针式打印医疗发票的CNN-RNN识别方法
2019-11-04长江大学电子信息学院湖北荆州434023
(长江大学电子信息学院,湖北 荆州 434023)
当前,医院里存在大量的纸质医疗发票,作为医院结算费用的重要统计信息,这些票据需要入库存储。而传统的人工录入方式需要花费很多时间,成本高,错误率也较高,是医疗产业中的一个薄弱环节。随着光学字符识别(OCR)技术在模式识别领域不断的发展,其识别率有了很大程度的提高,能够快速准确地识别医疗发票中的文本信息,在发票的自动识别与入库中起关键作用。截止目前,主要的文本识别方法有模板匹配法和几何特征抽取法等,这些识别方法均有一定的局限性,导致识别精度较低,
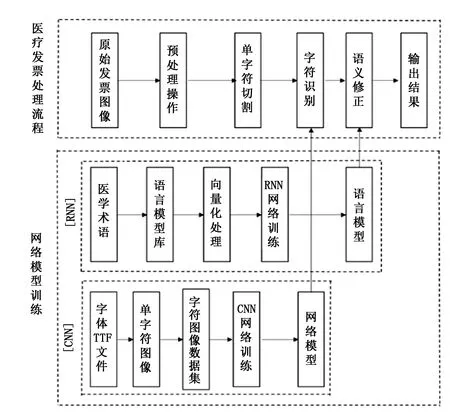
图1 CNN-RNN识别原理框图
尤其在有噪声的情况下识别效果更差。医疗机构为了节约成本,发票中的待识别信息都是采用针式打印机来打印的,这些针式打印的文字中存在断点,使用传统方法时识别精度低,一般的文本识别[1]方法不再适用。为此,笔者结合数字图像处理技术与深度学习方法[2]来识别医疗发票中的针式打印文本信息。
1 CNN-RNN识别方法
医疗发票识别的原理框图如图1所示,识别的具体过程主要包含3个模块,分别为CNN单字符识别模块、RNN语义修正模块[3]以及医疗发票图像处理模块。
CNN单字符识别模块是利用CNN[4]擅长于从二维图像中提取特征的优势来提取单字符图像的个性特征,从而实现针式打印医疗发票中单个字符的识别。
RNN语义修正[5]模块则是根据循环神经网络在时序信息处理方面的优势来实现医学术语的语义检测与修正,已获得更理想的针式打印医疗发票识别率,其基本原理是:RNN网络中的每个神经元都拥有记忆功能,且每个神经元之间可以实现信息的传递,同时也能够更深层次地揭示数据间隐藏的信息,适合于处理时序信息。
医疗发票图像处理模块主要通过数字图像处理技术将针式打印的发票中的文字图像处理成卷积神经网络能够识别的单字符图像,医疗发票图像处理的基本流程为:首先通过图像采集设备采集到一张原始的针式打印医疗发票图像,为了得到分辨率较高的医疗发票图像,原始的发票图像需要进行预处理操作;为了让卷积神经网络能够识别发票中的文字信息,还需要将预处理得到的发票图像中的文字切割为单个字符图像,再将单个字符图像交给卷积神经网络来识别。
基于CNN-RNN模型的医疗发票识别方法的具体流程图如图2所示。

图2 发票识别具体流程图
1.1 发票图像处理
医疗机构为了节约成本,使用针式打印机来完成医疗发票的打印,使得发票中待识别信息中的文字存在断点,其分辨率较低,且发票采集过程中存在偏差,导致采集到的发票存在倾斜等问题,不便于识别。为了提高发票中针式打印信息的识别率,有必要对采集到的原始发票图像做预处理操作。其预处理具体包括:发票图像的校正、灰度化处理、阈值分割去噪、断点处理等,其中,灰度化处理将彩色的医疗发票图像变为单通道图像,便于后面的阈值分割去噪;断点处理的核心是对图像进行高斯模糊与图像增强操作,以消除文字中的断点。经过预处理操作后,发票中待识别部分的信息被保留下来,且发票中的字符中不再有断点,即得到一张分辨率较高的单通道图像,最后进行单字符切割操作,得到待识别的单字符图像。发票图像处理的基本流程如图3所示,而断点处理前后的对比图如图4所示。

图3 发票图像处理流程图

图4 断点处理前后的文字图像对比图
1.2 单字符识别
对于针式打印医疗发票识别,通常是将发票图像中的文字信息转化成方便信息查询和和存储的文本信息[6],首先通过医疗发票图像处理模块得到分辨率较高的单个字符图像,再利用卷积神经网络强大的特征提取优势从单字符图像中提取出字符的特征并实现单个字符的识别,最后将CNN识别得到的语段输入到RNN网络中进行医学术语的语义检测与修正,从而得出最终的发票信息识别结果。
CNN属于深度神经网络中的网络模型之一,在二维图像处理中取得了显著的成果,隐藏层由卷积层和池化层交替构成的多个卷积池化小单元组成,具体有多少个这样的卷积池化小单元则根据具体处理问题的复杂程度决定[7]。CNN的网络结构图如图5所示。

图5 CNN结构示意图
CNN中卷积池化小单元是由一个卷积层、一个激活函数层、一个池化层和批量归一化层构成,其卷积层中的每个神经元与前一层的局部感受区域相连来提取特征,然后通过激活函数得到该层的特征图,激活函数层的作用是为了增加神经网络模型的非线性,从而使提取到的特征具有位移不变性,还可以降低计算机的内存占用。卷积运算的计算公式为:
(1)
式中:l代表卷积层所在的层数;k为卷积核;b为偏置大小;Mj表示选择的输入特征图组合;f是激活函数。池化层也称为下采样层,作用是对卷积层得到的特征图进行降维处理,以简化卷积层输出的特征,便于后续处理。最后的批量归一化层使得网络可以快速收敛,以加速网络模型的训练。
笔者比较了多个CNN模型,最后选择Alexent网络来实现针式打印文本的识别。但用多个单字符图像来训练Alexent网络模型时,由于样本量较大,需要消耗大量的时间以及计算机资源来训练好一个模型,虽然分布式并行计算可以加速模型的训练,但占用的计算机资源并没有减小。为解决这一问题,试验中对这个网络做了一系列的调整,调整后的F-Alexent网络的结构如图6所示。

注:Conv代表卷积层;Pool代表池化层。图6 微调后的F-Alexent网络图
F-Alexent网络模型的改进具体表现在:①将Alexent网络的第1个卷积层的卷积核大小由11×11变成9×9;②用2个3×3大小的卷积核代替第2层的5×5的卷积核;③多增加一层卷积层conv6;④将每一层网络的特征图数量减少,即通过改变卷积核的大小、特征图和卷积层的数量来降低计算机资源的占用。
需要注意的是,笔者用字体文件生成的训练集的图像大小为100×100,为了得到理想的识别率,识别阶段送入卷积神经网络的单字符文本图像也要是同样的分辨率,因此,在单字符切割后还需要对得到的文本图像做归一化处理。
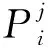
1.3 语义修正
医疗发票中语义修正的具体过程为:将多张二维的单字符图像依次输入到CNN中后,用改进后的Alexent网络完成多个文本图像的识别,最终输出多个语段。假设语段的个数为S,则这些语段可以用序列L=[L1,L2,…,Li, …,Ls]表示,其中1≤i≤S。在输入到RNN进行语义修正之前,需要对多个语段进行向量化处理,即Li表示一个大小为M×N的向量,将这些向量作为RNN的输入,且Li作为RNN在i时刻的输入。CNN-RNN模型的示意图如图7所示。
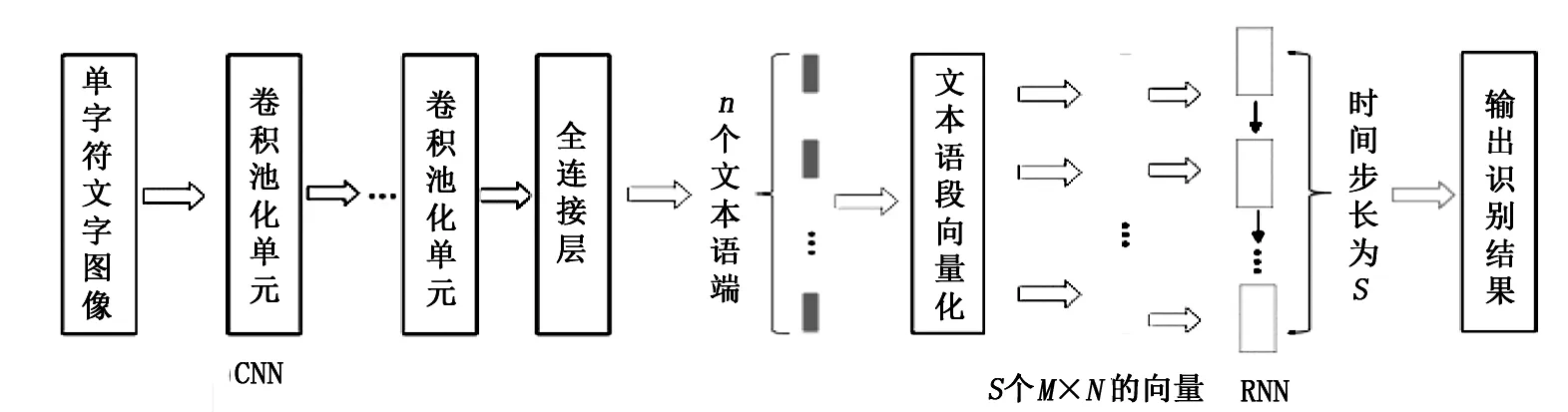
图7 CNN-RNN模型示意图
RNN利用各神经元之间的记忆功能来处理时序信息,能够更深层次的揭示数据间隐藏的特点,输出结果不仅与当前时刻输入的信息和权重有关,还与之前输入的信息相关[8]。RNN结构示意图如图8所示。

图8 RNN结构示意图
图8中,xt、ht、yt分别代表t时刻RNN网络的输入状态向量、隐藏层的状态向量和输出状态向量。隐藏层的作用就是将当前的输入与前一层的输出相结合,再通过激活函数激活神经元,就能够获得当前时刻的输出信号。t时刻的隐藏层状态向量和输出状态向量可以用公式表示为:
ht=g(uxt+vht-1)
(2)
yt=f(wht)
(3)
式中:u表示输入层与隐藏层间的权重矩阵;v为前后时刻隐藏层间的权重矩阵;w表示隐藏层与输出层间的权重矩阵;g为隐藏层的非线性激活函数,如sigmoid函数;f表示输出层的激活函数,一般是线性的,如softmax线性分类函数。
训练RNN模型进行医学术语修正的过程同样属于有监督学习,首先从CNKI、PubMed等网站上搜索并下载7000多条医学术语形成语言数据库,再对语言数据库中的医学术语打上标签,构成训练模型所需的训练集,将大量的训练样本做矢量化处理后送入RNN中,最后得到可实现医学术语修正的RNN模型。需要注意的是,CNN-RNN模型在训练时采用交叉熵代价函数来加快网络参数的调整和网络的训练速度。
2 试验结果与分析
2.1 单字符识别文本数据集
试验所采用的单字符图像数据集是从Windows自带的宋体字体文件中提取得到的,笔者对提取到的单字符图像做了一些处理,包括文字扭曲、文字倾斜、笔画粘连、笔画断裂以及加入椒盐噪声等。该操作不仅增大了样本量,还在一定程度上加强了CNN模型泛化能力。将处理后的单字符图像大小设置为100×100,这些单字符图像中的80%用于训练CNN模型,剩下20%的单字符图像用来测试得到的网络模型的好坏,若测试的结果不理想,则需要调整网络参数并重新进行网络训练,直到获得理想的网络模型。
2.2 医学术语语义修正数据集
利用RNN在自然语言处理方面的优势来实现医学术语的语义修正。通过CNKI、PubMed等网站下载7000多条医学术语文本文件,并将每条医学术语的最大长度设置为10个字符,以减少后期计算机资源的占用。将每条医学术语矢量化为M×N大小的向量,即RNN网络的训练数据集为7000多个大小为M×N的向量,再将其输入到RNN网络进行训练。
将识别准确率作为评价指标,识别准确率R的计算公式为:
(4)
式中:N为测试集中总的字符图像个数;n为正确识别的字符图像个数。
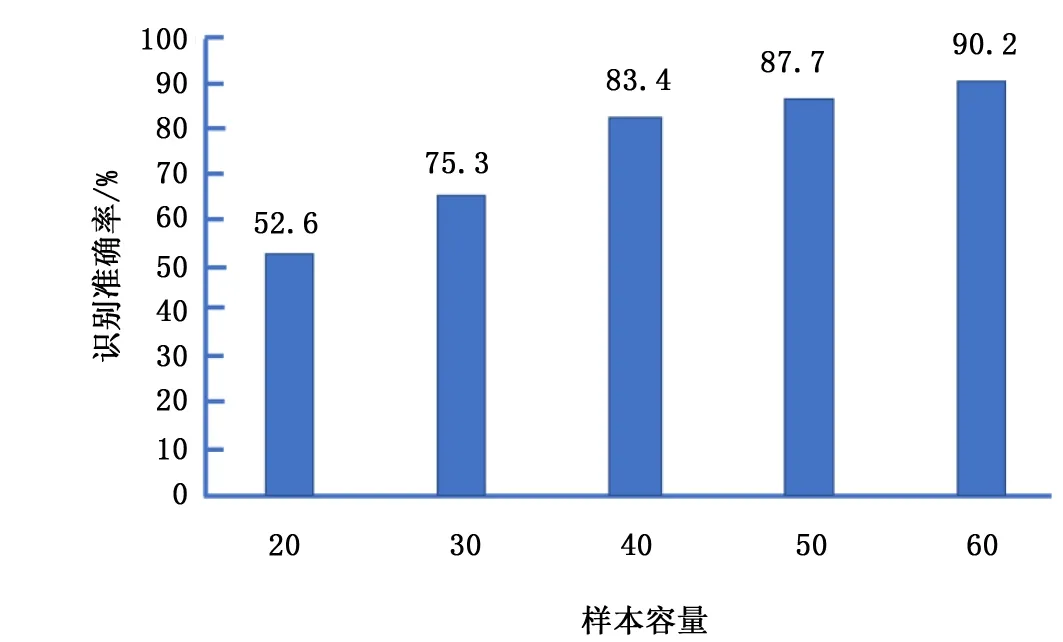
图9 不同的样本容量下发票识别准确率
2.3 网络训练样本量对识别率的影响
首先来研究样本容量对F-Alexent网络模型识别准确率的影响,将提取到的3755个字符图像经过处理后依次生成20、30、40、50、60张单字符图像分别作为训练集,并采用训练得到的模型来识别收集到的200张医疗发票,图9给出了采用不同的样本量对F-Alexent网络模型识别准确率产生的影响。
由图9可知,当训练F-Alexent网络的样本量增加时,其模型识别准确率也随之提高,当样本量较少时,由于此时网络并没有达到收敛状态,因此识别准确率相对较低。当单个字符的样本量达到60时,其识别准确率达到90.2%,网络处于收敛状态。
2.4 迭代次数对识别率的影响
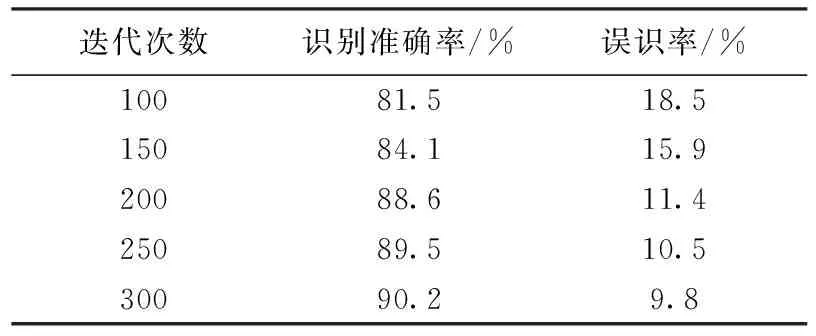
表1 不同迭代次数下识别准确率大小
在拥有相同大小样本量的情况下,迭代次数必然会对识别准确率产生影响,表1给出了不同迭代次数下识别准确率的大小。
由表1可知,当迭代次数增加时,医疗发票的识别准确率不断提高。但当迭代次数增大到300次后,网络达到收敛状态,识别准确率不再提高,网络的损失值趋于稳定。其Alexent与改进的F-Alexent在训练过程中损失值随迭代次数的变化关系如图10所示。
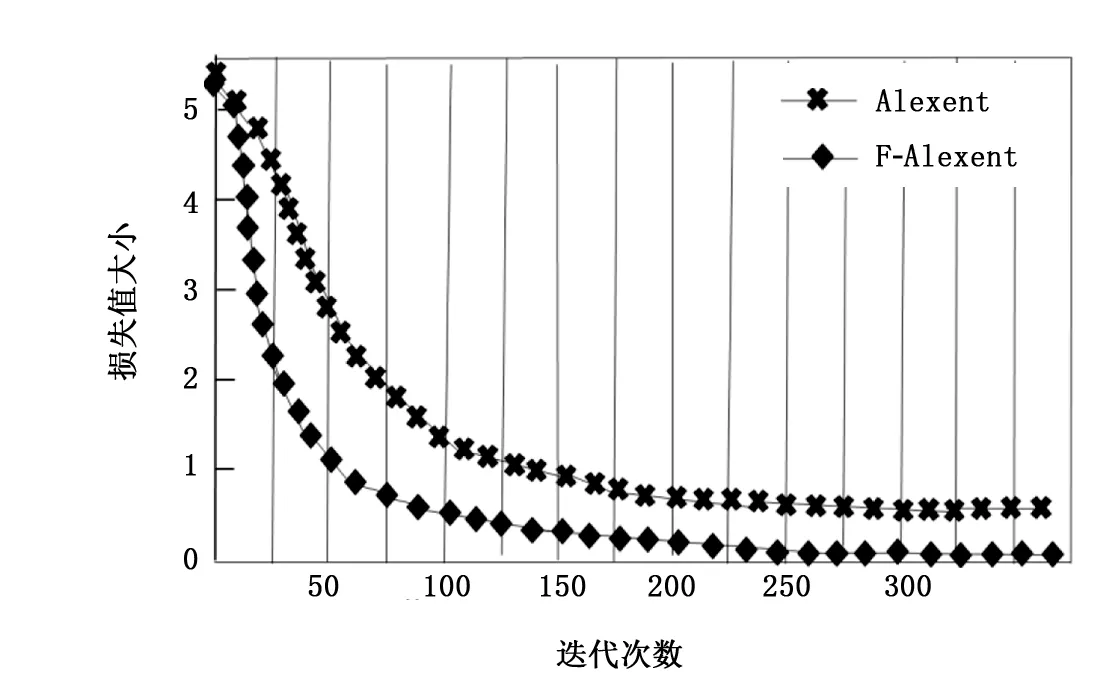
图10 损失值与迭代次数的关系图
从图10可以看出,在迭代次数刚开始增大时,损失值减小的速率较大,且改进的F-Alexent的损失值比原始的Alexent的损失值下降更快。当迭代次数达到250之后,网络处于收敛状态,损失值不再大幅度波动,此时模型训练完成,所得到的网络模型识别结果最佳。
2.5 网络结构参数对比
根据上面的试验,将F-Alexent网络参数设为最佳值,在这一基础上来研究RNN结构参数对识别准确率的影响。RNN凭借各隐藏层间的相互联系在自然语言处理方面取得了很大的进步,处理程度的好坏主要取决于RNN的隐藏层参数和每层的节点数。从理论上分析可知, RNN隐藏层层数越多,处理时序信息的能力越强,但随着隐藏层层数的增加,训练网络时计算机的资源占用也在增加,且容易出现过拟合问题。采用不同的隐藏层层数和每层节点数训练会得到不同的RNN模型,需要测试多个网络模型的识别准确率,最终选择识别率最高的网络模型并将该网络的RNN隐藏层层数和每层的节点数视为RNN的最佳参数。
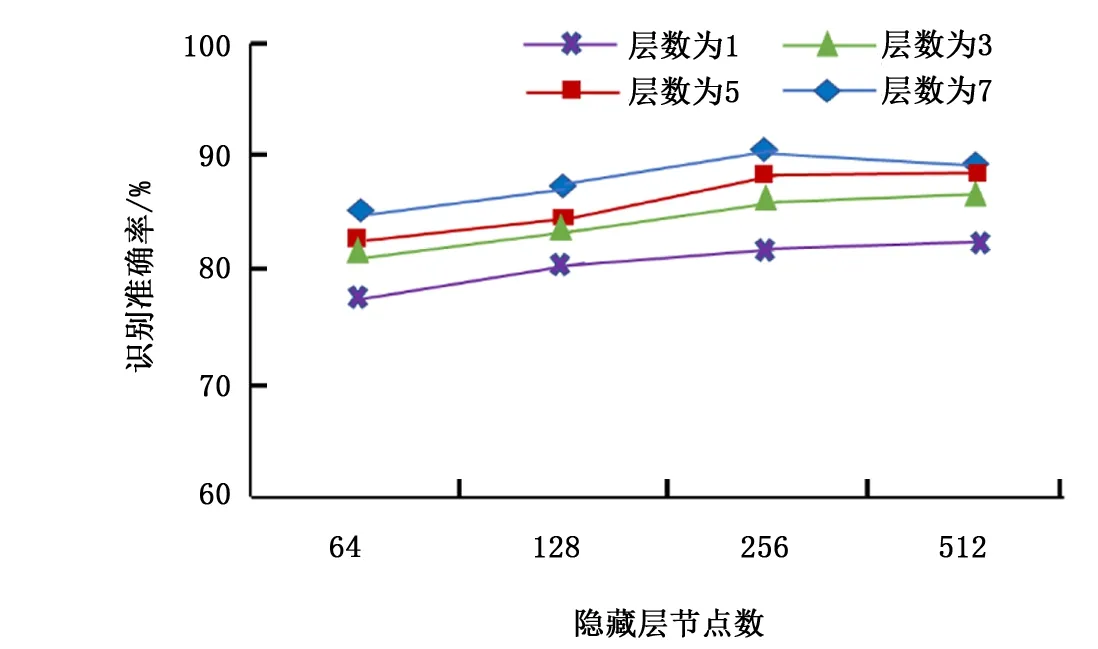
图11 RNN不同参数的识别准确率
分别将RNN网络的层数设置为1、3、5、7,并分别将每层的节点数设成64、128、256、512,经组合可以得到16种网络模型,不同的模型对应的识别准确率如图11所示。
由图11可知, 随着RNN隐藏层层数的不断增大,网络的准确率呈现增长趋势;随着隐藏层节点数的增大,网络的准确率也基本呈上升趋势。但当RNN隐藏层的层数为7,且每层节点数为512时,网络的识别准确率反而下降,也就是说每层节点数并非越多越好,且节点数越多,就越容易出现过拟合现象。为此,将RNN的隐藏层层数设为7层,每层的节点数设为256,训练得到的网络模型的识别效果最优。
2.6 不同的发票识别方法对比分析
比较了原始的Alexent网络、微调后的F-Alexent网络以及加入RNN网络后对识别准确率的大小的影响,其结果如表2所示。

表2 不同方法下识别准确率的大小
从表2可以看出,微调网络层数后得到的F-Alexent网络的识别准确率高于原始到的Alexent网络,但后续加入RNN进行医学术语修正后2种网络的识别准确率均有提高。试验结果表明,使用微调后得到的F-Alexent来提取单字符图像特征并输出识别结果,再结合RNN来对CNN输出的结果进行语义修正的方法在识别医疗发票时具有较高的识别准确率,体现了CNN-RNN模型在识别医疗发票时的优势。
采用训练好的CNN-RNN模型测试了200张医疗发票的识别情况,其中每张发票中大概有100个单字符,合计共测试了2000多张单字符图像。图12为笔者提出方法的识别结果。图12中左边为本地上传的原始发票图像,右边显示发票的最终识别结果。从识别结果中可以看出,医疗发票识别准确率达到90%以上,验证了该方法的有效性。
3 结语
针对针式打印的医疗发票中存在的断点等问题,提出了一种将数字图像处理技术与深度学习技术相结合的方法来识别医疗发票中的文本信息,通过数字图像处理技术得到单个字符图像,将其作为CNN网络的输入,并将识别得到的语段输入RNN网络进行语义修正,最终得到识别结果。该方法采用微调后的F-Alexent网络来提取单字符图像中的潜在文字特征,再利用RNN在时序信息处理中的优势来实现语义的修正。试验结果表明,该方法有效地提高了针式打印医疗发票的识别精度,在医疗发票的快速识别与入库中发挥着十分重要的作用。

图12 医疗发票识别结果
