基于径向变换和改进AlexNet的胃肿瘤细胞图像识别方法
2019-11-15甘岚郭子涵王瑶
甘岚 郭子涵 王瑶
摘 要:使用AlexNet实现胃肿瘤细胞图像分类时,存在数据集过小和模型收敛速度慢、识别率低的问题。针对上述问题,提出基于径向变换(RT)的数据增强(DA)和改进AlexNet的方法。将原始数据集划分为测试集和训练集,测试集采用剪裁方式增加数据,训练集首先采用剪裁、旋转、翻转和亮度变换得到增强图片集;然后选取其中一部分进行RT处理达到增强效果。此外,采用替换激活函数和归一化层的方式提高AlexNet的收敛速度并提高其泛化性能。实验结果表明,所提方法能以较快的收敛速度和较高的识别准确率实现胃肿瘤细胞图像的识别,在测试集中最高准确率为99.50%,平均准确率为96.69%,癌变、正常和增生三个类别的F1值分别为0.980、0.954和0.958,表明该方法较好地实现了胃肿瘤细胞图像的识别。
关键词:小样本数据集;数据增强;径向变换;卷积神经网络;胃肿瘤细胞图像识别
中图分类号:TP391.4
文献标志码:A
Abstract: When using AlexNet to implement image classification of gastric tumor cells, there are problems of small dataset, slow model convergence and low recognition rate. Aiming at the above problems, a Data Augmentation (DA) method based on Radial Transformation (RT) and improved AlexNet was proposed. The original dataset was divided into test set and training set. In the test set, cropping was used to increase the data. In the training set, cropping, rotation, flipping and brightness conversion were employed to obtain the enhanced image set, and then some of them were selected for RT processing to achieve the enhanced effect. In addition, the replacement activation of functions and normalization layers was used to speed up the convergence and improve the generalization performance of AlexNet. Experimental results show that the proposed method can implement the recognition of gastric tumor cell images with faster convergence and higher recognition accuracy. On the test set, the highest accuracy is 99.50% and the average accuracy is 96.69%, and the F1 scores of categories: canceration, normal and hyperplasia are 0.980, 0.954 and 0.958 respectively, indicating that the proposed method can implement the recognition of gastric tumor cell images well.
Key words: small dataset; Data Augmentation (DA); Radial Transformation (RT); Convolutional Neural Network (CNN); gastric tumor cell image recognition
0 引言
胃癌是世界范圍内最常被诊断出的癌症之一,具有预后不良的特点,一个重要原因是大多数患者在癌症已经发展时才被诊断出来[1],及时而精确地判断出胃肿瘤细胞能够改善胃癌的预后,为患者争取宝贵的治疗时间。随着近年来人工智能的快速发展,自动识别胃肿瘤细胞图像的需求日益迫切。
目前,以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习(Deep Learning, DL)算法快速发展,常用来识别特征维数高、背景复杂的医学图像[2-6]。在胃肿瘤细胞图像的应用上,杜剑等[7]使用CNN,结合高光谱成像与显微系统,实现了癌变和正常组织的精确分类;但是该方法的数据获取较为困难,需要一定的硬件条件才可实现。张泽中等[8]将AlexNet与GoogLeNet结合,使用专业标签过滤后的胃癌病理图像进行训练取得了良好效果,但现实中难以对胃肿瘤细胞图像进行实时过滤。可见,CNN是实现胃肿瘤图像识别的一个有效方法。
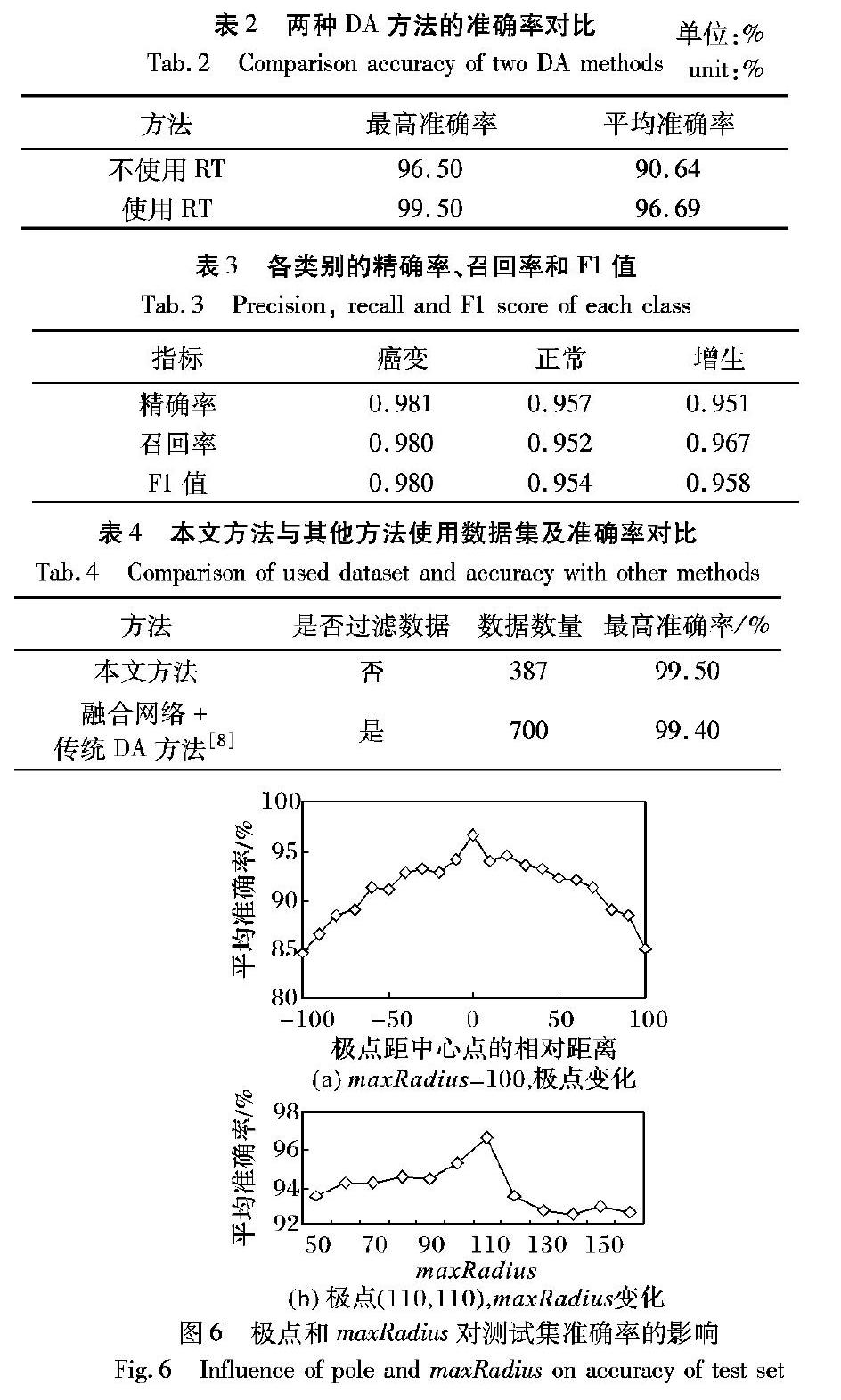
由于DL是数据驱动技术,所以当数据不足时,即使是更深的网络也难以取得更好的效果[9]。胃肿瘤细胞图像是典型的小样本数据集,不适合直接输入CNN进行训练。Perez等[10]证明通过剪裁、旋转、翻转等方法可以达到数据增强(Data Augmentation, DA)的目的,将这些传统DA方法组合起来可以进一步提高数据集的多样性,但并不能满足胃肿瘤细胞图像的数据集要求。Salehinejad等[11]针对超小型多模态医学数据集,提出使用径向变换(Radial Transform, RT)进行数据扩增,表明RT在多模态医学数据集上的可行性,由于胃肿瘤细胞图像具有旋转不变性,因此将传统DA方法与RT结合实现其数据扩展不失为一种好方法。
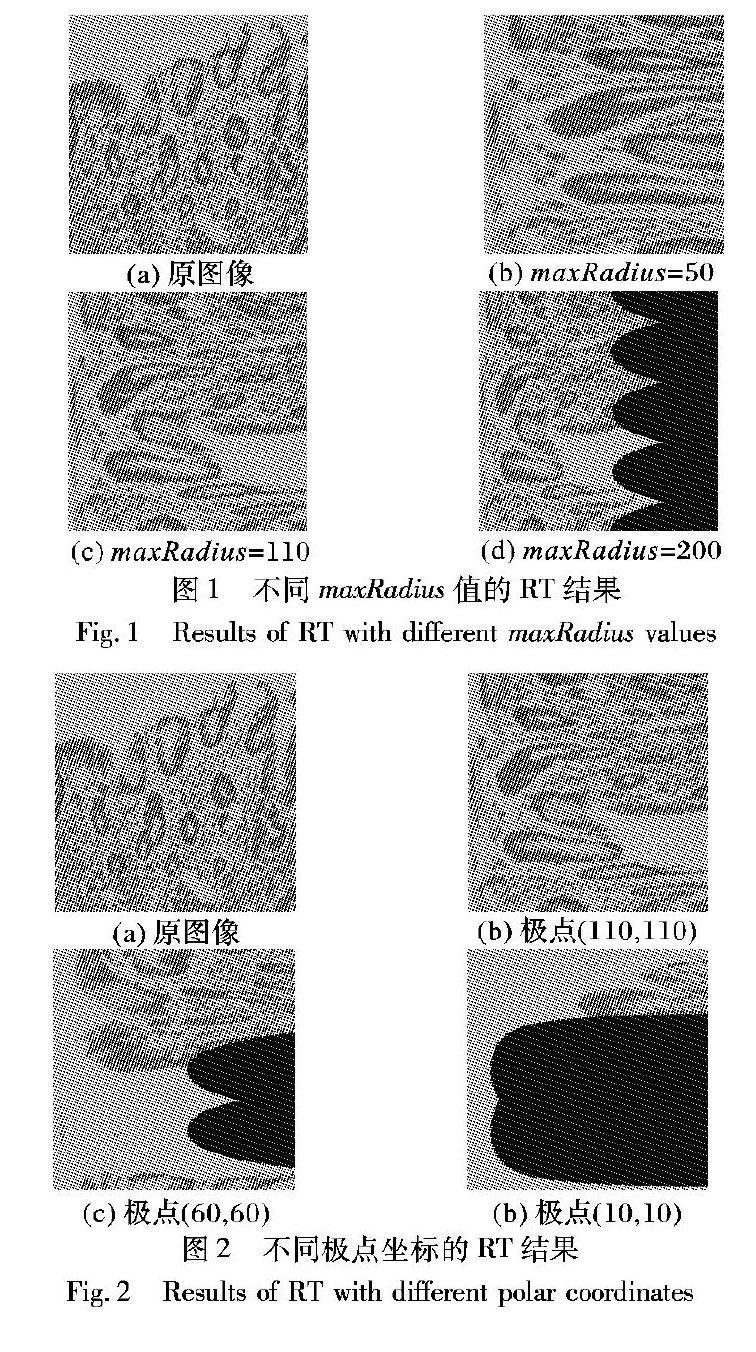
当maxRadius>110时,根据1.1节的分析,普遍存在Rm
综上所述,若想提取全部的图像信息,必须有Rm≤maxRadius,但是此时一定会出现超界缺失;若想不出现超界缺失,必须有Rm≥maxRadius,但是此时一定会出现信息丢失。因此,在使用固定极点的RT时,在超界缺失和信息丢失之间必须有所权衡。
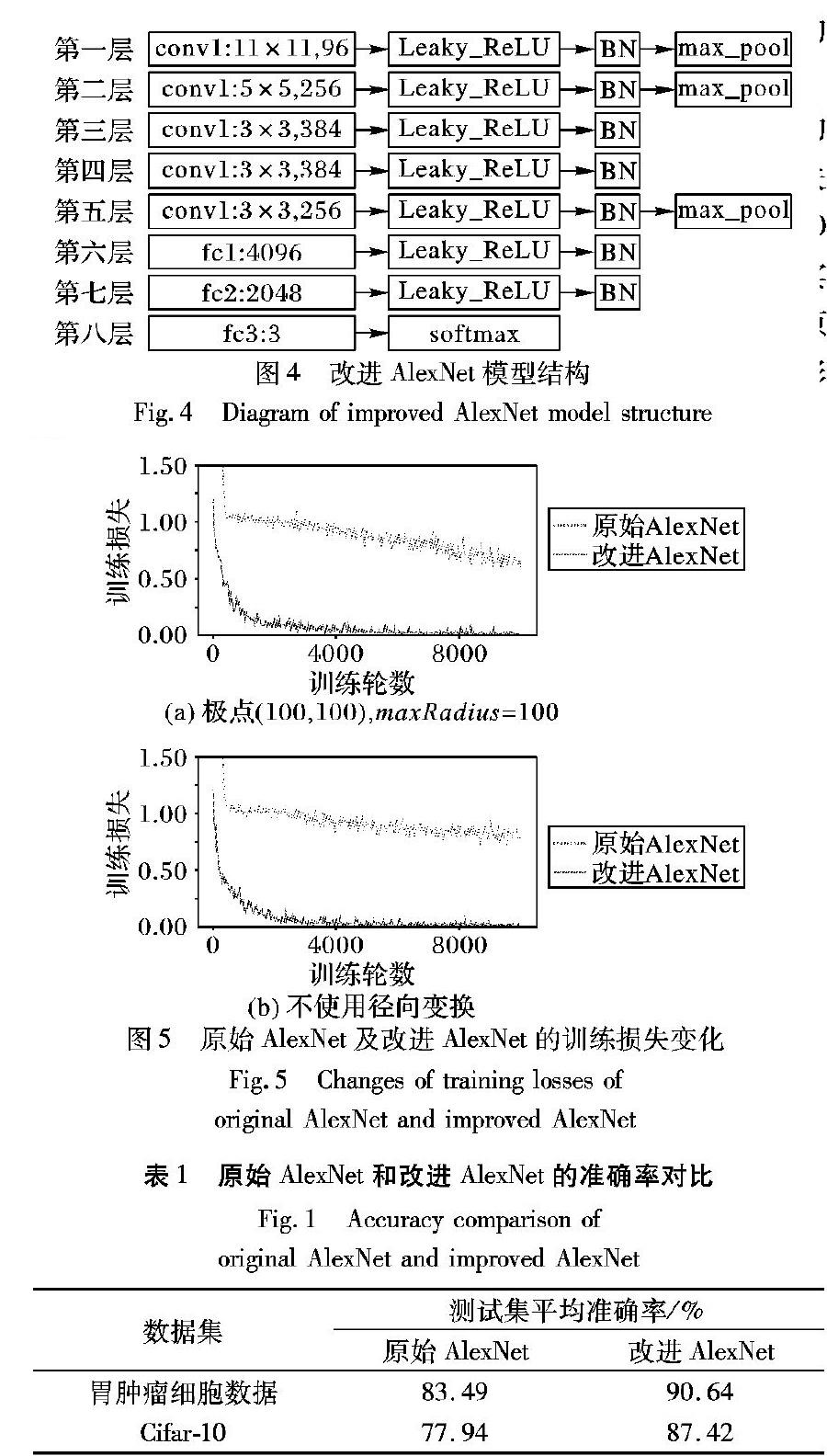
当极点偏离图像中心,接近图像边缘时,相对极点位于图像边缘区域的射线,即Rm较小的射线,存在Rm 综上所述,极点坐标如果偏离图像中心,超界缺失及信息丢失会同时出现,且随着偏离程度的增大,超界缺失及信息丢失的程度也越严重,因此,在使用RT进行数据扩增时,应尽量使极点位于图像的中心点。 1.3 RT的采样特点 根据式(1)易知,θm变化的范围是[0,2π]。根据式(3),当θm从0变化至2π时,q值也将从0变化至src.height,而p值保持不变。因此,在原图像上以极点O(u,v)∈X为圆心的圆,经过RT后,在新图像上会映射为一条竖直的直线。由于src.height是定值,而圆的周长会随着r的变化而变化,易知当r较小时,圆的周长也较小,经过RT其长度会被拉伸到src.height;当r较大时,圆的周长也较长,经过RT其长度会被压缩到src.height。这样的变化会使得极点的近邻点被扩展,极点的远邻点被压缩,由此可得RT的不均匀采样特点:对于极点O(u,v)∈X,其近邻点将会被上采样,远邻点将会被下采样。 由于这种不均匀采样的性质,原图中的细胞组织经过RT会产生形变,使得原来的细胞组织具有不同的表现形式,而这一过程并未产生新的图像特征,对比图2(a)(b)可以看出这一变化。同样地,因为不均匀采样的特点,这些不同的表现形式仅能作用于与极点有一定距离的环状区域。也即是说,经过RT处理的图像仅能准确地反映原图中一部分的特征信息,本文认为,在训练过程中,这一效果与图像放大、剪裁的DA方式相似。 此外,结合本节的分析可知,在原图中需要用非线性阈值划分的区域可以在RT后使用线性阈值划分,这表明RT不仅可以帮助增强图像,还可以降低图像中分类问题的复杂性,因此RT也常用于实现图像分割任务[17],本文仅讨论RT的DA能力。 1.4 基于RT的DA策略 根据1.3节的分析,RT的不均匀采样特点使其具有DA能力,但是下采样造成的信息丢失会导致CNN的分类能力下降[18],所以单独使用RT实现DA的效果较差。而传统的DA方法如剪裁、旋转、亮度变换不会因为采样不均匀导致信息丢失。因此使用RT实现DA时,应该采用RT和传统DA方法同时使用的策略。 更详细地,对于训练集,某张图片的增强图片集应分为两个部分:一部分为使用RT处理的数据,该部分保证图像表现的多样性;另一部分为仅使用传统DA方法处理的数据,该部分在增加多样性的基础上保证图像信息的完整性,以弥补RT带来的信息丢失问题。 对于测试集,不宜使用RT进行处理。在1.3节的分析中,RT处理后的图像仅能准确地反映原图中一部分的特征信息,因为单张RT图像包含的信息相当有限,而胃肿瘤细胞图像的类与类之间差距很小,这些有限的信息可能不包含分类胃肿瘤细胞图像所需的关键特征信息,所以在测试集中使用RT进行处理难以取得好的测试结果,前期实验也表明对测试集进行RT处理会降低模型的识别准确率。 2 AlexNet模型改进 2012年Alex等[19]提出了AlexNet,并因为它出色的分类能力获得了2012年ImageNet LSVRC比赛的冠军,具有结构简单、参数少的特点。虽然目前已有如GoogLeNet、ResNet等更先进的网络模型,但是有实验结果表明,对于小型的多模态医学图像数据集,采用RT作为DA手段时,GoogLeNet与AlexNet的分类效果十分相近,对于某些类别,AlexNet的识别率甚至优于GoogLeNet[11]。而对于ResNet等更复杂的网络结构,数据集过小时,其海量参数更容易导致过拟合。本文使用的胃肿瘤细胞图像数据集是典型的小样本数据集,AlexNet足以胜任该分类任务,因此选取AlexNet作为参考模型。 为了使AlexNet有更好的训练效果,尝试在使用胃肿瘤细胞图像数据时改进其网络结构。有研究指出,原始AlexNet的第三层和第四层卷积层对MRI等医学图像的特征提取能力最强[12],但是在这两层的改动效果并不理想,对其他层的改动同样会导致网络的泛化能力下降,所以本文转而在AlexNet的各个模块中寻求改进方法。在前期实验中,发现原始AlexNet的收敛速度很慢,训练非常耗时;同时原始AlexNet在胃肿瘤细胞图像数据上的识别率很低。因此,对AlexNet进行改进的主要目的是提高收敛速度、提高识别率。 2.1 激活函数改进 激活函数是神经网络的重要组成部分,通过激活函数,神经网络才具备了分层的非线性映射能力。除了非线性映射的能力以外,更加平滑的激活函数还具有更快的逼近速率[20]。因此,使用更好的激活函数能够提高模型的收敛速度,同时提高模型的泛化性能。 原始AlexNet使用修正线性单元(Rectified Linear Unit, ReLU)作为激活函数,当ReLU被激活至0以上时,其偏导恒为1,这解决了Sigmoid激活函数输入过大时带来的梯度消失问题,然而ReLU在输入为负值时其偏导恒为0,此时出现完全饱和,这可能导致神经元永远不会被激活,在使用基于梯度的优化算法时,这一缺点会使网络的训练速度变慢,甚至降低网络的泛化性能,ReLU的函数图像如图3(a)所示。 Leaky ReLU与ReLU激活函数的不同之处在于输入为负值时其偏导不为0,这解决了ReLU可能出现神经元不被激活的情况,使得网络的训练速度更快、效果更好,所以使用Leaky ReLU代替ReLU激活函数,Leaky ReLU的函数图像如图3(b)所示。 根据图3(b),Leaky ReLU输入为负值时其函数表示为yi=aixi,而ai的值与激活函数的表现有较大关联,当ai过小时,Leaky ReLU和ReLU的效果几乎相等[21];可以预见地,当ai过大时,对于负值输入,较大的梯度将使权重结果偏向正值,这将使模型训练不稳定,增加模型的训练时间。在TensorFlow 1.10.0版本中,ai的默认值为0.2,使用该值时效果良好,无需改动,所以本文实验中ai的值均设置为0.2。 2.2 归一化层改进 在神经网络中,通常要对输入数据进行归一化处理,在隐含层输入之前的归一化操作称之为归一化层。归一化层可以将不同参量去量纲化,缩小数值差别,并使网络快速收敛。因此,通过改进归一化层可以达到提高网络收敛速度的目的。 原始AlexNet中使用了局部响应归一化(Local Response Normalization, LRN)层对第一、二层进行归一化操作,以增强模型的泛化性能,但是LRN层对模型的实际改善效果有限[22],还会极大增加模型的训练时间。使用BN层替换LRN层可以提高计算效率的同时提高分类准确性[23],此外,使用BN层可以放宽网络的初始化条件,主要体现在可以使用更大的初始学习率[14]。 BN层与LRN层相似,也是一种归一化算法。对于深度学习这类包含很多隐含层的网络结构,训练过程中各层参数都在不停变化,各层的输入分布经过处理也在不停变化,由于训练期间网络参数变化导致的网络激活分布的变化称为协变量偏移[24]。BN层通过将每层的输入分布变换到均值为0、方差为1的正态分布来解决协变量偏移的问题。对于小批量梯度下降(Mini-Batch Gradient Descent, MBGD),设每层输入为x=(x(1),x(2),…,x(d)),BN的具体操作就是对输入x的每一维x(k)进行式(4)的变换: 式(4)中的期望及方差由训练集计算得来。经过式(4)的变换,某层的输入就变成了均值为0、方差为1的正态分布,从而限制分布,增大导数值,增强反向传播信息流动性,提高训练的收敛速度,但是这样会导致网络的表达能力下降。为了改进这一缺陷,BN对每个神经元增加两个可以学习的调节参数γ(k)和β(k),用来对经过式(4)变换后的激活值进行反变换,从而增强网络的表达能力,反变换操作为y(k)=γ(k)(k)+β(k),其中y(k)表示反變换结果。 BN层提出时,原文将BN层设置在卷积层和激活函数中间,但是目前在实践上倾向于把BN层放置在激活函数后面。BN层既然作为输入的归一化操作,而激活函数处理过后的数据就是下一层的输入,所以本文更倾向于将BN层放在激活函数之后,但是前期实验结果表明,BN层不论在哪个位置都对模型的训练结果没有明显影响。 需要说明的是,在加入BN层后,需要删除原AlexNet中的随机失活(Dropout)层并且不能使用L1、L2正则化项。有研究表明在使用BN层的网络中可以移除Dropout层[24],而L1、L2正则化项与BN层不能同时使用的原因尚不清楚。实验发现,当BN层与Dropout层或正则化项同时使用时会导致模型的训练过程不稳定,主要表现在损失函数出现较大波动,而删除Dropout层和正则化项后,损失函数趋于稳定,且模型的泛化能力没有出现明显下降。 2.3 改进AlexNet的模型结构 原始的AlexNet输入为227×227×3大小的图像,其中:227代表图像的宽和高,3代表图像的颜色通道数。因为对于胃肿瘤细胞图像,灰度图就足以判断其类别,所以将模型的输入调整为227×227×1,这样做不仅利于避免颜色噪声,还能一定程度上增加模型的训练速度。除2.1、2.2节的改进之外,对于原始AlexNet卷积层、池化层和全连接层的参数不作改变,改进后的AlexNet网络结构如图4所示。 3 实验过程 3.1 实验环境及超参数设置 实验通过1.10.0版本TensorFlow实现模型代码,通过OpenCV实现图像数据的预处理;训练模型时使用GPU加速,显卡使用单个RTX2070(8GB),CPU使用英特尔i5-9400。 模型训练使用MBGD方法,一个Batch大小设置为200,共训练10000轮,使用滑动平均模型以减小过拟合,使用Adam优化器,以0.0001为初始学习率,将训练集图片在输入前充分打乱,以减少图片顺序对模型的影响。数据集处理的时间与模型训练的时间一共约120min。 3.2 数据集处理 本文使用的实验数据是由南昌大学第一附属医院提供的胃粘膜细胞切片图像, 原始数据集共有387张彩色图片,每张大小为320×240像素。其中,胃肿瘤细胞图片180张,胃正常细胞图片134张,胃增生细胞图片73张。按比例随机选取其中307张(80%)作为原始训练集,80张(20%)作为原始测试集,将原始训练集和原始测试集分开处理。 对于原始训练集中的每张图片,处理步骤如下: 1)首先对图像进行剪裁:如果是胃肿瘤细胞图片或胃正常细胞图片,从左上角开始,横坐标每隔5个像素,纵坐标每隔4个像素,截取130张220×220大小的局部图片。如果是胃增生细胞图片,从左上角开始,横纵坐标每隔4个像素,截取156张220×220大小的局部图片。 2)对剪裁后的每张图片依次进行随机亮度变换、随机翻转和随机旋转处理,然后加入训练集,该部分为训练集中不使用RT处理的数据。 3)重新对原始训练集进行剪裁:如果是胃肿瘤细胞图片或胃正常细胞图片,从左上角开始,横坐标隔4个像素,纵坐标隔2个像素,截取306张220×220大小的局部图片;如果是胃增生细胞图片,从左上角开始,横坐标每隔3个像素,纵坐标每隔2个像素,截取357张220×220大小的局部图片。 4)对第3)步得到的每张图片依次进行随机亮度变换、随机翻转、随机旋转及RT处理,然后加入训练集,该部分为训练集中使用RT处理的数据。 5)对处理后训练集中所有图像进行灰度化处理,并将每张图片的尺寸通过双线性插值法调整为227×227。 经过如上步骤,原始训练集的每张图片都可以处理为若干张大小为227×227的局部图片,局部图片的集合包含原图像的所有信息。处理后的训练集共有138754张图片,其中经过RT的约占70%,该比例并未经过严格验证,仅为了证明RT在DA中的有效性。 对于原始测试集中的每张图片,随机剪裁出350张220×220大小的图片,然后通过双线性插值法调整为227×227大小并进行灰度化处理,处理后的测试集共有28000张图片。 需要说明的是,在原始训练集处理的第1)步和第3)步中将图片剪裁成220×220大小是为了方便讨论RT参数的影响。而目前没有文献证明对图片进行极小范围的尺寸变化会影响图像信息,因此本文认为将220×220尺寸的图片调整为模型输入所需的227×227尺寸时,不会对实验结果产生影响。 3.3 AlexNet改进效果 根据2.1、2.2节,对原始AlexNet的改进目的是提高模型的收敛速度同时提高模型的泛化性能,图5对比了使用RT和不使用RT时原始AlexNet和改进AlexNet在训练过程中的训练集损失变化。 图5(a)中,原始AlexNet在10000轮仍未收敛,改进的AlexNet在3000轮左右收敛,且其在整体训练过程中的损失都要小于原始AlexNet;图5(b)中,原始AlexNet同样在10000轮仍未收敛,改进的AlexNet在3000轮左右收敛。在前期实验中,原始AlexNet约在100000轮收敛,由图5可知,相比原始AlexNet,改进AlexNet具有更快的收敛速度,且不受RT影响。 由于训练损失仅能一定程度反映模型的训练情况,并不能反映模型的泛化性能,为了进一步验证本文AlexNet的改进效果,使用了两个不同的数据集,将原始AlexNet和改进AlexNet的测试集平均准确率进行了对比,对比结果如表1所示。表1中,胃肿瘤细胞数据使用的是未经RT处理的数据集。 由表1可以發现,改进AlexNet的测试集准确率在两个数据集上均有不同程度的提升。对于未经RT处理的胃肿瘤细胞图像数据集,改进的AlexNet相比原始AlexNet提高了7.15个百分点;对于Cifar-10数据集,改进的AlexNet相比原始AlexNet提高了9.48个百分点。表明本文的改进AlexNet相比原始AlexNet有更好的泛化性能。综上所述,本文对AlexNet的改进方法是有效的,相比原始AlexNet,具有更快的收敛速度和更好的泛化性能。 3.4 RT的参数设置为了寻找使用RT实现DA时的最佳参数设置,采用先确定最佳极点坐标,然后确定最佳maxRadius的策略。 令maxRadius恒为110,取图像左上至右下对角线上的点至中心点(110, 110)的相对距离为横坐标,两点间的欧氏距离为相对距离乘以2,测试准确率为纵坐标,极点距图像中心点的距离与测试集准确率的关系如图6(a)所示,其中中心点左侧的点取负距离,右侧的点取正距离。可以发现,当距离为0时,即极点位于图像中心点时测试准确率最高,当极点偏离图像中心点时,测试准确率下降,这说明极点应选取在图像的中心,验证了1.2.2节中极点应尽量接近图像的中心点的结论。 令极点坐标恒为(110, 110),测试集的平均准确率随maxRadius变化的情况如图6(b)所示,可以发现,maxRadius=110时,准确率最高,其他情况准确率均有下降。因此对于极点(110, 110),最佳的maxRadius应为110,根据1.2.1节的分析,此时刚好不会出现超界缺失,图像信息的丢失也最少,从侧面印证了该参数设置的合理性。 综上所述,使用RT作为DA方法时,应该采用不会出现超界缺失和信息丢失最少的RT参数。因此可以得到一个适用于胃肿瘤细胞图像数据的RT参数设置方法:对于大小为N×N的方形图像数据集,选取的极点坐标应为(N/2, N/2),maxRadius=N/2。对于本文使用的数据集,N=220,因此最佳的参数设置应为极点(110, 110),maxRadius=110。 3.5 实验结果分析 本文使用改进的AlexNet模型进行训练,采取极点(110, 110),maxRadius=110的RT方法对数据集进行DA处理,实现胃肿瘤细胞的图像识别。表2显示了使用RT和不使用RT时,DA对测试集准确率的影响。可以发现使用RT比不使用RT的效果更好,它在测试集上的最高准确率和平均准确率分别提高了3.00和6.05个百分点,说明了使用RT作为DA手段的有效性。 [9] ALOM M Z, TAHA T M, YAKOPCIC C, et al. The history began from AlexNet: a comprehensive survey on deep learning approaches[EB/OL]. [2019-02-08]. https://arxiv.org/ftp/arxiv/papers/1803/1803.01164.pdf. [10] PEREZ L, WANG J. The effectiveness of data augmentation in image classification using deep learning[EB/OL]. [2019-02-08]. https://arxiv.org/pdf/1712.04621.pdf. [11] SALEHINEJAD H, VALAEE S, DOWDELL T, et al. Image augmentation using radial transform for training deep neural networks[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 3016-3020. [12] 呂鸿蒙, 赵地, 迟学斌. 基于增强AlexNet的深度学习的阿尔茨海默病的早期诊断[J]. 计算机科学, 2017, 4(S1): 60-70. (LYU H M, ZHAO D, CHI X B. Deep learning for early diagnosis of Alzheimers disease based on intensive AlexNet[J]. Computer Science, 2017, 44(S1): 60-70.) [13] 丁蓬莉, 李清勇, 张振, 等. 糖尿病性视网膜图像的深度神经网络分类方法[J]. 计算机应用, 2017, 37(3): 699-704. (DING P L, LI Q Y, ZHANG Z, et al. Diabetic retinal image classification method based on deep neural network[J]. Journal of Computer Applications, 2017, 37(3): 699-704.) [14] BJORCK N, GOMES C, SELMAN B, et al. Understanding batch normalization[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1806.02375.pdf. [15] WANG S, PHILLIPS P, SUI Y, et al. Classification of Alzheimers disease based on eight-layer convolutional neural network with leaky rectified linear unit and max pooling[J]. Journal of Medical Systems, 2018, 42(5): No.85. [16] 余博, 郭雷, 赵天云. 基于对数极坐标变换的灰度投影稳像算法[J]. 计算机应用, 2008, 28(12): 3126-3128. (YU B, GUO L, ZHAO T Y. Gray projection image stabilizing algorithm based on log-polar image transform[J]. Journal of Computer Applications, 2008, 28(12): 3126-3128.) [17] FU H, CHENG J, XU Y, et al. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation[J]. IEEE Transactions on Medical Imaging, 2018, 37(7): 1597-1605. [18] KUMAR D, WONG A, CLAUSI D A. Lung nodule classification using deep features in CT images[C]// Proceedings of the 12th Conference on Computer and Robot Vision. Piscataway: IEEE, 2015: 133-138. [19] KRIZHEYSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc, 2012: 1097-1105. [20] MHASKAR H N, MICCHELLI C A. How to choose an activation function[C]// Proceedings of the 6th International Conference on Neural Information Processing Systems. San Francisco: Morgan Kaufmann Publishers Inc, 1993: 319-326. [21] XU B, WANG N, CHEN T, et al. Empirical evaluation of rectified activations in convolutional network[EB/OL]. [2019-02-08]. https://arxiv.org/pdf/1505.00853.pdf. [22] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2019-02-08]. https://arxiv.org/pdf/1409.1556.pdf. [23] JING J, DONG A, LI P, et al. Yarn-dyed fabric defect classification based on convolutional neural network[J]. Optical Engineering, 2017, 56(9): 093104. [24] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL]. [2019-01-10].https://arxiv.org/pdf/1502.03167.pdf.
