基于朴素贝叶斯的中文文本分类
2019-11-03姜天宇王苏徐伟
姜天宇 王苏 徐伟

摘要:在当今数据大爆炸时代,每天所产生的文本量数以亿计,急需整理分类,然而传统的数据分类的文本处理方式过于烦琐,在浩瀚的数据流中迅速,高效,精确地找到需求信息极其困难。怎么有效地区分鉴别杂乱的信息,怎么迅速地满足用户的需求,都面临着困难。为了解决信息无序的问题,文本的自动分类技术自然成了处理和组织大量信息的一个重要技术。因此众多文本分类方法应运而生,朴素贝叶斯也是其中一种。朴素贝叶斯作为数据的十大算法之一,由于其易于构造和解释,并具有良好的性能,因此被广泛用于解决分类和排序问题。本文研究基于朴素贝叶斯算法的中文文本分类改进算法。
关键词:朴素贝叶斯;文本预处理;特征选择
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2019)23-0253-02
开放科学(资源服务)标识码(OSID):
Chinese Text Classification Based on Naive Bayes
JIANG Tian-yu, WANG Su, XU Wei
(College of Electronic and Optical Engineering, Nanjing University of Posts and Telecommunications,Nanjing 210023, China)
Abstract: In today's era of big data explosion, billions of texts are generated every day, which are in urgent need of sorting and classification. However, the traditional text processing method of data classification is too complicated, and it is extremely difficult to find demand information quickly, efficiently and accurately in the vast data flow. How to effectively distinguish and identify mixed and disorderly information, how to quickly meet the needs of users, are facing difficulties. In order to solve the problem of information disorder, automatic text classification technology has naturally become an important technology for processing and organizing a large amount of information. Therefore, many text classification methods emerge at the right moment, and naive bayes is one of them. As one of the top ten data algorithms, naive bayes is widely used to solve classification and sorting problems due to its easy construction and interpretation and good performance. This paper studies an improved algorithm for Chinese text classification based on naive bayes algorithm.
Key words: Naive bayes; Text preprocessing; Feature selection;
朴素贝叶斯是一种基于概率的统计学习模型,它有一个前提假设,即给定类的所有属性都是完全独立的。虽然这一假设在许多实际应用中经常被违反,但朴素贝叶斯仍然是排名前十的算法之一,因为它的简单、高效和可解释性。
1 朴素贝叶斯文本分类法
基于特征独立性的假设称为朴素贝叶斯分类法,就是对于某个类别节点,表示文本的屬性之间没有任何关系即相互独立。
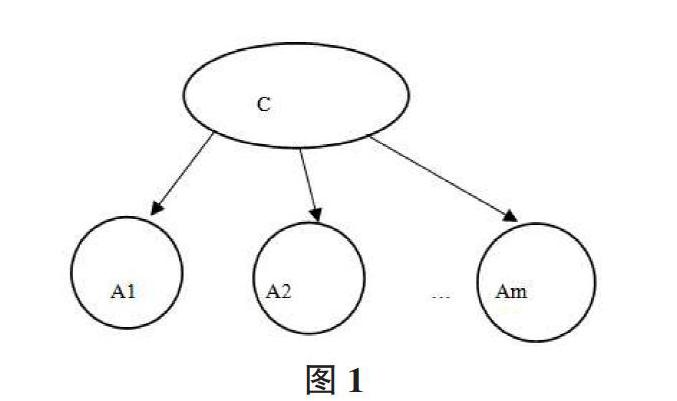
如图1所示,朴素贝叶斯分类模型的表示方法为:
C 为类别节点,A1,A2,…, Am是类别节点 C 下文本表示的m个属性结点。
在实际应用中,我们假设其中每个属性对所属类别的影响是相互独立的。这一假设降低了计算复杂度,因而能够加快分类速度。
使用朴素贝叶斯分类器对文本进行分类的过程如下:
(1)首先我们用特征向量空间来表示文本类别,这样一来我们就把分类的首要工作转变成构造每个类别的特征向量空间。我们就可以把训练集分成 m 类特征向量空间,每个文本类别拥有了一个独有的表示该类别文本的特征向量空间。
(2)我们用 P(ci|x)来表示待分类文本x属于类别ci的概率,那么文本分类的关键就是求出使P(ci|x)取最大值的类别。
(3)根据式[PAm|B=PAmPB|Am∑PAiPB|Aii],用 P(ci|x)(i=1,2,…,m)计算每个类别的条件概率。
(4)文档所属类别就是条件概率最大的类别。可以用公式表示为:P(ck|x)=max{P(c1|x),…, P(cm|x)},则x∈ck。
由于如何实现最优的朴素贝叶斯分类器是一个很困难的问题,改进的朴素贝叶斯分类方法引起了研究者的广泛关注。
改进的方法大致可分为五大类:1)结构扩展;2)属性权重;3)属性选择;4)实例加权;5)局部学习。
2 系统设计
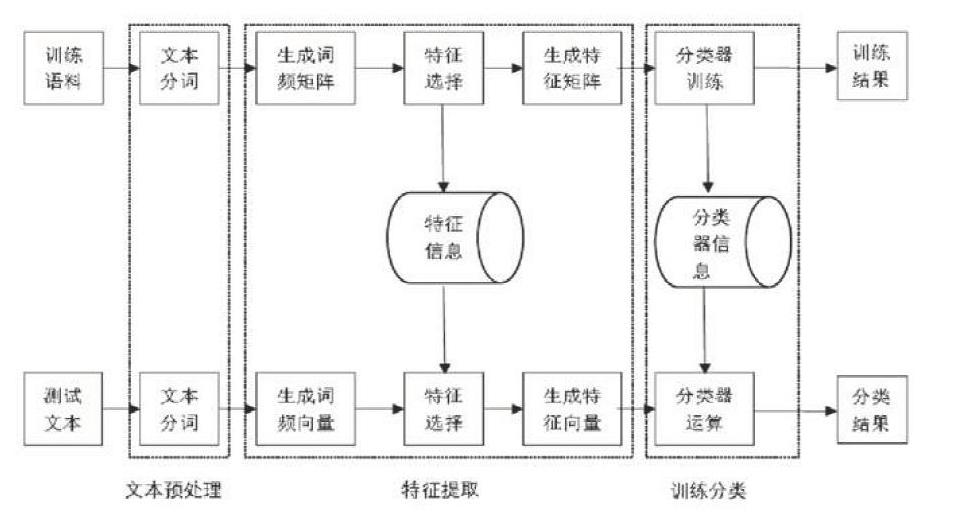
2.1文本预处理
本文的实验语料样本来自新华社的1659封邮件,包含有环境、交通、教育、军事、经济、体育共6个类别。接着给1659封邮件中每封邮件中的文本进行分词处理, 由此产生与之对应的文本词语表。再接着进一步简化,消去副词、虚词、量词这些没有意义的词, 消去经常重复多次出现没有显著特征的动词、名词, 记下体现文本中权重较高的词及词频, 将这些文本形成向量空间模型, 最后将全部文本处理完成之后形成一个矩阵,称其为词频矩阵,类属性加在最后一列。
2.2特征选择
本文使用改进TF-IDF做特征选择。TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于信息搜查的常用加权技术。TF-IDF是一种统计方法,用以评估每个字词对于一份文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF,(Term Frequency)表示某个关键词在某个文档中出现的频率。可以表示为:
词频(TF)=某个词在文章的出现次数/文章的总词数。即:
[TFi,j=ni,jkni,k]
DF,(Document Frequency)的缩写,表示文档集合中,出现某个关键词的文档个数。
IDF,(Inversed Document Frequency)的缩写,表示一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
[IDFj=logD1+DFj]
其中|D|:语料库中的文件总数
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
TF-IDF计算公式如下:
[TF-IDFi,j=词频(TFi,j)×逆文档频率(IDFj])
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
2.3系统流程图
3 系统验证
3.1训练分类仿真结果
本文所有实验都是在普通PC(Intel CORE i7,2.60 GHz CPU,8.0 GB RAM),软件为Pycharm64,使用Python语言实现提出的朴素贝叶斯算法。本文的实验样本来自新华社的1659封邮件,包含有环境、交通、教育、军事、经济、体育6个类别。
先对待分类文本进行关键词提取,每篇提取前 20 个权重最大的词,再转换成词向量,然后与模型训练计算出来的先验概率一起计算出文本属于每一类文本的概率,然后比较大小,选择概率最大的并判别文本属于哪个类别,输出类别标签。
注:
1.调和平均值 = 查全率 × 查准率 × 2/查全率 + 查准率。
2.图中P为查准率,R为查全率,F1为调和平均值
由上图可得以下表格:
从上表我们可以看出,对待分类文本采用改进TF-IDF 算法提取关键字后,再运用朴素贝叶斯算法对文本进行分类,各类文本都取得不错的分类效果,尤其环境类的查准率和调和平均值都超过了 90%。分类速度约为 800 篇/min。
4 总结
在本文中,我们首先研究了现有的朴素贝叶斯分类方法。然后,我们通过改进TF-IDF加权方法,该方法通过对训练数据的特征加权频率进行深度计算来估计朴素贝叶斯的条件概率。实验结果表明,与之前方法相比,我们的改进TF-IDF加权方法很少会降低模型的质量,而且在很多情况下,可以显著提高模型的质量。最后,我们对朴素贝叶斯中文文本分类器进行了改进TF-IDF加权,并取得了显著的改进。
参考文献:
[1]贺科达,朱铮涛,程昱.基于改進TF-IDF 算法的文本分类方法研究[J].广东工业大学学报,2016(9).
[2] 安艳辉,董五洲,游自英.基于改进的朴素贝叶斯文本分类研究[J].河北省科学院学报,2007(01):22.
[3] 饶丽丽,刘雄辉,张东站.基于特征相关的改进加权朴素贝叶斯分类算法[J].厦门大学学报:自然科学版,2012(4):682.
[4] 杨凯峰,张毅坤,李燕.基于文档频率的特征选择方[J].计算机工程,2010(17):33.
[5] 陈叶旺,余金山.一种改进的朴素贝叶斯文本分类方法[J].华侨大学学报:自然科学版,2011(4):401.
[6] 朱娟.基于贝叶斯算法的多语言文档分类[D].苏州大学,2016.
[7] 包小兵.基于朴素贝叶斯的Web文本分类及其应用[J].电脑知识与技术,2016(30):220.
[8] 史琬莹.朴素贝叶斯方法在文本分类中的运用[J].电子技术与软件工程,2018(208).
[9] 贺鸣,孙建军,成颖.基于朴素贝叶斯的文本分类研究综述[J].情报科学,2016(7):147.
【通联编辑:唐一东】
