基于BLSTM-CRF中文领域命名实体识别框架设计
2019-11-05张俊飞毕志升王静吴小玲
张俊飞 毕志升 王静 吴小玲


摘 要:为在不依赖特征工程的情况下提高中文领域命名实体识别性能,构建了BLSTM-CRF神经网络模型。首先利用CBOW模型对1998年1月至6月人民日报语料进行负采样递归训练,生成低维度稠密字向量表,以供查询需要;然后基于Boson命名实体语料,查询字向量表形成字向量,并利用Jieba分词获取语料中字的信息特征向量;最后组合字向量和字信息特征向量,输入到BLSTM-CRF深层神经网络中。实验结果证明,该模型面向中文领域命名实体能够较好的进行识别,F1值达到91.86%。
关键词:BLSTM-CRF;CBOW;Boson;命名实体识别
中图分类号:X853 文献标识码:A
Abstract:The BLSTM-CRF neural network model is built to improve the performance of Chinese domain named entity recognition in the absence of feature engineering.First,the CBOW model was used to carry out recursion training of negative sampling on the corpus of People's Daily from January to June in 1998 to generate a low-dimensional dense word vector table for the query needs;then,based on Boson entity corpus,the word vector was formed by querying the word vector table,and the information feature vector of the words in the corpus was obtained by using the Jieba participle;finally,the combined word vector and word information feature vector are input into BLSTM-CRF deep neural network.Experimental results show that the model can be well identified for the Chinese domain named entities,and the F1 value is up to 91.86%.
Key words:BLSTM-CRF;CBOW;Boson;named entity recognition
命名实体识别是自然语言处理中的一项基础任务,旨在从文本中识别命名实体如人名、地名和组织机构名等。命名实体识别是信息提取[1]、问答系统[2]、句法分析[3]、机器翻译[4]等应用领域的重要基础,其研究具有重要意义。早期学者利用命名实体识别规则或机器学习方法实现对中文命名实体识别。张小衡等[5]利用相应的规则实现对中国内地、香港、台湾高校名称的识别;程志刚[6]提出了采用基于规则和条件随机场相结合的中文命名实体识别研究方案对人民日报的语料进行人名、地名、机构名的识别。冯艳红等[7]基于词向量和条件随机场在渔业领域语料和Sogou CA语料上进行了领域术语识别,F值达到0.9643。近年来,随着人工智能技术的发展,相比基于规则和机器学习的命名实体识别方法,基于神经网络的深度学习方法因不依赖特征工程而备受关注。LSTM-CRF模型是当前命名实体识别比较流行的组合,最早由Collobert[8]提出,随后国内外学者对LSTM-CRF模型展开了深入研究。Huang[9]把BLSTM-CRF模型应用于序列标注;买买提阿依甫[10]通过CNN提取维吾尔单词的字符特征结合单词词性和词向量,应用BLSTM-CRF模型实现维吾尔命名实体识别,F1值达到91.89%;Dong[11]利用字的偏旁部首特性结合LSTM-CRF模型实现命名实体识别。
从当前研究可以看出,深度学习的命名实体识别不使用特征工程;在神经网络输入层尽量丰富输入数据信息,以提高识别准确率。基于1998年1月-6月人民日报语料和Boson命名实体识别语料,本文提出一种基于BLSTM-CRF的神经网络模型,首先利用Word2Vec訓练人民日报语料,输出字向量数据,以供Boson语料查询,形成Boson语料字向量;然后通过对Boson命名实体语料进行Jieba分词,获得字的信息特征向量;最后组合字向量和字信息特征向量输入到BLSTM-CRF模型中进行训练,从而得到面向中文领域命名实体识别模型。
1 框架整体设计
图1为本文提出的BLSTM-CRF模型框架。本模型共有三部分组成:输入层、BLSTM模块、线性CRF模块。输入层输入信息包括:字向量和字的信息特征向量。字向量通过查找预先利用Word2Vec训练好的字向量表得到;字的信息特征向量,需要对输入句子分词处理,然后进行标注获得。字向量和字信息特征向量组合喂入BLSTM模块中,输出各种标记序列组合,再进行线性CRF处理,得到一个最优的标记序列。
1.1 字向量
將文本应用于深度学习网络中,首先需要对输入数据进行向量化表示。文本向量化表示有两种:One-Hot方式和分布式方式[12]。One-Hot方式实现字符0和1表示的长向量,向量的长度是语料词典的大小。One-Hot表示容易遭受向量维数灾难,数据非常稀疏(大部分为0值),没有考虑字符间的语义和语法关系。分布式表示将字符从One-Hot表示向量映射为低维、稠密实数向量,且考虑了字符间的上下文信息环境,克服了One-Hot存在的缺陷。Mikolov等人[13]提出CBOW(Continuous Bag-of-
Word)和Skip-gram(Continuous Skip-gram)两个分布式表示模型。CBOW在训练效率上高于Skip-gram,[14]故本研究中采用CBOW模型来训练字的分布式特征。
CBOW模型包含三层:输入层、投影层、输出层,其模型框架如图2所示。以语料中“大江截流展宏图”语句为例,输入层为字符“流”的上下文,其中 wt-e,wt-e+1,…,wt-e-1,wt+e表示“流”上下文“长江截展宏图”对应的各个字的One-Hot向量表示,窗口大小c为3;投影层将6个输入层向量求和(或求均值、直接拼接);输出层是被One-Hot编码的输出字“流"。其目标函数为:p(wt|wt,wt-e+1,…,wt-e-1,wt+e),在上下文环境下求得wt的概率最大化。通过对目标函数的训练,获得每个字的k维向量。k值越大训练成本越高,模型效果越好,本研究k为150。
本研究以1998年1月-6月人民日报为字向量训练语料,使用Python Gensim工具构建Word2Vec的CBOW模型、输出层使用负采样降低训练复杂度,提高训练效率,最终生成了字向量Vec.txt文件。
1.2 Boson命名实体语料处理
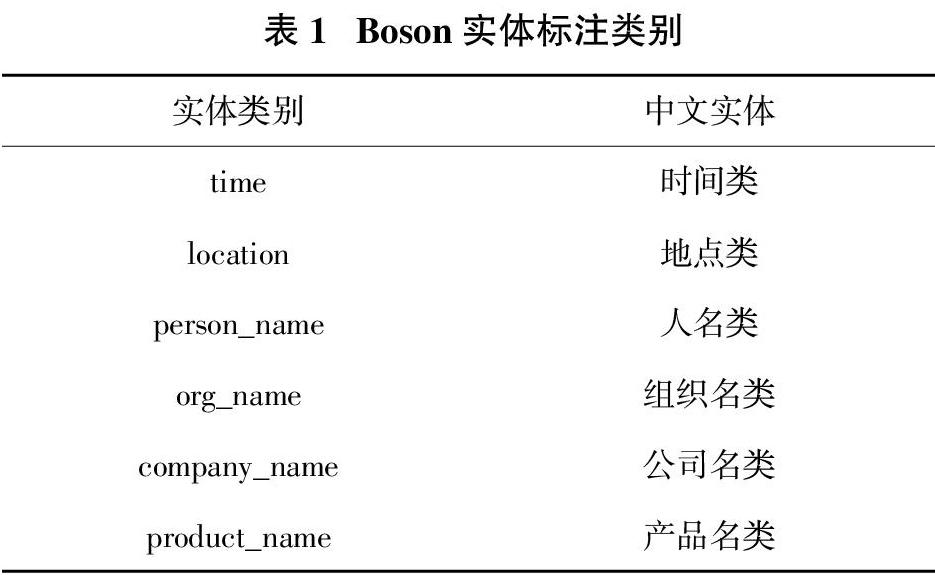
Boson命名实体采用UTF-8编码进行标注,每行为一个段落标注,共包括2000段落。所有的实体标注格式为:{{实体类型:实体文本}}。Boson语料中数据如:{{product_name:浙江在线杭州}}{{time:4月25日}}讯(记者{{person_name: 施宇翔}} 通讯员 {{person_name:方英}})。Boson标注的实体类别如下表1所示。
Boson命名实体语料首先采用BIEO标记(B表示词开头,I表示词中间,E表示词结尾,O表示其他)方法进行处理,按照标点符号分成短句,每个短句为一行。标记结果如:
浙/B_product_name江/I_product_name在/I_product_name线 /I_product_name杭/I_product_name州/E_product_name 4/B_time月/I_time 2/I_time 5/I_time日/E_time讯/O(/O记/O者/O施/B_person_name宇/I_person_name翔/E_person_name通/O讯/O员/O方/B_person_name英/E_person_name)。
然后,给每个字(char)和标签(tag)分配一个id,并将char_to_id,id_to_char,tag_to_id,id_to_tag的关系数据存在Boson.pkl中,以供本设计模型调用。
本文设计命名实体识别模型,其输入层数据不仅仅包含字向量还有字的特征向量。以“浙江在线杭州…讯”为例,首先查找Vec.txt获取字向量表示,同时采用Jieba分词加载外部词典Boson.dic(针对Boson语料设计的词典)实现对Boson语料分词处理,获取其信息特征[1,2,2,2,2,3,…,0](1表示词的开始,2表示词中间位置,3表示词结束位置,0表示单个词)。在使用字信息特征向量之前,先对其进行Min-Max Normalization归一化处理。
1.3 BLSTM模块
长短时记忆网络(LSTM)[15]是一种循环网络(RNN)模型的变种,通过引入一个记忆单元解决了RNN训练过程中的长距离依赖问题。记忆单元由记忆细胞、输入门、遗忘门和输出门组成,其中记忆细胞存储和更新历史信息,门结构利用sigmoid函数决定信息的保留程度。
(1)实验1和实验2对比分析
实验1和实验2对比分析可知,本文提出的识别框架模型识别效果F1值有2.77%的提升,这说明输出端采用线性CRF比softmax更能判断正确的标注序列。softmax层的输出是相互独立的,只考虑输出概率越大越好,没有计算输出标签之间的语法关系;线性CRF不仅考虑了输出概率的大小,还通过转移矩阵衡量了输出标签之间的转移分数,保证了标签之间的正确的语法关系。
(2)实验1和实验3对比分析
实验1和实验3对比分析可知,本文提出的识别框架模型识别效果F1值有2.06%的提升。本文提出的识别框架输入层的输入数据包括字向量和字的信息特征向量。字的信息特征向量的加入,丰富了输入信息,使得模型对领域命名实体的识别更加有效。
综上,在Boson领域语料命名实体识别任务上,本文提出的通过Jieba分词获取字的信息特征来补充字向量信息,以及BLSTM和CRF模型的融合,都是有效提高领域命名实体识别的途径。
3 结 论
文本针对Boson命名实体语料,提出了获取字的信息特征补充字向量信息,进而构建BLSTM-CRF神经网络模型,在Boson语料上取得了很好的识别效果。针对中文命名实体领域识别体现在如下两点:①采用Word2Vec方法,利用CBOW模型产生的Vec.txt具有特殊性。不同的训练语料可能产生不同的字向量数据,字向量维度和包含的字都可能不同。②利用Jieba分词获取的字信息特征具有独特性。针对Boson语料设计了外部分词词典Boson.dic,对Boson中的专属词语分词准确,增强了字的信息特征的有效性。提出的基于Boson中文领域命名实体识别框架针对专属领域的,通过选择字向量训练语料、设计该领域的专属词语分词词典,更加准确的识别命名实体。
参考文献
[1] 田家源,杨东华,王宏志. 面向互联网资源的医学命名实体识别研究[J]. 计算机科学与探索,2018,12(06):898—907.
[2] 于根,李晓戈,刘睿,等. 基于信息抽取技术的问答系统[J]. 计算机工程与设计,2017,38(04):1051—1055.
[3] 杨锦锋,于秋滨,关毅,等. 电子病历命名实体识别和实体关系抽取研究综述[J].自动化学报,2014,40(08):1537—1562.
[4] 张磊,杨雅婷,米成刚,等. 维吾尔语数词类命名实体的识别与翻译[J]. 计算机应用与软件,2015,32(08):64—67+109.
[5] 张小衡,王玲玲. 中文机构名称的识别与分析[J]. 中文信息学报,1997(04):22—33.
[6] 程志刚. 基于规则和条件随机场的中文命名实体识别方法研究[D]. 武汉:华中师范大学,2015.
[7] 冯艳红,于红,孙庚,等. 基于词向量和条件随机场的领域术语识别方法[J].计算机应用,2016,36(11):3146—3151.
[8] COLLOBERT R,WESTON J,BOTTOU L,et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research,2011,12(8): 2493—2537.
[9] HUANG Z,XU W,YU K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991,2015.
[10] 买买提阿依甫,吾守尔·斯拉木,帕丽旦·木合塔尔,等. 基于BiLSTM-CNN-CRF模型的維吾尔文命名实体识别[J].计算机工程,2018,44(08):230—236.
[11] DONG C,ZHANG J,ZONG C,et al. Character-based LSTM-CRF with radical-level features for chinese named entity recognition[C]//International Conference on Computer Processing of Oriental Languages. Springer International Publishing,2016: 239—250.
[12] 温潇. 分布式表示与组合模型在中文自然语言处理中的应用[D]. 南京:东南大学,2016.
[13] MIKOLOV T,SUTSKEVER I,CHEN K,et al. Distributed representations of words and phrases and their compo-sitionality[J]. Advances in Neural Information Processing Systems,2013:3111—3119.
[14] 孙娟娟,于红,冯艳红,等.基于深度学习的渔业领域命名实体识别[J].大连海洋大学学报,2018,33(02):265—269.
[15] HOCHREITER S,SCHMIDHUBER J. Long Short-term memory[J]. Neural Computation,1997,9(8):1735—1780.
[16] 李丽双,郭元凯. 基于CNN-BLSTM-CRF模型的生物医学命名实体识别[J]. 中文信息学报,2018,32(01):116—122.
[17] SRIVASTAVA N,HINTON G,KRIZHEVSKY A,et al. Dropout: a simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research,2014,15(1): 1929—1958.
