基于粗糙集的分布式集值数据属性约简
2019-11-12黄思妤
胡 军,黄思妤,邵 瑞
(重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)
0 引 言
实际获取的数据中,往往存在大量的冗余数据。因此,为了提高知识获取的效率,需要对这些原始数据进行约简。粗糙集是属性约简的重要方法。经典的粗糙集一般用来处理完备的数据,但在实际问题中,由于获取手段的限制以及实际问题的需要,获取到的数据很可能是不完备数据,区间值数据或是集值数据。目前针对集值数据已有许多研究成果。文献[1-3]从不完备信息系统的角度讨论了集值信息系统的处理。文献[4-5]定义了一种容差关系和最大容差类来划分论域,并给出了获取决策规则的方法。文献[6]针对集值信息系统提出了一种优势关系和相应的属性约简算法。文献[7]定义了一个模糊关系,可以用来衡量2个集值对象之间的相似程度。文献[8]提出了一个δ优势关系和相应的粗糙集定义,并基于分辨矩阵给出了属性约简算法。文献[9]提出了2种类型的模糊粗糙近似,并针对所提出的2种近似分别给出了相应的约简方法。
分布存储是目前数据存储的一种普遍形式,即数据存储在网络中的多个数据站点上。针对分布式数据的属性约简问题已有一些研究。文献[10-11]针对垂直分布的数据给出了一种利用不一致对象来求解全局属性核的算法,并通过并行计算条件信息熵来获得近似约简。文献[12]运用基于优势关系的邻域粗糙集理论提出了MapReduce下基于分辨矩阵的属性约简算法,该方法可以有效地约简混合型大数据集里的冗余属性。文献[13]针对符号型数据,定义了分布式决策信息系统下的粗糙集模型,并提出了一种基于正域的属性约简算法,文献[14-15]在这一基础之上,分别将该方法拓展到了连续值数据和不完备数据。但是,目前还没有针对分布式集值数据的相关研究。
本文主要研究分布式环境下集值决策信息系统的属性约简问题,给出了分布式集值决策信息系统的粗糙集模型,并提出了分布式集值决策信息系统下的属性约简算法,最后用实验证明了提出方法的有效性。
1 基本概念
集值信息系统是指在一个信息系统中,属性的值不唯一并且以集合的形式存在。对于集值的理解一般有2种语义:一种是合取语义,另一种是析取语义。本文主要研究在析取语义背景下的情况。
定义1S=(U,C∪D,V,F)是一个集值决策信息系统,对于∀b∈C,x,y∈U,x和y之间的相似度定义为
(1)
从概率的角度出发,μb(x,y)描述了x和y取相同值的概率。对于B⊆C,x和y在属性B下的相似关系RB定义为
(2)
可以证明,RB具有自反性和对称性。
定义2S=(U,C∪D,V,F)是一个集值决策信息系统,对于B⊆C,x∈U,x相对于B的δ-相似类定义为
δB(x)={y∈U|μRB(x,y)≥δ}(0≤δ≤1)
(3)
(3)式中,δ是一个阈值。可以通过δ来调节通过属性子集B所得到的信息粒度。具体地,δ越大,信息粒度越小;δ越小,信息粒度越大。
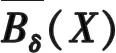
(4)
设U/D={d1,d2,…,dm}是论域上的划分,那么D相对于B的正域为
(5)
根据此定义,正域是在给定的条件属性下,论域里所有可以被确定分类的对象集合,它代表了系统的确定分类能力。
2 分布式集值决策信息系统下的粗糙集模型
设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,其中,Si=(Ui,Ci∪D,V,F)表示1个子决策表,并且U1=U2=…=Un,Ci≠Cj(i≠j)。
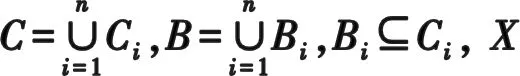
(6)
D相对于B的正域为
POSB(D)={x∈U|∃Si∈Δ∧dj∈U/D(δBi(x)⊆dj)}

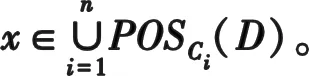
3 分布式集值决策信息系统的属性约简
下面将基于前面提出的分布式集值决策信息系统下的粗糙集模型来研究分布式集值决策信息系统的属性约简。
定理2设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,Φ和Ψ是Δ的2个子集。如果Φ⊆Ψ,则有POSΦ(D)⊆POSΨ(D)。
证明:可由定理1证得成立,故在此省略证明过程。
根据定理2可知,如果在一个分布式集值决策信息系统Δ中添加一个新的子决策信息表,那么Δ的正域将会增大或者维持不变。相应地,如果在Δ中删掉一个子决策信息表,这个时候正域则会减小或者维持不变。
定义5设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,如果POSΔ-{Si}(D)=POSΔ(D)成立,那么在该分布式集值决策信息系统Δ中,子决策表Si相对于D是可约简的。否则,子决策表Si是不可约简的。
定理3设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,如果POSCi(D)⊆POSΔ-{Si}(D)成立,那么子决策表Si是可约简的。
证明:根据上述定理1可以很容易得出POSΔ(D)=POSCi(D)∪POSΔ-{Si}(D),那么如果有POSCi(D)⊆POSΔ-{Si}(D)成立,则不难得出结论POSΔ(D)=POSΔ-{Si}(D),因此由定义5可知,子决策表Si是可约的。证得定理3成立。
定理4设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,当且仅当∃x∈U(x∈POSCi(D)∧x∉POSΔ-{Si}(D))成立,子决策表Si相对于Δ不可约简。
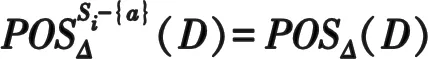
定理5设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,a是子决策表Si的一个属性。如果在子决策表中a相对于D是可约的,那么在该分布式集值决策信息系统Δ中,属性a相对于D也是可约的。如果在子决策表中属性a相对于D是不可约的,在Δ中,属性a不一定是不可约的。
证明:如果在子决策表Si中a相对于D是可约简的,那么从子决策表Si中删掉属性a后其正域保持不变。根据定理1,Δ的正域也保持不变。即证得,在该分布式集值决策信息系统Δ中,属性a相对于D是可约简的。

定义7设Δ={S1,S2,…,Sn}是一个分布式集值决策信息系统,Θ={T1,T2,…,Tn}是Δ的一个子系统,其中∀Ti∈Θ(∃Si∈Δ(Ti⊆Si))。当Θ是Δ相对于D的一个约简时,需满足的2个条件为
①POSΘ(D)=POSΔ(D)
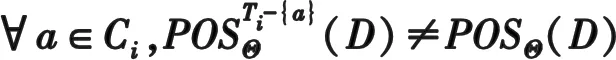
根据上述定义6和定义7可知,一个分布式集值决策信息系统Δ与其约简子系统Θ具有相同的全局正域。删掉约简子系统中的任意条件属性都会导致Θ的正域减小。下面给出分布式集值决策信息系统的属性约简算法。
分布式集值决策信息系统属性约简算法
输入:Δ={S1,S2,…,Sn}
输出:约简子系统Θ
1:Θ=Δ
2:for每一个子决策信息表Si∈Δdo
3: for每一个条件属性a∈Sido
5: 从Θ删掉属性a
6: end if
7: end for
8:end for
对于一个给定的分布式集值决策信息系统,属性约简算法首先选取其中的一个子决策信息表,并对该子决策信息表中的每一个属性根据定义6进行可约性判定,如果可约则去掉该属性,否则保留该属性直至子决策信息中的所有属性都判定完毕。然后,算法继续选取其他子决策信息表进行同样的操作,直至所有子决策信息表都操作完毕。最后,可以得到一个约简的子系统。接下来通过一个实例来说明算法的执行过程。
例如表1,一个分布式集值决策信息系统Δ,该系统有2个子决策信息表,S1和S2。其中,S1有3个条件属性,即C1={a1,a2,a3},S2有2个条件属性,即C2={a4,a5}。则使用上述属性约简算法得到Δ的约简子系统的过程为
令δ=2/5:
对于S1,有
δC1(x1)={x1},δC1(x2)={x2,x3,x8},
δC1(x3)={x2,x3,x4,x6,x8},
δC1(x4)={x3,x4,x6},δC1(x5)={x5,x6},
δC1(x6)={x3,x4,x5,x6},
δC1(x7)={x7},δC1(x8)={x2,x3,x8},
U/D={(x1,x7),(x3,x4),(x2,x5,x6,x8)},
POSC1(D)={x1,x5,x6,x7}。
对于S2,有
δC2(x1)={x1,x2,x4,x7},
δC2(x2)={x1,x2,x3,x4,x8},
δC2(x3)={x2,x3,x4,x8},
δC2(x4)={x1,x2,x3,x4,x7},
δC2(x5)={x5,x6},
δC2(x6)={x5,x6,x8},
δC2(x7)={x1,x4,x7},
δC2(x8)={x2,x3,x6,x8},
POSC2(D)={x5,x6,x8}。

表1 分布式集值决策信息系统
由定理1可得
POSC(D)=POSC1(D)∪POSC2(D)=
{x1,x5,x6,x7,x8}。
删除属性a1,对于S1,有
δC1-{a1}(x1)={x1,x5,x6},
δC1-{a1}(x2)={x2,x3,x8},
δC1-{a1}(x3)={x2,x3,x4,x5,x6,x8},
δC1-{a1}(x4)={x3,x4,x5,x6},
δC1-{a1}(x5)={x1,x3,x4,x5,x6},
δC1-{a1}(x6)={x1,x3,x4,x5,x6},
δC1-{a1}(x7)={x7},
δC1-{a1}(x8)={x2,x3,x8},
POSC1-{a1}(D)={x7},POSC2(D)={x5,x6,x8},
POSC-{a1}(D)=POSC1-{a1}(D)∪POSC2-{a1}(D)=
{x5,x6,x7,x8}。
由定理1可得
POSC-{a1}(D)=POSC1-{a1}(D)∪POSC2-{a1}(D)=
{x1,x2,x3,x5,x6,x7,x8}
由此发现,删除属性a1后全局正域发生了改变,因此可以推断,属性a1是不可约简的。同理,依次对属性a2,a3,a4和a5进行相应的判断,最终可以得出a2和a5是不可约的,a3和a4是可约的。因此,最终可以得到一个约简,约简结果为{a1,a2,a5}。
4 实验结果与分析
为了验证本文所提出方法的有效性,实验中首先运用分布式集值决策信息系统属性约简算法对系统进行属性约简,接着利用约简后的系统来训练分类器,最后通过集成来获得分类的结果。所用的分类器是SVM(support vector machine), GBDT(gradient boosting decison tree), RF(random forest), NB(naïve bayes)和LR(logistics regression),分类集成的方法是将不同分类器上样本的同类别概率加权求和,确定概率最大的类别为该样本的最终类别。
实验所用的5组数据集来自于UCI,数据集的具体信息如表2。为了模拟分布式集值决策信息系统且避免不同的属性顺序对结果的影响,实验将每份数据集的条件属性顺序随机打乱10次,并分别分割成2,3,4份来模拟具有2,3,4个数据站点的分布式集值决策信息系统,即每份数据集进行10次实验,最后将分类结果取平均值。

表2 数据集
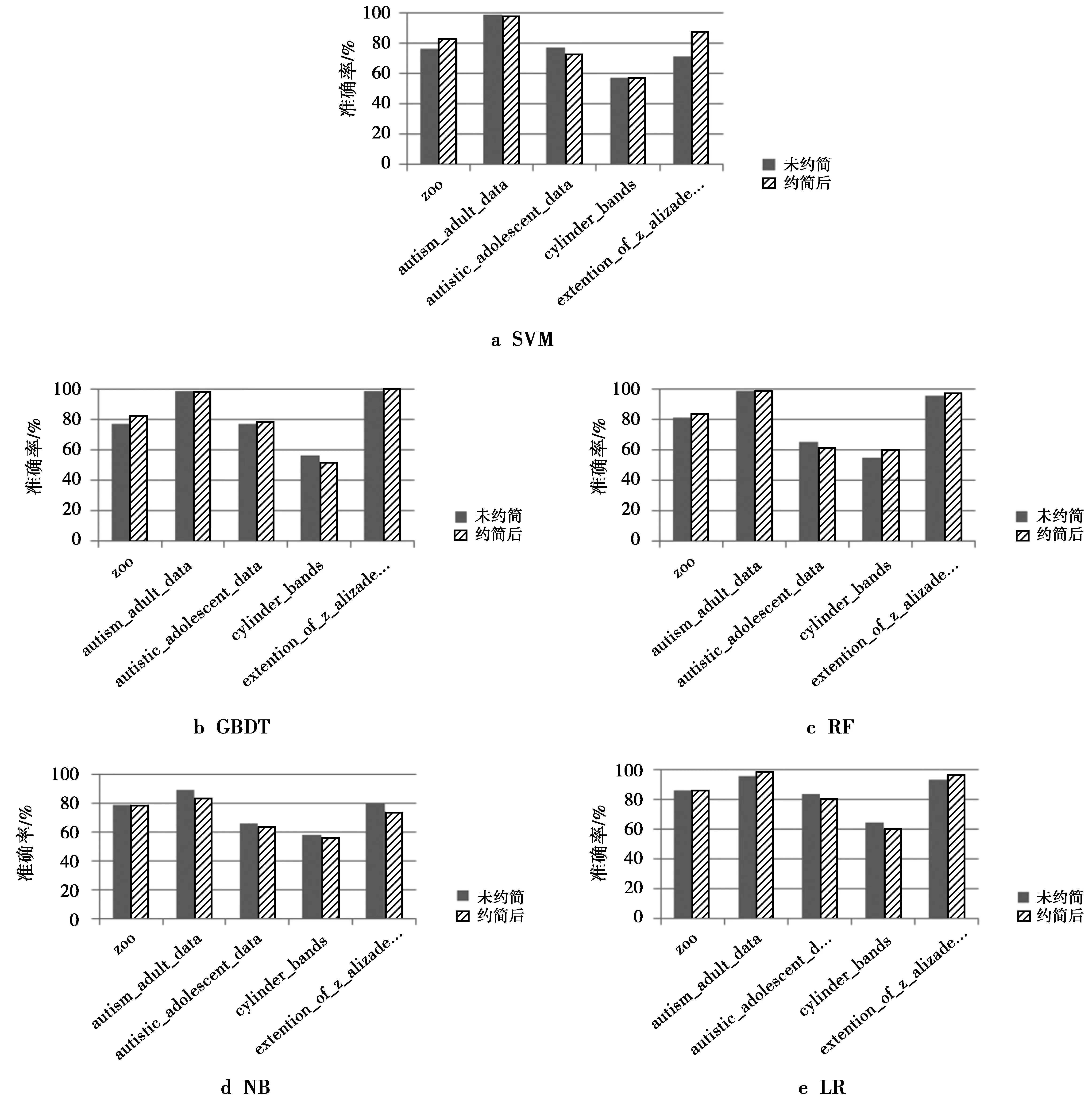
图1 约简前后平均分类准确率(2个站点)Fig.1 Average classification accuracy before and after reduction (two sites)
实验中,数据集zoo, autism_adult_data, autistic_adolescent_data, cylinder_bands和extention_of_z_alizadeh_sani,对应2,3,4个站点所选取的阈值分别为0.24/0.24/0.24, 0.26/0.24/0.24, 0.26/0.24/0.24,0.26/0.26/0.26,0.24/0.24/0.24。
1)2个站点。
约简后每个数据集最终剩余的平均属性个数(四舍五入取整)如表3,属性约简前后集成的平均分类准确率如图1。
2)3个站点。
约简后每个数据集最终剩余的平均属性个数(四舍五入取整)如表4,属性约简前后集成的平均分类准确率如图2。

表3 约简后剩余平均属性个数(2个站点)
3)4个站点。
约简后每个数据集最终剩余的平均属性个数(四舍五入取整)如表5,属性约简前后集成的平均分类准确率如图3。

表4 约简后剩余平均属性个数(3个站点)

表5 约简后剩余平均属性个数(4个站点)
从表3~表5可以看出,本文所提出的属性约简算法使得所有数据集都得到了一定程度的简化。其中,对于分割成2个站点的数据集来说,extention_of_z_alizadeh_sani数据集约掉的属性最多,相应的简化程度最高;分割成3个站点的数据集中,cylinder_bands数据集约掉的属性最多,得到的简化程度最高;分割成4个站点的数据集中,extention_of_z_alizadeh_sani数据集约掉的属性最多,得到的简化程度最高。由图1—图3可以看出,所有数据集在约简后的分类准确率相对于原始数据来说,其分类准确率基本保持不变,有的约简后的数据集的分类准确率甚至更高。其中,数据集extention_of_z_alizadeh_sani的表现效果最好,该数据集在被分割成不同的站点时均能得到很高程度的简化,且在所有分类器上几乎都能得到比原始数据集更高的分类准确率,说明约简去掉了原始数据集中冗余的甚至是具有干扰作用的属性,从而提高了分类的准确率。总之,本文提出的针对分布式集值决策信息系统的属性约简算法,可以对系统进行一定程度的简化,并且保持系统的分类能力基本不变。
5 结 论
为了简化分布式集值决策信息系统,同时保持它的分类能力不改变,本文给出了分布式集值决策信息系统下的粗糙集模型,并基于该模型提出了相应的属性约简算法。实验结果表明,该方法可以有效地去除系统中的冗余属性并且保持系统的分类能力基本不变,有效地解决了分布式集值数据的属性约简问题。该方法阈值的选取会对分类的准确率产生一定的影响,如何选取合适的阈值将是本文未来的研究工作。
