恶意代码演化与溯源技术研究∗
2019-10-28宋文纳彭国军傅建明张焕国陈施旅
宋文纳 , 彭国军 , 傅建明 , 张焕国 , 陈施旅
1(空天信息安全与可信计算教育部重点实验室(武汉大学),湖北 武汉 430072)
2(武汉大学 国家网络安全学院,湖北 武汉 430072)
恶意代码溯源是指通过分析恶意代码生成、传播的规律以及恶意代码之间衍生的关联性,基于目标恶意代码的特性实现对恶意代码源头的追踪.随着互联网的蓬勃发展,恶意代码已经成为威胁互联网安全的关键因素之一.2017 年,AV-TEST 安全报告[1]指出,AV-TEST 系统检测恶意代码规模已经超过6.4 亿,其中,Windows 和Android 平台的恶意软件规模极为显著,与前一年相比,Android 设备端恶意软件数量翻了一番,恶意软件的数量变化如图1[1]和图2[1]所示.
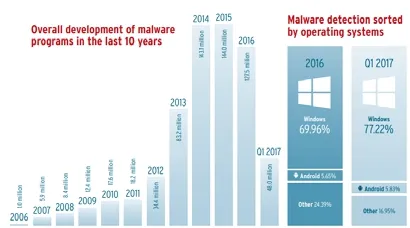
Fig.1 Over development of new malware programs in the last 10 years[1]图1 最近10 年新恶意软件的发展[1]
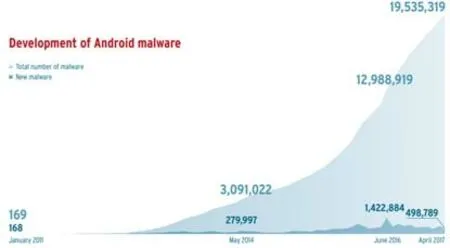
Fig.2 Development of Android malware[1]图2 Android 恶意软件的发展[1]
在与恶意样本的的对抗过程中,恶意软件分析和检测技术也在不断发展.基于静态分析的检测[2,3]、基于动态分析的检测[4−6]以及基于机器学习的检测[7−11]等技术不断涌现:基于静态分析的检测对非混淆样本更为准确;而基于动态分析的检测在检测混淆恶意软件方面表现更为出色;基于机器学习的检测[12−16]是通过对大规模恶意样本进行特征提取(如API(application programming interface)、CFG(control flow graph)、关键字符串值等),然后采用机器学习算法(例如分类或聚类)训练样本,以构建模型判断软件的恶意特性.这为安全研究人员提供了良好的辅助功能,有效地提高了大规模恶意软件的检测速度.
虽然恶意软件检测技术的广泛应用对恶意代码攻击起到了一定抵抗作用,但是震慑力依然不足.
· 一方面,恶意软件检测技术有限,恶意作者可利用免杀技术构建变体绕过恶意软件检测.例如2017 年,安天移动安全联合猎豹移动安全实验室捕获一例使用MonoDroid 框架开发的移动端C#病毒,该病毒将逻辑代码编译成DLL 文件,进而逃避恶意代码的常规检测[17].2017 年5 月份爆发的WannaCry 样本与2017 年3 月份Wcry 样本是同源样本,该变种利用微软SMB 漏洞以及DOUBLEPULSAR 后门实施攻击,绕过了包含360 在内的多个安全检测工具,英国、法国、西班牙、韩国、俄罗斯及中国等多个国家遭受了严重的经济损失[18].
· 另一方面,恶意代码检测技术侧重于对恶意代码的发现和防范,尽管利用该技术可以检测到大多数恶意代码攻击,但是不能提供对恶意代码来源的有效追踪,因此不能从根源上遏制恶意代码的泛滥.
FireEye[19]面向多个组织进行了针对网络安全应急响应速度的调查,其报告指出,在复杂的新型恶意软件和高级先进的持续威胁(APT)环境下,只有20%的组织认为其事件响应计划“非常有效”,而他们最大的安全差距在于是否能够检测和遏制APT 类恶意软件.这说明安全组织对威胁事件的响应计划、人员和工具还不能跟上新的威胁.不过,现有恶意代码检测中的部分工作也可用于恶意代码的溯源研究.例如,恶意代码检测技术中的特征分析可为溯源特征的提取提供借鉴,因为不管是恶意代码的溯源还是检测,在特征提取阶段,均会考虑对代码中包含其典型恶意性的关键代码或数据片段进行分析.
为了进一步震慑黑客组织与网络犯罪活动,目前学术界和产业界均展开了恶意代码溯源分析与研究工作.其基本思路是:利用恶意样本间的同源关系发现溯源痕迹,并根据它们出现的前后关系判定变体来源.恶意代码同源性分析,其目的是判断不同的恶意代码是否源自同一套恶意代码或是否由同一个作者、团队编写,其是否具有内在关联性、相似性.从溯源目标上来看,可分为恶意代码家族溯源及作者溯源.家族变体是已有恶意代码在不断的对抗或功能进化中生成的新型恶意代码[20],针对变体的家族溯源是通过提取其特征数据及代码片段,分析它们与已知样本的同源关系,进而推测可疑恶意样本的家族.例如,Kinable 等人提取恶意代码的系统调用图,采用图匹配的方式比较恶意代码的相似性,识别出同源样本,进行家族分类[21].恶意代码作者溯源即通过分析和提取恶意代码的相关特征,定位出恶意代码作者特征,揭示出样本间的同源关系,进而溯源到已知的作者或组织.例如,文献[22]通过分析Stuxnet 与Duqu 所用的驱动文件在编译平台、时间、代码等方面的同源关系,实现了对它们作者的溯源.Kaspersky 实验室通过深入分析Stuxnet 与Flame 这两款恶意软件发现,2009 版的Stuxnet 中的Resource 207 模板与Flame 中一个插件模块mssecmgr.ocx 几乎完全相同,得出Flame 与Stuxnet的开发人员有过早期合作等结论[23].2015 年,针对中国的某APT 攻击采用了至少4 种不同的程序形态、不同编码风格和不同攻击原理的木马程序,潜伏3 年之久,最终,360 天眼利用多维度的“大数据”分析技术进行同源性分析,进而溯源到“海莲花”黑客组织[24].可见,发现样本间的同源关系对于恶意代码家族和作者的溯源,甚至对攻击组织的溯源以及攻击场景还原、攻击防范等均具有重要意义.
本文主要围绕恶意代码的家族、作者等溯源工作进行进展研究.首先介绍恶意代码的编码特征和演化特性,然后从学术界和产业界两个方面梳理现有的研究工作.归纳并基于学术界所共有的实现环节,分析各个环节面临的关键问题,以及解决这些问题的研究思路;然后对产业界的溯源机理,所能解决的关键问题进行分析,并对学术界和产业界在溯源分析方法方面的区别和联系进行了总结.最后,对已有的恶意代码溯源方法中存在的挑战进行分析,并对未来可进行的研究方向进行了展望.
1 恶意代码的生成过程与演化特性分析
恶意代码是指在一定环境下执行的对计算机系统或网络系统机密性、完整性、可用性产生威胁,具有恶意企图的代码序列[25].恶意代码的编写流程通常如图3 所示.
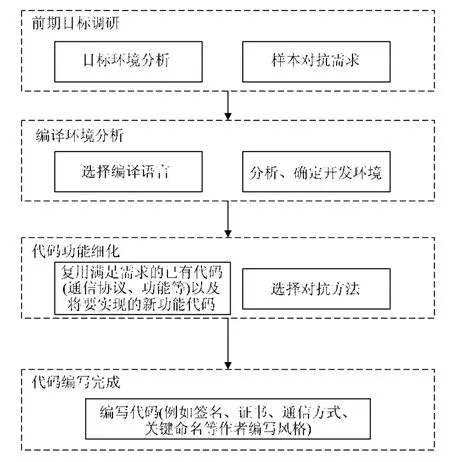
Fig.3 Malicious code writing process图3 恶意代码编写流程
恶意代码与正常应用程序的编写流程基本相似.
(1) 前期目标调研:制定自己代码功能需求,分析目标环境,主要获取目标环境信息.
(2) 编译环境选择:根据前期目标调研阶段的分析结果,确定恶意代码的开发语言与集成开发环境(通常包括编辑器、编译器、调试器和图形用户界面工具等)等,为代码的编写提供开发调试环境条件.
(3) 代码细化功能分析:结合第1 阶段和第2 阶段的代码功能的分析,进一步细化代码行为功能和对抗功能.全新编写代码或者从已有的样本源码库中选择满足自己需求功能的代码片段,并作为创建新程序的复用代码片段.选择合适混淆和对抗环境识别分析的方法,用于编写能够逃避静态和动态分析与检测的恶意代码.
(4) 代码编写:作者按照自己的代码编写风格与习惯进行编码实现,并选择合适的数字证书(APP 开发)进行签名,完成恶意代码的全部实现.
恶意代码的作者编写风格是作者在长期的编写过程中形成的不易改变的代码风格,利用代码编写风格的相似性可以实现对作者的溯源;另外,代码开发环境(如IDE、特殊的代码路径、非默认编译参数等)也可能成为作者溯源特征.
恶意代码遵循正常软件开发流程,但实现的功能往往是破坏计算机系统或者窃取用户隐私等.为了使代码中敏感操作能够逃避检测,恶意作者往往会采用与正常程序不一样的编码方式,从而表现出作为软件与身俱来的软件特性(如复用性、固有缺陷性等)以及作为恶意软件所特有的多种恶意特性(如代码敏感性、对抗性等).此外,在进行恶意代码编写时,功能代码和特有对抗代码的复用可能导致前后衍生软件的相似性.因此,恶意代码的编码特性可为进行溯源分析提供有效线索.下面将具体从恶意代码个体的编码特性以及恶意代码作者和家族的相似性角度进行阐述.
1.1 恶意代码个体的编码特性
恶意代码个体的编码特性指作者在编写恶意代码过程中所呈现出来的代码编写特性,为恶意代码文件的溯源分析提供了良好理论和技术支撑,有助于溯源特征的提取.本文从代码复用性、代码对抗性、代码敏感性、代码固有缺陷性等方面分析恶意代码的编码特性.
1.1.1 代码复用性
复用性是指恶意代码作者在进行代码复用行为后形成的一种代码衍生特性,该特性推动了恶意代码的快速生成.复用行为是恶意代码作者采用的一种,将已有恶意代码中满足自己功能需求的代码片段提取出来,不修改或进行稍许修改并应用于创建新的恶意代码的行为.2014 年,Symantec 报告[26]指出,大部分恶意软件都是已存在恶意软件的变种而不是重新创建的新型恶意软件.2018 年,Symantec 发布的《2017 年度回顾:移动威胁情报报告》[27]指出,2017 年移动平台恶意软件变种的数量增长了54%.可见,代码复用在移动恶意软件开发中具有普遍性,这在当前多个知名的PC 端恶意软件中也得到充分体现.比如,CrySyS 实验室发现Duqu 与Stuxnet 的某些DLL 文件具有多个相似的导出函数,driver 文件中也存在大量相似函数[28];Kaspersky 实验室发现Flame 与Gauss的C&C 服务功能函数、字符串的初始化函数、字符串解密函数等相似[29].另外,恶意软件Cloud Atlas 与RedOctober[30]的压缩算法实现函数相似.
1.1.2 代码固有缺陷性
固有缺陷性主要指恶意代码的编写缺陷.编写缺陷是指恶意代码作者因为个人水平或其他原因,在进行某些功能的编码时,有时候会产生一些编写或逻辑上的错误,而这种错误是在其编写类似代码时每次都会犯,这就形成了作者的固有缺陷.如果多个恶意软件均存在类似缺陷,则可能为同一作者所为.
1.1.3 代码对抗性
对抗性是指恶意代码具有的可以遏制逆向分析以及绕过杀软、穿透代理、防火墙以及对抗IDS 等防护手段.根据对抗类别的不同,恶意代码的对抗分为基于静态分析与检测的对抗、基于动态分析与检测的对抗以及基于机器学习分析与检测的对抗等.恶意软件的对抗性使得恶意代码在系统设备中长期潜伏成为可能,这对系统资源和用户数据造成了严重的潜在威胁.恶意代码对抗类别及常见方法见表1.
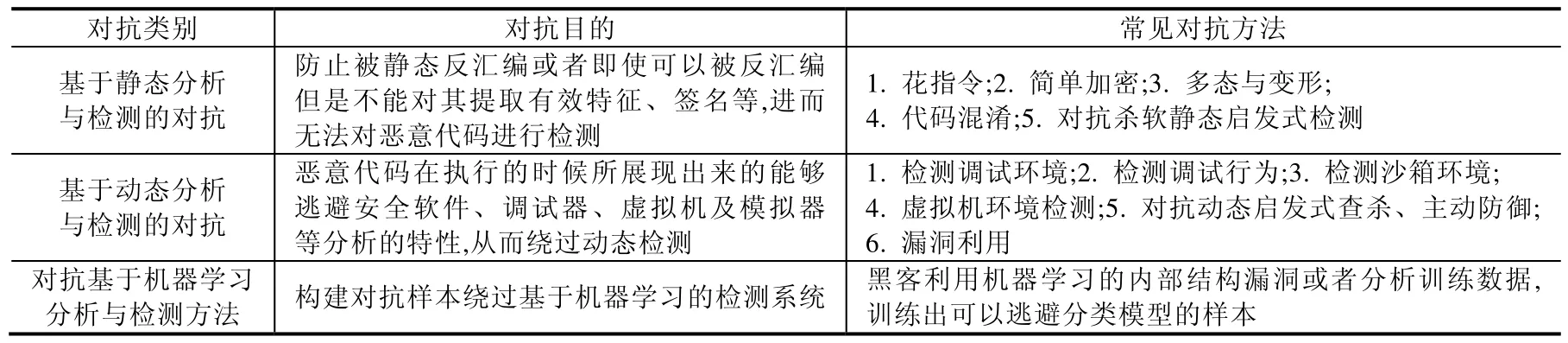
Table 1 Confrontation category and method of Android malware表1 Android 恶意软件的对抗类别及方法
表1 中列出的常见方法描述如下.
1) 基于静态分析与检测的对抗
花指令指精心设计代码逻辑或在指令间插入定义设计的数据,干扰反汇编器给出错误反汇编结果;简单加密指对病毒主体代码采用不同密钥加密,导致不同个体文件数据差异大,从而导致特征值提取困难[31].多态和变形是在加密基础上,在保持代码等价功能的前提下,对解密逻辑及原始病毒主体代码进行变换.保持功能等价的代码变换技术[32]包括插入无关垃圾代码、指令扩展或收缩、改变无关指令执行顺序、插入条件跳转指令、寄存器重新分配、变量重命名等;代码混淆指通过采用字符串混淆[33,34]、控制流混淆[35]等混淆技术对代码自身做出变换,常见的代码变换工具包括DexGuard[36]、ProGuard[37]、AMAD[38]、DroidChameleon[39]、代码隐藏(恶意组件隐藏在资源文件[40−43]中、Manifest 文件欺骗)、动态加载、加壳[44,45],如UPX,ASPACK,ASPROTECT,VMProtect 等;静态启发式检测主要是通过静态启发式扫描分析文件代码的逻辑结构是否含有恶意程序特征[46].常见的对抗杀软静态启发式检测的技术包括多节病毒、加密宿主文件头的前置病毒、入口点隐藏技术、在代码中选择随机入口点、重新利用编译器对齐区域、不适用API 字符串重命名已经存在的节等.
2) 基于动态分析与检测的对抗
(1) 检测调试环境:主要指在检测到调试环境的情况下终止敏感操作,包括从文件特征、进程名、进程数据特征、加载的特定模块、调试器窗口、调试器具有的特殊权限等方面进行检测.例如,利用调试器一般采用DBGHELP 库来装载调试符号,因此根据进程是否加载了DBGHELP.DLL,来判断是否存在调试器环境;通过FindWindow(⋅)等函数查看是否包含调试器标题和类名的窗口:如果存在,则很可能有调试器存在;调试器进程对其他进程调试的时候,需要拥有SeDebugPrivilege 权限,普通进程没有该权限,因此通过打开CSRSS.EXE 进程验证自身进程是否具备SeDebugPrivilege 权限,来确定进程是否被调试.
(2) 检测调试行为:主要指在调试行为发生的情况下,表现出对抗调试或终止敏感操作的行为.对抗调试行为的方法包括基于调试特征检测的调试对抗、基于调试特征隐藏关键代码的调试对抗.例如,利用PEB 结构BeingDebug 标志,在程序处于调试状态时为非0,将其作为特性进行反调试;利用异常中断int3 指令常被设置为软件断点的特性,在代码中置入int3 指令,当程序未被调试时,将进入异常处理继续执行,但是程序处于调试阶段时,int3 被当成调试器自己的断点,而不会进入异常处理程序,通过将核心代码写入异常处理过程,能够避开调试器的执行调用.
(3) 检测沙箱环境:主要指利用硬件序列号、固件版本和其他操作系统配置作为沙箱指纹,通过检测所处环境的沙箱系统和管理程序的每个工件来逃避沙箱系统的分析与检测[47,48].常见方法包括:访问特定注册表项(例如,HKEY_LOCAL_MACHINESYSTEMControlSet001ServicesDiskEnum),然后解析子项的值,查看“vmware”“qemu”“xen”等子字符串的存在情况,以判定沙箱的存在;利用内核数量检测沙箱环境的存在,这是因为正常环境中内核处理器是多个,但是在沙箱环境中通常是单核处理器;通过检测设备信息,并将该信息与沙箱中已知的值进行比较检测沙箱环境;利用模块名称检测沙箱.例如,在模块名称上调用GetModuleHandleA(⋅),如果返回Null,则表示模块已加载,沙箱在进程中注入模块以记录其执行活动,那么通过FreeLibrary(⋅)来卸载模块,使得沙箱将不能记录任何执行痕迹[49].
(4) 虚拟机环境检测:基于虚拟机环境检测的对抗分析方法主要包括3 类:语义攻击(CPU 语义攻击)、基于时间的攻击和字符串攻击[50].例如,文献[51,52]均使用CPU 语义信息来检测虚拟机的存在;文献[53]利用基于时间的技术来确定管理程序自省操作的存在,来识别虚拟机的存在;Thanasis 等人提出的基于QEMU 的模拟器的不完全仿真特点识别模拟器的存在[54];此外,枚举进程也可以识别虚拟机的存在,例如,通过使用Process32First(⋅)/Process32Next(⋅)查找与虚拟机相关的vmsrvc.exe 等进程名称:如果存在,执行非恶意操作,逃避安全检测.
(5) 对抗动态启发式查杀、主动防御:常见的方法包括:调用底层的未拦截API 接口完成上层API 功能;利用受信任进程完成对目标模块的加载,对主动防御拥有比较好的免杀效果;将多个行为在分离在多个进程中实现,将能成功绕过针对目标进程的行为进行综合分析的启发式查杀.例如,在进程A中完成文件释放,进程B中完成提权,进程C完成安装.
(6) 漏洞利用:漏洞利用[55]主要指利用程序中的某些漏洞(如缓冲区溢出漏洞[55]),得到计算机的控制权,进而逃避安全系统的分析与检测.例如,2017 年8 月,FireEye 发布报告指出,APT28 使用EternalBlue漏洞利用工具和开源工具Responder 进行横向传播[56].2017 年4 月,白象组织利用Office 漏洞,该漏洞利用Office OLE 对象链接技术,将包含的恶意链接对象(HTA 文件)嵌在文档中,通过构造响应头中content-type 的字段信息,最后调用mshta.exe 将下载到的HTA 文件执行[57].而目前漏洞利用的高级表现形式是组合漏洞的利用,突破了单一漏洞执行过程中被安全系统分析与检测到,而无法继续运行的问题.例如,2017 年的FinSpy[58]利用CVE-2017-0199,CVE-2017-8759,CVE-2017-11292 等多个漏洞来投递FinSpy,该病毒的复杂性强,对其检测困难.
3) 对抗基于机器学习分析与检测方法
对抗基于机器学习分析与检测:主要是通过对抗性数据操纵恶意软件逃避模型检测[59].攻击者对训练数据进行变形,使其接近训练数据集中良性实例,从而逃避目标分类器分类.目前,学术界的对抗研究是在攻击者对机器学习模型内部(特征空间、分类算法等)[60]、训练数据集、分配给输入样本的分类分数[61]等至少一种了解的情况下,实施的逃避方案.其中,攻击者利用分配给输入样本的分类分数进行的方案,在实际的应用场景实现艰难,因为现实部署的机器学习模型只会暴漏给攻击者最终决策(拒绝、接受等).文献[62]在基于攻击者仅知道机器学习模型的最终决策的情况下,提出一种使用黑盒子变形器操作恶意样本逃避的方法EvadeHC,使PDF 恶意软件有效地逃避了检测器.这表明:基于机器学习模型的恶意代码分析与检测系统并非完全可靠,仍需兼并人工分析.
综上,恶意代码动态和静态分析与检测的对抗方法增强了代码被解读的困难性,加强了代码痕迹被捕获的难度,使得恶意代码具备了一定的自我保护能力.然而在实际操作中,为了平衡恶意代码的运行效率和功能,往往不会在恶意代码中加入非常全面的对抗技术.例如文献[63]中提出:卡巴斯基在2015 年7 月发现Duqu 的新变种Duqu2.0,利用了0day 漏洞,该漏洞无法通过静态分析内容检测到,但是将该恶意软件放在沙箱环境中,利用强大的启发式引擎进行检测,可以拦截到行为.因此,在实际的恶意代码分析与检测中,动静结合使用,往往比采用单一的方法能发现更多的恶意代码.基于机器学习的分析与检测方法在检测大规模恶意代码方面效率大大提升,但是上述分析表明,该方法的自身缺陷可能为黑客提供对抗条件.由此可见,在面对大规模恶意软件的分析与检测方面,人工分析与基于机器学习的分析与检测结合使用,才能更加准确地检测到更多恶意代码.
1.1.4 代码敏感性
代码的敏感性是指恶意代码在进行行为隐蔽触发和敏感资源访问的所表现出来的特性,常见的恶意代码关键示例敏感点主要包括触发条件、系统(API)调用、代码结构、常量(关键字符串)等.图4 为恶意敏感操作执行代码片段示例,图5 为触发分支条件代码片段示例.
图4 中第1 行画线部分表示敏感函数入口点;第5 行表示敏感函数触发分支条件;第6 行和第7 行表示正常操作代码片段;第9 行和第10 行表示恶意代码操作片段;第7 行、第10 行、第15 行、第16 行画线部分表示调用的敏感API.

Fig.4 Malicious sensitive operation execution code snippet example图4 恶意敏感操作执行代码片段示例
图5 中第5 行~第7 行用于判断杀软是否存在;第9 行表示触发敏感操作的分支条件;第10 行、第11 行是正常操作代码片段;第13 行、第14 行是恶意操作代码片段.
下面结合图4、图5 中代码片段示例阐述代码敏感性.
1) 触发条件
触发条件指触发恶意敏感函数执行操作的条件,从触发条件的代码位置角度分为基于敏感函数入口点的触发和基于敏感操作分支的触发.
(1) 前者是指直接或间接触发恶意函数调用的程序入口点[65],从用户角度来看有两种入口点:用户界面和后台调用.根据文献[66,67]中实证研究,敏感API 操作与函数入口点之间如果没有与UI 相关的函数调用即采用后台回调,则所属样本通常具有恶意性.例如,当一个用户交互式API 被悄悄调用时,恶意软件便成功实施该恶意行为[68].如图4 所示,SetTextMessage是基于回调方式将设备号发送出去.
(2) 触发分支条件是指能够触发恶意敏感函数执行的代码分支[69].该分支具有与正常程序分支不一样的特点,文献[64]对触发隐藏敏感操作的分支进行了详细的描述.该分支条件能够使恶意活动尽可能地逃避安全软件的检测,如图5 所示,为了隐藏恶意活动,作者将恶意活动隐藏在第13 行、第14 行所表示的分支路径中,而另一分支完全执行正常活动,且隐藏活动与另一分支及分支条件之间没有共享任何数据与资源,致使安全检测系统在语义层面的追踪也变得困难.
图4 示例中,凌晨3 点~5 点时间来确定何时执行恶意活动(例如窃取私人数据),然而正常软件却很少使用时间作为活动执行的条件输入.上述触发条件的触发形式比较多样化,比如还包括网络指令触发(如远控木马)、环境触发(如GPS 位置变化)等.
2) 系统(API 等)调用
系统调用[70−76]是应用程序与系统交互的接口,实现了代码的功能,表达了关于应用程序行为的实质性语义.为了执行恶意行为,恶意软件需要调用敏感API 函数来实现,但是仅靠单一的API 调用无法判定所属代码的恶意性,因为API 调用具有通用性,许多良性App 也会调用这些API(例如截屏、录音、定位等API).然而,综合样本中多个API 函数构成的序列[77−79],可以看出它存在哪些恶意行为甚至意图.例如,文献[80]从vxheaven[81]中收集271 092 个属于137 个恶意软件家族的样本,相同恶意家族的样本因为共享相同的行为所以会调用更多相同的API 集合,发现至少90%样本中含有15 个相同API,因此,API 集合可以作为恶意性判定的一个特征.图4 展示的恶意性操作代码片段中,API 序列为getDeviceId(⋅),sendTextMessage(“6667”,null,getIMEI(this),null,null),设备号属于用户隐私信息,该序列表明这是将设备号发送出去的操作,存在泄密可能,展现了代码恶意性操作.
3) 代码结构
代码结构[82−84]主要指函数的逻辑结构,可以表达程序的语义信息,是一种细粒度的匹配特征.常见的代码结构表达方式包括如函数调用图FCG(function call graph)、控制流图CFG、程序依赖图PDG (program dependance graph)等.以API 为原子的代码结构表现为FCG,该结构展现了函数的调用逻辑.在恶意代码的家族分类中,FCG相比函数调用组成的序列集更能表达程序的原始信息,因此研究人员通常采用FCG 作为家族特征,用于恶意代码家族的识别;CFG 是以指令为代码单元,能够从触发条件、API 调用、方法调用、结果返回等方面细粒度描述恶意程序的代码逻辑,较全面地覆盖代码所涉及的执行流程;PDG 是一种基于数据流依赖的代码结构,相比前两种语义信息更加丰富,能有效地发现恶意程序的污点传播路径,进一步准确定位恶意程序的执行范围.
4) 常量
常量通过揭示关键参数的值和细粒度的API 语义来传达语义信息[85],例如在图4 中,sendTextMessage(⋅)函数以一个名为PremiumRate的电话号码常量作为参数,比通过getText(⋅)从用户输入接收电话号码的相同API的调用具有更可疑的行为.因此,恶意代码在操作敏感数据的时候关于常量的使用至关重要.
恶意代码在上述特征上通常具有典型敏感性,这是作者编写恶意代码内容的主要特点,也是安全研究人员进行溯源的主要依据之一.
1.2 恶意代码家族和作者的编码相似性
编码相似性是指恶意代码在编码环境及特征上具有相似性,基于恶意代码的编码特性,同一作者或者同一家族的恶意代码在内容和结构上往往存在相似之处[86],这为恶意代码的溯源提供了线索.
1) 同家族恶意代码的编码相似性(功能相似)
恶意代码以功能行为划分家族,同家族恶意软件的代码和行为具有相似甚至相同部分[87].作者为了快速构建恶意代码,复用已有恶意代码生成变体,使得同家族恶意代码中大部分代码及资源保持不变[88].而这些特性在编译后文件中表现为代码片段的相似性,其相似性主要集中在执行敏感操作的代码元素中,例如系统调用、关键字符串(如权限、重打包名字)和代码结构(逻辑结构)等.
· 系统调用:同家族恶意代码为了实施相同的功能行为,往往调用相同或相似的系统敏感函数API.
· 关键字符串:主要指的是硬编码字符串,同家族恶意代码为实现特定元素相关的行为,会在代码中采用关键字符串.
· 代码结构:同家族恶意代码在实施相同的功能行为时,会执行相似代码流程,因此其代码结构相似.
利用上述特性识别恶意代码变体,并根据已知恶意代码家族揭示变体家族.例如,文献[87]通过多个签名条目(字符串、方法名、方法体等)评估不同样本间的相似性,进而归类同家族样本,使得检测变体成为可能;文献[89]利用数据挖掘的方法分析Android 恶意软件家族样本的代码结构,并运用静态分析提取与应用程序片段关联的代码结构CFG,基于该代码结构计算家族指纹,使用该指纹与待检测的恶意软件进行相似度计算,可以识别出同家族恶意软件变体,验证了代码结构用于衡量家族变体间相似性的可行性;文献[90]为了识别Android 恶意软件的多态变体,采用聚类算法和社区结构方法,从家族样本的敏感API 调用子图中提取频繁子图作为恶意软件的家族行为特征,并利用该家族特征识别未知恶意软件,检测率达到94.5%;钱雨村等人[91]提出采用函数调用、资源对象、控制流程图等元素构建五元组行为,并将其作为聚类特征,所提出的方法能够有效地对不同恶意代码及其变种进行同源性分析及判定.综上所述,同家族恶意代码中存在相似性的代码元素,这些元素可以作为家族识别的关键特征.
2) 同作者或团队的编码相似性(风格相似)
同作者或团队编写的恶意代码由于受拥有的相关领域知识、经验、编码工具等限制,使得编写的代码在内容和结构上具有相似性.这种相似性抽象刻画了作者的编码风格,即使通过混淆技术隐藏或不留下其身份信息,但是人的编码习惯不会因为创建非同恶意代码而产生强大的差异.基于人的编程习惯,研究人员可挖掘和利用代码风格追踪到相关的作者.
目前,源代码作者的溯源分析已经相对成熟,其主要用于软件取证和抄袭检测.Krsul 等人[92]将编程习惯主要分为编程布局、编程风格、编程结构这3 类,见表2.基于这些编程习惯,许多研究学者对程序的归属问题进行了广泛研究,提取的特征主要集中在字节码、n-gram 序列、结构化特征等方面.例如,MacDonell 等人[93]基于该编程习惯对恶意作者身份进行识别,识别率达到81.1%;Lange 等人[94]采用布局、词汇以及遗传算法指标作为特征,对20 个作者进行去匿名化,准确率达到75%;Kothari 等人[95]将词汇标记与n-gram 结合使用,对12 个作者进行识别,准确率达到76%;Burrows 等人[96]采用字节级的N-gram 作为特征,对10 个作者的程序进行区分,准确率达到77%;Chen 等人提出通过比较程序数据流来识别作者身份的语义方法,实验结果表明,该方法具有健壮性,即使代码被有意修改,依然可以识别出来[97];Caliskan-Islam 等人[98]抽取抽象语法树作为特征,从GCJ 数据集中识别出1 600 个程序员,准确率达到94%.

Table 2 Authors’ programming habits[92]表2 作者编码习惯[92]
目前,二进制代码作者的溯源相对源代码的溯源工作更加困难,这是因为代码编译导致源码中许多信息丢失,同时,编译器优化可能会改变程序的结构,进一步模糊作者编码风格.Alrabaee 等人[99]设计了OBA2 实验,对8个不同作者创建的程序进行源码和二进制程序的溯源分析,准确率达到77%,验证了源码中一些特征在编译之后仍存在于二进制代码形式中,可用于恶意代码作者身份的识别.目前,常见的二进制恶意代码的溯源作者的编码相似性主要从代码风格和代码结构相似性角度进行分析.
恶意软件的代码风格主要依赖于作者的编码习惯.乔延臣等人[100]通过分析恶意代码中模块的复用风格,构建代码模块的快速溯源机制,且具有较高的准确率和召回率.Rosenblumdent 等人[101]提取指令序列和控制流作为特征,去匿名化准确率达到77%.Caliskan-Islam 等人[102]改善了该方法,分别从反汇编和反编译层面提取语义和语法特征来表示相关作者的编程风格,结合随机森林、SVM 等机器学习算法进行训练,针对100 个作者的900个文件进行识别,准确率达到96%.虽然该文的工作主要针对二进制文件而不是恶意文件的分析,但这依然能为二进制恶意代码的作者溯源提供借鉴.
2018 年2 月份,趋势科技[103]从代码结构着手分析,指出Patchwork 和Confucius 组织的Delphi 恶意代码存在相似之处,如图6~图8 所示.

Fig.6 Decompiled Form structure of Confucius’ sample[103]图6 Confucius 示例的反编译Form 结构[103]

Fig.7 Decompiled Form structure of Patchwork’s[103]图7 Patchwork 示例的反编译Form 结构[103]

Fig.8 Confucius code and Patchwork’s code[103]图8 Confucius 代码和Patchwork 的代码[103]
图6 的Confucius 示例的反编译Form 结构和图7 的Patchwork 示例的Delphi 反编译Form 结构中创建了相同的TForm 对象,如圈内代码所示.图8 展示了两个恶意代码中指令结构的相似性.此外,从代码中字符串域名的解析中发现,这两个团体主要攻击目标是东南亚,尤其是巴基斯坦,基于代码结构的相似性以及攻击方向的趋势可以判定它们来自同一组织.
由此可知,研究作者编写代码风格、代码结构相似性等对二进制恶意代码溯源具有重要意义.
1.3 恶意代码演化特性
恶意代码的个体编码特性、家族和作者的编码相似性,表明大部分恶意代码是对已有代码的修改,揭示了源码的演化趋势.源码的演化促使二进制恶意代码的变化,并为其提供逆向分析思路.移动端和PC 端恶意软件在敏感行为执行上存在差异,例如移动端经常会悄悄发送短信等,但是PC 端不会出现这样的操作,因此下面将分平台阐述二进制恶意代码的演化特性.
1.3.1 传统平台恶意代码的演化特性
了解恶意代码的演化,有助于更好地把握恶意代码的发展趋势,为发现新的恶意软件提供辅助信息,进而快速归属新恶意代码的家族或作者.表3 从时间维度给出了恶意软件典型功能演变历程.
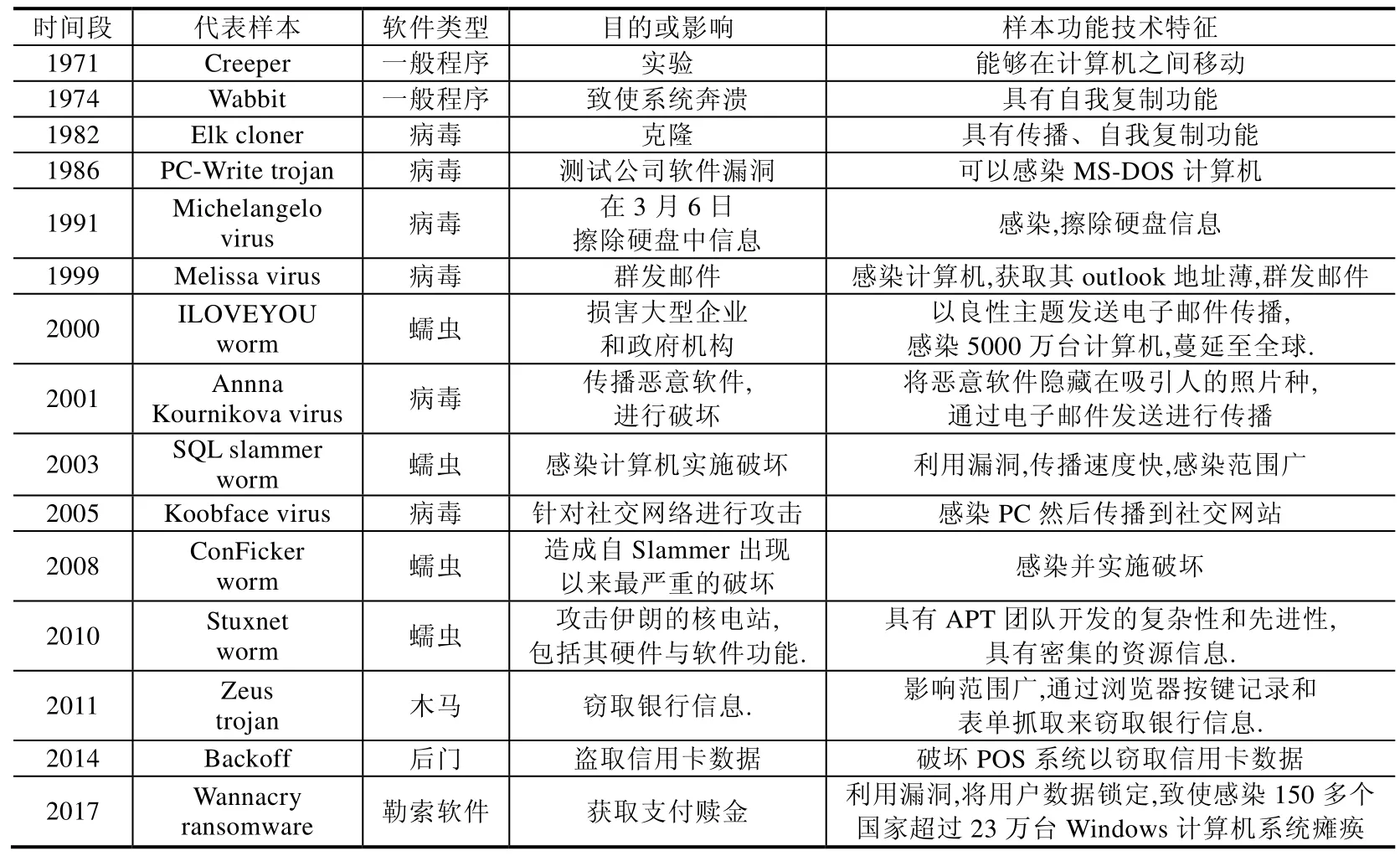
Table 3 Evolution and impact of PC malware表3 PC 端恶意软件的演化及影响
恶意软件的演化历程[104]主要分为3 个阶段.
· 阶段1.1971 年~1999 年的恶意软件主要以原始程序的形式出现,恶意软件功能单一,破坏程度小,无对抗行为.
· 阶段2.2000 年~2008 年,恶意软件的破坏性增强,恶意软件及其工具包数量急剧增长,借助网络感染速率加快,电子邮件类蠕虫、受损网站、SQL 注入攻击成为主流.
· 阶段3.2010 年之后,经济利益和国家利益的驱使下的恶意软件存在团队协作紧密、功能日趋复杂、可持续性强及对抗性强等特点.
上述演变历程中,一方面将恶意软件扩展到了不同平台,例如从早期的PC 计算机到工控行业,但更重要的是恶意代码的功能的进化:恶意代码在前一阶段的个别特性,会在后面阶段中持续增强.促进这种进化因素主要是恶意代码功能的不断改进以及攻防对抗技术的不断博弈.这主要涉及恶意代码攻击行为和生成方式两个过程的演化,具体演化描述如下.
1) 恶意软件的攻击行为演化特性
与传统恶意软件的攻击行为相比,新一代恶意软件[105−107]的攻击行为具备高级性,如图9 所示.
高级恶意软件攻击行为的定向性、持续性、隐蔽性和技术先进性的具体行为表现如下.
(1) 定向性[107]:攻击者利用Web 服务、浏览器和操作系统中的漏洞,或使用社会工程技术发现目标用户,并使用户运行恶意代码来散播恶意软件.
(2) 隐蔽性:一旦进入系统,恶意代码隐藏(加密流量等)并禁用主机保护[108],达到正常运行的目的.
(3) 持续性[108]:安装完成后,恶意代码会调用命令并控制服务器以获取进一步的指令(例如窃取数据、感染其他机器并允许侦察等指令),从而持续性地控制目标机器.
(4) 技术先进性[109]:恶意软件作者使用混淆技术,如无效的代码插入、寄存器重新分配、子程序重新排序、指令替换、代码转换和代码集成等,以逃避传统防御措施(如防火墙、防病毒和网关等).
基于上述行为描述,说明目前的高级恶意软件在功能和防御策略方面更为先进,其造成的影响和损失也更为严重.
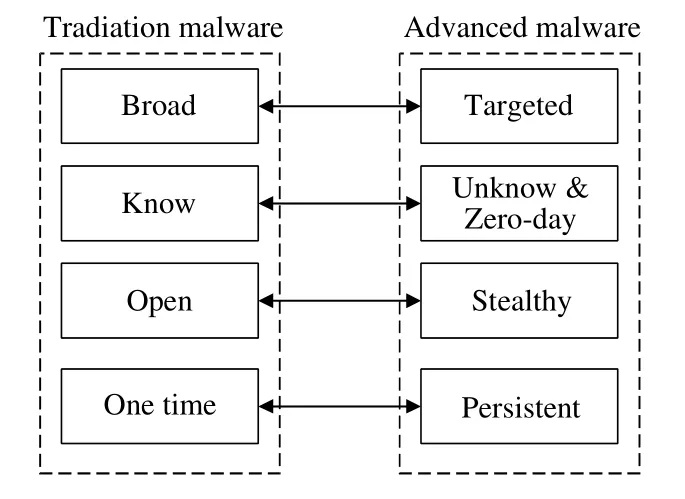
Fig.9 Attack behavior of traditional malware vs.advanced malware[107]图9 传统恶意软件VS 高级恶意软件的攻击行为[107]
2) 恶意软件的生成演化特性
目前,新的恶意软件很少从头开始创建,而是采用自动生成工具、第三方库以及借用现有的恶意软件代码等[82]生成,许多恶意软件都是已存在恶意软件的变体[110].根据一项调查[111]指出,超过98%的新恶意软件样本实际上是来自现有恶意软件家族的衍生产品(或变体).恶意代码经过修改或者自行演化等途径后,往往会形成数十种甚至更多的变种,使得变体数量迅速增长[112].
一个恶意代码变种与原来恶意代码形式上有所不同,但实现行为相似,那么这两个恶意代码称为同一个家族,新生成的恶意代码称为家族变体[113].当前的恶意代码变体在实现技术上大致可分为2大类:一类是共用基础技术(核心模块或理论),黑客通过重用基础模块实现恶意代码变种[114];另一类是针对现有防范和检测而研发的恶意代码混淆技术.恶意代码混淆技术按照其实现原理可分为2 类[115]:一类是干扰反逆向(反汇编)的混淆,使反逆向不能够得到正确的分析结果,从而阻碍进一步机理分析;另一类是指令和控制流混淆,这类混淆技术通常采用加壳、垃圾代码插入、等价指令替换、寄存器重新分配及代码变换等方式改变恶意代码的语法特征,隐藏其内部调用逻辑关系,使得恶意代码逃避恶意软件的检测.
随着恶意代码家族功能和对抗策略的不断调整,新的恶意软件变种及其早期版本的运行时行为通常非常相似,但样本的演化可能会带来家族的进化,以适应新的计算机环境.例如,文献[116]中指出,蠕虫家族Sobig 从版本Sobig.A 到Sobig.F,该蠕虫病毒只是增加或者减少一些特性,其行为近似相同;然而,蠕虫家族Beagle worm从版本A 到版本C 进行了不断的演化和升级,包括增加了后门、增加了阻碍本地安全机制的代码、增添了更好的在已有进程中隐藏蠕虫的机制等,其功能的复杂性提升,家族特性出现新的进化.目前,针对恶意软件生成演化特性的研究主要从家族进化角度进行分析.例如,文献[88]根据导出图的路径模式定义了一个恶意软件演化关系的框架,该方法的局限在于对恶意代码中源代码的定义不包括机器生成的代码,考虑到恶意代码通常是从现有恶意程序中自动生成的,具有限制性;文献[117]对恶意软件的系统进化模型进行研究,探索不同恶意样本数据集对演化模型分析结果的影响;研究人员[118]收集运行时执行指令、内存和寄存器修改等日志信息,构建家族演化树,研究变化样本的来源.
综上所述,传统平台恶意软件的行为演化描述了恶意软件在生成之后所表现的攻击特性.这种特性为研究恶意代码的安全防御系统提供技术支撑,进而加强安全防范,尤其是基于软件运行时行为的检测系统(如沙箱、云平台检测系统等),使之能够更可靠地检测大多数恶意软件及其变体.研究传统平台的恶意代码生成演化特性能够更加全面地把握恶意代码的发展趋势,进一步调整目前基于主机防御系统(如防病毒软件)的不足.恶意代码的攻击行为和生成特性作为恶意软件演化过程中的关键要素,对于构建恶意软件演化史具有重要意义:有助于促进对传统平台恶意软件的全面认识,明确未来恶意软件的发展方向,是恶意软件发展中一个需要不断跟进的领域.
1.3.2 移动平台恶意代码的演化特性
第一种智能手机病毒起源于2004 年[119],被称为Cabir,内容和功能均比较简单,使用传统的白名单即可以准确地对其检测.随着时间的推移,由于恶意作者对目标的修改以及尝试逃避检测,使得构造出的恶意代码不断改变;同时,随着代码复用以及现成工具的广泛性,恶意代码的数量不断攀升.图10 展现恶意家族样本自2012 年到2017 年每个季度的数量规模,表明恶意代码的家族数量整体呈上升趋势[120].
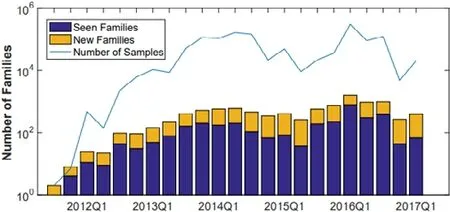
Fig.10 Quantitative scale of family samples in each quarter[120]图10 家族样本每个季度的数量规模[120]
下面具体分析移动平台恶意代码的演化特性,从行为演化和构成策略演化两个方面展开移动平台恶意代码的演化特性分析.
1) 恶意代码的行为演化
以文献[120−125]中对Android 恶意代码演化分析为基础,描述移动端恶意代码的行为演化.恶意软件的行为主要指与特定攻击目标相关的行为[123].恶意代码的行为操作涉及的内容见表4.

Table 4 Android malware behavior and goals表4 Android 恶意软件的行为及目标
(1) 隐私侵犯:据文献[120]统计,2014 年之后,与隐私侵犯相关的API 调用增加.例如HttpURLConnection.connect(⋅)等,该调用结合ContentResolver.query(⋅)可用于查询用户的隐私信息[124].这反映了移动平台恶意软件具备向隐私侵犯行为演化的趋势.
(2) 数据窃取:据文献[120]统计,在2012 年到2014 年,基于短信方式窃取数据的行为较多;而在2014 年之后,主要以网络通道来窃取数据.窃取数据方式的改变表明:互联网技术的发展在为人们带来方便的同时,也给攻击者带来了更多的机会.由此表明:智能化时代的来临,数据保护愈发重要,这也为APP 开发者提出了更高的安全需求.
(3) 欺诈:据McAfee 指出,传统的基于高级短信的收费欺诈形式已经演变为僵尸网络广告欺诈、按次付费下载的分发诈骗以及勒索软件欺诈.目前的诈骗方式伪装手段更高级、迷惑性更强、可持续时间更久.2017 年,McAfee[122]发现目前绝大多数恶意软件都是ad clicker Trojans,它在后台以欺诈手段操作移动广告,创建利润.
(4) 逃避:文献[120]指出,作用于更新攻击以及查询沙箱中某些硬件的相关API 调用在2017 年增加.此外,文献[121]统计指出,自2014 年之后,重命名、字符串加密是使用量增长最快的技术,动态加载、逃避动态分析等技术增加次之,而在Native 中隐藏有效载荷关键代码的方法几乎处于平稳状态.由此可以得出,恶意软件行为具有向逃避动态分析发展的趋势.
(5) 漏洞利用:文献[120]中指出,Process.killProcess(⋅)、File.Pid(⋅)、File.mkdir(⋅)等与漏洞利用相关的API调用增加,表明该行为目前比较流行.文献[121]指出,目前,利用漏洞获取root 权限已经不再流行;与此同时,利用漏洞获取device-admin-privilege 权限成为主流.McAfee[122]指出,2017 年手机银行类木马软件(比如Marcher malware)增加趋势明显,作为虚假更新或通过针对性的电子邮件或短信网络钓鱼提供.
结合上述演化行为,表明Android 恶意代码向更复杂、更具有针对性、逃避性发展,这也对移动安全防御系统提出了更高的挑战.研究移动平台恶意代码的演化行为,可以帮助安全研究人员更好地研究移动可疑恶意软件,理解恶意代码的操作和意图,进而归属出家族变体,促进移动平台安全体系的稳固.
2) 恶意代码构成策略的演化
据赛门铁克统计:2012 年,每个移动恶意软件家族平均有38 个变种;而在2013 年,每个家族变种数量达到58 个[125],展现了移动平台恶意软件变种规模逐年增加的趋势.与此同时,为了逃避移动平台防御系统的检测,自Android 恶意软件出现以来,使用混淆技术构建恶意软件的数量也逐年增加.文献[126]指出,Google Play 中不足25%合法应用程序被混淆[127],90%的恶意代码都使用了混淆技术.恶意软件在演化过程中继承了静态分析的局限性,根据衡量恶意软件行为演化过程中混淆API 的演化趋势,发现加密、反射、动态加载、代码隐藏等混淆技术,在恶意样本的生成过程中被越来越多地采用[41].此外,在分析基于代码隐藏构建的恶意软件Incognito 中,发现其APK 和Dex 的资源文件中,恶意代码所包含的常见方法并不多,这意味着在Incognito 应用程序中隐藏的恶意代码要么不流行、要么被高度混淆而使代码看起来不明显,从而逃避自动化系统动态检测[40].
基于上述对移动平台恶意软件行为演化和对抗技术演化的分析,重建恶意软件系统演化史,将有助于为移动平台中当前恶意软件与之前恶意软件的相关性提供线索,同时明确目前移动平台恶意软件以及未来可能的发展趋势,达到更全面地分析及了解移动平台恶意软件的目的.目前已经提出了基于静态[128]和动态[129]的分析模型,用于识别恶意软件的进化关系.例如,文献[130]提出了基于模型检查的方法来构建Android 恶意软件家族之间的进化关系.因为恶意软件作者通常会采用代码变换技术[131]隐藏派生关系,使得静态分析无效,文中采用动态分析[132]提取系统调用踪迹生成形式化模型,用于验证恶意软件行为的属性,具体为使用通信系统的微积(calculus of communicating systems,简称CCS)来制定模型,结合选择性的mu 演算逻辑表达行为属性,验证结果确定了恶意软件样本共有的常见恶意软件行为.基于该结果推断它们的祖先与后代之间的关系,从而获取家族进化树.建立恶意软件的进化模型有助于把握目前恶意代码的特性、快速地溯源同源样本,发现更多地未知移动平台恶意软件,进一步促进移动平台安全体系的完善.
2 恶意代码溯源机理
学术界和产业界的恶意代码溯源机理存在差异:在学术界,常见的恶意代码溯源依赖于代码的相似性分析,进而揭示恶意代码间的同源关系,且其溯源的目是定位变体家族或作者;而产业界,恶意代码溯源更倾向于恶意代码结构及其攻击链的关联性分析,且其溯源目的是为了挖掘攻击者或攻击背后的真正意图.基于这种差异性,本文将从学术界和产业界分别分析恶意代码的溯源机理.
2.1 学术界恶意代码溯源
学术界恶意代码溯源的基本思想是:采用静态或动态的方式获取恶意代码的特征信息,通过对恶意代码的特征学习,建立不同类别恶意代码的特征模型,通过计算待检测恶意代码针对不同特征类别的相似性度量,指导恶意代码的同源性判定[133].常见的恶意代码溯源主要包括4 个阶段:特征提取、特征预处理、相似性计算、同源判定,各阶段间的流程关系如图11 所示.

Fig.11 Malicious code traceability system model图11 恶意代码溯源系统模型
图11 所示的溯源对象是Windows 平台的PE 文件/Android 平台的APK 文件.将恶意文件输入溯源系统,经过同源分析,获取溯源结果.溯源系统模型的4 个阶段中:实线框包围的特征提取和同源判定是溯源系统中不可缺少的阶段;虚线框包围的特征预处理则根据初始特征是否适合于下一阶段的输入来决定是否执行;虚线框包围的相似性计算是基于聚类的同源性分析中必须执行阶段,相似性计算值作为聚类度量值使用,然而该阶段在基于神经网络的同源分析中省去,这是因为基于神经网络的同源算法旨在通过调整神经网络参数,构建同源性分析模型,在调整好的模型中对样本进行同源处理,无需额外执行样本间相似性计算.本文将详细阐述4 个阶段的实现机理,并评估其优势及缺陷.
2.1.1 特征提取
特征提取是溯源分析过程的基础,具有同源性的恶意代码是通过它们的共有特征与其他代码区分开来的.因此,所提取的特征既要反映出恶意代码的本质和具有同源性恶意代码之间的相似性,又要满足提取的有效性[134].依据溯源目的,溯源特征提取包括溯源家族的特征提取和溯源作者的特征提取.由于编译器的编译、优化以及恶意作者的混淆处理等,编译后的恶意代码中大部分源码信息丢失,特征提取的有效信息量变小.因此,有效地提取恶意代码特征需要做以下两点.
(1) 克服恶意代码的对抗手段.知道变体为避免检测而使用的技术,以便识别在其逃避策略下保持不变的变体的一部分[67].例如在代码级别的变体上,调用间接寻址、代码重排序、垃圾代码插入技术等,逃避使用字符串匹配与偏移或API 调用匹配的简单签名方法.针对该问题已经提出对抗逃避策略的动态或静态分析技术,例如污点分析、代码语义分析、动态分析等.文献[87]提出采用统计性方法获取常见的多个字符串作为签名,这些签名对于重排序和硬编码都是健壮的,因此可以在一定程度上克服恶意代码的对抗手段.
(2) 相似性代码的片段提取.根据恶意代码家族和作者的编码相似性,恶意代码的家族溯源中,以相似性行为代码片段为导向,在编译后的代码中,提取同家族变体的相似性特征来识别同源样本;恶意代码的作者溯源分析中,在编译后的代码及其结构中,提取作者遗留的编码习惯作为特征,来识别同源样本.学术界常见的特征提取类型包括序列特征和代码结构特征,见表5,在恶意代码家族溯源或作者溯源中均效果明显.然而因其溯源目标存在差异,所以两种类型的特征在不同的溯源应用中表现不同.此外,权限特征和资源使用特征在移动平台中广泛采用.下面将揭示序列特征、代码结构特征,权限特征和资源使用特征在溯源家族、溯源作者中的应用情况.
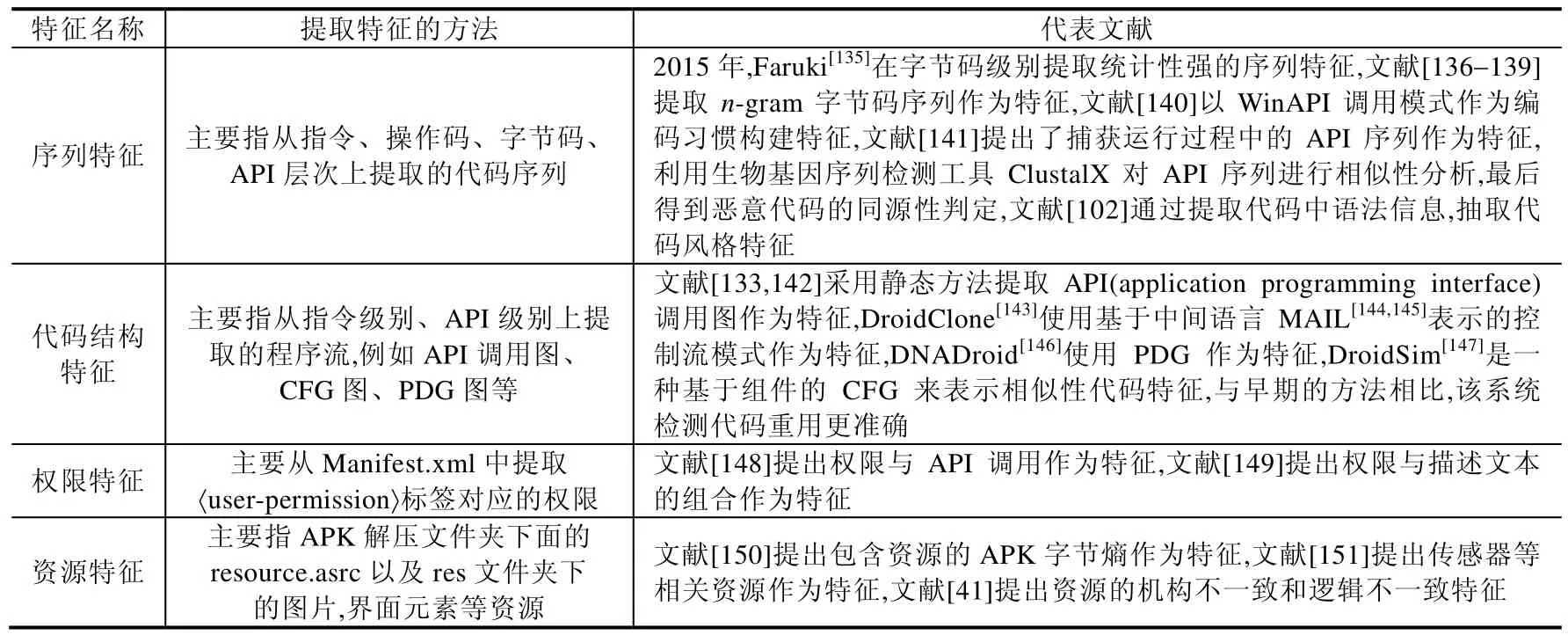
Table 5 Malicious code feature type表5 恶意代码特征类型
1) 序列特征
常见的序列包括指令序列、字节码序列、API 调用序列、n-gram 序列等.序列提取是一种语法分析方法,通过分析语法上不容易被混淆的序列作为特征.文献[135]通过熵值评估和实证研究,提取统计性强的字节码序列作为特征,这种特征在同家族恶意代码中广泛存在,即使该样本被混淆,被混淆部分因发生变化很少出现在较多样本中.然而,如果文件被严重混淆,则无法通过静态分析方式获取特征.动态分析可以克服静态分析的此种缺点,文献[136−139]利用动态分析,从系统调用序列中提取n-gram 序列作为特征.n-gram 序列相对于整个的API调用序列,在数据集中出现的次数更多,稳定性更强,因此该特征相较于API 调用序列具有较好的统计特性,可以用于检测一般性混淆的变体.这些文献均是针对家族变体的分析,API 调用序列、统计性强的字节码序列反映了同家族的行为特征,可以在家族变体分析中使用.然而在基于作者的溯源分析中,不能单纯依据代码功能相似性提取特征,因为即使同一个作者或团队也会编写出不同家族的恶意代码,但是特定类型的编码习惯在编译过程后保留在了二进制文件里,利用该类信息,可以执行二进制作者的溯源.文献[102,140]均提取到了溯源到作者的特征,文献[140]提取了7 类WinAPI 调用模式作为作者的编码习惯特征,有效地溯源到了恶意代码的作者.然而该特征是依据作者已有的样本进行提取,依赖于已有的样本数量.Caliskan-Islam 等人[102]使用Hex-Rays 反编译二进制文件为类似于C 的伪代码,基于该代码构建模糊抽象语法树,然后从语法树中获取可以表示作者编码风格的语法特征,从而实现对恶意代码作者的溯源.在恶意代码的家族溯源和作者溯源中,由于恶意代码的特征大多反映功能、结构信息,反映作者与作者关系的特征较少,因此在溯源作者的特征提取中能够提取到的信息较少,且在学术界,针对作者的溯源文献低于针对家族的溯源文献.在序列特征提取中,统计性强的序列特征可以检测到密切相似的数据对象,但检测恶意软件变体的能力要低得多,因此在同源性分析中,序列特征并不用于准确性匹配.
2) 代码结构特征
代码结构提取是一种从代码逻辑结构提取特征的方法,该特征包含了程序的语义信息,属于细粒度特征.常见的代码结构主要包括API 调用图结构、CFG 图结构、PDG 图结构等.代码结构包含程序的行为语义信息,即使样本的语法被混淆处理,只要语义相同,还是可以追踪到.例如,文献[146]采用PDG 作为代码特征,通过计算两个样本间的相似性,可以有效地检测复用或克隆恶意代码,同时能够抵抗多种类型的检测逃避技术,例如语句重排序、插入以及删除代码等.虽然恶意代码的代码结构特征使得恶意代码对抗性在检测系统中作用变小甚至无效,但在基于代码结构特征的同源分析中,常用的子图同构算法是NP 问题,该问题使得系统计算复杂度变大.例如,文献[142]提出加权的敏感API 调用子图集,作为恶意代码的聚类特征,并对该图进行加权处理,对加权后的敏感API 调用图执行同构计算,加大了系统分析的复杂度.为了消除该问题,文献[133]提出利用卷积神经网络对恶意代码API 调用图进行处理的方法,选择关键节点邻域构建感知野,使图结构数据转换为卷积神经网络能够处理的结构,消除了子图同构带来的问题.
相比代码结构信息,序列信息会丢失恶意代码执行过程中的某些空间特征.但是基于代码结构的相似性分析由于要分析程序执行流程,因此复杂度比较高,效率得不到保证;同时,序列信息比图结构信息更容易获得,因此大多数研究者仍然采用基于指令序列或API 序列的特征进行研究[133].
3) 权限特征
权限是Android 系统的三大保护机制之一,在Manifest 文件中,声明的权限很容易捕获应用程序的数据使用意图,可用于识别应用程序的恶意行为[152].权限特征提取属于轻量级方法,避免了高成本的时间和计算,但是它只能捕获应用程序的粗粒度功能,通常需要结合序列特征、代码结构特征等使用,方能深刻地展示应用程序的行为信息.文献[148]提出采用AXMLPrinter2 工具解析AndroidManifest.xml 文件获取权限,并集合API 调用作为特征集合,用于Android 恶意软件的静态检测,使用权限与API 结合的特征优于仅使用权限作为特征的分类结果,说明权限信息粒度较粗,API 信息有助于恶意软件的分类.文献[149]使用Android 恶意软件的共同权限和描述文本的组合来估计权限的意图,该方法克服了良性应用有意、无意采用类似的权限所引起的错误检测问题,但是由于描述文本中的正面词语并非强制性的,可以伪造且不会丢失任何恶意功能,因此它仍然存在对错误检测和稳健性的挑战.
4) 资源使用特征
资源文件的使用特征在移动平台中应用广泛,该特征主要是从APK 解压后的resources.arsc 文件以及res文件中提取的信息.文献[150]提出在重打包的APK 中,资源文件几乎相同,资源文件的使用可以作为检测恶意代码变体的特征之一,在采用统计性强的字节码熵作为特征的过程中,发现直接提取APK 文件的字节码的检测率,高于仅使用dex 字节码的检测.这主要是因为APK 文件中包含有大量的资源信息,而恶意代码变种往往仅对原始恶意软件中dex 中的代码进行修改,对资源改变很少甚至无改变,因此采用包含资源文件的字节码特征,更能够有效地检测到家族变体.文献[151]提出传感器类型和生成传感器数据传播路径作为特征,以提供传感器使用模式的概述,然后使用传感器使用模式识别应用程序是否具有危害性.文献[41]提出了结构不一致(structural inconsistencies)和逻辑不一致(logical inconsistencies)的资源特征,从而用于识别Android 恶意软件的家族变体.但是文中的资源特征提取使用简单的启发式方法派生,没有涉及程序/资源分析,因此效率较高;但是针对混淆而一般样本的检测问题,该文提出的资源特征不足以分析.
2.1.2 特征预处理
特征预处理在溯源分析技术中起到承上启下作用:承上即对初始特征进行预处理;启下则是为相似性计算提供基础数据.提取的原始特征存在不具有代表性、不能量化等问题,特征预处理针对这一问题进行解决,以提取出适用于相似性计算的代表性特征.根据第2.1.1 节所述,常见的特征类型包括序列特征和代码结构特征,其中,针对移动平台的权限特征和资源使用特征,在具体的表现形式上也以序列特征和代码结构特征为主,下面分析每类特征形式的预处理机理.
1) 序列特征预处理
常见的序列特征预处理方法包括信息熵评估、正则表达式转换、N-grams 序列、序列向量化、权重量化法等.序列特征预处理使得初始特征中冗余特征消除、特征语义表达增强、特征量化等以便于进行相似性计算,具体描述如下.
· 信息熵评估
熵是包含在数据中的信息量的非常广泛的量度,是提取稳定性特征的有用工具[153].根据熵值对特征的信息量进行评估,进而选择出稳定性的特征序列.2016 年,Cheng Wang 等人[154]为了优化操作码序列特征的精度和性能,提出了基于信息熵的特征提取方法来提取数量少但非常有用的信息,来表示恶意软件实例.关键步骤如下.
(1) 在汇编代码中选择2-元组操作码序列,见表6.
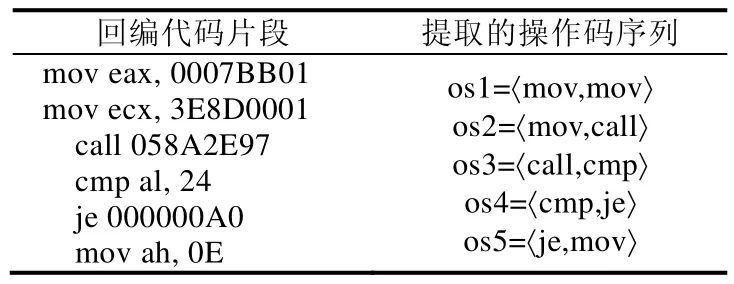
Table 6 Assembly code fragment example表6 汇编代码片段举例
(2) 利用变形信息熵计算操作码序列信息熵,信息熵公式如(1)所示.
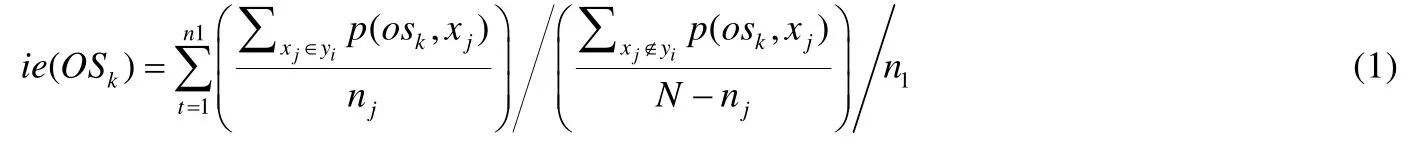
其中,p(osk,xj)表示恶意代码xj中osk操作码序列出现的概率,yi表示恶意软件家族的数目,N为恶意代码总数.设置阈值α,并将ie(OSk)>α的操作码序列提取出来用于相似性比较中的特征数据.选择具有高信息熵的操作码序列作为恶意软件实例的表示,结果表明:较少数量的具有高信息熵的操作码序列,比大量的操作码序列提供更好的准确性和性能,缓解了因操作码多样性导致恶意代码的特征维度大的问题.
· 正则表达式转换
正则表达式是由字符元素以及元素之间的组合组成规则序列,以用来表达对字符串的过滤.在序列的分析中,将序列转换为基于序列元素和序列间关系的正则表达式,从而实现对符合正则表达式的恶意软件识别.该特征是一种启发式特征,可以识别事前未出现的恶意软件.例如,L.Wu[155]通过分析恶意软件敏感API 操作以及事件等,将API 序列特征转换为正则表达式,并在发生类似的正则表达式模式时检测恶意代码,在最终的实验结果中,证明基于正则表达式的方法可以检测出部分新恶意软件.
·N-gram 序列
N-gram 指由较大字符串分割出的固定长度的子字符串[156],例如字符串序列MALWARE,那么被分割出的4-grams 是MALW,ALWA,LWAR,WARE 等.IBM 研究小组最先将N-gram 方法应用于恶意软件分析中[157],使用N-gram 的统计属性可以预测给定序列中下个子序列.从恶意代码提取n-gram 序列,一方面便于进行相似性计算;另一方面,基于n-gram 序列相比原始序列统计性更强,有利于对未知恶意代码序列识别.文献[158]提出对API 调用序列进行n-gram 处理获取子序列,如果采用API 序列作为特征,此时序列相对较长,其他代码(如附加功能)会添加到该部分;然而基于N-gram 的序列子集比整个API 序列的更稳定.采用n-gram 方法将API 调用序列转换为n-gram 序列,具体过程如图12 所示.
S1,S2表示初始特征API 序列,为了方便表示,将API 名称用单个大写英文字符表示,并基于该字符序列提取对应的n-gram 序列,该特征相比API 序列特征更短,且序列种类多样化,在表达相似性上更具有代表性.但是n-gram 很难同时捕获不同长度的序列,存在一个有意义的序列被拆开的可能,影响结果的准确性判定.
· 序列向量化
序列向量化是一种量化序列的方法,将具体的序列转换为可进行计算的数学模型.通过量化分析,有利于进行重要特征的分析,提取出具有代表性特征.此外,量化的特征便于进行相似性计算.例如,文献[158]以API 调用序列作为神经网络分析的目标,经过分析,将一个恶意样本归属到某个恶意软件家族.API 调用序列是由具体名称序列组成的序列,不能进行数学计算,因此在将提取的API 调用序列特征输入到神经网络之前会进行预处理,如果某个API 调用序列中出现2 次或2 次以上相同的API 调用子序列,则消除掉重复的子序列.然后采用one-hot编码对序列中每一个API 构建唯一的二级制向量,该向量的长度等于不同API 调用的总数,将API 调用名称构成的序列转换为二进制向量序列.由于字典中一共包含60 个不同的系统调用,因此不会遇到任何特征向量大小的挑战,实现了特征的量化表示,可以输入到神经网络进行运算.此外,基于神经网络的训练向量往往面临维度高问题,文献[159]初始产生基于字符串、3 元-API 调用组合、API-参数调用组合等3 种类型的特征0.5 亿个,为了降低维度,作者提出采用随机映射将输入的特征维度降低了45 倍,进而使得高纬度的特征数据能够高效地在神经网络模型中训练.序列向量化使得基于特征的数学计算变得可能,进而用于同源性分析的后续处理.
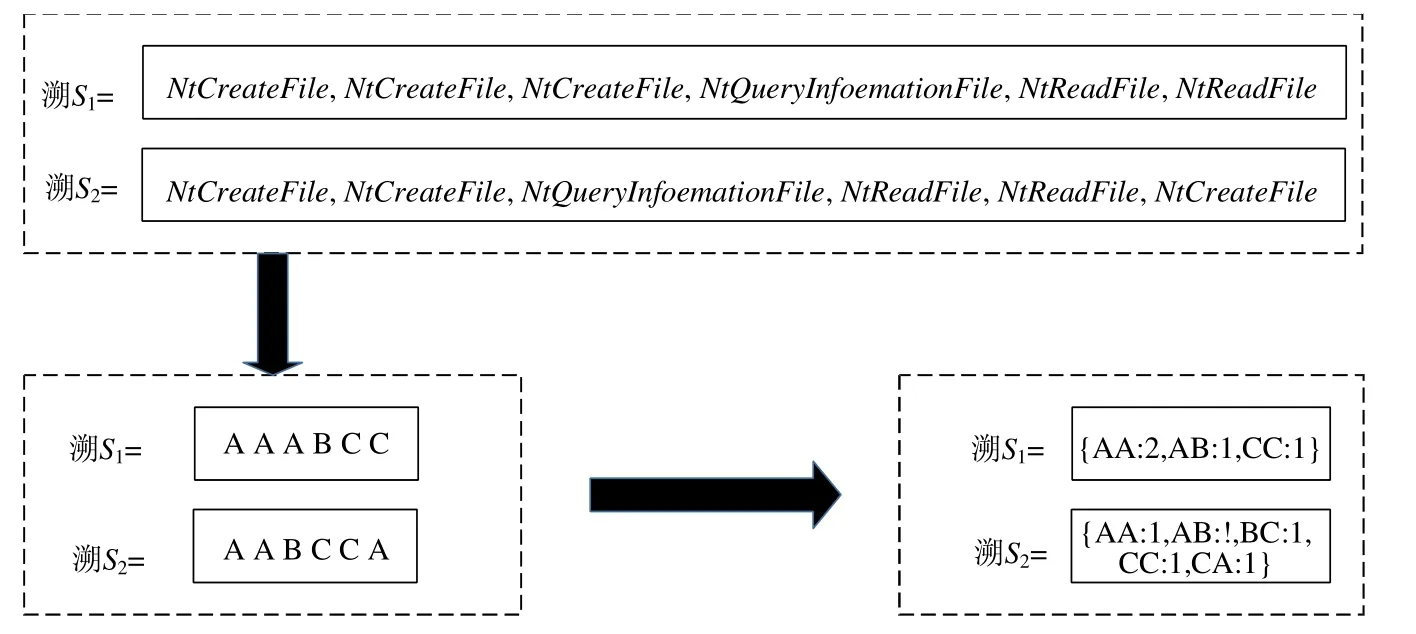
Fig.12 Conversion of API sequences to n-gram sequences图12 API 序列转化为n-gram 序列
· 权重
权重是一种统计分析方法,权重定义了特征重要性.文献[160]提出计算API 调用、返回值、模块名称等动态特征向量的权重,以选择重要的特征.由于权重特征本身的限制,该文构建了一种新的基于TF-IDF 的权重计算方法,如公式(2)所示.
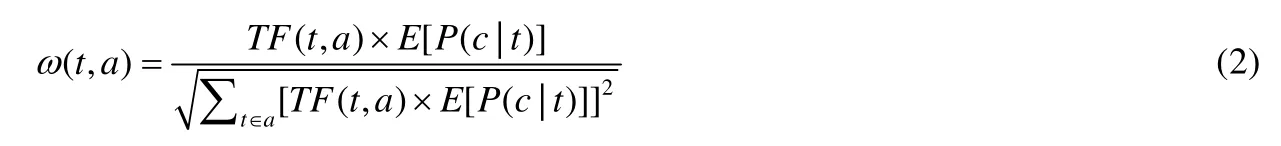
其中,a表示恶意软件变体;t表示恶意软件特征向量;ω(t,a)表示样本a中特征t的权重;TF(t,a)表示变体a中包含该特征t的数目占该变体中所有特征数目的比例;E[P(c|t)]表示特征t在不同家族中出现的差异.ω值越大,说明该特征越能表达样本a的关键信息.根据该权重值可以选择具有强分辨力的特征,即,具有高权重值的靠前特征被选择,并采用Min-Max 对选出的特征向量进行归一化处理.将该特征应用于集成学习算法的分类训练中,并与现有的恶意软件分析类方法,如卡方检验(chi-square test)[161]和主成分分析(principal component analysis,简称PCA)[162]进行比较,发现恶意软件的分类工作比之前更加准确.
2) 代码结构特征预处理
一方面,基于代码结构的特征在相似度比较时存在边、节点等匹配问题即子图同构算法复杂性;另一方面,代码结构特征中存在冗余结构,因此除去冗余、保留与恶意操作相关的代码结构是预处理的主要目的.常见的结构图包括API 调用图、CFG 调用图、PDG 图等.本文将代码结构特征中预处理机理阐述如下.
· API 调用图预处理
API 调用图是由图中敏感API,根据前后调用关系建立的网络结构图.
为了消除图相似性计算的复杂性问题,文献[133]对调用图特征进行预处理,以选择API 调用图中重要节点,具体为采用PageRank 算法计算API 调用节点的重要程度,但是在API 调用图中,某个节点不需要用户随机访问,因此使用PageRank 算法的时,需要考虑每个API 对恶意代码行为的贡献程度,结合PageRank 算法和贡献程度实现对API 重要程度的计算;同时对API 进行分类,为不同API 设置不同的等级;然后计算各节点在图中重要程度,从而选择关键节点,构建出适合于神经网络算法的输入值.
2016 年,文献[90]为了对抗重打包中正常代码部分对恶意代码部分的影响,以提取出更能代表家族恶意代码部分的特征,在基于家族恶意代码API 调用图的基础上,利用社区结构算法进一步提取API 调用图的敏感频繁子图,并将其作为家族恶意代码特征,特征的进一步细化使得系统对应用程序的识别速率提升,识别一个软件的时间减少到了4.4s.
· CFG 图预处理
CFG 图以单个代码语句为原子单位,细粒度地表示了程序的执行流程[163].面对其在图同构方面的复杂性问题,文献[124]采用Hyperion[164]二进制静态分析工具,将恶意软件的CFG 结构以正则表达式字符串的形式生成,正则表达式中包含汇编指令信息和程序的控制结构信息,使得基于图的相似性匹配转换为基于字符串的相似性匹配,解决了图匹配带来的复杂度.此外,文献[165]提出采用Poulik 等人[166]设计的方法将CFG 转化为基于一定语法的字符串,该方法抽象地表示了应用程序的信息,在抵抗代码变换方面,比基于n-gram 特征表达的方法具有更好的抵抗性.文献[167]提出CFG 与DFG 结合,转化为矩阵形式用于CNN 模型训练,在准确率方面取得了良好的效果,针对Marvin 数据集的检测达到了99.649%,但是在召回率方面低于文献[165].这可能是因为前者包含了数据流分析,匹配更加精准,使得漏报情况相对较重.
· PDG 图预处理
PDG 图是一种结合数据流和控制流分析的代码结构,展现了敏感操作的依赖性,包含程序语义信息.但是该特征结构在匹配时是一种准确性匹配,因此计算复杂度比较高.文献[168]对基于单个方法的PDG 进行预处理,将PDG 转换为一组特征向量,并根据特征向量找到相似性引用程序集群.该方法对应用程序中所有方法进行处理以提取一组特征向量,当一组新的应用程序加入时,它需要与以前的大量特征向量再次进行比较,因此效率低下.但是需要检测没有任何先验知识的未知恶意代码时,该方法有效.
基于上述描述表明:在图特征的预处理过程中,评估图中的关键节点、非图形化处理、排除图中非相关子图[169]均是对图进行预处理,以消除图相似性计算复杂度的有效方法,基于神经网络模型的应用使得消除图结构间的计算成为可能.在实际同源判定中,需要结合所构建的特征以及实际应用场景及目的,来选择合适的特征预处理方案.
2.1.3 相似性计算
溯源的目是通过分析样本的同源性定位到家族或作者,样本的同源性可以通过分析代码相似性来获取.相似性计算旨在衡量恶意代码间相似度,具体为采用一种相似性模型对恶意代码的特征进行运算.根据预处理特征类型的不同以及溯源需求(效率、准确性等)的差异,采用不同的相似性运算方法.目前比较流行的相似性计算方法主要集中在对集合、序列、向量、图等特征表现形式的处理.
1) 基于集合的相似性计算
集合是多个元素的组合,这是一种简单的特征形式,常见的相似性计算方法为Jaccard 系数等.Qiao 等人[80]在不同恶意样本API 集合的相似性比较中采用了Jaccard 系数方法,将为A,B两个集合的交集在并集中所占的比例作为相似度,比例值越大,证明越相似,如公式(3)所示.

通过以上计算,将查询点与待比较空间中的集合点进行比较,返回满足条件的结果.该算法思想简单,操作方面,在基于集合形式的特征中广泛采用.
2) 序列形式特征的相似性计算
序列特征的相似性计算既要考虑序列元素的匹配,又要考虑序列的次序关系.2013 年,Faruki 等人[135]提出采用SDhash 相似性散列技术构建样本的签名序列,并采用汉明距离法对序列进行相似性计算,从而识别同源性样本.恶意软件通常会将其恶意负载隐藏在DEX 或托管为主应用APK 的资源文件中,文献[163]从DEX 或APK类型的应用程序中提取所有可用资源中的片段构建特征序列,结合模糊Hash 和特征Hash 的方法[164]计算样本之间的相似度.此外,也有研究者采用数据挖掘的方法进行相似性计算,例如,乔等人[140]利用频繁模式离群因子计算基于 WinAPI 调用序列的相似性;文献[143]将两个字符串形式的签名中公共的 LCS(largest common substring)长度占较大签名长度的比值作为相似性值,此种方法是一种简单的数学算法,计算复杂度低.
3) 基于向量形式特征的相似性计算
向量是一种基于维度的几何表示方法,在相似性比较中,需要明确各维度的特征类别,使得不同样本的特征向量中各维度具备一致性.文献[170]提出基于指纹的特征,但该指纹是位特征向量,因此不能直接采用Jaccard相似度进行计算.为了计算两个指纹之间的相似性,文中采用了位Jaccard 相似度计算代表相同内容的位特征向量之间的相似性.具体过程为:1) 计算两个向量并集的基数,假设A和B是两个位特征向量,那么两个向量并集的基数是A+B,按位求并的结果向量中“1”的数目;2) 计算两个向量交集中基数,仍然基于上述假设,两个向量交集的基数是两个向量按位交集结果中“1”的数目;3) 将交集的基数除以并集的基数即为位向量间的相似度值.Suarez-Tangil 等人[89]用数据挖掘算法中向量空间模型,展示家族的恶意代码特征形式,将同家族提取出来的具有代表性的CFG 元素作为特征中维度,采用余弦算法对不同家族的向量空间模型进行相似度计算,根据余弦值来判断它们的相似性,从而识别出相似性样本,进而归属到对应的家族.用于比较向量的余弦相似度反映了恶意代码间的相似性,其具体公式如公式(4)所示.
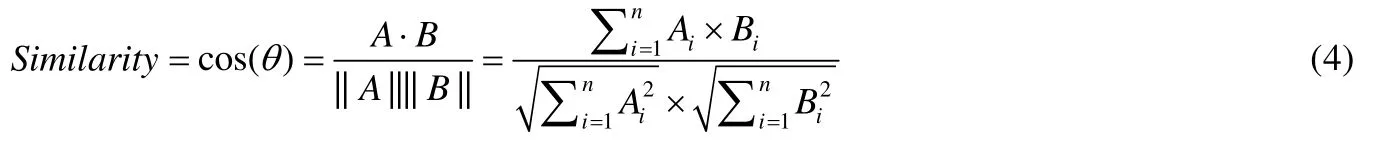
公式(4)中计算的相似性值在0 和1 之间,并且基于阈值确定相似性变体.该阈值与相似性分析结果的准确性密切相关,因此在现实世界中,如果要寻找恶意软件变体,则需要严格制定阈值.
4) 图特征的相似性计算
图特征的相似性计算涉及到图中边和节点的匹配,复杂性比较高.文献[171]提出采用的是最小距离匹配度量法,比较不同样本的CFG 图特征的相似性.Kinable 等人通过静态分析恶意代码的系统调用图,采用图匹配的方式计算图相似性得分,该得分近似于图的编辑距离.利用该得分比较样本的相似性,采用聚类算法将样本进行聚类,实现家族分类[82].Fan 等人[90]将API 调用图的敏感子图集作为特征,为了计算图之间的相似度,文中自定义加权敏感API 子图匹配方法来计算同源恶意行为的图形之间的相似度,同时容忍较小的实现差异.文献[105]采用两个匹配——“Initial matching”,“second matching”和统计模型来计算样本特征的相似性.在“Initial matching”中,匹配具有完全相同4 元组值的方法;在“second matching”中,递归地比较先前匹配方法的Parent/Child 方法的4 个元组值.Parent 方法是调用上一个匹配方法的方法,而Child 方法是由以前匹配的方法调用的方法.
基于上述描述表明:针对不同的特征形式可以采用同一种算法,例如,Jaccard 系数既可以用于集合形式的相似性计算,也可以用于向量等其他特征.此外,在实际的特征相似性分析中,往往由于特征形式的多样性,会采用多种相似性计算方法结合使用.上述相似性比较方法中:基于集合的比较方法实现简单,但没有考虑变量间的相关性;而基于向量的相似性比较考虑了变量的位置关系,但是向量方法容易引起维度膨胀问题;基于序列的相似性比较考虑了变量的次序关系,但缺乏元素间的相关性分析;基于图特征的相似性比较则考虑了变量间的语义相关性,但计算复杂度大,该特征往往用于需要精确匹配的场景中.上述相似性比较的粒度依次变细,在实际溯源分析中,需要结合应用需求,选择合适的相似性计算方法.
2.1.4 同源判定
目前,学术界常见的同源判定方法主要包括基于聚类算法的同源判定、基于神经网络的同源判定等.利用聚类算法操作相似性值获取待测样本同源度,同源度越高,溯源结果越准确.
1) 目前,在恶意代码的聚类中,应用广泛的聚类算法是基于密度的聚类算法、划分聚类算法、层次聚类算法、近邻聚类算法,具体见表7.
这里以DBSCAN 聚类算法[172]来阐述其聚类原理.DBSCAN 聚类搜索数据空间中密集区域,并与低密度区域分隔,低密度区域样本被认为是“噪音”,因此被丢弃.DBSCAN 聚类一共包括4 个阶段,步骤如下.
(1) 对于待测集合中尚未检查过的对象p,如p未被处理过(归为某个簇或者标记为噪声),则检查其邻域:若包含的对象数大于阈值,则建立新簇C,将其中的所有点加入候选集N.
(2) 对候选集N中所有尚未被处理的对象q,检查其邻域:若至少包含阈值个对象,则将这些对象加入N;如果q未归入任何一个簇,则将q加入C.
(3) 重复步骤2),继续检查N中未处理的对象,直至当前候选集N为空.
(4) 重复步骤1)~步骤3),直到所有对象都归入了某个簇或标记为噪声.
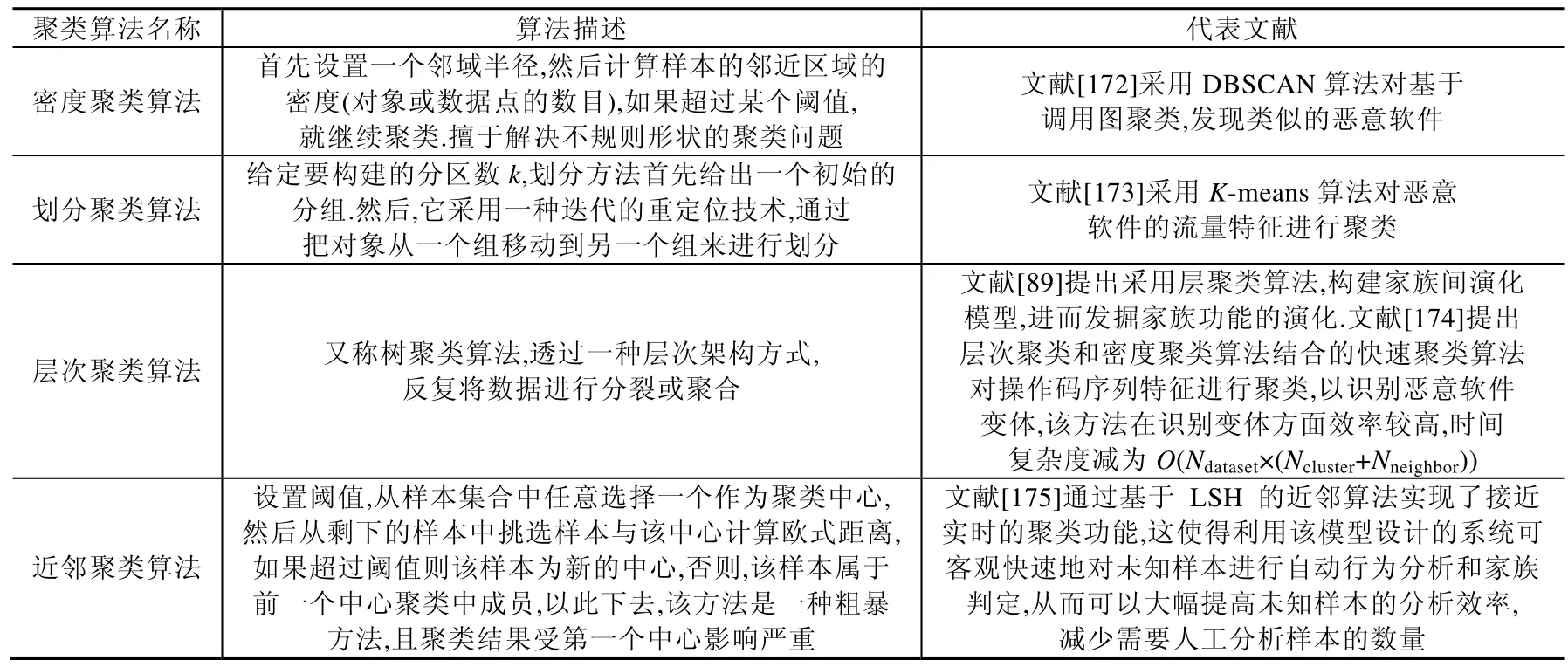
Table 7 Application of clustering algorithm in homology judgment表7 聚类算法在同源判定中的应用
图13 描述了在训练时间内子簇及其代表性样本和对应的家族之间的关联.实线方形框表示聚出来的家族,椭圆形框表示簇,椭圆形里面的刺边圆圈表示簇中的代表样本即簇中心.新样本输入时,将新样本分别与已分类家族中的代表样本即椭圆中的刺边圆圈进行相似性计算,选择相似性值排名靠前的样本,通过同源决策(选择相似性样本的平均值,以最接近样本的家族作为归属家族或者将选出的靠前几个候选样本交给人工分析等决策方法),归属到对应的家族.
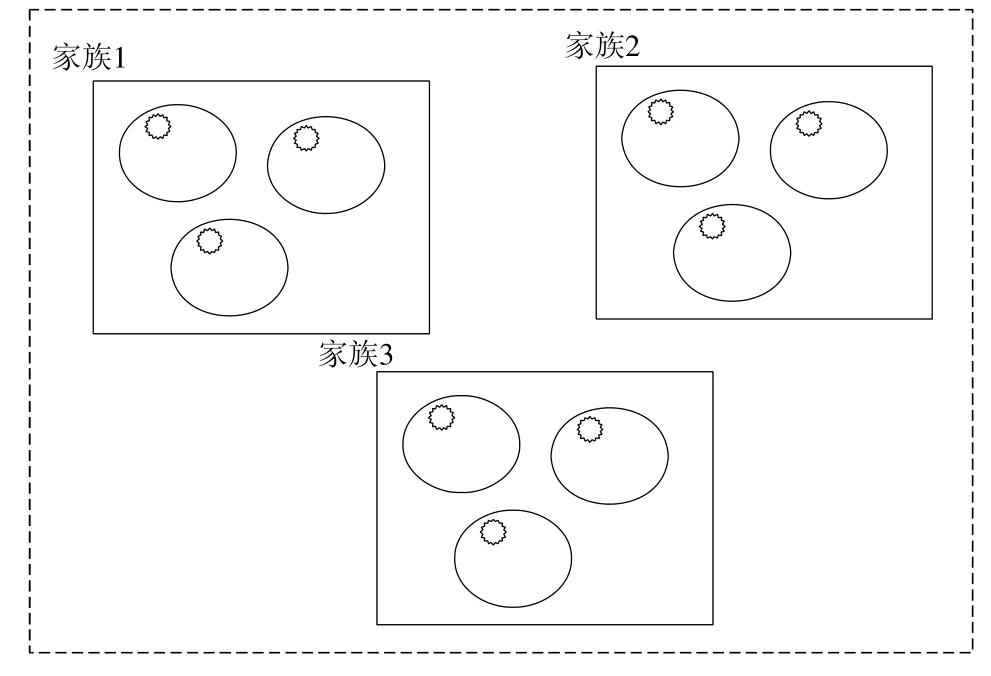
Fig.13 Abstracted cluster model图13 抽象聚类模型
DBSCAN 聚类算法的优势在于聚类时不需要事先指定聚类的簇数,可根据样本之间的差异性将相似样本聚为一类.此外,在该算法中,高密度区域可以是任意形状,样本不一定要围绕单个中心,这符合恶意代码演化、衍生的特点,适用于同源性恶意代码的聚类.
基于聚类算法的同源判定一般步骤如下.
· 设置聚类阈值.
· 利用聚类算法进行聚簇运算,使得同一簇内的数据对象的相似性尽可能大;同时,不在同一簇中的数据对象的差异性也尽可能地大.
· 同源判定,如果同簇中属于同一家族或同一作者的多;而同一家族或同一作者的样本几乎很少出现的不同簇中,则表明聚类出的模型同源性判定效果强.
2) 基于神经网络的同源判定.
神经网络是一种多层网络的机器学习算法,可以处理多特征以及复杂特征的同源判定.基本思想为:将样本特征作为输入层数据,然后不断调整神经网络参数,直到输出的样本与该样本是一种同源关系未为止.在测试过程中,将恶意代码特征送输入层,即可判断恶意代码的同源性.
赵炳麟等人[133]提出了基于神经网络的同源判定方法,其整体实现框架如图14 所示.
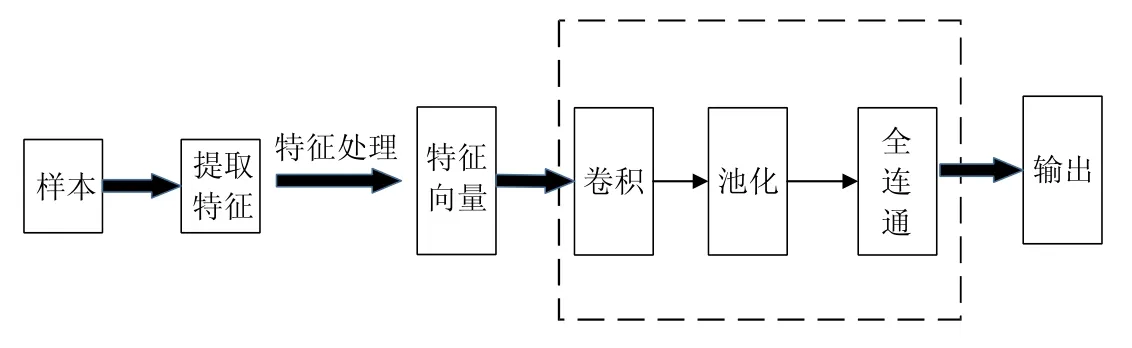
Fig.14 CNN-based homologous analysis model of malicious code图14 基于CNN 的恶意代码同源分析模型
下面描述具体实现过程.
· 采用静态分析方法分析恶意代码,提取其API 调用图作为恶意代码样本的特征,该阶段操作为图14 中的“提取特征”.
· 选择调用图中的关键节点,使其能够与卷积神经网络的输入匹配,该阶段为图14 中的“特征处理”.以关键节点邻域构建感知野,使图结构数据转换为卷积神经网络能够处理的结构,设置一个统一的规则,使图的邻域到感知野是一条单射函数,从而保证具有相似结构特征和属性的节点能够映射到感知野的相似区域.这个过程是对关键节点及其邻近节点的一个规范化的过程,至此,特征向量构建完毕.
· 将特征向量输入CNN 模型进行训练,直到模型处于稳定状态.至此,基于CNN 的恶意代码同源判定模型建立完毕.
· 对8 个家族的恶意样本进行测试,实验结果表明,恶意代码同源性分析的准确率达到93%,并且针对恶意代码检测的准确率达到96%.
根据上述研究发现,基于聚类算法的同源判定过程为不断调整聚类阈值、测试其同源性强度的过程.在该过程中存在以下问题:1) 图特征的相似性计算是个NP 问题,计算复杂度大;2) 当出现多类型特征共存时,需要考虑不同类型特征带来的影响,导致相似性判定模型变得复杂,影响同源判定结果.而基于神经网络的聚类算法主要的运算是对其调参过程,只要特征满足该神经网络模型的输入标准,即使包含多类型特征,依然可执行同源判定.
2.2 产业界恶意代码溯源
产业界除了采用与学术界类似的同源判定方法之外,还会通过关联的方法对恶意代码进行溯源.
2.2.1 溯源意图
产业界的溯源意图除了溯源出编写恶意代码作者、恶意代码家族之外,还要挖掘出攻击者及攻击者背后的真正意图,从而遏制攻击者的进一步行动.
2.2.2 溯源机理
产业界与学术界溯源方法的差异主要表现在特征提取和同源判定两个方面:在特征提取上,产业界更倾向于从代码结构、攻击链中提取相似性特征;在同源判定上,除了采用与已有的历史样本进行相似度聚类分析之外,产业界还会采用一些关联性分析方法.目前,产业界常见的溯源特征见表8.
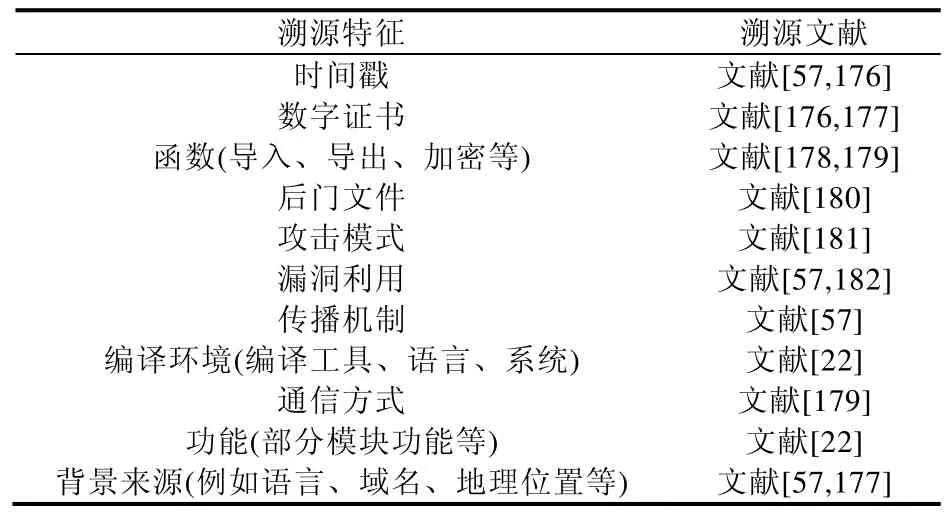
Table 8 Traceability characteristics of industry表8 产业界溯源特征
表8 展示了产业界溯源特征类别多,对溯源样本的描述全面详细,下面举例阐述这些特征.
FireEye[176]实验室于2013 年对APT 高级可持续攻击进行分析,在攻击所用的恶意代码中发现了相同的代码段、时间戳、数字证书等,收集恶意代码中这些信息作为特征,基于这些特征进行关联分析,认为攻击均是由同一个组织操纵.
文献[177]指出,将所有收集到的可执行文件的时区、时间戳作为溯源特征,根据特定标准分组统计,将统计出来的工作时间映射到攻击者的时区,再根据世界时区分布图,就可以定推断攻击者所在的区域或国家.
Mandiant 的研究人员通过文件的导入函数信息生成哈希作为特征,用于追踪APT 攻击的恶意代码[178].
2017 年,McAfee 报告[180]指出,Appears 恶意软件与Lazarus Cybercrime Group 有关,发现Appears 中包含一个ELF 格式的后门文件,该ELF 文件与已报告属于Lazarus 网络犯罪组织的多个可执行文件类似,因此判定该恶意软件的作者是Lazarus Cybercrime Group.
攻击模式主要指某些攻击团队特有的攻击套路,并且长期专注于一个领域的攻击.例如2016 年10 月爆发的Mirai 僵尸网络[181]主要利用物联网设备默认口令的问题感染大量设备,通过对其攻击模式进行相似性匹配,溯源到对应的作者.
在“白象”组织最新的攻击行动中[57],安天工程师对“白象组织”进行了追踪分析,通过分析样本中的系统账号、开发编译工具、样本编译时间等对黑客组织成员进行画像分析;继而对用户ID 进行追踪,并将ID 为“cr01nk zer0”的黑客关联到了www.null.co.in 网站的一个发帖人,捕获其邮箱等个人信息;同时,在多个论坛进行关联,深入挖掘相关信息,最终确定其来源区域为东南亚某国.
启明星辰[182]揭露海德薇(Hedwig)组织在利用文件漏洞攻击的样本中,样本所利用的漏洞和内嵌的Shellcode 高度同源.例如,2012 年至2014 年拦截到的CVE-2010-3333 漏洞的shellcode 和2015 年拦截到的CVE-2012-0158 漏洞部分样本的shellcode 功能、代码完全一致.这些可以作为关联分析的特征,进而溯源到黑客组织.
Gostev[22]花费2 个月分析Duqu 木马,发现Stuxnet 与Duqu 所用的驱动文件在编译平台、时间、代码等方面具有相似性,并通过关联分析得出 Duqu 是 Stuxnet 先驱的结论.文献[103]从代码模块着手分析,指出Patchwork 和Confucius 组织的Delphi 恶意代码存在相似之处.
安天[57]对“女神”行动的溯源包括对C&C 的分析,发现“女神”攻击样本涉及到3 个域名,通过whois 查询溯源到注册人均来自同一个人,且注册地为东南亚;此外,进行时间戳的分析关联当时活跃的黑客组织,最终确定该攻击来自于东南亚某国.此外,安天对“苦酒(BITTER)”行动进行C&C 分析,获取攻击邮件域名、伪装样本App、邮件和数据中“非常好的”英文等,并对这些信息进行关联分析,推断攻击者的区域及特点.
2013 年曝光的“阿克斯(Arx)”组织利用0day 漏洞(CVE-2013-3906 等传播Trojan[Spy]/Win32.Zbot 和Trojan/Win32.Dapato 恶意软件.安天对从攻击者样本的时间节点、攻击目标、传播细节、相关的C&C 基础设施的注册信息等提取特征进行关联分分析,发现“阿克斯”组织与“白象”组织并不存在明显联系,但是也来自东南亚某国[57],且攻击大部分目标均为中国,这些组织具有相似的背景线索和特点,推测它们可能来自某国的不同组织.
安天对“白象二代”组织[57]的一名开发人员ID 为“Kanishk”进行关联分析,发现中文翻译为“迦腻色迦”,迦腻色伽是贵霜帝国(Kushan Empire)的君主,贵霜帝国主要控制范围在印度河流域,此背景信息提供攻击者潜在的来源信息.
上述案例主要从样本、C&C 信息、背景来源等作为溯源特征关联到攻击者.相比学术界溯源特征,产业界溯源特征更加详细全面,信息复杂度大.因此,学术界的同源判定方法并不能完全用于产业界各类特征的相似性分析中.通过对360 安全威胁中心[183,184]、火眼[185]、安天CERT[57]、绿盟[181]等公开的溯源素材进行分析,将产业界溯源方法分类见表9.

Table 9 Common malicious code traceability method in industry表9 产业界常见恶意代码溯源方法
溯源方法已经在产业界广泛使用,在实际溯源分析中,一般会结合关联分析技术、画像分析等溯源到攻击者及真实意图.例如,文献[183]获取C&C 服务器域名后,查询其whois 信息,然后与贴吧信息关联定位到攻击者.文献[184]中在获得下载恶意代码的域名信息后,利用360 威胁情报中心分析平台扩展样本信息,获取历史样本信息以及与其相关的溯源报告,通过信息关联定位出APT 攻击者.绿盟[181]指出,2015 年,乌克兰电厂遭受攻击之后,攻击者利用killdisk 组件销毁了全部数据,在主机上没有留下任何操作痕迹,最终通过全流量分析找到了溯源线索.FireEye 通过多重调查、针对端点和网络侦测持续监控,并对APT28 组织的攻击活动进行追踪和画像,最终确定APT28 是俄罗斯政府幕后支持的黑客组织[185].绿盟[181]在溯源关于攻击者使用加密的SMTP 服务器窃取敏感信息的案例中,分析入侵日志,获取到邮箱的用户名与密码,登陆攻击者邮箱,在登陆邮箱后发现攻击者真实邮箱,通过进一步的关联分析,定位到了攻击者.文献[181]对样本进行分析获取时间戳,统计出相应的时区,推断出攻击者所在的国家,最后,基于互联网上公开的信息进行关联分析和画像分析,确定攻击组织.这些案例均是通过手动分析关联恶意代码攻击者,虽然定位结果信息全面,但是效率较低,无法做到完全自动化地溯源.此外,从“白象”系列的攻击中发现,中国大量基础的信息安全环节和产品能力还不到位.“白象一代”以免杀PE 辅助有限的社会工程技巧,成功实施了攻击,这是一种轻量级APT 攻击;而“白象二代”虽然采用高级的对抗方法,但也未见其使用0day 漏洞,且所使用的漏洞是已经被修补过的,其中2 个漏洞也未经过免杀处理,但依然成功实施了攻击.由此可见,当前,补丁、系统加固等基础安全环节不到位、产品能力仍然不足.
3 恶意代码溯源对抗
自从“GhostNet”幽灵网、APT1 等事件之后,近年来,全球范围内各类网络攻击事件不断被曝光,恶意代码溯源手段和技术也在不断发展,“白象”“海莲花(APT32)”“摩诃草”等各类溯源分析报告陆续被公布.2017 年,美国有24 个研究机构[186]展开了APT 的相关溯源研究,发布相关研究报告多达47 篇;我国有4 个机构发布了8 篇报告,居全球第二.
恶意样本、攻击行为(攻击者)、攻击手段和渠道(攻击者与攻击事件的关联)是溯源分析的关键要素,黑客组织为了尽可能消除溯源线索,目前从代码、攻击行为等多个层面采取了对抗措施.
(1) 代码角度的溯源对抗:恶意开发者尽可能在代码编写生成阶段消除(或伪造)溯源痕迹,或采用技术手段混淆甚至隐藏自身关键特征信息,避免特征信息的暴漏.
(2) 攻击行为的溯源对抗:黑客组织采用精准定位、伪装、隐藏(持续免杀或无文件运行)、自毁等方式,使得攻击行为不被发现;在攻击渠道方面,黑客组织采用代理、匿名网络技术阻止对实际攻击来源、渠道的追踪.
3.1 代码角度的溯源对抗
代码的溯源对抗主要指攻击者在恶意代码发布之前,对代码文件进行痕迹(如生成时间、时区、特殊字符串、语言、C&C 域名、团队代码特征、开发坏境等)消除、伪造或混淆处理,使得安全研究人员从中无法或者尽可能少地提取到有效信息.例如2017 年,安天移动安全分析团队对Dvmap 病毒分析报告[187]显示:该黑客组织故意隐匿APK 文件生成时间,在生成APK 时修改系统本地时间,导致解包APK 文件获取到的生成时间为1979年.同样在2017 年,维基解密公布Vault7 系列数百份文件中泄露,CIA 在恶意程序源码Marble 中插入外语,嫁祸中国、俄罗斯等国.比如,将恶意程序中使用的语言伪装为汉语而非美式英语,然后假装掩饰使用汉语的痕迹,用于阻碍取证调查人员和反病毒公司将病毒、木马和黑客攻击行为溯源到CIA 身上.另外,大量使用加壳和代码加固方案,也提升了代码痕迹被提取分析的难度.
第1.1.3 节描述了编写恶意软件的对抗性方法,这些方法同样使得从恶意代码中提取同源特征信息变得困难.
以上这些措施不仅会妨碍产业界对单个样本的人工溯源进度以及与其他样本的关联难度,同时也将给需要大量标注样本的学术领域溯源研究带来障碍.
然而,随着主机行为监控[188]、恶意代码API[91]、栈异常的shellcode 检测[189]、敏感信息测量[190]、内核虚拟机防护[191]、解析壳[192]等各种安全防护机制的不断出现,恶意开发者也开始对代码进行了自我保护处理,使得代码的解读变得更加困难.
3.2 攻击行为的溯源对抗
恶意软件攻击行为的溯源对抗主要指软件运行后,攻击团队或恶意软件自身进行的对抗行为,主要包括自身伪装、持续免杀策略、攻击定向性提升、控守网络隐匿、攻击载体隐匿等.
(1) 增强自身伪装,提高人工分析溯源难度.
目前常见的伪装程序分为重打包程序和区域性伪装.重打包程序伪装将恶意程序逻辑隐藏在合法程序的有用功能之后,且恶意程序只占重打包程序的小部分,致使系统调用[193]和敏感路径[194]等特征在合法组件和恶意组件中无法区分,因此在恶意代码检测及恶意代码家族变体识别时容易逃离.陈凯等人[195]为了识别出重打包恶意软件,构建基于UI 界面结构和代码方法层结构的MassVet,该方法在识别重打包恶意代码方面取得效果,但仍然有限,特别是识别具有防御策略的恶意软件.
区域性伪装则往往与特定区域相关,主要是通过将特定区域的语言、域名、时区、组织等嵌入到伪装程序中,从而逃离区域溯源.例如,2017 年6 月8 日,卡巴斯基[196]发布报告《Dvmap:The first Android malware with code injection》指出,该恶意软件所包含的“.root_sh”脚本文件中存在中文注释,推测其开发人员可能是中国人,但通过对其恶意样本载荷向位于亚马逊云的页面接口回传的数据进行分析,发现该页面域名中包含“d3pritf0m3bku5”字样,经分析为印度尼西亚方言;同时,对恶意样本colourblock 的Google Play 市场缓存及全球其他分发来源的页面留存信息关联分析,得到Retgumhoap Kanumep 为该恶意样本声明的作者姓名,其姓“Kanumep”各字母从右至左逆序排列则为Pemunak,即印度尼西亚语“软件”之意,融合多方证据证明,该黑客来源于印度尼西亚.
(2) 增强免杀手段,提高抗分析能力,提高安全软件检测难度.
恶意代码的复杂度显著增强,主要指恶意代码开发的复杂性提升,以逃避查杀.2017 年,在高级攻击领域[58],FinSpy 的代码经过多层虚拟机保护,并且还有反调试和反虚拟机等功能;在2017 年4 月,Seduploader 的新版本增加了一些新功能,例如截图功能或从C2 服务器直接加载到内存中执行,从而逃避恶意软件的检测.安天在《白象的舞步——HangOver 攻击事件回顾及部分样本分析》中指出,“白象一代”使用了超过500 个C&C 域名样本,同时采用多种环境开发编译,例如VC,VB,.net,Autoit 等,结合PE 免杀处理等手段,且在该次攻击后,具有相关基因特点的攻击载荷变少,说明黑客组织已经开始着手对抗检测方法,并已经拥有对抗溯源的意识.而在2015 年的“白象二代”中,黑客组织使用了具有极高社工构造技巧的鱼叉钓鱼邮件进行定向投放、在传播方式上不再单纯采用附件而转为下载链接、部分漏洞利用采用了反检测技术对抗手段,初步具备了更为清晰的远程控制的指令体系.“白象二代”相比“白象一代”的技术手段更为高级,其攻击行动在整体性和技术能力上的提升,可能带来攻击成功率上的提升.
(3) 提升目标定位精度,增强攻击定向性,降低样本被捕获几率.
传统的恶意代码攻击未分析目标特点,实行随机性的最大传播策略,这种机制容易暴漏自己.因此,为了避免被发现,攻击者会尽可能地多了解攻击目标,实施小范围的攻击活动,这样可有效降低样本被捕获分析的几率.例如海莲花团伙的攻击活动中,鱼叉邮件的社工特性突出,体现为对攻击目标的深度了解,例如样本中的附件名:invitation letter-zhejiang ***** working group.doc,星号是非常具体的目标所在组织的简称,意味着这是完全对目标定制的攻击木马.2018 年,Confucius 黑客组织执行客户端和服务器端的IP 过滤,仅对指定IP 地址进行破坏,如果受害者来自攻击目标以外的国家,该程序将自行删除并退出.这与2017 年底,来自该组织的C&C 不仅可以从任何IP 地址访问,而且可以在不进行身份验证的情况下,浏览服务器目录树,形成鲜明对比[58].
(4) 提升通信控制方式的隐匿性,提高攻击者被溯源难度.
目前,恶意代码通信方式更加隐蔽,体现在域名隐藏、IP 地址动态变化等.例如,海莲花组织为了抵抗溯源开启Whois 域名隐藏和并且不断更换服务器的IP 地址,并使用DGA 算法生成动态域名,增加了安全分析人员定位有效服务器难度.海莲花组织在最新攻击中,攻击者对采用的网络基础设施也做了更彻底的隔离,使之更不容易做关联溯源分析[58].
(5) 通过无痕迹运行技术,隐匿攻击代码,提升攻击代码被定位难度.
近年来,无文件恶意代码攻击又开始逐渐引起注意.无文件恶意代码没有文件载体仅在内存中运行,该类软件运行后不会在磁盘上留下痕迹,溯源检测困难.比如,安天分析“女神”(Shakti)行动发现,其样本运行时会在内存中解密一个dll 模块并注入到浏览器进程中,这些dll 模块都被直接注入到内存中运行,在磁盘中并无实体文件[58].趋势科技[197]发现,木马软件JS-POWMET.DE 通过完全无文件的感染,完成整个攻击过程,这种极其隐蔽的操作使得沙箱难以分析,甚至专门的安全分析师也难以察觉.
这种恶意软件的出现已经表明,网络犯罪分子将会使用一切手段来躲避安全软件的检测和分析.这在一定程度上说明那些不常见的无文件恶意软件的感染方法也在不断发展,即使安全研究人员能够从内存中获取代码,调查工作仍然很难开展.
4 恶意代码溯源面临的挑战和发展趋势
严峻的网络安全对抗和博弈形势,使得对恶意代码的演化与溯源技术的研究价值凸显,学术界、产业界近年来分别从攻击和防护[198,199]两个方面展开了深入的研究.前文基于已有的研究总结了恶意代码的生成过程和编码特征,并对来自产业界、学术界恶意代码的溯源机理和溯源对抗方法进行了详细描述.目前,学术界和产业界在恶意代码溯源技术方面取得了较大的进步,在追踪恶意代码组织、黑客组织(攻击者)、发现未知恶意代码方面取得了部分研究成果,例如海莲花、白象、方程式组织等典型APT 攻击计划和黑客团队的不断曝光.但依然存在不足和挑战.具体描述如下:
(1) 产业界恶意代码溯源特征提取与分析的自动化程度严重不足.
目前,产业界的溯源分析过程主要基于人工分析手段,例如,Sasser 与Netsky、Duqu 与Stuxnet、Flame 与Gauss 等的识别工作均由相关安全专家人工分析完成,虽然分析结果详细全面、可信度高,但受专家经验影响较大,其效率较低.
这主要是因为溯源特征碎片化,特征提取位置不稳定,与此同时,恶意代码作者采用大量的对抗技术应对自动化检测与分析,使得特征自动化提取困难.这些困难都是目前自动化溯源分析面临的重要挑战.
(2) 编译器及开源代码复用给溯源工作带来干扰.
一方面,大量攻击程序源代码被公开,开源项目及第三方库如雨后春笋,这也导致目前很多恶意代码在编码阶段开始进行大量的代码复用;另外一方面,即便处理不同的复用代码,编译器也将自动插入大量相似代码,这给基于代码相似性的溯源分析带来很大干扰.比如,文献[200]使用VC6.0 和GCC-4.7.2 编译了一个只包含用c语言编写的主函数的源代码文件,使用IDA pro 逆向二进制可执行文件,发现VC6.0 插入了103 个函数.而GCC-4.7.2 插入了18 个函数,不同编译器插入的函数与函数插入的位置均不同,需要大量的经验和技巧才能识别这些函数,这类函数对恶意代码分析与同源判定工作造成干扰.如何有效排除公共复用代码干扰,是后续需要解决的一个问题.
除此之外,即便是对于相同的病毒代码,当攻击者采用不同的编译器、不同的编译参数进行编译时,最终生成的代码特征也可能发生较大变化,从而导致原本同源的代码被漏判.
(3) 溯源对抗和伪造手段将对溯源工作带来严重挑战.
目前,有效的恶意代码溯源案例中,大多都依赖了类似特殊字符串、语言、控守地址、作者编码心理、代码风格、时间戳等极具个性化且易被伪造的低维特征.为了防止被溯源追踪,目前部分恶意软件作者和团队已经具备溯源对抗意识并开始采用溯源对抗甚至伪造手段,这将对恶意软件的溯源工作带来极大挑战.
(4) 恶意代码溯源基础库缺乏,溯源分析效率低下.
提升溯源效率的第一要素,需要构建恶意代码、代码编写者、攻击团队的代码或行为基础库,否则,即便获得以往攻击样本的变种,也很难快速获得溯源数据支撑.
目前,在溯源基础库的构建方面还存在较多问题.
· 首先,在恶意代码溯源特征库构建方面,目前已有的恶意性判定特征和积累难以直接适用.目前,恶意代码捕获样本数量多,但以往主要是以“恶意性判定”为目标来构建特征库,但恶意性判定特征与恶意代码家族聚类特征存在很大差异.
· 其次,在恶意代码编写者和攻击者基础库方面,由于之前被定位的恶意代码编写者与攻击者基础数据少,这一工作还难以有效开展.
(5) 溯源攻击者(代码使用者)困难.
目前,针对攻击者的追踪主要发生在产业界,恶意代码攻击者的追踪需要对攻击者手段、攻击者行为进行刻画,同时需要结合攻击意图等关联到攻击者.攻击意图的分析需要结合多个攻击样本集分析其功能,同时了解黑客背景,例如黑客的活跃区域、擅长的攻击手段等,构建攻击行为演化趋势,揭示出攻击背后的真正意图.然而在实际的攻击中,黑客活动异常隐蔽,所暴露的活动只是很少部分,此外,嫁祸类攻击日益增多,因此识别真正来自于某个组织的攻击特点是溯源攻击者的另一挑战.
除此之外,攻击者信息还依赖于跨境、跨国第三方平台(论坛、Github、网盘资源)信息等,但是第三方平台人员信息复杂、数量庞大,同时存在伪造信息的可能,因此,即使能够追溯到攻击者的部分信息,准确定位到个人还是需要进一步针对个人进行审查.
(6) 新型APT 攻击溯源难度大.
目前,学术界和产业界在恶意代码家族聚类[91]及溯源分析[189]方面主要依赖已知的恶意代码,已知样本量越大,溯源结果越准确.已有的恶意样本为溯源变体提供了先验知识,但如果仅根据已有的样本来识别变体,将可能导致溯源工作低效甚至无效,特别是在应对APT 环境下的零日恶意样本时.随着APT 功能的复杂以及逃避技术的增强,已有的历史数据无法检测出高级的APT 攻击.
(7) 产学研合作需要增强.
目前,学术界恶意代码溯源分析方法主要采用学术界已有算法和相关理论成果,并辅以产业界公开的安全分析网站及报告等信息,样本提取与标注数据严重不足,难以构建满足现实溯源需求、切实有效的溯源分析方法.而产业界获取的特征信息虽然详细全面,但是缺乏良好的自动化特征提取模式与溯源关联分析机制,更多的是借助于人工分析平台辅以有限的信息自动化关联,效率低下.产业界与学术界如何进一步加强合作,构建更加有效的溯源技术与体系,是今后发展的一个必然选择.
在应对相关挑战的同时,恶意软件溯源研究与分析工作将得到系统化推动,溯源对抗技术也将在对抗博弈中得到不断发展.对于后续发展,相关展望如下.
(1) 政府部门将在溯源基础信息库的建设工作起到主导作用,多方协同建设机制将被构建.
恶意代码的演化衍生特性涉及软件静态特征、行为规律、家族衍生特性、作者编码习惯、恶意软件团队特性等,这些是做好恶意代码溯源分析工作的基础与重要依据.
选择合适的特征及特征粒度构建基础库特征模板,充分利用现有的恶意软件信息库以及程序自动化分析技术,构建融合恶意软件静态特征、行为规律、家族衍生特性、作者及团队风格等的强大溯源基础信息库,是今后不可回避的一个研究和建设重点.
在溯源基础信息库的建设过程中,基于恶意代码溯源工作的重要性与特殊性,政府部门必将起到主导作用,各大安全厂商、重要互联网企业、各类重要信息系统所在单位等将作为重要支撑单位进行协同建设.比如,当前的各大反病毒厂商的样本以及归属判定知识,将为基础信息库奠定重要基础,同时由于其强大的样本捕获与分析体系,反病毒厂商也必将成为溯源基础信息库后续不断完善的重要渠道.
(2) 网络威胁情报库建设与共享将进一步增强.
准确、及时的网络威胁情报库,是恶意软件发现和溯源的另外一个重要基础.目前,多个安全公司都构建了自己的网络威胁情报分析平台,如何有效地加强合作建设与资源共享,将成为国家网络威胁溯源的重要基础.
从建设内容上说,除了目前已有的威胁数据之外,来自暗网和攻击第一现场的最新威胁情报、最新恶意软件样本、最新漏洞攻击样本以及代码静态和行为特征,都将成为网络威胁情报库建设的重要内容;与此同时,开源软件平台、典型网络攻击平台和框架的公开资源也将成为网络威胁情报库构建时的重要来源.
(3) 溯源对抗措施将日益成熟和体系化,溯源质量和可信度将受到影响
目前,逃避溯源已经成为恶意软件攻击的一个重要考量因素.与此同时,产业界中基于低维经验特征的溯源取证分析工作还将持续,人工分析在相当一段时间内依然是溯源分析的主要手段.
在此背景下,恶意软件作者和团队将投入更多精力在溯源对抗技术研发中,基于现有溯源机制的溯源对抗方法、框架和体系将会得到不断成熟,相应的溯源伪造、干扰工具和体系将被构建.这不仅可以去除、混淆甚至能够伪造溯源特征,这将对今后恶意软件溯源分析报告的质量与可信度形成极大影响.
(4) 溯源痕迹伪造识别技术将成为恶意代码溯源工作的重要需求.
随着溯源痕迹伪造技术的不断应用,现有的基于低维简单溯源特征的溯源分析手段将难以发挥应有的作用.如何有效识别溯源伪造样本,排除溯源伪造样本形成的干扰,成为产业界溯源工作不可回避的重要任务,这也将成为学术界溯源分析研究的重要需求之一.
(5) 难以伪造的基于高层语义的溯源特征将被提出和构建.
细粒度的恶意软件行为刻画、代表攻击本质的恶意软件攻击意图重塑等,将可能成为对抗伪造溯源痕迹的重要依据与突破点.
(6) 多维度的溯源特征智能化解析机制将被构建.
随着样本特征库信息量以及样本分析粒度的不断丰富,对恶意代码的家族和来源认识将更加全面,在样本细粒度分析与提取技术的不断提升下,家族恶意代码特征智能化解析将成为发展趋势,各类恶意软件溯源特征自动化分析平台将被构建,进而可脱离对人工分析的过度依赖.而自动化解析机制的形成,也将进一步推动溯源基础信息库的构建.
(7) 基于智能化的恶意软件自动化溯源定位机制将逐渐构建.
随着恶意软件家族聚类研究和溯源分析技术的不断推进,以及恶意样本的溯源知识库的不断完善,恶意代码、团队、作者溯源基因库将逐步构建和细化,产业界与学术界将合作日益紧密.结合网络态势感知、数字画像技术、大数据分析、机器学习、深度学习等技术实现的攻击者自动化溯源定位机制将被构建和不断推动.
