基于注意力机制和双向GRU模型的雷达HRRP目标识别
2019-11-02刘家麒
刘家麒 陈 渤* 介 茜
①(西安电子科技大学雷达信号处理国家重点实验室 西安 710071)
②(西安电子科技大学计算机科学与技术学院 西安 710071)
1 引言
雷达高分辨距离像(High-Resolution Range Profile,HRRP)是基于雷达宽带信号获取的目标散射点子回波在雷达射线方向(Radar line of sight,RLOS)上投影的向量和,它含有大量的目标结构、散射点分布和目标尺寸等可判别信息。相比2维的合成孔径雷达图像,1维的HRRP数据存储量较低,更易保存和计算,如今在雷达自动目标识别(Radar Automatic Target Recognition,RATR)领域中广泛应用。
HRRP具有方位敏感性、幅度敏感性和平移敏感性[1],这对目标特征的提取造成了困难,而特征提取的好坏又直接影响了目标的识别性能。针对以上问题,大量学者进行了广泛的研究。文献[2]提取了HRRP数据的高阶谱特征,对所得谱特征使用模板匹配法进行识别。但这需要专业人员的经验,同时将时序数据映射到了其他域,破坏了HRRP距离单元之间的时序相关性。文献[3]基于字典学习的方式得到了噪声环境中HRRP的稀疏表示,并在此基础上进一步进行处理。文献[4]使用PPCA对HRRP数据进行特征的提取,用MPPCA按照方位角的不同进行了聚类,从而减少待匹配模板的数量。文献[5]认为HRRP数据服从混合Gamma分布,将HRRP的识别问题转化为概率统计模型。文献[6]使用了原始的复数HRRP数据,充分利用了相位角信息。虽然以上方法都取得了不错的识别性能,但是这些方法都将HRRP数据视为一个整体,仅关注了样本的包络信息,而忽略了HRRP数据内部不同距离单元之间的时序相关性。文献[7,8]考虑到不同距离单元之间的时序相关性,将HRRP转化为序列的形式并使用隐马尔科夫模型(Hidden Markov Models,HMM)建模。但由于方位敏感性的原因,需要对不同帧的数据分帧建模,具有较大的计算量。相比于HMM模型,循环神经网络(Recurrent Neural Network,RNN)由于其具有非线性的激活函数以及较大的隐空间范围,具有更强的表示能力。通过其独特的自循环机制,输入数据的隐层特征可以在不同时刻的隐状态间传递,可以有效的提取完整的样本特征。通过梯度下降算法(gradient descent)可以自动学习循环神经网络模型权矩阵的值,可以在不需要相关人员的先验经验的条件下完成数据的特征提取与分类。因此,被广泛应用于时序数据的建模[9,10]。由于平移敏感性问题的存在,HRRP样本目标区域两侧均会有一段数据冗余,而冗余数据对目标识别没有帮助。另一方面,传统的循环神经网络是单向的,分类时仅能利用当前及之前时刻的数据信息。另外由于传统的循环神经网络存在着梯度消失[11]等问题,使其对历史数据的记忆能力较差。
针对上述问题,本文提出一种基于注意力机制的双向门控循环单元(Attention-based Bidirectional Gated Recurrent Unit,ABi-GRU)模型。门控循环单元(Gated Recurrent Unit,GRU)是一种对于循环神经网络的改进[12],通过在传统RNN基础上额外增加“重置门”和“更新门”操作,可以有效的保证可分性信息在网络自循环中的传递,从而缓解梯度消失带来的性能损失,相比于传统的循环网络模型,其记忆性更强。该模型首先使用双向GRU网络对HRRP数据的正向序列和反向序列分别建模,得到其正反向序列的隐层特征。再对正反向得到的隐层特征进行拼接,拼接后的隐层特征可以同时利用正反向的内容,有利于目标的识别与分类。最后考虑到不同时刻的样本数据对识别所起的作用是不同的,使用注意力机制对不同时刻的隐层特征进行加权处理得到最终的隐层,从而使模型可以自动关注并计算对识别有效的目标区域部分,更有利于目标的识别与分类。
最后,通过实测数据进行相关实验,验证本文模型的正确性。实验结果表明,本文模型有效解决了HRRP的平移敏感性问题,具有较高的识别性能。
2 门控循环单元及注意力机制
2.1 门控循环单元
门控循环单元是一种带有自循环结构的神经网络,它可以自动对多个时间的输入进行特征提取,而不同时刻的数据共享同一组权值矩阵。由于其独特的自循环机制,隐层特征可以在不同时刻间单向传递,从而记录下先前时刻的“历史数据”,再通过历史数据与新数据的融合得到当前时刻的隐层特征值。由于传统的循环神经网络存在着梯度消失问题[11],进而对识别的性能造成了影响。GRU模型在RNN的基础上增加了2个控制门结构,使得信息有选择性的在隐层中传递,在记忆重要信息的同时有效的减轻了梯度消失的问题。
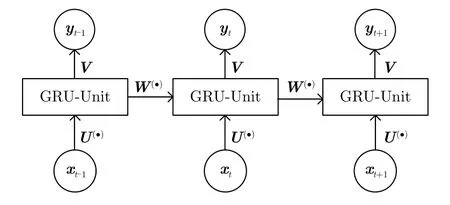
图1 GRU网络结构示意图Fig.1 GRU network architecture

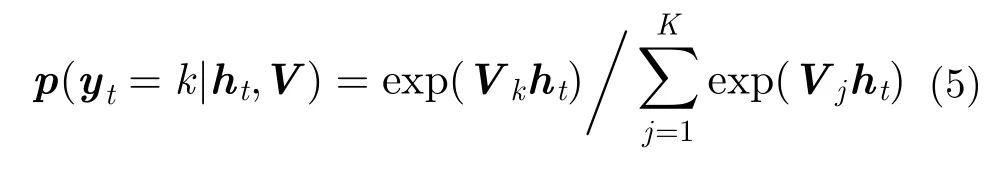
2.2 注意力模型
注意力机制(attention mechanism)源自人类大脑对新事物认知的特点,即对于重要的内容分配较多注意力,而对于不重要的部分分配较少的注意力[13]。对目标识别问题来讲,目标区域的价值远远大于两侧的冗余数据。在GRU模型中,样本通过滑窗操作后得到多个时刻的样本序列,不同时刻的序列进行类别预测的重要程度是不同的。这需要通过一种特殊的计算手段自动获得目标区域的范围,并对此范围赋予较大的权值。最后将不同时刻的隐层状态与权重进行加权求和,从而得到经过注意力模型处理后的隐层状态



3 基于注意力机制和双向GRU模型的HRRP目标识别方法
3.1 HRRP数据的预处理
如图2所示,雷达HRRP数据反映了在一定的雷达视线方向上,目标散射点子回波的分布情况,其中每个距离单元等于所有散射点目标在这个距离单元内的回波叠加。HRRP数据包含了丰富的目标尺寸和相对结构等信息,可用来目标的识别与分类[14]。记HRRP数据为,其中表示第个距离单元的子回波;表示距离单元总个数。对复向量取幅值,得到其幅值向量。

图2 高分辨距离像生成示意图Fig.2 Illustration of an HRRP sample
本文使用能量归一化方法消除HRRP数据的强度敏感性问题,即限制不同HRRP数据的总能量相同。使用重心对齐法消除平移敏感性,将HRRP数据的重心位置平移到距离像的中心位置处。HRRP数据的重心位置可由式(11)计算出。
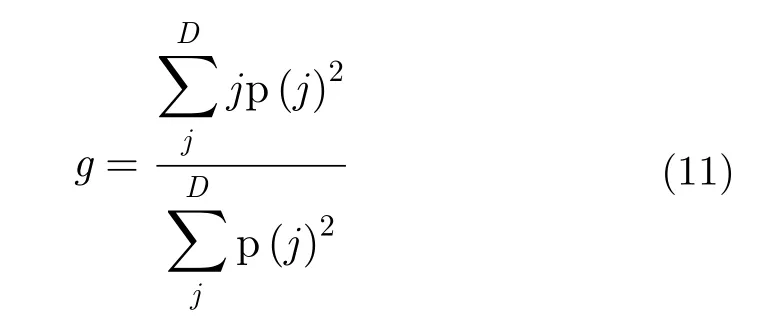


3.2 基于注意力机制和双向GRU模型的HRRP目标识别方法
传统的GRU模型是单向的,即数据只能沿着一个方向进行处理。网络只能结合当前时刻的输入数据及之前时刻的隐状态信息计算新的隐状态,而之后的信息无法有效的利用。而HRRP本身并无特定的顺序,因此只考虑单向信息并不利于HRRP数据的识别。针对此问题,本文提出将双向GRU模型应用在HRRP序列的识别问题上,即将HRRP数据分正反双向分别输入2个独立的GRU模型,从而得到正反序列的隐层特征分别为和[15],其中表示序列的时刻数。将同时刻的隐层进行拼接,则拼接之后的隐层可以充分利用前后两个方向上所有时刻的HRRP信息,有利于特征提取的进行。


图3 基于注意力机制的双向门控循环单元(ABi-GRU)模型结构Fig.3 Structure of ABi-GRU model

4 实验
实验数据为国内某研究所雷达实测飞行数据,其中雷达和飞机的参数如表1所示。所测数据共含有3类目标飞机,其时域特征如图4所示。其中“安26”为中型螺旋桨飞机,“奖状”为小型喷气式飞机,“雅克42”为中型喷气式飞机。其飞行轨迹图如图5所示。为了考虑尽可能完备的方位角数据,本文将飞机飞行轨迹分为数段,其中“安26”和“奖状”分为7段,“雅克42”分为5段。为了验证模型的普适性,本文选取方位角变化较大的几段作为训练数据,其他数据段作为测试数据。因此本文使用“安26”的第5,6段数据,“奖状”的第6,7段数据,“雅克42”的第2,5段数据作为模型的训练数据,其它段作为测试数据。以上训练数据段基本覆盖了测试数据可能的方位角信息,而且与测试数据段无重复数据,可以有效验证模型的性能。共得到7800个训练样本数据,5124个测试样本,每个距离像维度D为256维。
表2展示了本文提出的模型与多个现有模型对测试数据的识别性能,识别性能指分类正确的样本占全体测试样本的比例。现有模型包括:最大相关系数法[7](Maximum Cross Correlation,MCC),全连接神经网络(Full Connected Neural Network,FCNN),自适应高斯分类器[16](Adaptive Gaussian Classifier,AGC),隐马尔科夫模型。除此之外,为了验证双向网络和注意力机制的有效性,还加入了融合注意力机制和仅用正向或反向数据的单向GRU模型(AGRU-for,AGRU-back)和无注意力机制的双向GRU模型(Bi-GRU)作为对比。在实验中,设置滑窗的窗长d为32,每次滑动的距离为16,经过预处理后的高分辨距离像的维度为256,可计算得到总的序列数为15。GRU网络的隐层状态的维度大小为20,注意力权值的长度l为12。待训练的参数包括,其中带方向箭头的变量表示正向或反向GRU网络的相关权值,是注意力机制的相关参数,是最终融合注意力机制和双向信息的隐层状态所经过分类器的相关参数。初始化时,所有待训练参数均从分布中采样。学习率设置为,表示迭代次数。使用交叉熵作为模型的损失函数,其定义为L=其中是第i个样本真实的类别向量(one-hot编码),是第i个样本网络预测的输出分布向量。采用随机梯度下降法对网络进行权值的训练,每次使用的mini-batch样本数设置为30。

表1 雷达和飞机相关参数Tab.1 Parameters of planes and radar

图5 实验数据飞行轨迹投影图Fig.5 Projections of target trajectories onto the ground plane

表2 不同方法实验识别性能对比Tab.2 Performance comparison with different methods
从表2中可以看出,相比于传统的全连接神经网络模型,基于循环结构的GRU模型考虑到了高分辨距离像内部不同距离单元之间的时序相关性,从而有效的提高识别性能。而结合了双向信息的Bi-GRU由于在任一时刻考虑到了样本的整体信息,比仅仅使用部分正向或反向序列的AGRU-for和AGRU-back模型性能更好。基于注意力机制的ABi-GRU模型则在考虑到双向时序性的前提下,又引入了注意力机制。在考虑样本整体信息的情况下,数据的目标区域含有最为丰富的可判别信息,因此是模型识别的重点区域。而引入注意力机制后的模型可以自动的对目标区域赋予较大的权值,增加了目标区域的权值比重。识别性能相比无注意力机制的Bi-GRU模型又提高了0.7%,取得了最佳的识别性能。
图6给出了经预处理后的时域HRRP数据和经本模型(ABi-GRU)所提取得到的隐层特征的主成分分析(Principal Component Analysis,PCA)2维投影图。从中可知,ABi-GRU模型所提取到的隐层状态具有很高的可分性,所提特征整体可分性较好,投影图中只有部分红色星号(安26)与绿色圆圈(奖状)有重叠现象。
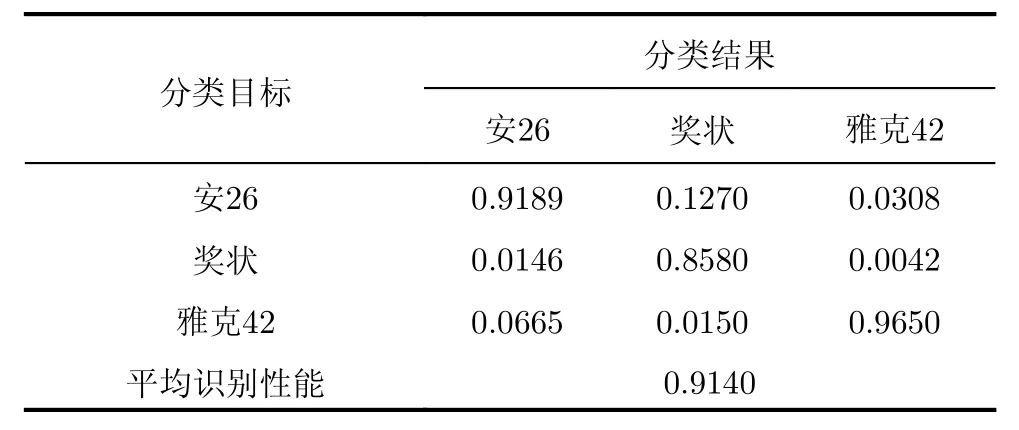
表3 ABi-GRU模型对时域HRRP数据的混淆矩阵Tab.3 Confusion matrix of ABi-GRU model for time domain HRRP data
图7展示了不同样本不同时刻的注意力系数分配图。其中横轴表示不同的时刻,纵轴表示不同的样本,不同颜色代表着不同的注意力数值。对经过重心对齐处理的HRRP数据来说,1~5时刻和12~15时刻对应时域HRRP数据目标区域两侧的噪声区域,这部分数据不具备目标识别能力,因此其对应的注意力权值较低。而6~11时刻为数据的目标区域,这部分区域包含有大量目标结构信息,因此是目标识别的重点。图7(a)是已经经过重心对齐处理后样本的注意力系数图,可见较大的权值基本分布在中间时刻(时刻7~9)附近,这与实际情况相符。注意力机制可以自动找出目标区域,有效提高了识别性能。
平移敏感性问题会对模型性能造成一定影响,但是注意力机制是数据相关的。当输入数据发生平移移动时,注意力系数会自动修正相应的权值。在模型已经训练完成的情况下,将测试数据整体平移一定的距离单元,此时HRRP数据的目标区域将不在位于6~11时刻所框定的范围内。如若将经过重心对齐后的HRRP数据整体向前平移50个距离单元并将其输入已训练好的模型中,可得此时的注意力系数如图7(b)所示。可见虽然距离像平移了一定单位,但是相对应的注意力权值也发生了变化,且此时注意力权值较大的区域与目标区域的位置依然吻合,模型依然可以有效从整个HRRP数据中提取目标区域并得到其隐层特征,可见基于注意力机制的双向GRU模型对于HRRP的目标识别非常稳健。

图7 测试数据注意力权值系数Fig.7 Attention coefficients of test data
5 结论
本文针对雷达高分辨距离像的自动目标识别问题,提出了一种基于注意力机制的双向GRU网络的识别模型。基于GRU模型的循环机制,充分利用了高分辨距离像内部距离单元之间的时序相关性,有效捕捉了HRRP数据深层的隐含特征,提高了特征提取的效率与质量。并在此基础上引入了注意力机制,有效地从距离像中获取得到目标区域,降低了特征提取的难度。实验结果表明,本文模型可以有效地捕获HRRP数据的可分性信息,以及处理高分辨距离像的平移问题,而且不需要专业人员的先验经验,取得了较好的识别性能。
