基于角度间隔嵌入特征的端到端声纹识别模型
2019-11-15王康董元菲
王康 董元菲

摘 要: 针对传统身份认证矢量(i-vector)与概率线性判别分析(PLDA)结合的声纹识别模型步骤繁琐、泛化能力较弱等问题,构建了一个基于角度间隔嵌入特征的端到端模型。该模型特别设计了一个深度卷积神经网络,从语音数据的声学特征中提取深度说话人嵌入;选择基于角度改进的A-Softmax作为损失函数,在角度空间中使模型学习到的不同类别特征始终存在角度间隔并且同类特征间聚集更紧密。在公开数据集VoxCeleb2上进行的测试表明,与i-vector结合PLDA的方法相比,该模型在说话人辨认中的Top-1和Top-5上准确率分别提高了58.9%和30%;而在说话人确认中的最小检测代价和等错误率上分别减小了47.9%和45.3%。实验结果验证了所设计的端到端模型更适合在多信道、大规模的语音数据集上学习到有类别区分性的特征。
关键词:声纹识别;端到端模型;损失函数;卷积神经网络;深度说话人嵌入
中图分类号:TN912.34;TP391.42
文献标志码:A
Abstract: An end-to-end model with angular interval embedding was constructed to solve the problems of complicated multiple steps and weak generalization ability in the traditional voiceprint recognition model based on the combination of identity vector (i-vector) and Probabilistic Linear Discriminant Analysis (PLDA). A deep convolutional neural network was specially designed to extract deep speaker embedding from the acoustic features of voice data. The Angular Softmax (A-Softmax), which is based on angular improvement, was employed as the loss function to keep the angular interval between the different classes of features learned by the model and make the clustering of the similar features closer in the angle space. Compared with the method combining i-vector and PLDA, it shows that the proposed model has the identification accuracy of Top-1 and Top-5 increased by 58.9% and 30% respectively and has the minimum detection cost and equal error rate reduced by 47.9% and 45.3% respectively for speaker verification on the public dataset VoxCeleb2. The results verify that the proposed end-to-end model is more suitable for learning class-discriminating features from multi-channel and large-scale datasets.
Key words: voiceprint recognition; end-to-end model; loss function; convolutional neural network; deep speaker embedding
0 引言
聲纹识别是一种从语音信息中提取生物特征的识别技术[1]。在该技术发展的几十年中,由Dehak等[2]提出的身份认证矢量(identity vector, i-vector)方法一度成为声纹识别领域的主流研究技术之一。该方法主要有三个步骤:1)利用高斯混合模型通用背景模型(Gaussian Mixture Model-Universal Background Model, GMM-UBM)计算充分统计量;2)在全因子空间上提取i-vector;3)利用概率线性判别分析(Probabilistic Linear Discriminant Analysis, PLDA)计算i-vector间的似然比分数并作出判断[3]。
深度神经网络(Deep Neural Network, DNN)在图像识别、机器翻译和语音识别等诸多领域取得了非常瞩目的成绩,所以声纹识别技术同样引入了这一思想。利用DNN对声纹建模一般有两种方式:一种是利用DNN取代i-vector框架中GMM-UBM来计算充分统计量[4];另一种是从DNN的瓶颈层中提取帧级别的特征,利用这些特征获得话音级别表示[5-6],Variani等[7]将DNN最后一个隐藏层中提取的特征整体取平均来替代i-vector,是这种思想的典型代表。目前,将DNN和i-vector融合的技术已经较为成熟,并且在部分小规模的商业产品上得到了实现。但利用该方法仍然存在两大问题:1)提取i-vector作为话音级别的表示形式后,还需要长度标准化和后续分类器的步骤[8],比较繁琐;2)由于加性噪声的存在,利用i-vector构建的模型泛化能力较弱[9]。
基于上述研究背景,本文构建一个端到端的声纹识别模型,利用卷积神经网络(Convolutional Neural Network, CNN)和重新设计的度量方式,提取到类别区分能力更强的嵌入表示。这些方法在人脸识别领域得到了验证,但在声纹识别中比较少见。模型用于文本无关的开集识别任务,也就是训练和测试数据没有交集,并通过嵌入之间的余弦距离直接来比较说话人之间的相似性。为使模型学习到的深度说话人嵌入有足够的类别区分性,损失函数选择A-Softmax(Angular Softmax)来替代分类网络中最常使用的Softmax。A-Softmax损失函数能学习角度判别特征,将不同类别的特征映射到单位超球面上的不同区域内[10],更适合大规模数据集的训练,得到泛化能力更强的模型。
1 端到端声纹模型——深度说话人嵌入开集识别任务本质上是一种度量学习任务,其中的关键是使模型学习到类别间隔较大的特征,所形成的特征空间足以概括没训练过的说话人,所以模型训练过程中的目标是在特征空间中不断缩小同类距离的同时增大异类之间的距离。
目前,已有一些研究通过改进主干神经网络结构来提升模型效果,如文献[11]利用循环神经网络(Recurrent Neural Network, RNN)提取话音级别特征作为说话人嵌入,文献[12]则利用NIN(Network In Network)建模。
CNN最初在图像领域应用广泛,将其应用到语音分析中也能有效地在声学特征中减少谱之间的变化并对谱之间的相关性进行建模[13],故本文选择CNN从声学特征中提取语音数据帧级别的特征。
从平衡训练时间和模型深度的角度来看,选取CNN提取特征也要优于语音识别中常用的长短期记忆(Long Short-Term Memory, LSTM)网络[3]。
另一方面,模型的度量方式也可以进行改进,基于这种改进思想一般有两种方式[8]:一种是训练分类网络作为深度说话人嵌入的提取器,在损失函数上加上限制条件约束网络学习方向,提取输出层前一层的特征作为深度说话人嵌入;另一种是直接在特征空间中训练,使不同类别说话人之间的欧氏距离有一定的间隔,并将归一化后的特征作为深度说话人嵌入,这样特征空间中的欧氏距离与余弦距离意义等价,测试阶段可以直接利用余弦相似性计算分数。直接度量特征之间距离最具代表性的是三元组损失[14],但三元组的挖掘非常复杂,导致模型训练非常耗时,且对性能敏感,所以本文主要研究分类网络,即输出层神经元的个数等于训练的说话人类别数,这种思想的系统流程如图1所示。
系统的整体流程分为训练过程和测试过程两个部分。在训练过程中,将从语音数据中提取的声学特征送入CNN生成帧级别的特征,帧级别的特征被激活后送入平均池化层得到话音级别的特征,再利用仿射层进行维度转换,得到固定维度的深度说话人嵌入,输出层将固定维度的说话人嵌入映射到训练说话人类别数。损失函数是构建的端到端网络训练过程的最后一步,通过不断减小网络预测值和实际标签的差距来提高网络性能。在测试阶段,先把语音数据送入已经训练好的网络模型,从仿射层中得到深度说话人嵌入,再计算每对嵌入之间的余弦距离,根据阈值即可判断该对语音数据是属于相同说话人还是不同说话人。
2 具有角度区分性的深度说话人嵌入
基于Softmax损失函数学习到的深度说话人嵌入在本质上就有一定的角度区分性[10],这一点在文献[15]中也得到了证实,但在由Softmax直接映射的角度空间中对异类说话人嵌入没有明确的限制条件,这样同时优化了特征之间的夹角和距离。A-Softmax损失函数将特征权值进行归一化,使CNN更集中于优化不同特征之间的夹角,学习到具有角度区分性的深度说话人嵌入[10],以提高模型性能。
2.1 A-Softmax原理
延用文獻[16]中的定义,将分类网络的全连接输出层,Softmax函数以及交叉熵损失函数三个步骤联合定义为Softmax损失函数,表达式为:
其中:xi表示第i个训练样本的输入特征; yi为其对应的类别标签;Wj、Wyi分别是全连接输出层权重矩阵W的第j列和第yi列;bj、byi为其对应的偏置。训练数据时一般会分批处理,N即为每一批次中的训练样本个数,K为所有训练样本中的类别数。
将W与xi展开成模长与夹角余弦的乘积,同时限制‖Wj‖=1和bj=0,即在每次迭代中都将权重矩阵W每列的模进行归一化,并将偏置设为0,损失函数表达式转化为:
其中:θj,i(0≤θj,i≤π)为向量Wj与特征xi间的夹角,式(2)表明了训练样本i被预测为类别j的概率仅与θj,i有关。A-Softmax不仅在角度空间上使不同类别的样本分离,同时利用倍角关系增大了类别之间的角度间隔[10],表达式为:
2.2 A-Softmax角度间隔的性质
A-Softmax损失函数不仅通过角度间隔增加了特征之间的类别区分能力,同时能将学习到的特征映射到单位超球面上解释。权重Wyi与特征xi之间的夹角对应于该单位超球面上的最短弧长,同一类别在超球面上形成一个类似于超圆的区域。通过角度间隔参数m的设定可以调节学习任务的难易程度,m越大,单个类别形成的超圆区域也就越小,学习任务也越困难。但m存在一个最小值mmin使同类特征之间最大角度间隔小于异类特征之间最小角度间隔,文献[10]中未给出推导过程,本文将在二维空间中定量分析mmin。
二分类情况下不同类别之间的角度间隔如图2所示,其中W1、W2分别是类1、类2的权重向量,W1与W2之间的夹角为θ12,令输入的特征x属于类1,则有cos(mθ1)>cos(θ2),即mθ1<θ2。当特征x在W1、W2之间时,θ1存在一个属于类1的最大角
θin1_max;当特征x在W1、W2之外时,θ1存在一个属于类1的最大角θout1_max,θ1的范围即在θin1_max与θout1_max之间。如图2(a),当x在W1、W2之间时有:
选择满足期望特征分布的参数m,理论上可使所有训练特征按标准分布在单位超球面上,不同类别之间始终存在角度间隔,在此基础上训练尽可能多的类别数,则可以得到类别区分能力更强的深度说话人嵌入,提高模型的泛化能力。
2.3 网络模型设计
本文设计的网络模型主要分为三个部分:首先是语音信号声学特征的提取;其次是主干神经网络的构建;最后,利用A-Softmax损失函数衡量模型预测值,并更新参数。
在声学特征提取阶段,为保留更丰富的原始音频信息,将语音信号利用帧长25ms、帧移10ms的滑动窗口转化为64维FBank(FilterBank)特征。每个样本随机截取多个约0.6s的语音段,生成64×64的特征矩阵,经过零均值,单位方差归一化后,转化为单通道的特征图送入构建好的CNN。
主干网络是基于残差网络设计[17],网络层细节如表1所示。
每个残差块由两个卷积核为3×3、步长为1×1的卷积层构成,包含低层输出到高层输入的直接连接,每一种残差块只有一个。当输出通道数增加时,利用一个卷积核为5×5、步长为2×2的卷积层使频域的维度保持不变,将经过多个卷积层和残差块提取到的帧级别特征送入时间平均池化层。时间平均池化层将特征在时域上整体取均值,得到话音级别的特征,使得构建的网络在时间位置上具有不变性,再经过仿射层将话音级别的特征映射成512维的深度说话人嵌入。
A-Softmax损失函数中的角度间隔参数m设为3,利用反向传播更新模型参数。测试数据直接从仿射层提取512维深度说话人嵌入,通过L2归一化后直接计算余弦相似性,设置分数阈值评判一对嵌入属于相同说话人还是不同说话人,模型的训练算法和测试算法分别如算法1和算法2所示。
3 实验与结果分析
3.1 实验数据集
为得到一个强鲁棒性模型,需要训练一个多类别、多信道的大规模数据集,本实验采用VoxCeleb2数据集进行验证。VoxCeleb是一个从YouTube网站的采访视频中提取的视听数据集,由人类语音的短片段组成,其中VoxCeleb2数据集的规模比目前任何一个公开的声纹识别数据集仍大数倍,包含近6000个说话人产生的百万多条语音数据[18]。
VoxCeleb2中的语音数据包含不同种族、口音、职业和年龄的说话人演讲,数据在无任何约束条件下采集,背景有说话声、笑声、重叠的语音等符合实际环境的各种噪声[18],更适合训练端到端的神经网络模型。同时该数据集提供了几种不同方法在不同评价指标下的基础分数,本实验构建自己的网络模型与i-vector结合PLDA的方法进行比较。
3.2 模型訓练方法
模型共训练40轮,每轮每批处理的样本数为64个音频文件。每个卷积层后都加入批标准化(Batch Normalization, BN)和激活层,以提高模型训练速度,激活函数选择上限值为20的线性整流函数(Rectified Linear Unit, ReLU)。优化器选择动量为0.9的随机梯度下降法,权重衰减设为0。
为防止训练过程中损失函数出现震荡,利用指数衰减法控制模型学习率,衰减系数设为0.98,每隔1000个批处理步骤当前学习率乘以衰减系数,模型初始学习率为0.001。
3.3 实验结果分析
训练好的端到端模型可以同时进行说话人辨认和说话人确认两个实验,前者是“多选一”问题,后者是“一对一判别”问题。VoxCeleb2中的测试集共有118类,36237条语音,两个实验设计的方法均参考文献[19]。实验训练了基于Softmax和A-Softmax两种损失函数的模型,以验证本文模型的优势。
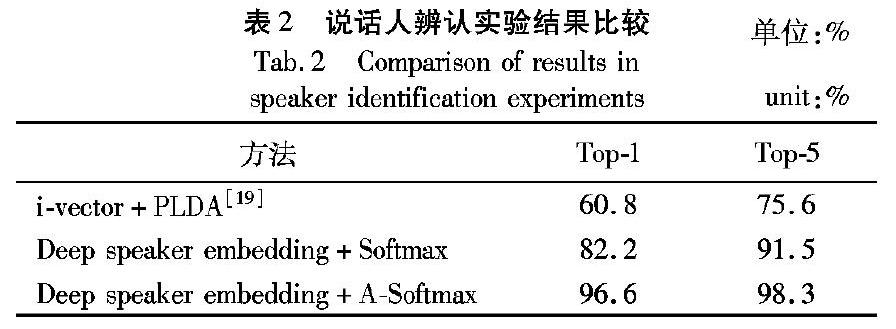
对于说话人辨认实验,在118个说话人中每人选择5条语音数据构建声纹库,即声纹库中一共包含590条语音。再从每个说话人中选择一条不同于声纹库的测试语音与声纹库中的所有语音进行比对,按相似性分数从大到小排序,计算相似度最大匹配成功的概率Top-1和前5名匹配成功的概率Top-5,结果见表2。
由表2的实验结果可知,采用提取深度说话人嵌入的方式,模型性能要明显优于i-vector结合PLDA的方法。选择A-Softmax作为损失函数构建的模型与之相比,Top-1和Top-5准确率分别提高了58.9%和30%。原因在于传统方法提取的i-vector中既包含说话人信息又包含信道信息,利用信道补偿的方法来减少信道影响不能充分拟合多种信道下采集的训练数据集,CNN却可以很好地拟合这种多种信道样本和标签之间的关系。损失函数选择A-Softmax与Softmax相比,Top-1和Top-5准确率分别提高了17.53%和7.41%。原因在于A-Softmax能学习到具有角度区分性的特征,对于从大规模的数据集训练得到的说话人嵌入在单位超球面上聚集更集中,这使得采用A-Softmax的模型比采用Softmax的模型具有更强的泛化能力。
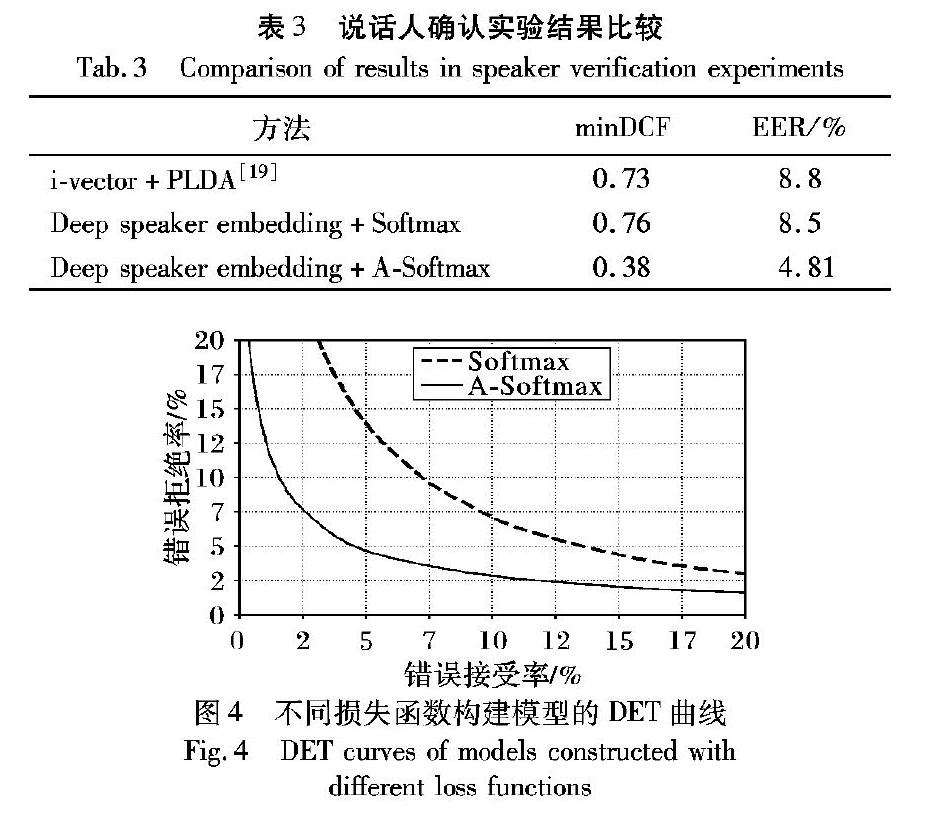
在说话人确认实验中,测试集中共有36237条语音,对于每条测试语音组成两对与该条语音属于同种说话人的语音数据和两对属于不同说话人的语音数据,实验一共组成了144948对测试对。计算所有测试对中错误接受率(False Acceptance Rate, FAR)和错误拒绝率(False Rejection Rate, FRR)相等时等错误率(Equal Error Rate, EER)的值。同时该实验还有一个评价标准为最小检测代价函数(Minimum Detection Cost Function, minDCF),检测代价函数DCF的公式为:
其中:CFR和CFA分别表示错误拒绝和错误接受的惩罚代价;Ptarget和1-Ptarget分别为真实说话测试和冒认测试的先验概率。实验设 ,结果见表3。同时针对两种不同损失函数所构建的模型,绘制了检测错误权衡(Detection Error Tradeoff, DET)曲线图,结果如图4所示。
由表3和图4的实验结果可知,采用提取深度说话人嵌入的方式,模型性能受损失函数的影响非常大。选择A-Softmax作为损失函数构建的模型与传统方法相比,minDCF和EER分别减小了47.9%和45.3%。原因是采用A-Softmax损失函数构建的模型增加了角度间隔,学习到的深度说话人嵌入有非常好的类别区分性。但选择Softmax作为损失函数构建的模型,minDCF反而大于传统方法,EER的减少程度也不明显,这也说明了Softmax并不适用于学习具有类别区分性的深度说话人嵌入。
4 结语
本文构建了一个端到端声纹识别模型,该模型利用类似于残差网络的卷积神经网络,从声学特征中提取深度说话人嵌入,选择A-Softmax作为损失函数来学习具有角度区分性的特征。通过对角度间隔参数m的分析,推导出满足期望的特征分布时m的最小值。本文从实验中得出,端到端的声纹模型能训练出结构更简单、泛化能力更强的模型,该模型在说话人辨认实验上有明显的优势,但在说话人确认实验中,模型性能受损失函数的影响较大。对于更大规模的数据集,本文构建的网络模型可能达不到更好的效果,需要构建更深的网络且减少过拟合对模型效果的影响,为保持特征在频域上的维度不变,可以对每一层的残差块个数进行增加。后续将会进一步研究在大规模数据集的条件下,所设计的模型中残差块的个数对声纹识别模型性能的影响。
参考文献(References)
[1] KINNUNEN T, LI H. An overview of text-independent speaker recognition: from features to supervectors[J]. Speech Communication, 2010, 52(1): 12-40.
[2] DEHAK N, KENNY P J, DEHAK R, et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 788-798.
[3] LI C, MA X, JIANG B, et al. Deep speaker: an end-to-end neural speaker embedding system[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1705.02304.pdf.
[4] LEI Y, SCHEFFER N, FERRER L, et al. A novel scheme for speaker recognition using a phonetically-aware deep neural network[C]// Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2014: 1695-1699.
[5] FU T, QIAN Y, LIU Y, et al. Tandem deep features for text-dependent speaker verification[EB/OL]. [2019-01-10]. https://www.isca-speech.org/archive/archive_papers/interspeech_2014/i14_1327.pdf.
[6] TIAN Y, CAI M, HE L, et al. Investigation of bottleneck features and multilingual deep neural networks for speaker verification[EB/OL]. [2019-01-10]. https://www.isca-speech.org/archive/interspeech_2015/papers/i15_1151.pdf.
[7] VARIANI E, LEI X, McDERMOTT E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]// Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2014: 4052-4056.
[8] CAI W, CHEN J, LI M. Analysis of length normalization in end-to-end speaker verification system[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1806.03209.pdf.
[9] 王昕, 張洪冉. 基于DNN处理的鲁棒性I-Vector说话人识别算法[J]. 计算机工程与应用, 2018, 54(22): 167-172. (WANG X, ZHANG H R. Robust i-vector speaker recognition method based on DNN processing[J]. Computer Engineering and Applications, 2018, 54(22): 167-172.)
[10] LIU W, WEN Y, YU Z, et al. SphereFace: deep hypersphere embedding for face recognition[C]// Proceedings of the IEEE 2017 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6738-6746.
[11] HEIGOLD G, MORENO I, BENGIO S, et al. End-to-end text-dependent speaker verification[C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 5115-5119.
[12] SNYDER D, GHAHREMANI P, POVEY D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification[C]// Proceedings of the 2016 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2016: 165-170.
[13] ZHANG Y, PEZESHKI M, BRAKEL P, et al. Towards end-to-end speech recognition with deep convolutional neural networks[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1701.02720.pdf.
[14] ZHANG C, KOISHIDA K. End-to-end text-independent speaker verification with triplet loss on short utterances[EB/OL]. [2019-01-10]. https://www.isca-speech.org/archive/Interspeech_2017/pdfs/1608.PDF.
[15] WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9911. Cham: Springer, 2016: 499-515.
[16] LIU W, WEN Y, YU Z, et al. Large-margin softmax loss for convolutional neural networks[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1612.02295.pdf.
[17] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[18] CHUNG J S, NAGRANI A, ZISSERMAN A. VoxCeleb2: deep speaker recognition[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1806.05622.pdf.
[19] NAGRANI A, CHUNG J S, ZISSERMAN A. VoxCeleb: a large-scale speaker identification dataset[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1706.08612.pdf.
