基于互联网大数据“接地气”的深度学习研究
2019-10-24谢妤婕孟凡然刘旭东刘凤海贾国柱
谢妤婕,孟凡然,刘旭东,杨 鑫,刘凤海,贾国柱
1 概述
“接地气”在百度百科中解释为:广泛接触老百姓的普通生活,反映最底层普通民众的愿望、诉求。用大众的生活习惯、用语等,而不是脱离了群众的实际需求和真实愿望,而是踏踏实实。用来形容一些政府官员及名人,比较亲善大众。再看近年来,两起打破常规的政治选举事件,跟“接地气”有着微妙的联系。2019 年4 月21 日,作为“政治素人”的喜剧演员泽连斯基利用社交媒体,用喜剧、漫画来调侃竞争对手,并将普通民众的诉求、愿望、利益作为自己的竞选重点,拉近与选民的距离,靠着非常“接地气”的形象大获全胜,成功当选乌克兰总统。还有诸多实例都能说明“接地气”与政客、政治领域紧密相关,引起媒体的关注和报道。从这些实例中可以看出,“接地气”,本身带有一种感情色彩。另外,从百度指数来看,“接地气”呈现明显的震荡趋势,对“接地气”的研究有很大的价值。
那么我们是否可以通过研究“接地气”的相关数据,建立一个关于“接地气”的情感分析语料库,从而辅佐媒体等领域的研究呢?本文将从以下方面来展开对“接地气”的研究。大数据是互联网平台产业的结晶,利用大数据是分析事物客观规律的有效途径。本文选取百度指数、CNKI 数据库等数据作为数据源。在对数据进行自然语言分析(NLP)时,发现“简单”和“接地气”有着很高的相关性,不过“简单”的百度指数和“接地气”的百度指数这两列数据集是非平稳时间序列,且相关性复杂,不能只运用简单的线性分析。为了得到更可靠的分析,本文选择了MF-DCCA 对“简单”和“接地气”进行分析,并为进一步形成关于“接地气”的情感分析语料库做了基础性的工作。
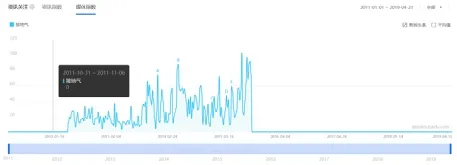
图1
2 数据源与研究方法
2.1 数据源
百度指数是一个数据共享平台,基于以百度为搜索引擎的海量网民的行为数据构建,作为研究数据具有一定的可信度和普遍性[1]。
CNKI 是中国影响力大、内容全的数字图书馆和网络资源共享平台,核心期刊和重要评价性数据库来源期刊的收录率达到99% 以上,其信息内容有非常明确的来源、出处,内容可信可靠,可以作为学术研究和科学决策的依据[2]。
2.1.1 CNKI 数据库
关键词选择“接地气”,文献类型去除“非工程科技Ⅰ类和非工程科技Ⅱ类”,从1984—2019 年,共获得3 700 条文献数据。每一条数据记录主要包括文献的作者、题目、摘要、关键字和引文等。
如图2 所示,2010 年前,年平均发表文献小于10 篇,2010 年之后整体呈现明显的上升趋势,在2014 年达到顶峰后又开始呈现明显的下降趋势,并且百度指数也在2014 年达到最高点。检索到的文章主题分布非常广泛,共15 个,其中“接地气”主题占比最大达到80.44%,超过一半,占比第二的是企业管理。进一步主题可大分为接地气、政治、管理。整体呈现,以接地气为主导,政治、管理为辅的局势。研究层次分布广泛,共18 个,主要在自然科学和社会科学。其中占比最大的是政策研究,达到33.36%,行业指导次之24.29%。占比前四均为社会科学研究,总占比达到81.68%,超过一半。
2.1.2 百度指数
已在概述中做出说明。
2.1.3 爬虫抓取数据
使用了八爪鱼采集器抓取以“接地气”为关键词的百度新闻标题,并对其进行词频分析,去掉动词、量词等,只用名词和形容词,最后统计得出:名词里词频TOP3 是网友、明星、句子;形容词里词频TOP3 是精辟、喜欢、简单。
在百度资讯中分别以“接地气”和词频Top5的形容词组合成接地气精辟、接地气喜欢、接地气简单、接地气真实、接地气高大为搜索词进行搜索,得到表1。
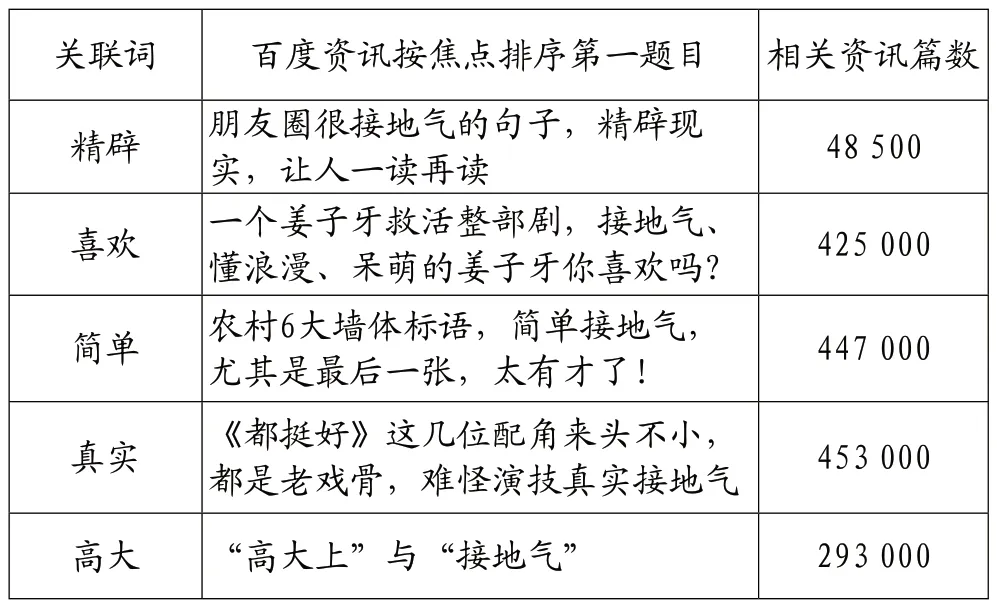
表1 2019年4月21日星期日
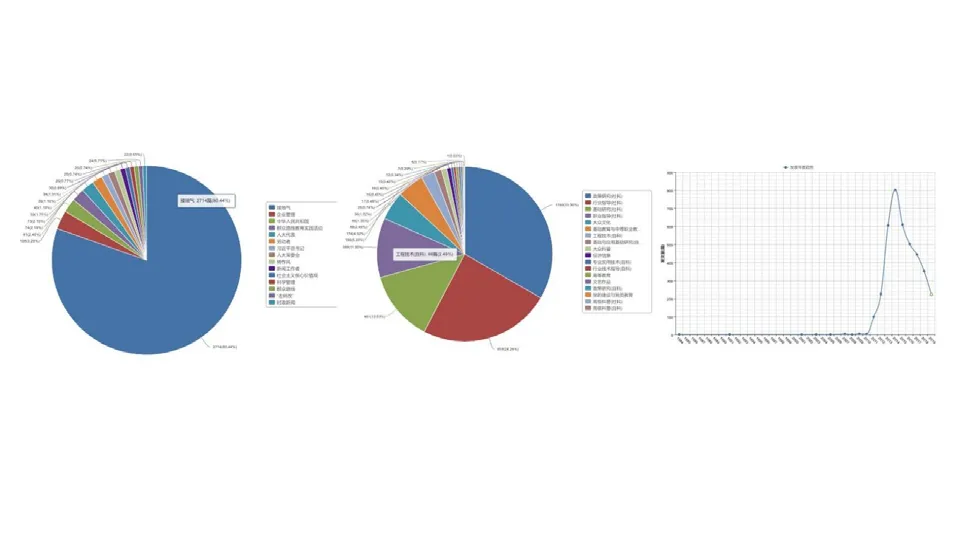
图2
结合以上数据分析发现,“接地气”的百度指数呈现明显震荡状态,其相关学术研究较少,且与新闻、媒体、传播等具有一定相关性。
2.2 研究方法
1)在CNKI 数据库中以关键词“接地气”为关键词高级检索,去除“非工程科技Ⅰ/Ⅱ类”,提取研究层次、领域等数据,绘制成图,分析其特征。利用八爪鱼采集器抓取以“接地气”为关键词的百度新闻标题,运用NLP 分析、易词云进行词频分析画图。提取形容词词频TOP5 数据,做进一步处理。结合“接地气”和形容词词频TOP5 的词汇作为关键词,在百度搜索引擎中搜索相关条目。为更深入研究,本文采用MF-DCCA 来分析“接地气”和“简单”的相关性。整个研究方法归结为一个模型,即基于互联网大数据的深度学习的研究。在接下来的工作中,融入已有情感词典和相关语料库,形成关于“接地气”的情感分析语料库,为新闻,媒体领域的研究做辅助性工作。
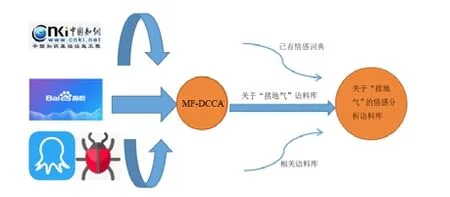
图3 互联网大数据深度学习模型
2)MF-DCCA。1967 年,Mandelbrot 首次提出了分形理论,用分数维度的视角和数学方法描述和研究客观事物。为了研究不同数据集的长期交叉相关性,Podobnik 和Stanley 提出了去趋势交叉相关性分析法(DCCA),在多个领域得到了广泛应用。为探究两个交叉相关的非平稳时间序列的多重分形特征,Zhou 结合DCCA 方法和MF-DFA 方法,提出了多重分形去趋势交叉相关性分析法(MF-DCCA),将DCCA 的二阶局部趋势推广到了q 阶,用于研究两个同时发生的具有自相关性的非平稳序列之间的相关性及其多重分形特征[3]。
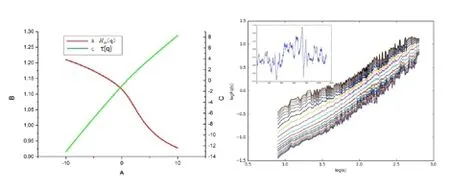
图4
(1)赫斯特指数Hxy(q)。根据图4 中呈现的曲线来看,赫斯特指数Hxy(q)随q 值的不同而不同,Hxy(q)均不为常数,这表明“接地气”和“简单”交叉相关性具有多重分形特征。图5 中可以看出,当q=2 时,Hxy(q)=1.066,接近于1,说明“接地气”和“简单”两列时间序列呈长程相关性。
(2)τ(q)图4 中表明τ(q) 不是 q 的线性函数,所以“接地气”和“简单”两列时间序列的交叉相关性呈多重分形。
(3)波动函数Fq(s)和时间间隔s。图4 中显示了“接地气”和“简单”之间的波动函数随着时间标度s 的变化而变化的双对数图。从图中可以看出,对于不同的q 值,在一段时期内曲线基本呈现出线性关系,具有较好的幂律关系,这也就意味着“接地气”和“简单”之间确实存在着交叉相关性。
(4)滑动窗口分析。图4 中小图为滑动窗口分析图。横坐标为时间,纵坐标为赫斯特指数。
滑动窗口常用于研究两列数据集相关性的时间变化特征,为了更全面地分析“接地气”和“简单”的交叉相关性,本文采用滑动窗口分析方法得到“接地气”和“简单”的交叉相关性的日度动态变化特征。滑动窗会随着窗口长度的变化而变化,滑动窗口过长,会导致丢失许多局部信息;而滑动窗口过短,会导致局部波动太剧烈而影响动态趋势的观察[4]。因此,正确选择滑动窗口的长度对于滑动窗口分析方法至关重要。为了正确捕获到全样本交叉相关性的动态特点,适应研究需要将滑动窗口分析的窗口期设定为500 天。从2012 年1 月1 日 到2018 年12 月31 日;设定q 值为2,去除时间序列的前500 天,计算交叉相关性指数Hxy(q);然后将样本向前滚动一天,重复上述步骤直至样本末端,得到交叉相关性指数序列图。
从图4 中可以看出,所有赫斯特指数Hxy(q)均在0.75-1.10 之间,说明“接地气”和“简单”两列时间序列一直都具有长程相关性且呈多重分形特征。
2.3 总结
通过多重分形去趋势交叉相关性分析法(MFDCCA)得出的结果发现“接地气”的百度指数和“简单”的百度指数这两列时间序列总是具有长程相关性,且呈多重分形特征。
3 研究结果与分析
1)互联网时代,人们对于事物的关注度往往体现在搜索量上。对于“接地气”的关注,自然也可以通过百度指数来反应。从“接地气”的百度指数可以看出,人们对于“接地气”一直有关注,且其走势呈明显的震荡趋势,所蕴含的信息丰富,研究价值很大。
2)将八爪鱼采集器爬取到的以“接地气”为关键词的百度新闻标题进行分词。通过简单的NLP 分析可以发现,“接地气”与“简单”“精辟”“真实”等具有一定的相关性。并且可以看到,“接地气”一般用来表示官员、政客、名人等的亲善大众,是一个本身带有情感色彩的词汇。
3)CNKI 文献数据表明关于“接地气”在党建,政策研究等领域都有相关研究,但在新闻、传媒研究甚少,且“接地气”又和新闻、媒体、传播等领域具有一定相关性,因此关于“接地气”在新闻、传媒等领域具有很大的研究价值和潜力。
4)通过多重分形去趋势交叉相关性分析法(MF-DCCA)和滑动窗口分析方法研究“接地气”百度指数和“简单”百度指数这两列时间序列,结果发现,“接地气”百度指数和“简单”百度指数具有总是具有长程相关性,且呈多重分形特征,这说明,研究“简单”对于研究“接地气”有一定的意义,对“接地气”的研究提供了方向。
5)对于“接地气”的数据分析和研究,可以进一步扩展到情感分析领域,建立一个“接地气”的情感分析语料库,从而辅助“接地气”对于新闻,传播,媒体等领域的研究。文章对于“接地气”的CNKI 文献数据、百度指数、爬虫爬取的新闻标题的研究,为建立“接地气”情感分析语料库做了一个基础性的工作。
