基于支持向量数据描述算法的变频空调系统制冷剂泄漏故障诊断研究
2019-11-01徐廷喜杜志敏吴斌黄小清晋欣桥
徐廷喜,杜志敏,吴斌,黄小清,晋欣桥
(上海交通大学机械与动力工程学院,上海 200240)
0 引言
据统计,建筑能耗约占总能量消耗的20%~40%,50%以上的建筑能耗用于HVAC系统中[1]。变频空调系统利用容量可变压缩技术,该系统在长时间使用后,由于制冷剂泄漏、机械性损坏或不适当的系统保养,导致系统效率大幅下降[2]。理想VRF系统应具有故障检测和诊断的能力。制冷剂充注故障是多种故障类型中最为常见的一种,直接影响制冷系统的效率[3-4]。
FDD方法可分为3种:定量模型研究方法、基于规则的研究方法和基于过程数据的数据挖掘方法[5]。本文诊断方法采用第3种,该方法与传统故障检测和诊断方法相比,具有灵活、可直接运用、节省时间和提高效率的优点。故障识别方法的理论和算法较为成熟,无故障数据通常可在建筑模型或一些数据库中获得。郭宪民等[6]和吴斌等[7]研究表明,基于过程数据的数据挖掘方法可以量化不同故障等级,将模型拓展到相似的系统中。
将机器学习模式识别方法应用于HVAC的故障诊断的研究较少。在HVAC的FDD方法中,主成分分析(Principal Component Analysis,PCA)是主要的方法之一,PCA可以通过数据分析进行故障识别,通过重建算法用于传感器故障诊断[8-9]。近年来数据挖掘方法是故障诊断领域中的研究热点,神经网络[10-11]等方法均已用在空调系统的故障诊断中,该方法通过挖掘数据之间的固有关系来区分正常数据与故障数据。部分专家学者将支持向量机(Support Vector Machine,SVM)及支持向量数据描述(Support Vector Data Description,SVDD)算法引入制冷装置故障诊断领域中[12-17],制冷装置的FDD方法为多类划分方法,诊断准确率可达90%以上。多分类问题将未知类别的数据划分到指定的类别中,但当数据不属于任何一个指定类别时,便会出现问题。多分类问题在所有故障类型均可获得时有效,否则将失效。
故障检测为单类划分问题,将一类故障从所有数据诊断出来。无故障数据在制冷装置无故障条件下获得,简单方便且成本低。本文故障条件下的诊断数据通过控制制冷剂充注量,模拟不同的制冷剂泄漏的故障等级获得。单类划分故障诊断模型是通过串联多个单故障诊断模型得到,利用支持向量机等机器学习方法,每次从数据中诊断一类故障,按照故障等级依次诊断,直至对所有故障类别均作出判断[18-21]。
本文以变频空调系统作为研究对象,采用了PCA-SVDD的方法,分别构建并研究了不同压缩机转速,不同制冷剂泄漏等级下的故障检测与诊断的模型。介绍了PCA和SVDD算法的基本原理,说明了模型具体构建过程并验证了该方法的准确性。利用遗传算法优化模型超参数的求解过程,优化后的诊断模型准确率进一步提高。本文还给出了该方法优缺点分析以及该方法潜在的应用价值。
1 变频空调系统原理
图1所示为变频空调系统原理,对制冷剂泄漏故障进行检测和诊断。实验直接或间接获得64个变量,制冷剂为R410A。共有3种实验工况,如表1所示。制冷剂充注量故障分为6个等级,分别为无故障数据、制冷剂泄漏10%、制冷剂泄漏15%、制冷剂泄漏20%、制冷剂泄漏30%和制冷剂泄漏40%。利用无故障数据训练SVDD无故障模型,无故障SVDD模型可以将数据分为无故障类和故障类。故障数据可以通过对具体的故障或故障等级数据进行训练,以便分类确定具体故障类型或故障等级。
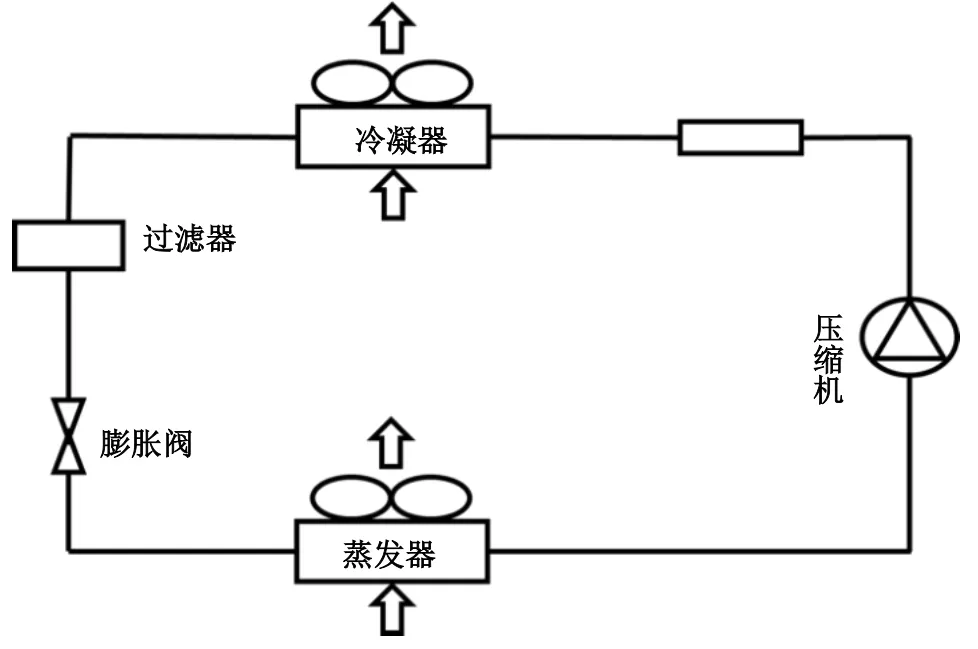
图1 变频空调系统原理

表1 实验工况
2 基于PCA-SVDD的故障诊断
2.1 基于PCA的数据降维
主成分分析(PCA)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。使用 PCA获取低维度的样本特征还能够加快机器学习的速度。
设训练样本集X为:

文中取N=14,训练样本集为14个特征变量数据集,分别为制冷量、输入功率、COP、质量流量、过冷度、过热度、蒸发温度、冷凝温度、排气温度、膨胀阀开度、室外风机转速、室内风机转速和冷凝器空气侧温升。14个特征数据变量依据制冷系统故障诊断经验规则选取,部分变量为直接测得(如温度和转速等),但制冷量及质量流量根据质量守恒公式和能量守恒计算得到。
该样本集的平均向量为:

样本集的协方差矩阵为:
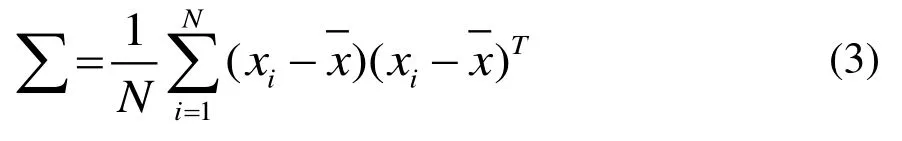
求出协方差矩阵的特征向量和对应的特征值,这些特征向量组成的矩阵U即变量的正交基底,信息集中在特征值大的特征向量中,即使丢弃特征值小的向量也不会影响初始变量质量。将协方差矩阵的特征值按大到小排序:λ1≥λ2≥…≥λd≥λd+1≥…。
由大于λd的λ对应的特征向量构成主成分,模型中λd=0.1,特征向量主成分矩阵包含5个特征变量。主成分构成的变换矩阵为:
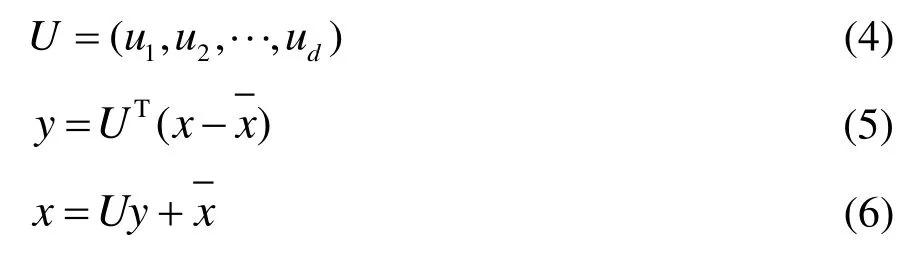
式中:
u1——制冷量,kW;
u2——输入功率,kW;
u3——COP;
u4——质量流量,kg/min;
u5——过冷度,℃。
2.2 单分类SVDD
本文通过给定一个目标xi∈Rd,i=1,2,3…N,SVDD的原理是在高维空间中寻找一个球心为aF,半径为D的最小超球面[9],包裹尽可能多的目标点。
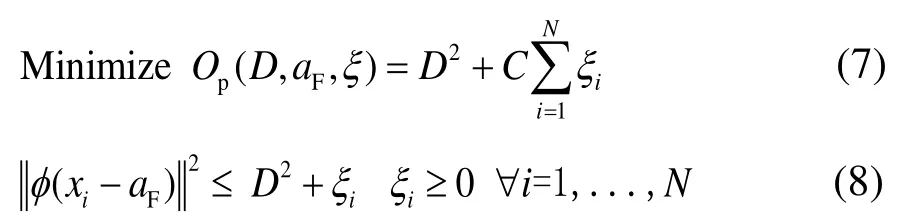
式中:C为控制超球面的体积与误差;ξi为一个松弛变量,允许训练的模型可以有一定的误差。这是一个非线性的映射,可以把输入变量映射到一个φ的高维特征空间F中,式(7)的对偶问题为式(9)。
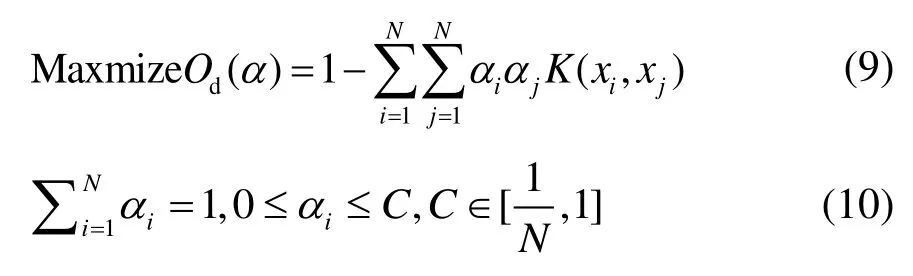
式中,K(xi,xj)为一个核函数,α为拉格朗日对偶变量。
核函数为高斯核:

选择高斯核,是因为高斯核包含一个自由参数,更加趋近于边界条件。目标可以分为3类:1)如果αi=0,则目标位于球面内;2)0<αi<C,目标位于超球面边界上;3)αi=C,在超球面外,而且有一定误差余量。0<αi<C的目标为支持向量点,在边界上的点为边界支持向量,超球面的球心可用式(14)确定,半径则利用球心与目标之间的距离确定。对于检测变量x,其输出结果可以比较目标点距离球心的距离与半径大小,式(16)是SVDD的决策方程。
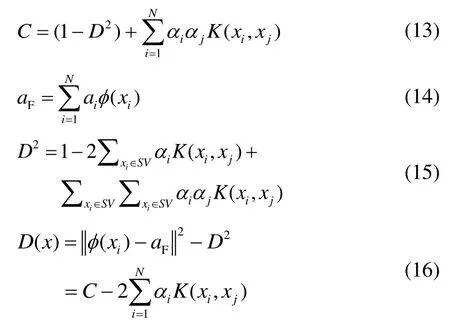
制冷装置故障检测的对象是无故障系统中异常的数据,故障诊断的目的是如果数据被划分到故障类别中,需要确定具体类别,如图2所示。
A是目标类,即某种故障数据点,如果过程数据在圆内,故障可以被检测和诊断,如果在圆外,故障不存在。文中需要指定C和γ两个变量。C为控制超球面的体积和模型误差的权重,γ为改变高斯核内的宽度参数,γ=1/2σ2,其中σ越小,边界条件越严格。
3 诊断模型
3.1 SVDD模型的建立
在SVDD模型训练环节中,将数据分为无故障数据和故障数据。首先收集数据,并进行数据预处理,由于稳态中3,000 r/min和5,000 r/min数据较多,因此仅对该两种转速进行建模,转速可根据实际样本数据选择,同样适用于其他转速。图3所示为诊断逻辑图。
3.1.1 数据预处理
考虑系统稳定运行的影响,训练数据为压缩机转速为3,000、5,000 r/min的工况数据。工况数据3,000 r/min实际转速范围为2,950~3,050 r/min,工况数据5,000 r/min实际转速范围为4,950~5,050 r/min。转速取值可以适当变动,在不同工况和转速的分布量上取值。根据样本非稳态数据,通过异常值过滤器和稳态数据检测器去除异常值。参与训练的变量可以通过分析常用物理变量变化趋势进行合理的选择,这一步骤可尝试多次。根据制冷系统原理初次选用变量14个,再对已选择的变量进行归一化处理,预处理完成后,数据按4:1比例分为训练数据和检测数据。
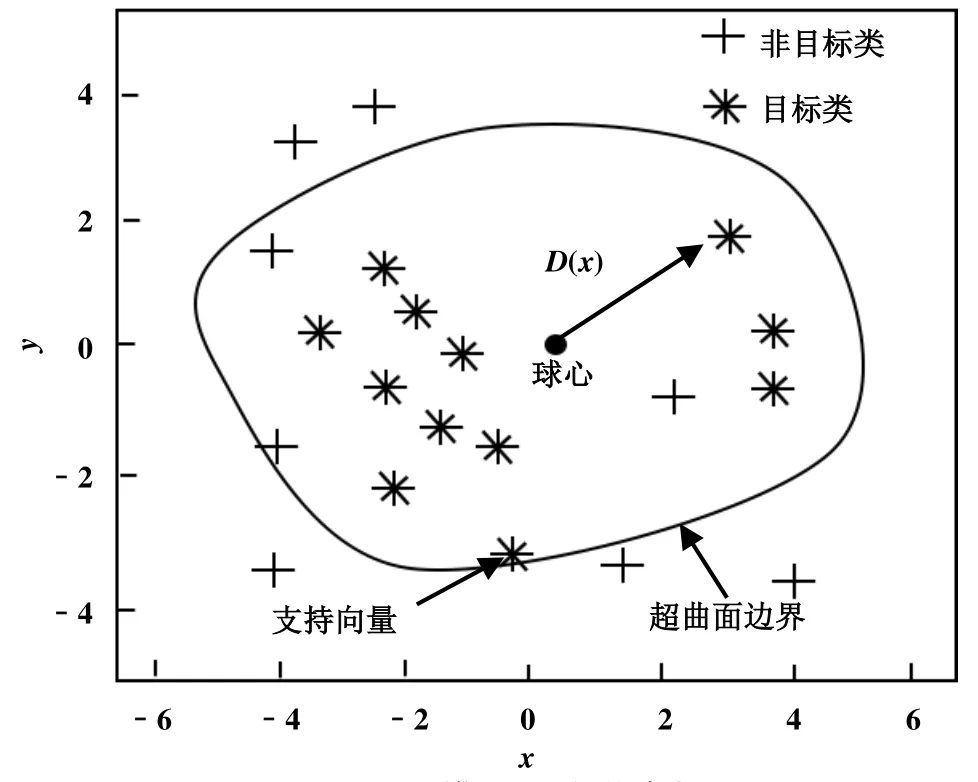
图2 SVDD二维数据分类诊断图
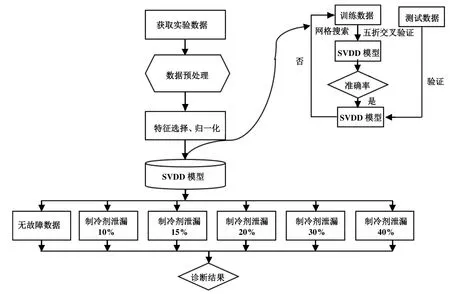
图3 诊断逻辑图
数据归一化将有量纲的表达式,变换为无量纲的表达式。选定范围为(-1,1),将数据进行归一化处理。文中采用的归一化方法为:
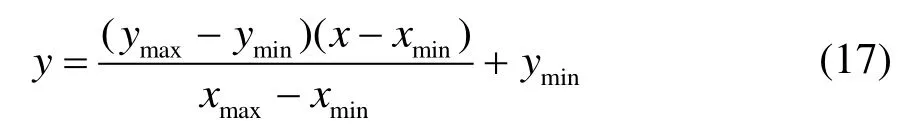
3.1.2 特征选择
数据预处理完成后,对14个特征变量利用PCA算法进行降维处理,确定4个特征变量进行分析。选定的特征变量为制冷量、输入功率、质量流量和过冷度。图4所示为PCA模型特征变量权重分布。
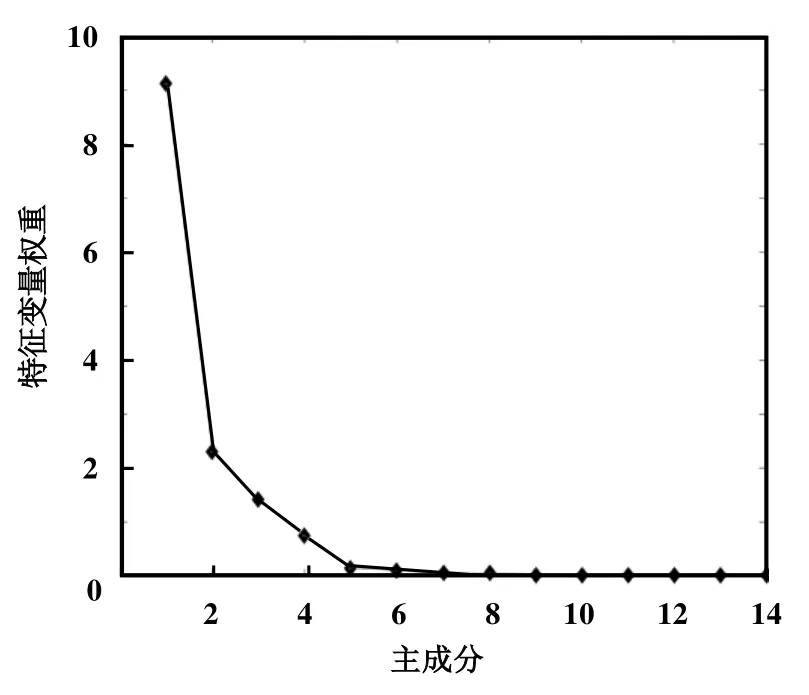
图4 PCA模型特征变量权重分布
3.1.3 模型参数设定
SVDD模型在训练之前,需要指定模型的可信度,即模型允许的错误诊断率。采用交叉验证可以优化得到参数C和γ。文中模型采用5折交叉验证,训练数据和交叉测试数据精度要求在95%以上,否则模型将继续寻优。
3.1.4 模型验证
利用测试数据验证模型,表2所示为错误类别说明。当某SVDD模型错误划分该类型数据为异常点(一类错误),或错误划分另类故障数据为该类型故障数据(二类错误)均认为分类错误。对每个模型,当用验证数据进行验证时,一类错误概率应小于5%;反之,模型需要调整两个参数直至模型满足该条件为止。训练好的模型应可以有效区分数据类别,二类错误的概率应尽可能小,所有的模型都需要用其他类的样本数据进行验证。二类错误的概率一般小于40%可以接受。如果二类错误概率大于该阈值,SVDD模型则需要重新训练,这种情况下,一类错误概率可以适当调整。
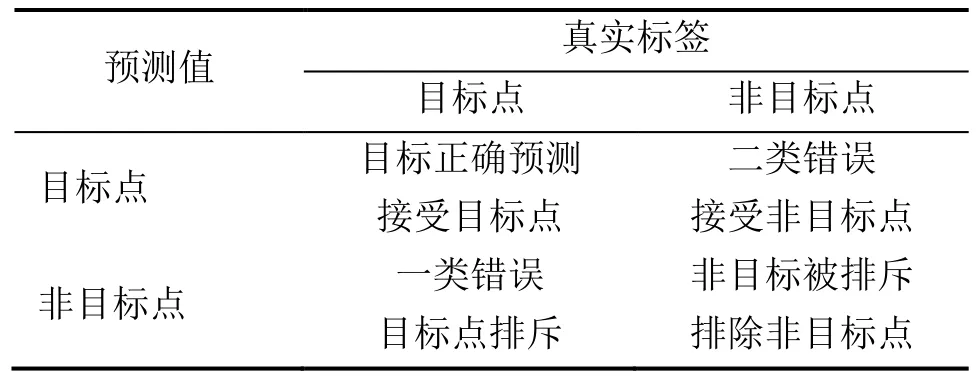
表2 错误类别说明
3.1.5 模型优化
当粗略确定较优的参数后,利用遗传算法在局部范围内进一步寻优,进而优化模型。
不同故障类型对应的模型测试或训练的组数,每组数据包含4列,分别代表参与模型训练的4个变量,即制冷量、输入功率、质量流量和过冷度。
当压缩机转速为3,000 r/min时,采用5折交叉验证,表3所示为不同故障类型的模型测试或训练组数,表4所示为不同故障类型的模型预测结果。
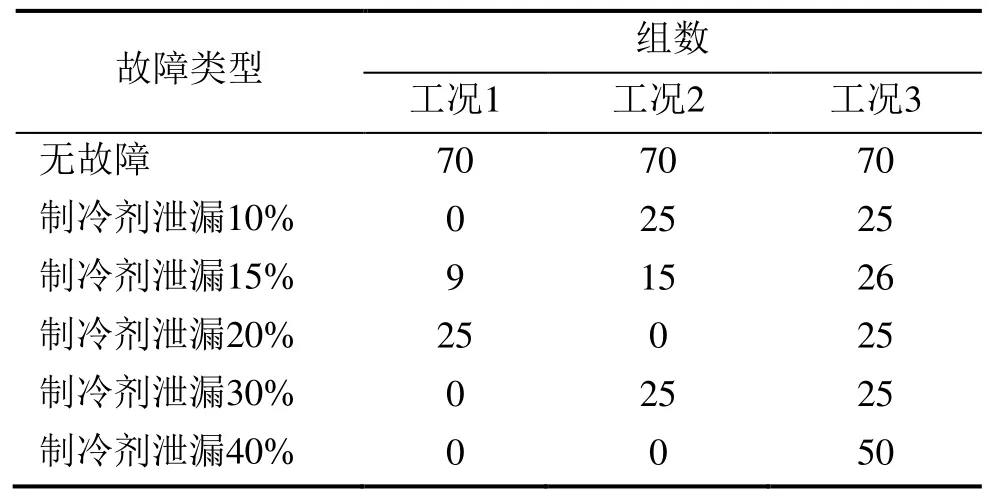
表3 不同故障类型的模型测试或训练组数(3,000 r/min)
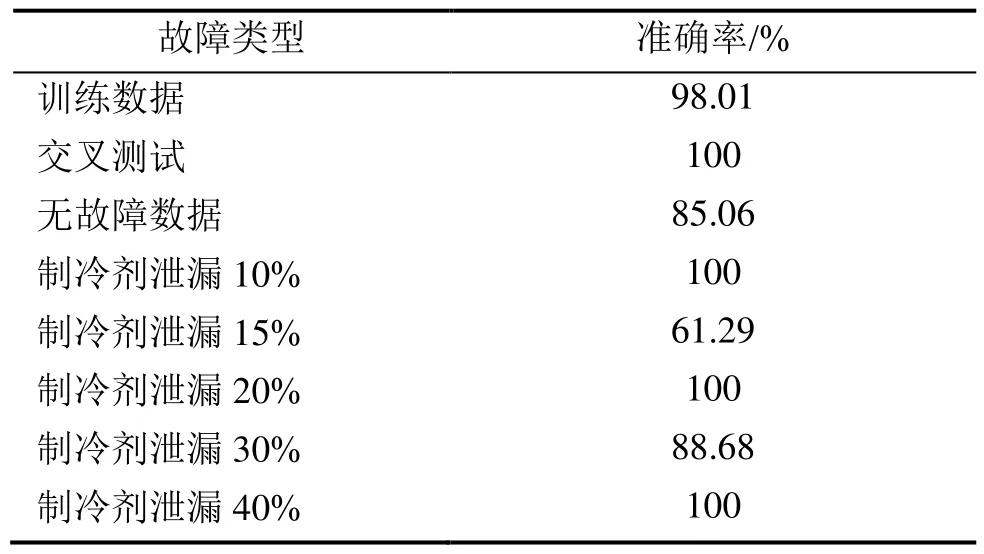
表4 不同故障类型的模型预测结果(3,000 r/min)
由表4可知,模型训练数据集以及交叉验证测试集的模型准确率达到96%以上,在无故障数据测试集准确率达到 85.06%,远高于制冷剂泄漏的 5种故障数据,具有较高的故障检测率,说明模型具有较高的可信度。
当压缩机转速为5,000 r/min时,采用5折交叉验证,表5所示为不同故障类型的模型测试或训练组数,表6所示为不同故障类型的模型预测结果。
由表6可知,模型训练数据集以及交叉验证测试集的模型精度均达到95%以上,在测试数据集中,无故障数据达到 75.39%,远高于制冷剂泄漏的 4种故障数据,具有较高的故障检测率,说明模型具有较高的可信度。
对比表4与表6可知,5,000 r/min模型训练数据达到1,800组,大约为3,000 r/min测试模型训练数据量的9倍,对故障数据的误诊率更低,制冷剂泄漏15%数据的61.29%准确率提高至73.16%。

表5 不同故障类型的模型测试或训练组数(5,000 r/min)
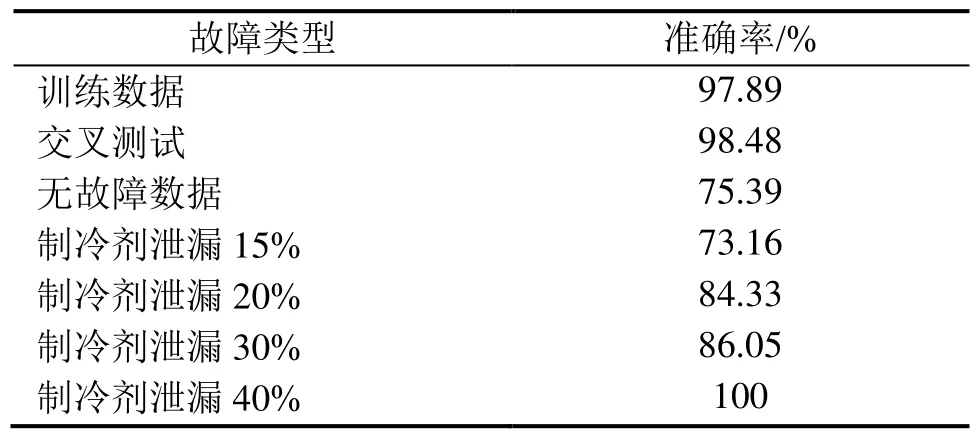
表6 不同故障类型的模型预测结果(5,000 r/min)
3.2 改进的SVDD模型
由前文研究结果可知,准确率提高的同时,无故障数据的测试精度却降低了,经数据分析,这是由于训练数据增多,为缩短模型训练时间,所取有限穷举步长过大造成。这可以通过遗传算法在小范围进一步寻优,获取更好的参数,以提高模型精度。
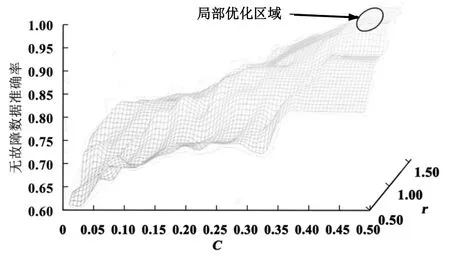
遗传算法也称基因进化算法,或进化算法,属于启发式搜索算法的一种[10]。文中遗传算法的局部优化范围为0.9 表7 采用遗传算法的模型预测结果(5,000 r/min) 在SVDD模型中,通过交叉验证,应用遗传算法优化参数C和γ。完整的网格比较浪费时间,建议首先用较大步长的网格。当初步确定更好的优化区域后,对区域进行细化网格,在交叉验证过程中,建议计算两个参数的分类比例,避免过度拟合。 参数C控制超球面体积和划分错误模型之间的比重,C越小,超球面的半径越大,参数r控制超球面的形状,r越小,越接近边界,在无故障模型中,进行网格探索,C∈(2-10,2-1),r∈(2-10,210),运用5步交叉验证,如图5所示。 图5 不同参数下模型精度分布 本文以变频空调系统作为研究对象,采用了PCA-SVDD的方法,分别构建并研究了不同压缩机转速及制冷剂泄漏不同等级下的故障检测与诊断的模型,得到如下结论: 1)PCA-SVDD模型适用于变频空调系统制冷剂泄漏故障的检测和诊断,随着故障等级的降低,模型的准确率也会随之降低,但小故障等级的模型准确率仍然在60%以上; 2)训练数据的数据量会影响模型准确率,转速为5,000 r/min模型训练数据达到1,800组,约为3,000 r/min测试模型训练数据量的9倍,对故障数据的准确率更高,15%制冷剂泄漏数据的准确率由61.29%提高为73.16%;因此丰富训练数据集可以提高模型准确率; 3)遗传算法可以优化SVDD算法的参数,加速模型收敛,提高模型准确率。本文通过先网格搜索,然后局部使用遗传算法优化的方法改进SVDD模型。模型改进后,模型参数得到优化,模型5,000 r/min转速下无故障数据诊断率由 75.06%提高为93.43%,模型对其他类型故障水平的准确率达到100%,模型的检测能力大幅度提高。
4 结论
