上海局高铁智能化配餐分析和对策研究
2019-11-15张剑霞中国铁路上海局集团有限公司上海华铁旅客服务有限公司
张剑霞 中国铁路上海局集团有限公司上海华铁旅客服务有限公司
1 现状分析
1.1 背景描述
近些年,中国的高铁发展迅猛,得到提升的不仅仅是出行速度,还有旅程的数字化、信息化程度。同时,随着生活水平的不断提高,人们对于出行方式的快速便捷化要求也越来越高,乘坐高铁出行已经成为了大多数人的出行首选,而高铁盒饭则为不少旅客解决了出行途中的“吃”问题。
2017年7月18日,中国铁路总公司推出了“12306网上订餐”服务,在动车上只要拿出你的手机,登录12306网站或者手机APP,就可以预定自己路过地方的当地美食,美食做好将提前送到车站,列车一到站由工作人员送到车厢。此外,列车还陆续推出了“高铁点外卖服务”、“高铁扫码选餐服务”等,让旅客在座位上享受一键下单、美食即刻到身边的便捷服务。
1.2 问题分析
目前,高铁不同车次盒饭的配餐数都是根据以往数据和业务经验来制定的,大都是主观判断,缺少科学依据,且不同价位、不同口味、不同供应商、不同交路、季节变化等因素都需要综合考虑,相关业务人员工作量很大。
2 总体设计
2.1 目标
通过系统实现智能化预测不同线路、不同车次、不同价位和不同口味的个性化配餐需求,完成列车配餐的智能化决策。
2.2 总体思路
(1)高铁点餐服务的便捷性和多样化,使得高铁餐饮数据随着列车里程的不断积累越来越丰富,因此我们可以通过这些海量销售数据进行深度分析挖掘,找出旅客餐食需求的变化趋势和规律特征,从而实现智能化配餐的目标。
(2)在算法选择上,可以采用已经成熟的大数据智能分析算法,如RBF神经网络、BP神经网络、时间序列模型、先知模型等对数据进行智能化分析预测。
3 系统设计
3.1 数据采集
(1)对列车运行过程中产生的实时销售数据进行实时采集,主要包括列车乘务员的手持终端以及扫码点餐的移动端APP的数据等进行实时抽取对接。
(2)采集方式:存放实时数据的关系型数据库,如MySQL,与高铁配餐智能化预测大数据平台做实时数据同步。
3.2 数据处理
利用智能算法处理异常记录、缺失数据等。常用的数据预处理的技术主要包括缺失值填充技术、数据抽样技术、变量处理技术、数据重构技术、数据无量纲处理技术等。
3.2.1 缺失数据处理
缺失值填充是针对带有缺失值的数据进行处理,因为有的分析算法在进行数据分析前要求数据是无缺失的,所以数据的缺失值填充是非常关键的一步,对后续的分析影响很大。一般的缺失值填充方法见表1。

表1 缺失值填充方法列表
本系统根据数据特征进行缺失值填充处理,主要采用线性插值法进行填充处理。
3.2.2 异常值处理
异常值处理用来发现“小的模式”(相对于聚类而言),即数据集中显著不同于其它数据的对象,也称为孤立点。
Hawkins(1980)给出孤立点(outlier)的定义:孤立点是在数据集中与众不同的数据,使人怀疑这些数据并非随机孤立点,而是产生于完全不同的机制。孤立点可能在聚集运行或者检测的时候被发现,比如一个人的年龄是999,这在对数据库进行检测的时候就会被发现。还有就是outlier可能是本身就固有的,而不是一个错误,比如CEO的工资就比一般员工的工资高出很多。
孤立点算法是基于距离的:设Dk(p)表示点p和它的第k个最近邻居的距离。直观地看,Dk(p)越大,p越有可能成为孤立点。给定d维空间中包含N个点的数据集、参数n(孤立点个数)和k(偏差距离),如果满足Dk(p')>Dk(p)的点p'不超过n-1个,那么称p为Dnk孤立点。如果对所有数据点根据其Dk(p)距离进行从大到小排序,那么前n个点就被看作是孤立点。
最后,我们可以根据数据特征将异常值进行剔除。
3.2.3 预测建模
将神经网络模型、时间序列模型与先知模型分别带入该预测模型中,根据模型精度进行优化调整参数,并选取预测精度最高的作为本次建模的算法。
按照实际训练效果,采用先知模型的效果最好,模型精度最高。
Prophet模型是指将经济社会增长与节假日等影响因素加入到模型中,具体模型如下:

g(t)用于拟合时间序列中的分段线性增长或逻辑增长等非周期变化。
(1)逻辑增长模型

其中,C是饱和值,k是增长率,m是偏执参数。
因为C是随时间t变化的,且k也会随着一些其他不确定因素发生改变。故该模型需做一些改进。
在时间序列中设置若干个转变点Sj,j=1,2...,S,在这些转变点上k的值会发生改变。改变量为σj表示在时间tj处的变化量,构建出向量a(t)∈{0,1}s

则增长率在时间t的表达式变为:
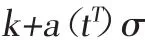
当增长率发生变化时,偏执参数m也应随之做出相应的调整,来连接时间片段的尾部。在转折点j处对偏执参数的调整量如下:
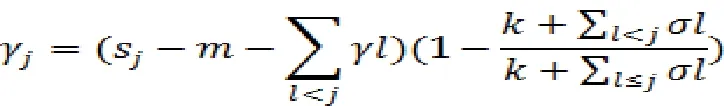
因此得到分段logistic趋势模型:

逻辑增长模型适合有增长趋势的预测问题,而对于没有增长趋势的预测问题时,线性增长率模型则更加有效:

同理,k是增长率,σ是增长率的调整值,m是偏执参数,γj设置为-sjσj来使得函数连续。
(2)s(t)周期变化(每周/每年的季节性)
本研究主要依靠傅里叶级数来构造灵活的周期性模型,可以设置p为我们想要的时间序列的规则周期长度,这样就得到了任意平滑周期效应的估算值:

为了拟合周期性,需要估计这 2N 个参数β=[a1,b1,...,aN,bN]。这是通过对历史上和未来的每个t值构建一个季节性向量矩阵来实现的。
在我们的生成模型中,我们采用β~Normal(0,δ2)来对季节性施加一个先验分布。
将傅里叶级数的项数N进行截断相当于对季节性施加了一个低通过滤波器,增加N能够提高拟合效率,但可能会出现过拟合。这些参数的选择能够通过模型选择程序来自动实现。
(3)h(t)非规律变化的节假日效应
整理出这种非规律变化的节假日或事件(过去和未来),认为它们的作用是独立的,并考虑进模型中。对于每个节假日i,让Di设置为过去和未来节假日的集合,添加一个指示函数来表明时间t是否在节假日i中,并对每一个节假日设定一个参数ki来对应出预测中变化。与季节性模型处理方法类似,生成一个回归元的矩阵:

与季节性模型类似,采用先验k~Normal(0,δ2),ε为误差项,用来反映未在模型中体现的异常变动。
3.3 数据源
(1)数据源的来源
基于大数据、云计算等技术,构建高铁智能化配餐云平台,采集配餐业务相关的各种数据源,主要分为三部分:一是ERP系统数据,包括销售数据、库存数据、退损数据、供应商数据等;二是手持终端数据,包括列车乘务员手持设备的实时销售数据、扫码点餐数据等;三是其它数据,包括客流数据、天气、宏观经济等外部数据。
(2)利用数据源构建服务引擎
我们可以利用马克威的算法引擎服务对配餐数据进行分析挖掘,建模预测。算法引擎主要包括机器学习算法、数据挖掘算法、统计分析算法、数据处理算法等。
(3)可视化展示数据分析结果
配餐预测模型结果进行可视化的展示,既可以提供传统的饼状图、柱状图、折线图及数据表结合等展现形式,还可以提供包括决策树、地图分布、驾驶舱、仪表盘、全景视图和多维立方体等大数据分析的展现方式。
3.4 模型的应用
以G2车次数据为例:将导出的G2总盒饭数TOTAL输入模型,调整预测周期,得到G2总盒饭数的预测值,图1为预测周期为2周的预测值。

图1 对G2进行2周预测的预测值
模型将预测值写入数据库里的G02_FORECAST表中,将实际值写入G02_TOTAL表中便于查看对比,高铁配餐智能化预测系统WEB界面将直接调用这两个值做出曲线图,图2即为WEB界面实际值与预测值曲线图。

图2 WEB界面实际值与预测值曲线图
4 结束语
本文利用大数据智能算法模型,通过大量的统计数据对高铁配餐的现状进行了系统化的分析,努力实现高铁智能化配餐的目标。智能化的目标主要体现以下几个方面:
(1)预测多样化的需求
预测不同线路、不同车次的冷链类盒饭的需求,并根据季节、假日、突发情况等因素对列车盒饭进行合理调配,努力满足不同旅客的多样化需求,同时降低配送成本。
(2)实现精细化管理
提高精细化管理能力和精准化服务水平,为高铁配餐计划的制订和管理提供数据支持,为旅客提供贴近实际需求的餐饮供应。
(3)提供决策支持
提高模型预测能力,实现提前预知预警,为高铁配餐提供决策支持,实现高铁配餐业务的有的放矢,既满足旅客需求又避免了浪费。
(4)提高管理水平
对高铁配餐作业数据进行收集、保存、处理,提供配餐在线预测系统,自动生成预测报表,进一步提高高铁配餐管理效率和水平。
