镝, 刘明辉. 大数据的安全理解及应对策略研究[J]. 电信科学, 2014, 30(2): 112-117, 122. (HU K, LIU D, LIU M H. Research on security connotation and response strategies for big data[J]. Telecommunications Science, 2014, 30(2): 112-117, 122.)
[3] 吕欣, 韩晓露. 大数据安全和隐私保护技术架构研究[J]. 信息安全研究, 2016, 2(3): 244-250. (LYU X, HAN X L. Research on the technology architecture of big data security and privacy system[J]. Journal of Information Security Research, 2016, 2(3): 244-250.)
[4] LI J, LI Y K, CHEN X, et al. A hybrid cloud approach for secure authorized deduplication[J]. IEEE Transactions on Parallel and Distributed Systems, 2015, 26(5): 1206-1216.
[5] 冯朝胜, 秦志光, 袁丁. 云数据安全存储技术[J]. 计算机学报, 2015, 38(1): 150-163. (FENG C S, QIN Z G, YUAN D. Techniques of secure storage for cloud data[J]. Chinese Journal of Computers, 2015, 38(1): 150-163.)
[6] FU Z, REN K, SHU J, et al. Enabling personalized search over encrypted outsourced data with efficiency improvement[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(9): 2546-2559.
[7] 蒋旭, 孙磊, 谭炜波. 一种安全可靠大数据存储平台的设计[J]. 信息安全研究, 2018, 4(1): 63-72. (JIANG X, SUN L, TAN W B. The design of secure reliable big data storage platform[J]. Journal of Information Security Research, 2018, 4(1): 63-72.)
[8] BONEH D, di CRESCENZO G, OSTROVSKY R, et al. Public key encryption with keyword search[C]// Proceedings of the 2004 International Conference on the Theory and Applications of Cryptographic Techniques, LNCS 3027. Berlin: Springer, 2004: 506-522.
[9] SONG D X, WAGNER D, PERRIG A. Practical techniques for searches on encrypted data[C]// Proceedings of the 2000 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2000: 44-55.
[10] GOH E. Secure indexes[EB/OL]. [2018-04-17]. http://eprint.iacr.org/2003/216.pdf.
[11] BLOOM B H. Space/time trade-offs in Hash coding with allowable errors[J]. Communications of the ACM, 1970, 13(7): 422-426.
[12] CHANG Y, MITZENMACHER M. Privacy preserving keyword searches on remote encrypted data[C]// Proceedings of the 2005 26th International Conference on Applied Cryptography and Network Security, LNCS 3531. Berlin: Springer, 2005: 442-455.
[13] CURTMOLA R, GARAY J, KAMARA S, et al. Searchable symmetric encryption: Improved definitions and efficient constructions [C]// Proceedings of the 13th ACM Conference on Computer and Communications Security. New York: ACM, 2006: 79-88.
[14] NAVEED M, PRABHAKARAN M, GUNTER C A. Dynamic searchable encryption via blind storage[C]// Proceedings of the 2014 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2014: 639-654.
[15] KAMARA S, PAPAMANTHOU C, ROEDER T. Dynamic searchable symmetric encryption[C]// Proceedings of the 19th ACM Conference on Computer and Communications Security. New York: ACM, 2012: 965-976.
[16] XIA Z, WANG X, SUN X, et al. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(2): 340-352.
[17] BALLARD L, KAMARA S, MONROSE F. Achieving efficient conjunctive keyword searches over encrypted data[C]// Proceedings of the 7th International Conference on Information and Communications Security, LNCS 3783. Berlin: Springer, 2005: 414-426.
[18] CAO N, WANG C, LI M, et al. Privacy-preserving multi-keyword ranked search over encrypted cloud data[C]// Proceedings of the 32th IEEE Conference on Computer Communications. Piscataway: IEEE, 2011: 829-837.
[19] 楊旸, 杨书略, 蔡圣暐, 等. 排序可验证的语义模糊可搜索加密方案[J]. 工程科学与技术, 2017, 49(4): 119-128. (YANG Y, YANG S L, CAI S W, et al. Semantically searchable encryption scheme supporting ranking verification[J]. Advanced Engineering Sciences, 2017, 49(4): 119-128.)
[20] FU Z, WU X L, GUAN C, et al. Toward efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement[J]. IEEE Transactions on Information Forensics and Security, 2016, 11(12): 2706-2716.
[21] 王恺璇, 李宇溪, 周福才, 等. 面向多关键字的模糊密文搜索方法[J]. 计算机研究与发展, 2017, 54(2): 348-360. (WANG K X, LI Y X, ZHOU F C, et al. Multi-keyword fuzzy search over encrypted data[J]. Journal of Computer Research and Development, 2017, 54(2): 348-360.)
[22] KIM I T, QUAN T H, DUC L V, et al. An efficient searchable encryption scheme in the multi-user environment[C]// Proceedings of the 6th International Conference on Green and Human Information Technology, LNEE 502. Singapore: Springer, 2018: 188-192.
[23] HAHN C, SHIN H J, KWON H, et al. Efficient multi-user similarity search over encrypted data in cloud storage[J]. Wireless Personal Communications, 2018,107(3): 1337-1353.
[24] ZHANG W, LIN Y, XIAO S, et al. Privacy preserving ranked multi-keyword search for multiple data owners in cloud computing[J]. IEEE Transactions on Computers, 2016, 65(5): 1566-1577.
[25] 束曉伟, 杨庚, 那海洋. 并行密文倒排索引研究[J]. 计算机工程与应用, 2016, 52(20): 14-19, 45. (SHU X W, YANG G, NA H Y. Research on parallel crypt inverted index[J]. Computer Engineering and Applications, 2016, 52(20): 14-19, 45.)
[26] KAMARA S, PAPAMANTHOU C. Parallel and dynamic searchable symmetric encryption[C]// Proceedings of the 2013 International Conference on Financial Cryptography and Data Security, LNCS 7859. Berlin: Springer, 2013: 258-274.
[27] WANG B, SONG W, LOU W, et al. Inverted index based multi-keyword public-key searchable encryption with strong privacy guarantee[C]// Proceedings of the 2015 IEEE Conference on Computer Communications. Piscataway: IEEE, 2015: 2092-2100.
