基于SWT法网络社交平台图像文本检测
2019-11-12乔平安刘佩龙
乔平安 刘佩龙


摘 要: 网络社交平台图像包含丰富的文本信息,而文本检测是提取这些文本信息的基础。针对网络社交平台图像的特点,提出一种基于笔画宽度变换(Stroke Width Transform)的检测图像文本的方法。该方法首先预处理输入的图像,接着按照分布规则检测图像文本区域,然后根据形态规则和笔画特征规则筛除非文本区域,最后输出检测的文本区域结果。仿真实验结果表明,该方法能够准确检测网络社交平台图像文本区域,效率较好。
关键词: 图像文本检测; 网络社交平台; 笔画宽度变换; 文本区域检测; 算法流程; 仿真验证
中图分类号: TN919.8?34; TP391.1 文献标识码: A 文章编号: 1004?373X(2019)20?0048?05
Social networking platform image text detection based on SWT algorithm
QIAO Pingan1,2, LIU Peilong1
(1. School of Computing, Xian University of Posts and Telecommunications, Xian 710100, China;
2. Shaanxi Provincial Key Laboratory of Network Data Analysis and Intelligent Processing, Xian 710100, China)
Abstract: Social networking platform image contains abundant text information, and text detection is the basis of extracting text information. In allusion to the features of the social networking platform image, a method for text image detection based on SWT (stroke width transform) is proposed. In this method, the input image is preprocessed, the image text area is detected according to the distribution rules, and those non?text areas are eliminated according to the morphology rules and stroke feature rules. Finally, the detected results of text area are output. The simulation experimental results show that the method can accurately detect the image text area of the social networking platform, and has better detection efficiency.
Keywords: image text detection; social networking platform; stroke width transform; text area detection; algorithm flow; simulation verification
0 引 言
文本检测已成为计算机视觉与模式识别、文档分析与识别领域的一个研究热点[1?3]。近年来,随着互联网的发展和移动终端的普及,微信、微博、Facebook、推特、ins等网络社交平台已经完全融入大众生活,这些平台上的大量信息成为情感研究、舆情监测、网络环境净化等关注的重点。目前,国内外对自然场景文本检测研究很多,超过80%的关于自然场景论文关注图像文本检测问题[2,4],但是针对网络社交平台上的图像文本的检测却很少。如何检测、识别和提取网络社交平台上的图像文本信息具有重要意义和研究价值。基于此,本文根据大众在这些社交网络平台发布图像的文本特点,提出一种基于笔画宽度变换(SWT)的图像文本检测方法用于检测网络社交平台图像文本信息。
1 相关工作
目前,文本检测中最具代表性的方法为最大稳定极值区域(MSER)法[5?7]和笔画宽度变换(SWT)法[8]。SWT算法能准确地获取图像文本候选区域以及根据网络平台图像文本的分布规则减少图像检测的面积,提高检测效率。
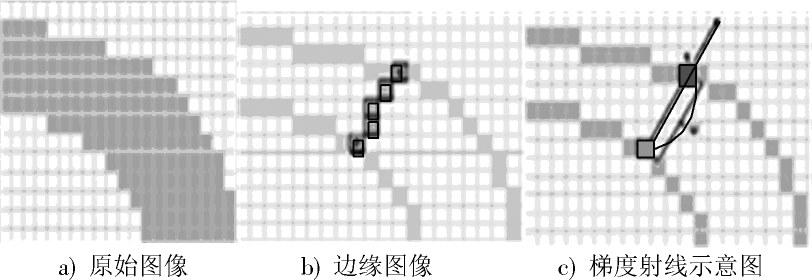
Epshtein等人首次提出SWT算法,利用Canny算法对输入图像进行边缘检测,并计算边缘像素点的梯度方向,沿着梯度方向的路线寻找与之匹配的像素[8]。这个做法使得场景文字检测向前迈出一大步;Yao Cong通过笔画宽度变换 (SWT) 处理获得文本候选区域,用文本级分类器(简单特征+随机森林)过滤非文本区域[9];利用文本间的相似性连接成文本行,再用文本行级的分类器(简单特征+随机森林)[10]进一步过滤背景区域, 较早地实现了任意方向排列的自然场景文本检测任务;Huang Weilin考虑到传统的笔画宽度变换方法在应对图像中包含一些具有不规则梯度方向的边缘时往往不能准确地计算出笔画宽度,所以利用颜色信息来改进笔画宽度算法并提出笔画特征变换 (Stroke Feature Transform)算法[11]。
5) 笔画宽度规则。继续对图像进行笔画特征规则,有的图像会产生长而窄的连通域,这些会被误认为是文本区域,实则不然,在此限制它们的宽高比,不符合要求的剔除掉,对于高宽比较大的区域可以排除。同样限制连通域的直径和笔画宽度的中值比。一块区域的边界框包含不超过两块连通域,以消除文本外围包围线之类,单独的字符通常不出现在图像中,当作噪声剔除。
6) 合并输出。连通域合并形成文本行然后输出。中文合并:同一个文本行里的汉字有相似的笔画宽度,所以平均笔画宽度比值应该在0.8和1/0.8之间,两个汉字之间水平排列,连通域外接矩形的中心点 坐标差值不大于两个连通域之间较高的高度值的0.5。英文合并:两个字母应具有相似的笔画宽度(笔画宽度均值比率小于2.0)。字母的高度比不得超过2.0(由于大写和小写字母之间的差异)。字母之间的距离不得超过宽字母宽度的3倍,另外颜色相同进行合并即可。
4 实验与分析
4.1 实验数据集
为了更好地评定本文的研究,本文根据ICDAR的数据集的图像组成规则,建立了针对中英文文本提取的图像库,图像主要来源于微信、微博、推特、Facebook、Ins等网络社交平台。具体建立步骤如下:
1) 数量组成:200幅当作训练样本的图像和100幅作测试集的图像。
2) 图像分辨率范围:类似的文中采集的图像,分辨率范围为650×260~860×1 024。
3) 难度比例:根据图像文本提取的难度,将图像分为难、中和易三个等级,比例为2∶3∶5。
4) 图像文本内容:ICDAR图像库中文本内容包括路边标志牌文本、建筑物名称等,自建库图像适合聊天或发心情日志等带有感情色彩。
4.2 评价标准
本文采用国际会议ICDAR所提出的评估方法具体如表1所示。
4.3 结果分析
仿真实验数据集采用自建的中英文数据集,在WIN8系统下用Matlab 2016a版本进行仿真实验。
图6和图7是仿真实验的具体实现步骤。
表1 评价的标准

图8中列举了一些本文算法的检测结果。其中第1、2行特意选取符合文本规则的复杂场景图像。图8a)为原图(蓝色框为图像文本规则分布);图8b)为图像检测结果;图8c)为原图;图8d)为它的检测结果,说明该方法也能够在有复杂背景的场景图像中精确地检测文本区域。第3行是网络社交平台图像检测结果。图8e)为原图;图8f)为图像检测结果。第4行是失败的检测案例。图8g)和图8i)为输入的原图(蓝色框为文本规则分布),由于图像文本分布规则不符合,所以图8h)和图8j)原文本区域的文本当作背景筛除。
利用本文方法检测图像文本得到的结果与其他算法相比较,结果如表2所示。无论是准确率或者时间效率,本文算法都较优于其他一些文献检测算法。
图8 其他图像检测

5 结 语
依据网络社交平台图像和自然场景图像的不同点和相同点,提出了基于改进SWT法的图像检测方法,该方法分为4部分:图像输入、分布规则、筛选、输出结果。笔画宽度特征在分布规则之后进行检测,分布规则大大减少了算法处理像素的数量,从而减少了算法时间成本和提高了效率。
仿真实验结果表明效果达到了理想预期,提高了定位的准确性,但是由于SWT算法主要针对英文检测,中文文本检测还有提高的空间,以后还需要继续研究改进。
参考文献
[1] BAI X, SHI B, ZHANG C, et al. Text/nontext image classification in the wild with convolutional neural networks [J]. Pattern recognition, 2016, 66: 437?446.
[2] LIU Y, JIN L. Deep matching prior network: toward tighter multi?oriented text detection [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3456?3461.
[3] SHI B G, BAI X, YAO C. An end?to?end trainable neuralnetwork for image?based sequence recognition and its application to scene text recognition [J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 39(11): 2298?2304.
[4] 王润民,桑农,丁丁,等.自然场景图像中的文本检测综述[J].自动化学报,2018,44(12):3?31.
WANG Runmin, SANG Nong, DING Ding, et al. Overview of text detection in natural scene images [J]. Journal of automation, 2018, 44(12): 3?31.
[5] NEUMANN L, MATAS J. A method for text localization and recognition in real?world images [C]// Proceeding of 10th Asian Conference on Computer Vision. Queenstown: [s.n.], 2010: 770?783.
[6] ZHU A, GAO R, UCHIDA S. Could scene context be beneficial for scene text detection [J]. Pattern recognition, 2016, 8: 204?215.
[7] WEI Y, ZHANG Z, SHEN W, et al. Text detection in scene images based on exhaustive segmentation [J]. Signal processing image communication, 2017, 50: 1?8.
[8] EPSHTEIN B, OFEK E, WEXLER Y. Detecting text in natural scenes with stroke width transform [C]// Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco: IEEE, 2010: 2963?2970.
[9] YAO C, BAI X, LIU W, et al. Detecting texts of arbitrary orientations in natural images [C]// Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 1083?1090.
[10] ANTHIMOPOULOS M, GATOS B, PRATIKAKIS I. Detection of artificial and scene text in images and video frames [J]. Pattern analysis and applications, 2013, 16(3): 431?446.
[11] HUANG W L, ZHE L, YANG J, et al. Text localization in natural images using stroke feature transform and text covariance descriptors [C]// Proceedings of IEEE International Conference on Computer Vision. Sydney: IEEE, 2013: 1241?1248.
[12] 张伟伟.一种针对汉字特点的场景图像中文文本定位算法[J].信息工程大学学报,2014,15(6):729?736.
ZHANG Weiwei. A Chinese image localization algorithm for scene images based on Chinese characters [J]. Journal of Information Engineering University, 2014, 15(6): 729?736.
