基于生成对抗网络的研究综述
2019-11-12葛生国范宝杰尹哲
葛生国 范宝杰 尹哲
摘要:近年来,随着人工智能的发展,生成对抗网络[(Generative Adversaria l Network,GAN)]已成为生成型深度学习模型中最流行的模型之一,并且基于[GAN]繁衍了一些改进型的[GAN]模型,在各个领域进行了研究和应用。首先对[GAN]及其衍生网络进行阐述和对比,然后对[GAN]的应用场景进行介绍,最后对[GAN]做了总结和展。
关键词: 人工智能;生成对抗网络; 深度学习
中图分类号:TP391.4 文献标识码:A
文章编号:1009-3044(2019)25-0197-02
Abstract: In recent years, with the development of artificial intelligence,The Generative Adversarial Networks is one of the most popular models in the generative deep learning model. Firstly, GAN and its derivative network are elaborated and compared. Then, application scenarios of GAN are introduced. Finally, Finally, a summary and development of GAN are made.
Key words:artificial intelligence; generative adversarial networks; deep learning
1 引言
近年來随着深度学习的火热,大量的神经网络被提出,而生成对抗网络是目前最为流行的生成型神经网络,2019年图灵奖获得者深度学习之父[Yann LeCun]称之为过去十年间,机器学习领域最让人激动的点子。[GAN]模型提出后立即被应用到许多深度学习的领域当中去,并且针对[GAN]所存在的一些问题如训练不稳定等提出了一些改进型的[GAN]模型。
本文章节安排如下,在第2节中介绍了[GAN]及其改进模型,在第3节中介绍了[GAN]的主要应用,在第4节中做了总结和展望。
2 [GAN]及其改进模型
2.1 [GAN]模型
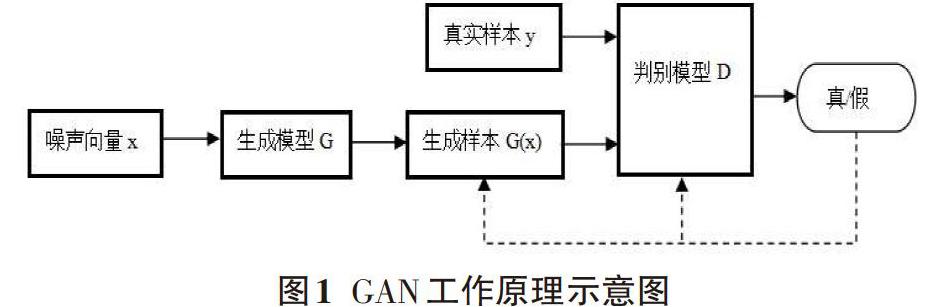
2014年由[Goodfellow]等人[1]提出了[GAN]模型。[GAN]主要有生成网络G和判别网络D组成。其工作原理如图1所示,首先判别器D学习真实样本y,当D对真实样本y有了一定的了解之后用D来观察通过加入随机噪声x生成的样本G(x),然后判断生成样本G(x)是否为真实样本y。生成模型G通过判别模型D的判别真假不断提高自己生成接近真实样本G(x)的能力,而判别模型D通过不断学习真实样本y而不断提高自己判别生成样本G(x)真伪的能力,两个网络通过相互博弈使得各自性能不断提高,直到生成模型和判别模型别无法提升自己,这样生成模型就会成为一个比较完美的模型。
虽然[GAN]的生成效果很好但也存在一些缺陷如训练不稳定、梯度消失、模式崩溃等问题。因此针对[GAN]的这些缺陷又提出了一些改进的[GAN]模型。
2.2 [GAN]的改进模型
(1)[DCGAN]模型[2]。[DCGAN]的原理和[GAN]的原理一样,不过[DCGAN]网络将[GAN]网络的[G]和[D]换成了两个卷积神经网络,通过对两个卷积神经网络做一些特定的限定使得[DCGAN]网络训练起来更加稳定,并且使用得到的特征表示来进行图像分类,得到比较好的效果来验证生成的图像特征表示的表达能力。
(2)[WGAN]模型[3]。[Arjovsky]等人提出了[WGAN]。[WGAN]指出[GAN]使用交叉熵不适合衡量具有不相交部分的分布之间的距离从而导致训练不稳定,因此[WGAN]使用[wassertein]距离去衡量生成数据分布和真实数据分布之间的距离。
(3)[WGAN-GP]模型[4]。鉴于[WGAN]将更新后的权重强制截断到一定范围内导致大多数权值有可能聚集在两个数上,导致梯度消失或梯度爆炸。提出了基于改进[WGAN]的[WGAN-GP]网络。[WGAN-GP]使用梯度惩罚解决了训练梯度消和失梯度爆炸的问题。
(4)[LSGAN]模型[5]。[LSGAN]指出使用JS散度并不能拉近真实分布和生成分布之间的距离,使用最小二乘可以将图像的分布尽可能的接近决策边界,因此[LSGAN]使用了最小二乘损失函数代替了GAN的损失函数。
(5)[BEGAN]模型[6]。[BEGAN]提出了一种新的判别生成样本真伪的方法,用判别器判别生成样本分布和真实样本分布之间的误差距离,当误差距离较小即生成样本分布与真实样本分布相似时,说明生成器生成的样本接近真实样本。因此可以用多种类型的[GAN]结构和损失函数做训练。
(6)[Info GAN]模型[7]。[GAN]的生成模型输入的是一个连续的噪声信号并且没有任何约束,导致GAN无法利用这个噪声信号,并将噪声信号的具体维度与数据的语义特征对应起来,因此不是一个可解释的表达。而[Info GAN]将噪声信号分解为一个不可压缩的噪声和一个可解释的隐变量,使得噪声数据可解释。
(7)[CatGAN]模型[8]。[CatGAN]的判别器模型以较大确信度划分真实样本,而且以较大确信度对真实样本分类到现有的一个类别,但对于生成样本的不确信度却比较大。[CatGAN]采用数据的熵来作为衡量标准,即用熵值得大小来衡量确信度,熵值越大,不确信度越大,熵值越小,确信度越大。
