基于大数据的数据挖掘技术和应用分析
2019-11-13徐伟
徐 伟
(桐城师范高等专科学校,安徽 桐城 231400)
大数据技术发展带来的巨大信息风暴正在改变人们的生活、工作和思维方式,也是开启重大时代转型的钥匙。全球各国普遍认识到数据作为战略性资源对发展和竞争带来的关键作用,诸多国家开始制定以大数据为核心的战略或发展计划,借此实现业务创新和新兴产业发展。大数据技术能够挖掘海量数据的内在规律,打开全新思维和认知视角,在“互联网+”的时代背景下,为各行各业的发展保驾护航[1]。本文讨论基于大数据的数据挖掘关键技术,理清思路,突出数据挖掘价值,并以电力行业为例,分析大数据挖掘技术在企业生产经营中的应用场景和应用价值。
1 数据挖掘技术
数据挖掘技术是利用算法搜索,从海量数据中提取重要信息和有趣模式的过程[2]。图1所示为数据挖掘的数据模型建立过程。
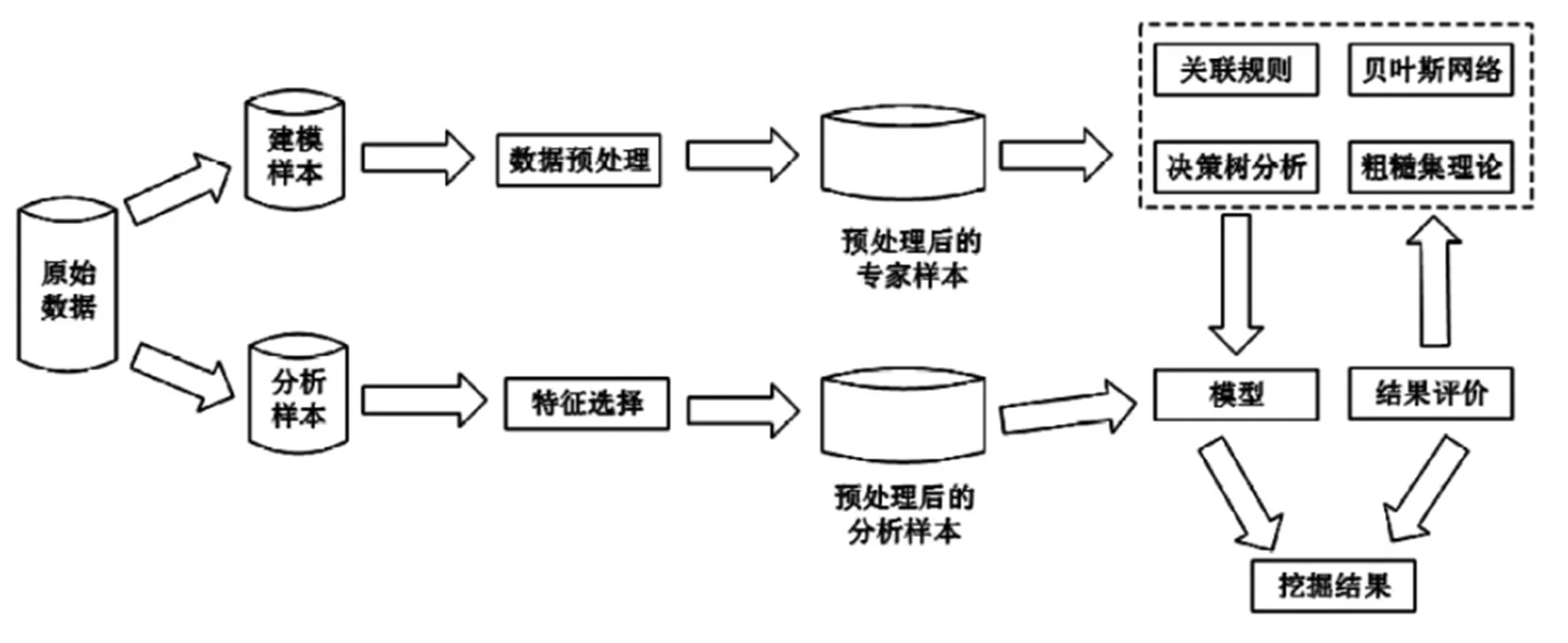
图1 数据挖掘建模过程
第一个阶段是数据的预处理,将采集到的原始数据转化为符合项目需求的有效数据。数据预处理是为了有效弥补原始数据缺陷,保证数据的可靠、完整。数据抽取就是要在海量数据中快速获取与项目有关的数据。
第二个阶段是数据挖掘。根据数据仓库中数据的普遍特征,选择合适的算法和工具,采用案例推理、规则推理、模糊集、遗传算法、神经网络、统计学等方法处理信息。数据挖掘的关键在于明确挖掘任务,并找到合适的挖掘算法。
第三个阶段是知识表示和模式评估。模式主要用于准确表达出数据的挖掘成果,最终构建出有识别能力的完整的表达模式。
2 数据挖掘常见算法
数据挖掘是集统计学、软件开发、机器学习、数据库等技术的综合多学科先进技术,经过大量数据的分析处理,挖掘隐含的高价值信息,为决策提供技术支持。狭义算法是指一些统计算法、分类算法、规则提取算法等。常见的狭义数据挖掘算法包括K-means聚类算法、Apriori布尔型关联规则算法、最大期望算法、K最近邻分类算法等。广义算法泛指一切数据处理、规则提取的方法来发现数据中的信息,能够转化为数据信息进行关键知识提取的方法都可以被看作是数据挖掘,例如图像处理也可以是一种数据挖掘算法[3,4]。下面将着重介绍几种常见数据挖掘算法。
2.1 决策树分类算法
决策树分类算法是一种应用非常广泛的数据挖掘分类算法,包括C4.5和ID3算法。决策树算法是针对给定数据集快速生成分类的有效方法。决策树算法关键是从无次序、无规则的数据集中推理出数据分类的规则,采用决策树方式将分类结果表现出来。决策树分类算法的核心思想是自上而下在树结点利用递归的方式比较数据属性值,不同的属性值决定了树的走向,结论表现在叶子结点处。
决策树分类算法的第一步是按照给定数据集创建决策树,核心是对元数据源的机器学习;第二步是根据第一步建立的决策树进行分类学习。构造决策树是决策树算法的关键步骤,属性和判断逻辑的选择直接决定了决策树的结构和处理效果。一般来说,决策树算法利用剪枝方法处理过分适应的问题,利用统计度量消除这种情况,快速实现数据集分类,提升数据分类效果和速度。
2.2 关联规则
关联规则是非常活跃的一种数据挖掘算法,可以在庞大、无规律、杂乱的数据中建立数据之间的关联关系,对未来可能发生的情况进行预测。关联规则常用置信度、支持度两个指标表示结论的正确性和显著性。
置信度用于衡量A发生的前提下,结论B发生的概率,即P(A|B),表示这一规则在数据中所占比率。置信度是衡量关联规则可信度的指标,一般将设置最小值不小于0.5,以此过滤正确率低的规则。
支持度用于衡量已知A和B均发生的概率,即P(A∩B)。假设最小支持度的目标是过滤数据比率低的关联项,提升关联规则的代表性。
Support(A⟹B)=P(A∩B)
2.3 神经网络和遗传算法
神经网络是模拟人脑神经元建立的数学模型,包括大量分布式单元,通过控制神经元之间的信息实现知识信息学习。神经元的相互关联组成了神经网络,神经元有多个输入输出端,输入端权重系数能够进行调整,通过函数关系输出计算结果[5]。图2所示为单层神经网络拓扑结构示意图。
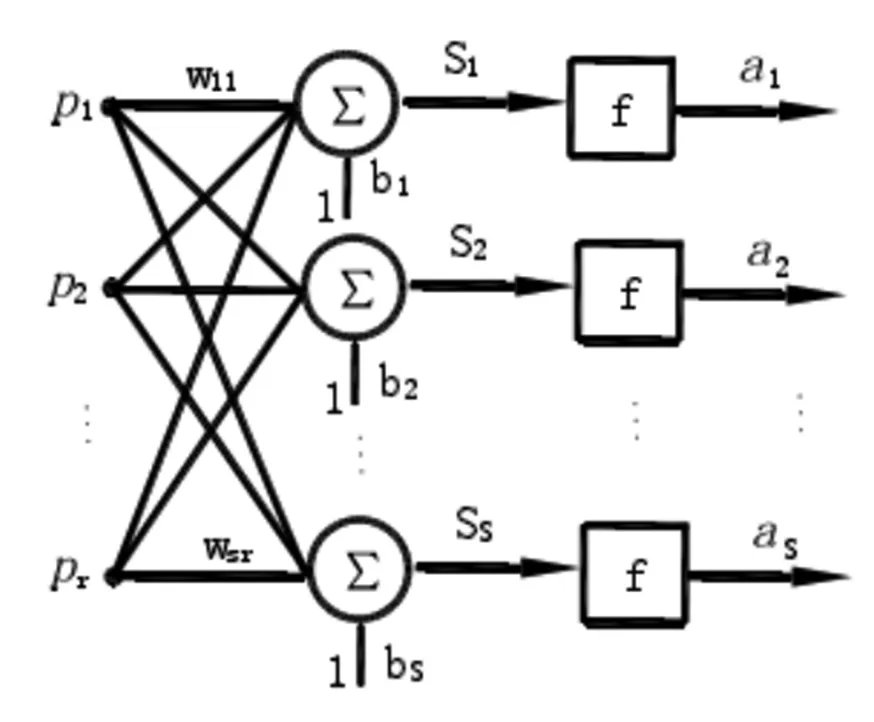
图2 单层神经网络拓扑结构示意图
遗传算法属于一种全局优化算法,主要用于求解最优解,当一个问题有多个答案时,常用遗传算法来选择最优答案。遗传算法利用生物遗传学知识,模仿自然优胜劣汰以及遗传机制,提升个体适应性。利用遗传算法求解问题,首先是抽象问题模型结构,将问题转换为编码,对改组后的编码结构进行赋值、交叉、变异运算等,为机器学习算法的检索提供指导。
3 电力行业的大数据应用
3.1 电力大数据及其特征
电力大数据主要是指在智能电网运营过程中产生的海量数据,既包括电网调度数据、设备运维数据,也包括用户用电数据等。数据通过部署在设备上的传感器、用户家中的智能电表、客户反馈等数据源产生,并汇聚到数据中心统一存储管理[6]。电力大数据是智能电网稳定发展、可靠、高效运行的重要支撑。电力大数据价值挖掘是促进电网精益化管理、优化电力生产调度、建立用户用电行为模型的基础支撑。电力大数据的基本特征表现为:
第一个特点是体量大,随着智能电网的快速发展,电网智能设备终端的部署越来越密集,采集的数据量激增;第二个特点是类型多,电力生产、销售等环节会产生大量结构化和非结构化数据;第三个特点是速度快,电力运营数据的采集响应速度非常快,终端数据量快速增加,对数据存储系统有较高的要求。
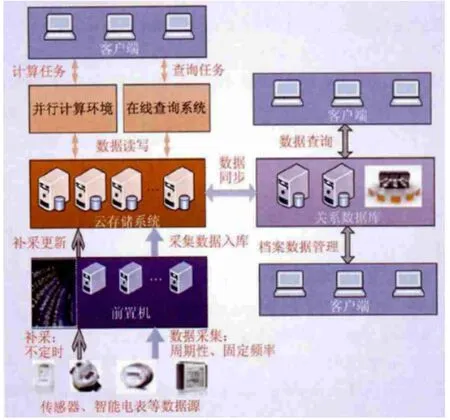
图3 电力大数据流转示意图
3.2 数据挖掘在电力行业的应用
支持分布式挖掘算法是电力大数据分析的关键,通过分析建模、模型运行、模型发布等功能,满足高效的数据挖掘分析需求。电力数据挖掘常用方法包括传统数据统计分析、多维分析、逻辑回归算法、回归分析、聚类算法、关联分析等等。除此之外,还经常使用分类算法、演化分析、异类分析等预测性挖掘算法。针对电力各环节大量存在的文本、视频、图片等非结构化数据,多采用文本分析、图像分析、语音分析等算法加以处理。数据挖掘在电力行业的应用场景有电力负荷预测、设备重过载预警分析、配网故障抢修分析等。
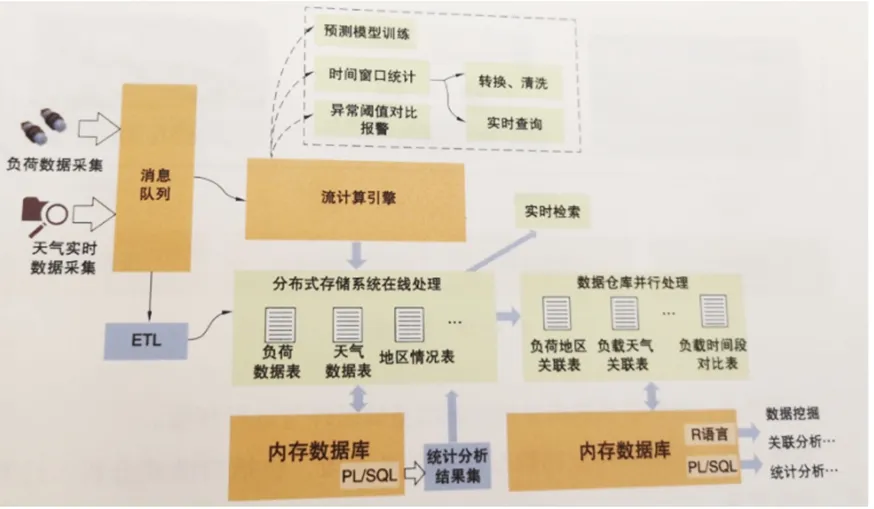
图4 电力大数据挖掘应用
4 基于用电大数据的业扩影响电量预测
业扩报装包括新装、增容、减容和减容恢复等,预测的第一步是建立模型,根据历史用户业扩情况以及业扩对电量的影响规律,建立全行业的业扩电量影响模型,反映业扩对负荷利用率的影响。第二步是将需要分析的历史预测、预测时间等代入定义好的预测模型,推算业扩影响预测电量。
1.数据清洗。电力营销系统中,每天会产生大量业扩报装数据,要进行数据挖掘,第一步是数据清洗。用户业扩报装的原因很多,要消除因为线路变更、接入双电源等申请的报装数据。保留在业扩工单结束之后,能够确切影响用户用电量的数据。
2.数据预处理。用户会在不同时间提起业扩报装申请,所以需要从时间维度进行归一化处理。业扩申请的时间是起始时间,该月份表示为第0个月,后续的每月用电量的时间时段被设置为1-18个月。如果某个时间段内多次发生业扩报装,那么将该用户的数据剔除,因为无法判断哪次业扩报装对用户量产生的影响最大。
3.剔除外部因素。用户的业扩报装申请工单完成之后,用电量的变化可能会受到节假日、天气等因素的影响。如果考虑这些外部因素,则需要利用气象、节假日对用电量的影响模型来全面分析外部因素对负荷利用率的影响。所以此次的研究中,剔除外部因素的影响。
4.模型计算。经过上述步骤之后,要搭建业扩负荷利用率的变化值模型。
业扩负荷利用率变化值根据下式进行计算:
上式中,F表示的是业扩的月负荷率;Tind表示的是用电行业的类型;Mperiod表示的是业扩报装的月份和业扩影响电量统计月份的间隔;KTYPe表示的是业扩报装类型,KTYPe值等于1时业扩类型为新装和增容,值等于2时表示业扩类型为减容销户;S表示的是某个行业中业扩申请用户总数;Ai为不同用电行业中某个业扩申请用户的月度用电量变化情况;Paddi表示的是行业中某个业扩申请用户容量变化。
5.模型应用。选取某个地区2018年3-6月份的业扩报装情况,基于此分析对于第四季度用电量的影响。
第一步:分地区、行业、业扩类型统计二季度业扩数据;
第二步:循环第二季度各个月份的数据进行计算,5月相对10月、11月分别间隔5个月和6个月,根据负荷利用率的变化模型,计算出不同行业、不同业扩类型、不同间隔月份的负荷利用变化值;
第三步:负荷率变化值的计算和电量增长值的计算;
第四步:累加所有月份和地区的业扩的电量增长值。
计算Mstart~Mend月份的业扩对于未来Meffect月份业扩容量情况:
上式中,Mstart和Mend表示的是统计开始和统计结束的月份;Meffect表示容量影响的对应月份;S表示的是某个行业中业扩申请用户总数;Pj表示行业内第j个申请用户业扩容量的变化;F(·)表示负荷率计算函数。
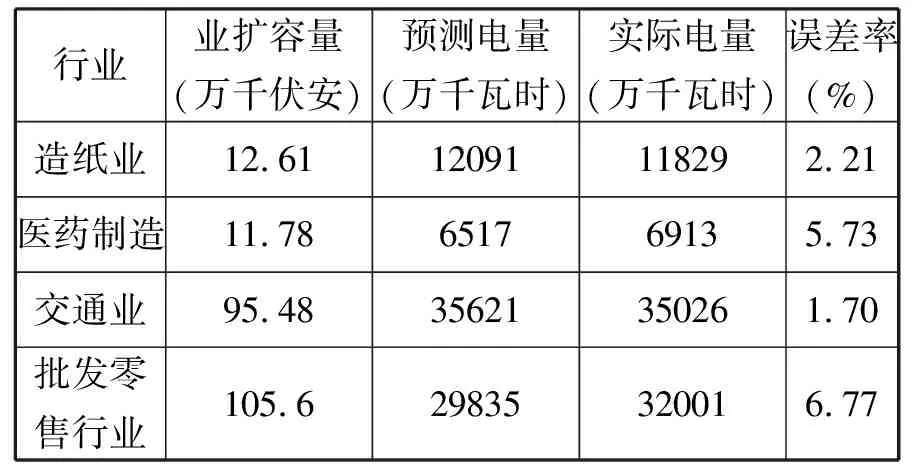
表1 电量预测数据
6.应用成效。选取造纸业、医药制造、交通业、批发零售行业对业扩-电量影响模型进行测试,表1所示为上述行业2018年的电量预测结果。
5 总结
机器学习科学的进步推动数据挖掘技术的发展,产生的数据越多,数据的价值就越大,相应的数据处理的难度就越大。本文梳理了数据挖掘的概念、理论,并介绍了数据挖掘的几个主要算法。以电力行业为例,概括电力行业大数据的特征,分析了基于用电大数据的业扩影响电量预测模型,用实践案例验证了大数据挖掘技术的应用成效。
