联合分层注意力网络和独立循环神经网络的地域欺凌识别
2019-10-23孟曌田生伟禹龙王瑞锦
孟曌 田生伟 禹龙 王瑞锦


摘 要:为提高对文本语境深层次信息的利用效率,提出了联合分层注意力网络(HAN)和独立循环神经网络(IndRNN)的地域欺凌文本识别模型——HACBI。首先,将手工标注的地域欺凌文本通过词嵌入技术映射到低维向量空间中;其次,借助卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM)提取地域欺凌文本的局部及全局语义特征,并进一步利用HAN捕获文本的内部结构信息;最后,为避免文本层次结构信息丢失和解决梯度消失等问题,引入IndRNN以增强模型的描述能力,并实现信息流的整合。实验结果表明,该模型的准确率(Acc)、精确率(P)、召回率(R)、F1和AUC值分别为99.57%、98.54%、99.02%、98.78%和99.35%,相比支持向量机(SVM)、CNN等文本分类模型有显著提升。
关键词:地域欺凌;结构信息;分层注意力网络;独立循环神经网络;词向量;语境
中图分类号: TP391; TP181
文献标志码:A
Regional bullying recognition based on joint hierarchical attentional network and independent recurrent neural network
MENG Zhao1, TIAN Shengwei1*, YU Long2, WANG Ruijin3
1.School of Software, Xinjiang University, Urumqi Xinjiang 830008, China;
2.Network Center, Xinjiang University, Urumqi Xinjiang 830046, China;
3.School of Information and Software Engineering, University of Electronic Science and Technology of China, Chengdu Sichuan 611731, China
Abstract: In order to improve the utilization efficiency of deep information in text context, based on Hierarchical Attention Network (HAN) and Independent Recurrent Neural Network (IndRNN), a regional bullying semantic recognition model called HACBI (HAN_CNN_BiLSTM_IndRNN) was proposed. Firstly, the manually annotated regional bullying texts were mapped into a low-dimensional vector space by means of word embedding technology. Secondly, the local and global semantic information of bullying texts was extracted by using Convolutional Neural Network (CNN) and Bidirectional Long Short-Term Memory (BiLSTM), and internal structure information of text was captured by HAN. Finally, in order to avoid the loss of text hierarchy information and solve the gradient disappearance problem, IndRNN was introduced to enhance the description ability of model, which achieved the integration of information flow. Experimental results show that the Accuracy (Acc), Precision (P), Recall (R), F1 (F1-Measure) and AUC (Area Under Curve) values are 99.57%, 98.54%, 99.02%, 98.78% and 99.35% respectively of this model, which indicates that the effectiveness provided by HACBI is significantly improved compared to text classification models such as Support Vector Machine (SVM) and CNN.
Key words: regional bullying; structural information; Hierarchical Attention Network (HAN); Independent Recurrent Neural Network (IndRNN); word vector; context
0 引言
近年來,随着互联网的不断发展和社交媒体的普遍应用,人们在网络中对各类事物的参与程度前所未有。移动通信终端的普及进一步使人们的工作和生活融入到网络中,QQ、微信等即时通信软件,Wiki、Facebook、微博、贴吧等各类社交网站为世界范围内的网民提供了相互交流的平台,公众广泛参与到社会事件、政治活动、产品服务等方面的评论中。然而由于缺乏监管和网络天然的匿名特点,社交媒体带给人们自由、便利和迅捷的同时,也带来很多负面影响,由此产生了海量欺凌信息。在日常生活中,常出现针对特定地域或特定地域人群的欺凌性言论,而这些地域欺凌性言论发布和传播不仅严重地损害了被欺凌地域的形象,影响该地域的发展,破坏社会和谐,还给受害人或群体带来心理和情感上的严重伤害。目前国内地域欺凌语料库较少,并不能满足研究需求,因此构建地域欺凌语料库是该研究的一项重要基础任务。深度学习技术在自然语言处理、计算机视觉和机器翻译等领域大放异彩,为地域欺凌文本的识别提供了一种全新的思路,因此,如何利用现有的特征工程和深度学习神经网络来识别地域欺凌文本已成为一个重要的研究课题。
1 相关研究
欺凌言论的分析方法一般可以分为:基于浅层特征的方法、基于词向量(word embedding)[1]的神经网络方法、情感分析方法以及基于对网络欺凌相关人员分析的方法等。为了检测欺凌文本中攻击性内容和识别社交媒体中潜在的攻击性用户,Chen等[2]提出词汇和句法特征的检测架构,但词句分析需要人工参与设定各种规则,通用性有待商榷。Ashktorab等[3]从社交网站Ask.fm收集网络欺凌文本,将其作为一种特殊的网络优化形式,以提高检测的自动化程度,并从欺凌的程度、文本中出现的角色和欺凌的类别等方面对其进行细粒度分类。为捕捉不同文本环境中欺凌相关术语、上下文信息与Twitter上欺凌内容分类的关联性,Burnap等[4]提出了基于规则的方法。为了进一步根据欺凌术语的相关强度以及对文本中角色的引用进行加权,Zhou等[5]通过把亵渎、猥亵和贬义的词作为特征来确定欺凌内容,建立机器学习模型来减小假阴率(False Negative, FN)。Dadvar等[6]使用第一和第二人称代词对YouTube上的欺凌行为进行分类,得到了良好的分类效果。针对词袋模型(Bag of Words, BoW)[7]技术的局限性,Collier等[8]利用词汇泛化方法将词典以外的URL(Uniform Resource Locator)、标点符号和标记符号等作为附加特征,能进一步提高预测性能。为了进一步克服词袋模型表现出的局限性,Djuric等[9]提出了基于词向量的神经网络方法,并使用词向量模型来探索段落向量与段落内部信息之间的关系,与直接使用单词向量法相比,识别效果更好。因网络欺凌和情感分析中的负面情感具有一定的相似性,从而可将情感分析作为网络欺凌分析的辅助方法。Wijeratne等[10]通过基于情感的分析算法设计了通用监测平台,但未考虑特定的社会媒体语言环境及其文化。Gitari等[11]使用分类器将不带情感的文本略过,缩小研究范围,提高欺凌文本的识别准确率。Mishra等[12]等通过对185名青少年网民进行问卷调查,将网民之间的交流阶段分成建立联系、信息分享、亲密关系生成和欺凌的四个阶段,基于网络欺凌、信任和信息共享的关系模型探求发生欺凌原因,并对欺凌程度作了定量分析。
上述研究在分类准确度上有一定的效果,但是忽略了文本中深层语义特征和上下文语境,且大多是基于浅层机器学习[13],对文本分类问题的表征和泛化能力有限。本文利用分层注意力网络(Hierarchical Attention Network, HAN)[14]从单词和句子两個层面来捕获地域欺凌文本的内部结构语义信息,并与卷积神经网络(Convolutional Neural Network, CNN)[15]、双向长短期记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)和独立循环神经网络(Independent Recurrent Neural Network, IndRNN)[16]联合提取文本中欺凌词句和整体语义信息,以提高对地域欺凌文本的描述和识别能力。
综上所述,本文的主要贡献包括:
1)构建地域欺凌语料库。通过对地域欺凌文本的上下文语境分析,将地域欺凌语料库编制分为5个语境类别,各类语境共包含37个子类别。
2)本文提出联合分层注意力网络和独立循环神经网络的模型——HACBI(HAN_CNN_BiLSTM_IndRNN),采用HAN呈现出地域欺凌文本中关键单词和句子的内部结构信息,用其捕获上下文的相关性;借助IndRNN通过调节基于时间的梯度反向传播,有效地解决梯度消失和梯度爆炸的问题,提高对地域欺凌文本的上下文语义信息描述能力。
2 语料构建
2.1 语境
在语言学中,王建华等[17]认为语境是与语用主体(关注使用语言的人)、话语实体(关注语言手段本身)相对而存在的语用三大要素之一,并定义语境为人们在语言交际中理解和运用语言所依赖的各种表现为言辞的上下文或不表现为言辞的主观因素,因此,文本中要研究完整的文本语义,不仅要研究话语的本身意义,还要研究增生出的语境意义。
本文主要对地域欺凌文本的整体语境进行研究,特别是上下文语境信息。上下文语境由具体的话语组成,它的意义首先必须依赖于一个个具体话语的意义,每个话语的意义又需要由具体的上下文来显现。
2.2 语料库构建
构建地域欺凌语料库,包括语料的获取、标注体系及规范的建立、资源建设平台的构建。构建的语料来源于微博、知乎、百度贴吧、今日头条等中文网页,为地域欺凌文本的识别提供基础资源支撑。地域欺凌语料库编制分为语言情境、情境语境、文化语境、背景语境和辅助语境5个语境类别。语言情境包括单词语境和上下文语境,如例1所示。
例1 小柳较胖,看起来腿较粗,被同学小丽和小冰谈论:“你看小柳的大象腿。”小冰说:“对啊,腿可真粗啊。”
情境语境包括外部关系和内部关系两个类别。文化语境包括社会因素、民族因素、历史因素。如例2所示,“东方人”在美国有欺凌的含义,2016年奥巴马政府出台禁止“东方人”等含有欺凌情感的词语,判断得出“白人老板”称“亚裔员工”为“东方人”是一种地域欺凌。
例2 在美国一家工厂里,一位白人老板对一位近期工作效率低下的亚裔员工说:“你的表现足以表明你是东方人。”
背景语境包括背景知识、社会常识和专业知识。辅助语境即言语表达者的表情、姿态、动作及某些信号等。
语料标注结构如表1所示。
2.3 欺凌特征
根据地域欺凌文本的内容,本文选取了10类特征作为地域欺凌文本特征,包括欺凌程度、情感极性、欺凌指示词词性、欺凌类别、依存句法分析、语义依存分析和语义角色七类传统手工特征和欺凌角色、欺凌指示词、欺凌表现形式三类特征。三类特征具体描述如下:
1)欺凌角色。Xu等[18]指出,除面对面接触外,地域欺凌也可以通过口头和其他相关形式发生。欺凌事件发生的主要原因之一是认知上的差异。欺凌事件角色如图1所示。
其中,实心圆圈代表社会科学中的传统角色,虚线圆圈代表社交媒体增加的新角色。边代表角色之间的相互作用强度,实线的作用强度大于虚线。
2)欺凌指示词。欺凌指示词能反映该地域欺凌文本的主题,具有很强的欺凌指向性,因此本文选择欺凌指示词作为特征。如例3所示,“粗鄙”“乡巴佬”等为欺凌指示词。
例3 卡帕多西亚人可能族源是安纳托利亚的土著,在拜占庭生活的卡帕多西亚人行为粗犷,拜占庭人谈论:“卡帕多西亚人是粗鄙的乡巴佬,贪婪且暴力。”
3)欺凌表现形式。针对地域欺凌文本,其表现形式有三种,包括反语、隐喻和显式欺凌。
3 联合分层注意力网络和独立循环神经网络的 HACBI模型
3.1 文本的层次结构信息
文本具有层次结构,即词语形成句子,句子形成文本。首先,以句子的形式聚合成地域欺凌文本的表示形式;其次,考虑到文本中不同的单词和句子包含着不同的信息,而且单词和句子的结构信息高度依赖于上下文,起着不同的作用,因此为了进一步刻画地域欺凌文本的结构信息,本文引入HAN从单词和句子两个层面来捕获地域欺凌文本的内部结构语义信息。
本文利用HAN呈现地域欺凌文本中关键单词和句子内部结构信息,并用其捕获上下文之的相关性,而不是通过上下文信息对地域欺凌文本的序列进行简单的过滤以获取全局语义信息。
3.2 HACBI模型
为使模型更好地描述地域欺凌文本的内部结构信息,将通过词嵌入技术(Word2Vec)和手工标注所得到的地域欺凌文本输入HAN中。词嵌入是一种词的分布式表示,将每个词表示成一个连续实数值的向量。词嵌入技术分为两部分:第一部分为建立模型,第二部分是通过网络获取词向量。当网络对地域欺凌文本训练完成后,便可得到所有词语对应的词向量,并可以从地域欺凌文本中提取有效的上下文语义特征。在HACBI中,首先,通过CNN和BiLSTM对其进行空间和时间上的扩展,并提取地域欺凌文本的局部、全局特征;其次,考虑到文本中欺凌词组对句子的表示有着关键性作用,本文利用词“注意力”提取地域欺凌词在句子中的语义信息,并计算该单词在句子中的权重,然后对其语义特征进行加权合并,还引入句“注意力”来刻画句子对文本的表示形式,对其提取的語义信息进行加权求和以及非线性映射和归一化处理;最后,借助IndRNN的跨层连接原理(网络内部各个神经元之间相互独立)实现信息流的整合,以增强该HACBI对地域欺凌文本中上下文语义信息的描述能力和对语义信息在神经元上传递的可解释性,避免了层次结构语义特征在层间传递的丢失并解决梯度消失等问题,并用Softmax进行地域欺凌文本的分类。联合分层注意力网络和独立循环神经网络的模型HACBI网络结构如图2所示。
图2中, H 代表模型的隐含层,且由CNN和BiLSTM构成; w 和 s 分别代表着地域欺凌文本中的词组和简短句子。
独立循环神经网络(IndRNN)中Hadamard信息流处理,具体计算如式(1)所示:
h t=σ( ω x t+ λh t-1+ b ) (1)
其中: h t∈ R N和 x t∈ R M分别代表时间步长T的输入和隐藏状态; ω ∈ R N*M、 λ ∈ R N*N和 b ∈ R N分别代表当前输入的权重矩阵、循环权重矩阵和偏置值;σ是神经元的激活函数;N是该神经网络层中神经元的数目,是Hadamard乘积。
而对于第n个神经元,隐藏状态 h n,t可以通过式(2)计算得出:
h n,t=σ( ω n x t+ λ n h n,t-1+bn) (2)
其中, ω n和 λ n分别代表输入权重矩阵和循环权重矩阵的第n行。由于每层中各个神经元相互独立,因此神经元之间的链接可以通过堆叠两层或更多层的IndRNN神经元来实现。每个神经元仅在前一时间步从输入或它自己的隐藏状态中接收信息,即随着时间的推移(通过 λ )独立地聚集空间模式(通过 ω )。
综上所述,联合分层注意力网络和独立循环神经网络模型HACBI的具体算法步骤如下:
1)利用词嵌入技术和词性标注工具提取欺凌文本中的语义和特征提取,并映射成相应的低维向量。初始化模型参数θ。对词向量 α 进行Dropout处理,经过CNN层BiLSTM层进一步提取文本的局部特征 β 和全局以及上下文语义特征 υ 。根据式(3)计算其关键特征的注意力概率 a ij,具体公式如下:
e ij= λ a·tanh( λ b· f i+ λ c· f j+ b k)
a ij=exp( e ij) /( ∑ T k=1 exp( e ij) ) (3)
其中: e ij代表经过分层注意力网络的输出特征, f i和 f j代表隐藏层输出特征, a ij代表第j个特征对第i个特征的注意力概率, λ a、 λ b、 λ c代表分层注意力网络的权值矩阵, b k代表分层注意力网络的偏置向量。第i种特征向量的新输出特征 e new_i计算如式(4)所示:
e new_i=∑ n j=1 e ij· e j (4)
同理,可求取第j个特征向量的新特征值。
2)根据式(5)将局部和全局语义特征进行融合:
e ′= βυ (5)
其中: e ′代表经过注意力获取语义特征的编码向量,代表向量拼接。
3)得出分类结果g,即g=1为地域欺凌文本,g=0为非地域欺凌文本。
3.3 HACBI性能分析
为了评估该模型在计算平台上的理论性能,对HACBI的性能进行分析。HACBI性能分析如表2所示。
其中:CPU、GPU内存占用表示的是运行程序时所占用的计算机内存的字节数;CPU、GPU内存占用比表示运行程序时占用计算机内存的百分比;模型耗时代表模型运行150次迭代时所耗时间。
从表2中可以看出,本文所提模型算法在训练过程中,每次迭代仅耗费约20s,因此,当有新的训练数据需要进行训练时,较少的训练时间能够满足模型快速训练的要求,并且对CPU和GPU的占用较少,可满足对地域欺凌文本的快速分类识别的要求。
4 实验结果与分析
4.1 实验数据
首先,通过网络爬虫技术下载中文网页中的地域欺凌文本;其次,对其进行去重、去噪等一系列处理;最后,筛选出11833篇包含地域欺凌的新闻报道或网友评论作为实验文本,其中地域欺凌文本正负例比例为1∶ 5。在对实验文本数据进行预处理时,采用jieba分词法,即一种词典分词法,将句子拆成字,然后字和字组合进入词典中匹配。
4.2 实验结果
本文从以下几方面对实验的准确率(Accuracy, Acc)、精确率(Precision, P)、召回率(Recall, R)、F1(F1-Measure)和AUC(Area Under Curve)值进行分析。
4.2.1 实验超参数设置
HACBI参数不合理设置会影响对特征的有效利用及对地域欺凌文本中语义信息的描述。超参数设置如表3所示。
本文使用简单高效、对参数更新时不受梯度伸缩变化影响的Adam优化器。其中,Dropout表示Dropout损失率为0.25;Filter size(C)表示卷积核窗口大小为5,Kernel size(P)表示池化核窗口大小为2。
4.2.2 CNN层数、BiLSTM层数和IndRNN层数 不同层类型及层数对模型性能的影响
HACBI模型中隐含层数直接影响模型对地域欺凌文本中的语义识别能力。以4.2.1节中的初始化参数为基础验证HACBI性能,其中词向量维度设置为150维。不同CNN层数、BiLSTM层数和IndRNN层数对模型性能的影响如表4所示。
由表4可知,在CNN为2层、BiLSTM为1层和IndRNN层数为2层时,Acc、P、R、F1和AUC值效果最好。随着BiLSTM层数增加,模型加入了大量与文本无关的噪声和参数,计算效率降低,并出现过拟合现象。随着CNN层数和IndRNN层数的增加,各项指标呈现先增后减的趋势。当层数太少时,不能学习到更好的特征,特征的表征能力不足;当层数过多时,提取的深层特征更抽象,在丢失大量细节信息的同时也使特征的表征能力下降,模型在特征学习时出现了可能会出现过拟合现象,降低模型对文本的识别效果。
4.2.3 词向量维度和语料数量对模型性能的影响
词向量维度和语料数量对模型性能的影响如表5所示。
由表5可知,当词向量维度为150维和语料数据量为11833篇时,各项指标呈现出最优结果。当词向量维度太小时,原始数据映射到低维空间中会丢失大量的细节信息,特征不能很好地描述文本的语义信息。词向量维度过大时,词向量过于稀疏,增加很多非相关信息。随着训练数据量增多时,模型能更多地学习到文本中欺凌词和欺凌语句的上下文信息,从而使模型具有更好泛化能力和识别能力。
4.2.4 面向欺凌特征对象的比较
在现有文献对面向“欺凌”特征对象的研究中,本文除提取七类传统手工(Traditional Manual, TM)特征外,还提取欺凌角色“A”、欺凌指示词“B”和欺凌表现形式“C”,TM与A、B、C的组合“M(Manual)”即本文手工特征,并结合词向量“W(Word2Vec)”对地域欺凌文本内容进行描述,“W+M(Word2Vec+Manual)”是本文提出的特征工程。词向量维度设置为150维,不同欺凌特征对模型性能的影响如表6所示。
由表6可知,本文提出的手工特征与词向量结合的特征工程,各项指标最优。单用手工特征对文本的描述简单,不能很好地学习文本深层特征,而且需要人工参与进行标注,文本处理效率降低。单独用词向量特征不能很好地体现文本的细节内容。
4.2.5 与现有识别模型的比较
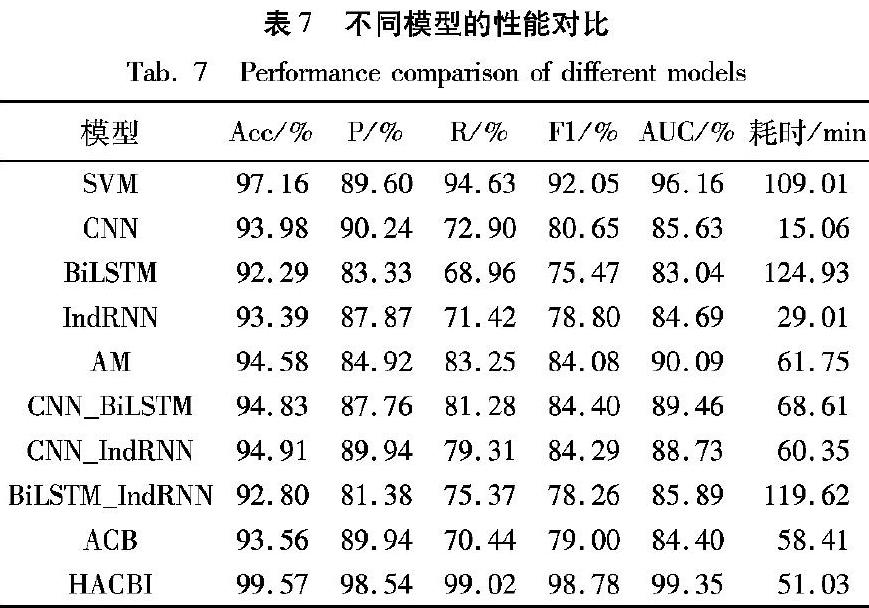
为了进一步验证HACBI对地域欺凌文本有更好的识别效果,将与支持向量机(Support Vector Machine, SVM)、CNN、BiLSTM、IndRNN、注意力机制(Attention Mechanism, AM)、CNN和BiLSTM的联合模型(CNN_BiLSTM)、CNN和IndRNN的聯合模型(CNN_IndRNN)、BiLSTM和IndRNN的联合模型(BiLSTM_IndRNN)及AM、CNN和BiLSTM的联合模型(AM_CNN_BiLSTM, ACB)进行对比,并分析执行耗时。对不同模型中层数及超参数的设置保持一致。不同模型对比如表7所示。
表7中SVM使用径向基函数(Radial Basis Function, RBF),当gamma和惩罚系数C分别为1E-4和10时,其识别效果达到最优。
由表7可知,HACBI相比实验中其他模型在Acc、P、R、F1和AUC值均取得最优。AM对文本的语义信息进行提取,起到信息流整合的作用,但未对句子中的关键词进行特征加权求和,模型对文本的描述能力和对各个神经元的可解释性不足。CNN能提取局部特征,但丢失了全局语义信息。BiLSTM可提取全局语义特征,但忽略了大量局部信息,影响模型对文本内容的描述。尽管SVM浅层机器学习在各项指标上均优于本节实验的其他模型,但仅仅对地域欺凌文本进行简单分类,并未捕获文本内部的结构信息,与HACBI相比,各项指标分别降低了2.41个百分点、8.94个百分点、4.39个百分点、6.73个百分点和3.19个百分点。
在模型參数相同的条件下,与BiLSTM相比,CNN耗时减少了87.95%,IndRNN耗时减少了76.78%。BiLSTM在计算文本的双向特征时,将每个词作为了时间点,而CNN在参数微调(finetune)过程时只会对文本中的部分关键词进行更新。SVM对数据规模较小的文本进行分类效果好且耗时短。HACBI使用分层思想,在对文本特征学习时采用自根节点向下逐层获取上下文语义信息的方法,与SVM相比,HACBI耗时减少了53.19%,在缩短耗时的同时提高了对文本的识别效果。
5 结语
针对现有的文本分类模型在识别地域欺凌文本时存在忽略文本内部层次结构信息以及模型在训练过程中出现的梯度消失等问题,本文提出HACBI地域欺凌文本识别模型。实验结果表明,该算法优于SVM、CNN等文本分类模型。其创新点在于HACBI模型采用词“注意力”和句“注意力”的HAN来捕获地域欺凌文本的内部结构信息,以增强文本中上下文之间的语义相关性,并引入IndRNN有效地避免信息在层间传递的丢失和解决梯度消失等问题。接下来在增加语料的同时也会从细粒度分类方面进行下一步实验。
参考文献
[1] HU K, WU H, QI K, et al. A domain keyword analysis approach extending term frequency-keyword active index with Google Word2Vec model [J]. Scientometrics, 2018, 114(3): 1031-1068.
[2] CHEN M, LIU W, YANG Z, et al. Automatic prosodic events detection using a two-stage SVM/CRF sequence classifier with acoustic features [C]// Proceedings of the 2012 Chinese Conference on Pattern Recognition, CCIS 321. Berlin: Springer, 2012: 572-578.
[3] ASHKTORAB Z, HABER E, GOLBECK J, et al. Beyond cyberbullying: self-disclosure, harm and social support on ASKfm [C]//Proceedings of the 2017 ACM on Web Science Conference. New York: ACM, 2017: 3-12.
[4] BURNAP P, COLOMBO G, AMERY R, et al. Multi-class machine classification of suicide-related communication on Twitter [J]. Online Social Networks and Media, 2017, 2: 32-44.
[5] ZHOU Y T, DU Z G, ZHANG D, et al. Retrospective observational study about reducing the false negative rate of the sentinel lymph node biopsy: never underestimate the effect of subjective factors [J]. Medicine, 2017, 96(34): e7787.
[6] DADVAR M, TRIESCHNINGG D, de JONG F. Experts and machines against bullies: a hybrid approach to detect cyberbullies [C]// Proceedings of the 27th Canadian Conference on Artificial Intelligence, LNCS 8436. Cham: Springer, 2014: 275-281.
[7] FIRUZI K, VAKILIAN M, DARABAD V P, et al. A novel method for differentiating and clustering multiple partial discharge sources using S transform and bag of words feature[J]. IEEE Transactions on Dielectrics and Electrical Insulation, 2018, 24(6):3694-3702.
[8] COLLIER N, NOBATA C, TSUJII J. Automatic acquisition and classification of terminology using a tagged corpus in the molecular biology domain[J]. Terminology, 2001, 7(2): 239-257.
[9] DJURIC N, ZHOU J, MORRIS R, et al. Hate speech detection with comment embeddings[C]// Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015: 29-30.
[10] WIJERATNE S, DORAN D, SHETH A, et al. Analyzing the social media footprint of street gangs[C]// ISI 2015: Proceedings of the 2015 IEEE International Conference on Intelligence and Security Informatics. Piscataway, NJ: IEEE, 2015: 91-96.
[11] GITARI N D, ZUPING Z, DAMIEN H, et al. A lexicon-based approach for hate speech detection[J]. International Journal of Multimedia and Ubiquitous Engineering, 2015, 10(4): 215-230.
[12] MISHRA M K, KUMAR S, VAISH A, et al. Quantifying degree of cyber bullying using level of information shared and associated trust[C]// INDICON 2015: Proceedings of the 2015 Annual IEEE India Conference. Piscataway, NJ: IEEE, 2015: 1-6.
[13] OGUZLAR A. With R programming, comparison of performance of different machine learning algorithms[J]. European Journal of Multidisciplinary Studies, 2018, 3(2): 172-172.
[14] YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1480-1489.
[15] 李洋,董红斌.基于CNN和BiLSTM网络特征融合的文本情感分析[J].计算机应用,2018,38(11):3075-3080. (LI Y, DONG H B. Text sentiment analysis based on feature fusion of convolution neural network and bidirectional long short-term memory network [J]. Journal of Computer Applications, 2018, 38(11): 3075-3080.)
[16] LI S, LI W, COOK C, et al. Independently recurrent neural network (IndRNN): building a longer and deeper RNN[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 5457-5466.
[17] 王建華,周明强,盛爱萍.现代汉语语境研究[M].杭州:浙江大学出版社,2002:59. (WANG J H, ZHOU M Q, SHENG A P. On the Context of Modern Chinese[M]. Hangzhou: Zhejiang University Press, 2002: 59.)
[18] XU J M, JUN K S, ZHU X, et al. Learning from bullying traces in social media[C]// Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2012: 656-666.
