多噪声环境下双微阵列语音增强算法
2019-10-23罗瀛曾庆宁龙超
罗瀛 曾庆宁 龙超
摘 要:为提高双微阵列语音增强系统在多噪声环境下的消噪性能,提出一种适用于双微阵列的改进广义旁瓣抵消器语音增强算法。根据双微麦克风阵列的结构特点,首先,用基于噪声互功率谱估计的改进相干滤波算法消除距离较远麦克风之间产生的弱相关噪声;然后,利用广义旁瓣抵消算法消除距离较近麦克风之间产生的强相关噪声;最后,通过基于最小值控制递归平均的子带谱减法有针对性地消除不同频带上的残留噪声。仿真实验表明,在多噪声环境下所提算法较现有的双微阵列语音增强算法取得了更好的感知语音质量评价得分,一定程度上改善了双微阵列语音增强系统对复杂噪声的抑制效果。
关键词:双微阵列;噪声互功率谱估计;广义旁瓣抵消器;最小值控制递归平均;子带谱减
中图分类号: TN912.35
文献标志码:A
Dual mini micro-array speech enhancement algorithm under multi-noise environment
LUO Ying, ZENG Qingning*, LONG Chao
Ministry of Education Key Laboratory of Cognitive Radio and Information Processing (Guilin University of Electronic Technology), Guilin Guangxi 541004, China
Abstract: In order to improve the denoising performance of dual mini micro-array speech enhancement system in multi-noise environment, an improved generalized sidelobe canceller speech enhancement algorithm for dual mini micro-array was proposed. According to the structure characteristics of the dual mini micro-array, firstly, an improved coherent filtering algorithm based on noise cross-power spectrum estimation was used to eliminate the weak correlation noise between microphones with long distances. Secondly, the strong correlation noise between microphones with short distances was eliminated by using a generalized sidelobe cancelling algorithm. Finally, the minima-controlled recursive averaging based sub-band spectrum subtraction was used to eliminate the residual noise in different spectrum bands purposefully. Experimental results show that the proposed algorithm achieves better score in perceptual evaluation of speech quality than existing dual mini micro-array speech enhancement algorithms under multi-noise environment, and improves the suppression effect of dual mini micro-array speech enhancement system on complex noise to a certain extent.
Key words: dual mini micro-array; noise cross-power spectrum estimation; generalized sidelobe canceller; minima-controlled recursive averaging; multi-band spectral subtraction
0 引言
在實际环境中,目标语音存在于多种噪声混合的噪声环境中,多噪声环境严重影响目标语音的获取。在实际应用中,谱减[1]、维纳滤波[2]、最小均方误差估计[3]等传统的单通道语音增强方法会受到各种不同场景的限制,同时还会造成一定程度的语音失真。基于麦克风阵列[4]的语音增强方法能同时利用时域和空域信息来有效消除噪声,这使得其应用场合更为广泛,在应用于助听器及移动通信设备时都具有较好的效果。
广义旁瓣抵消器(Generalized Sidelobe Canceller, GSC)[4]是一种能较好抑制相关噪声的麦克风阵列语音增强算法,但由于GSC算法在消除弱相关噪声时的效果依赖于阵列的阵元数量及阵元间距,因此应用于小型及微型麦克风阵列时不能有效地消除较近阵元间的弱相关噪声。相干滤波(Coherence Filtering, CF)算法[5]在抑制弱相关噪声时具有良好的效果。文献[6]提出了一种基于相干滤波与GSC相结合的小麦克风阵列语音增强方法,对多噪声环境下的噪声消除有一定的效果。文献[7]提出了一种基于双微阵列的语音增强算法。双微阵列的结构如图1所示,麦克风M1和M2、M3和M4分别构成双微阵列中的两个子阵,两个子阵的间距为16cm,子阵中的两个麦克风间距为2cm。文献[7]中先用谱修正滤波器对双微阵列子阵中的两个距离为2cm的麦克风接收的信号进行增强,生成4路增强信号作为GSC的输入,通过GSC进一步消除相干噪声后再用调制域谱减法消除残留噪声。通过在white噪声、f16噪声等单一噪声环境的仿真实验验证了该算法具有较好的消噪性能。但在双微阵列中,两个距离较近麦克风中的噪声呈现强相关性,而距离较远麦克风中的噪声呈现弱相关性[8-9],文献[7]所提出的算法选择子阵中距离较近的两个麦克风进行谱修正滤波,不能较好地解决距离较远麦克风产生的弱相关性噪声消除问题。同时,在多噪声混合的环境下,通过GSC增强后的信号的残留噪声在不同频带上的分布并不均匀,调制域谱减法不能针对性地对各频带上的残留噪声进行消除。
本文根据双微阵列中麦克风的排列特点,提出一种适用于多噪声环境下的双微麦克风阵列语音增强算法。首先分别对距离较远的四组麦克风M1和M3、M4,M2和M3、M4采用基于噪声互功率谱估计的改进相干滤波算法消除弱相关噪声,然后将4路增强信号作为输入,通过GSC算法消除强相关噪声,最后采用基于最小值控制递归平均的子带谱减法对不同频带上的残留噪声进行有针对性的消除。
1 本文算法框架
图2是本文算法的原理框图,y1、y2、y3、y4分别代表麦克风M1、M2、M3、M4所采集到的信号。用y1和y3、y4,y2和y3、y4分别进行改进互功率谱估计的相干滤波,得到GSC的四路输入信号yout_13、yout_14、yout_23、yout_24。
经过GSC增强后的信号YGSC_out再采用最小值控制递归平均(Minima Controlled Recursive Averaging, MCRA)子带谱减抑制残留噪声后得到最终的输出Ymcra_out。
2 改进互功率估计的相干滤波
Jeannès等[10]提出利用带噪语音互功率谱减去噪声估计互功率谱的方法以改进相干滤波器,因此噪声互功率谱估计的准确性决定了改进相干滤波器的消噪性能。本文在最小跟踪噪声功率谱估计算法[11]的基础上,对最小跟踪算法进行改进并用以估计含噪语音的噪声互功率谱。其基本原理如图3所示。
首先对分别来自不同子阵的两路麦克风采集到的信号yi和yj进行分帧和傅里叶变换,接着通过基于互功率谱谱减的相干滤波函数式(1)对带噪语音进行增强。
H(k,l)= | PYiYj(k,l) | - | PNiNj(k,l) | PYiYi(k,l)PYjYj(k,l)
(1)
其中:PYiYi(k,l)表示通道i带噪语音信号的自功率谱密度;PYjYj(k,l)表示通道j带噪语音信号的自功率谱密度;PYiYj(k,l)表示通道i和通道j带噪语音信号之间的互功率谱密度;PNiNj(k,l)表示通过改进最小跟踪算法估计得到的噪声互功率谱密度。
为计算噪声互功率谱密度估计,首先需要对带噪语音信号互功率谱PYiYj(k,l)进行平滑:
PYiYj(k,l)= 0.7×PYiYj(k,l-1)+0.3×Yi(k,l)Y*j(k,l)
(2)
接着引入平滑因子λ(k,l)对噪声互功率谱密度进行估计:
P ^ NiNj(k,l)= λ(k,l)PNiNj(k,l-1)+(1-λ(k,l))Yi(k,l)Y*j(k,l)
(3)
本文提出一種基于先验信噪比SNR(k,l)的平滑策略,通过各个频带k上的信噪比来更新平滑因子λ(k,l)以便及时地跟踪噪声互功率谱。平滑因子的计算方式为:
λ(k,l)=0.96-0.3 G(k,l) 1+G(k,l)
(4)
其中G(k,l)表示信噪比参数,通过带噪语音信号的先验信噪比得到:
G(k,l)=exp(min(0.66×SNR(k,l)-1,200))
(6)
带噪语音信号的先验信噪比由当前帧互功率谱密度估计 | PYiYj(k,l) | 与前一帧的噪声互功率谱密度估计 | PNiNj(k,l-1) | 的比值求得:
SNR(k,l)= | PYiYj(k,l) | / | PNiNj(k,l-1) |
(7)
计算出噪声互功率谱密度初值P ^ NiNj(k,l)后再利用一个长度为D帧的窗口搜索该窗长内的局部最小噪声互功率谱Pmin(k,l):
Pmin(k,l)= (P ^ NiNj(k,l),P ^ NiNj(k,l-1),…,P ^ NiNj(k,l-D+1))
(8)
由于Pmin(k,l)总小于噪声平均值,因此需要利用无偏因子Bmin(k,l)对Pmin(k,l)进行补偿。Bmin(k,l)与搜索窗长D有关。本文算法中D的取值为150。噪声互功率谱估计PNiNj(k,l)最终通过式(9)计算得到。
PNiNj(k,l)=Pmin(k,l)Bmin(k,l)
(9)
最后经过改进互功率估计的相干滤波后,输出一路增强信号yout_ij。
3 广义旁瓣抵消器
广义旁瓣抵消器基于线性约束最小方差(Linearly Constrained Minimum Variance, LCMV)条件提出,其结构由上通道模块的约束部分与下通道模块的阻塞矩阵组成。图4是GSC的简易原理图。上通道主要作为参考信号,利用固定波束形成器对改进噪声互功率谱估计的相干滤波结果 Y OUT(n)=[yout_13,yout_14,yout_23,yout_24]进行初步增强得到增强信号Yd(n):
Y d(n)= Y OUT(n) W T
(10)
其中 W T=[w1,w2,w3,w4]为固定波束形成器的权值向量。
参考噪声 D (n)由下通道的阻塞矩阵 B 与噪声互功率谱估计的相干滤波结果获得:
D (n)= Y OUT(n)· B
(11)
其中 B 是满足约束条件 B · 1 = 0 的3×4维矩阵。使用归一化最小均方算法迭代得到噪声估计值 D c(n),同时利用语音活动检测(Voice Activity Detector, VAD)技术在非语音段更新滤波器系数:
D c(n)= D (n)· C
(12)
其中 C 是由自适应算法得到的归一化最小均方权值系数。最后GSC的输出为:
Y GSC_out(n)= Y d(n)- D c(n)
(13)
4 MCRA子带谱减
MCRA算法[12]在平稳及非平稳噪声环境中都能有较好的鲁棒性,并且在噪声急剧变化时能快速跟踪噪声。其噪声功率谱估计由式(14)可得:
λ ^ d(k,l)= d(k,l)λ ^ d(k,l-1)+[1- d(k,l)] | Y(k,l) | 2
(14)
其中:λ ^ d(k,l)表示在第l帧语音,第k个频点处噪声的功率谱估计; | Y(k,l) | 2表示在此处带噪语音信号的功率谱。平滑参数 d(k,l)由式(15)计算得到。
d(k,l)=αd+(1-αd) (k,l)
(15)
其中:αd是固定常数,本文中αd的取值为0.95; (k,l)为语音存概率,
通过式(16)进行递归平滑得到,其中平滑参数为αp=0.2。
(k,l)=αp (k,l-1)+(1-αp)p(k,l)
(16)
p(k,l)表示语音是否存在:
p(k,l)= 1, Sr(k,l)>δ0, Sr(k,l)≤δ
(17)
将Sr(k,l)与一阈值δ进行比较,本文中δ的值设为5,当Sr(k,l)>δ时认为语音存在,p(k,l)=1;
当Sr(k,l)≤δ时认为语音不存在,p(k,l)=0。Sr(k,l)通过式(18)计算:
Sr(k,l)=S(k,l)/Smin(k,l)
(18)
其中:S(k,l)=αsS(k,l-1)+(1-αs)Sf(k,l),本文中αs取0.8,Sf(k,l)表示当前帧频点k处一定范围相邻频点的平均值;Smin(k,l)表示当前帧频点k处带噪语音功率谱的最小值。
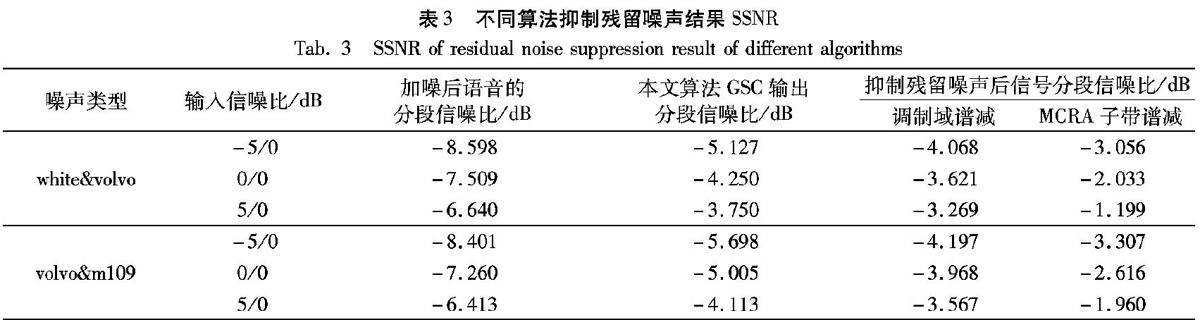
本文将MCRA算法作为子带谱减中的噪声功率谱估计方式,同时将带噪语音的频谱划分为6个相互不重叠的子频带,利用带噪语音各频带上不同的子带信噪比值来计算独立的过减因子。基于MCRA的子带谱减法[13-14]计算公式可以表示为:
| X ^ i(ω) | 2=
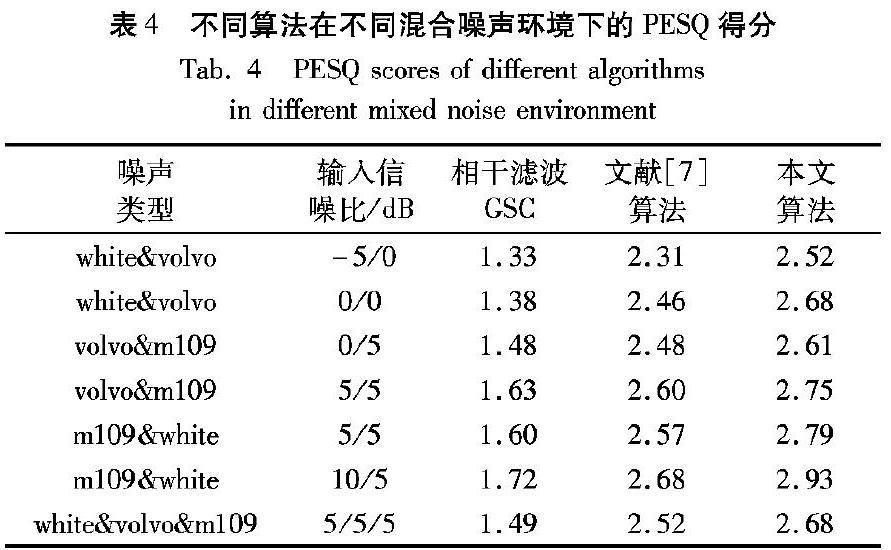
| Y ^ i(ω) | 2-αiδi | Di(ω) | 2; bi<ω (19) 其中: | Y ^ i(ω) | 2为频带i上带噪语音功率谱; | Di(ω) | 2表示频带i上MCRA噪声功率谱估计; | X ^ i(ω) | 2表示频带i上对纯净语音功率谱估计;bi表示频带的起始点,bi+1表示频带的截止点;αi和δi分别是频带i的过减因子和减法因子。频带i上的子带信噪比SNRi由带噪语音功率谱和噪声功率谱估计通过式(20)确定: SNRi=10lg ∑ bi+1 bi | Yi(ω) | 2 ∑ bi+1 bi | Di(ω) | 2 (20) αi由子带信噪比SNRi通过式(21)计算得: αi= 5, SNRi<-5 4-3/20*SNRi, -5≤SNRi≤20 1, SNRi>20 (21) 减法因子δi为子带谱减法中各子带谱减权重控制提供更大的灵活性。δi的值通过式(22)确定: δi= 1, fi≤1kHz 2.5, 1kHz 1.5, fi> Fs 2 -2kHz (22) 其中: fi表示第i個子带频率的上界; Fs为语音采样频率。其中低频带和高频带谱减较为缓和以最小化语音失真。 当谱减后的功率谱出现负值时,纯净语音信号功率谱估计 | X ^ i(ω) | 2由频谱乘系数b和带噪语音信号功率谱相乘的乘积得到: | X ^ i(ω) | 2= | X ^ i(ω) | 2, | X ^ i(ω) | 2>0 b* | Yi(ω) | 2, | X ^ i(ω) | 2≤0 (23) 频谱乘系数b取0.002。 本文于广义旁瓣抵消器的输出端采用MCRA子带谱减进一步对残留噪声进行消除。 5 实验结果及分析 本文利用KEMAR人工头设备与M-AUDIO多路音频采集器采集实验数据,语音和噪声在同环境下录制,噪声源使用Noisex-92数据库中的部分噪声。录制的纯净语音文件和噪声文件都包含不同麦克风采集的4路子信号。用于实验的带噪语音文件是将一种或多种噪声文件按照一定的信噪比混入纯净语音文件相对应的子信号中生成。带噪语音文件同样包含4路子信号。所有实验均在Matlab仿真环境下进行。 首先,通过本文提出的改进互功率估计的相干滤波算法与谱修正滤波算法进行对比实验,来验证该算法对弱相关噪声的抑制效果。实验采用一段时长为5s左右,加入了不同信噪比(-5dB、0dB、5dB)单一噪声类型(volvo噪声、white噪声)的带噪语音文件。提取带噪语音文件中间距较远、所含噪声呈弱相关性的两个麦克风M1和M3采集的子信号作为参考输入。经过两种不同算法增强后的语音通过信噪比(Signal-to-Noise Ratio, SNR)来对噪声抑制效果进行对比。表1是谱修正滤波及改进互功率估计的相干滤波算法增强后的输出信噪比。 通过表1对比两种算法的输出信噪比可以看出,在输入信噪比小于5dB时,改进互功率估计的相干滤波算法增强信号的输出信噪比谱修正滤波算法增强信号更高,这说明改进互功率估计的相干滤波算法对弱相关性噪声的抑制效果更好。 接着通过对比文献[7]算法GSC增强信号,及本文算法GSC增强信号的消噪效果,以验证本文算法对GSC性能的改进。实验采用一段时长为5s左右,加入了不同信噪比(-5dB、0dB、5dB)多种噪声类型(volvo噪声、m109噪声、white噪声)的带噪语音文件。两种算法GSC增强后的信号同样通过信噪比对噪声的抑制效果进行比较,结果如表2所示,其中输入SNR-5/0表示第一类噪声输入信噪比为-5dB,第二类噪声输入信噪比为0dB。 文献[7]提出的算法中两次对带噪语音的增强都主要针对双微阵列阵元相互之间的强相关噪声,对弱相关噪声的抑制能力有所不足,而本文算法则对强相关噪声及弱相关噪声都有较好的抑制效果。通过表2中GSC增强信号输出SNR的对比可以看出,本文算法有更好的消噪性能。 在多噪声环境下,本文算法GSC输出端仍残留着一些噪声,且这些噪声在各频带上分布较不均匀,因此需要有针对性地消除这些残留噪声。本次实验将调制域谱减法及本文提出地基于MCRA的子带谱减法对残留噪声的抑制效果进行比较。增强后的信号采用分段信噪比(Segmental Signal-to-Noise Ratio, SSNR)[15]来评测残留噪声抑制效果。表3是经过不同算法抑制残留噪声后信号的SSNR。 通过表3可以看出,在多噪声环境下采用MCRA子带谱减对GSC输出信号的残留噪声抑制效果比调制域谱减法更好。 最后,通过比较相干滤波GSC算法、文献[7]算法及本文算法对一段17s左右包含12个孤立词的带噪语音文件的增强效果,进一步验证本文算法的有效性。带噪语音文件中混入了不同信噪比(-5dB、0dB、5dB、10dB)多种类型的噪声(volvo噪声、m109噪声、white噪声)。本文通过感知语音质量评价(Perceptual Evaluation of Speech Quality, PESQ)[16]对语音增强效果进行衡量。PESQ算法得分与主观评测方法平均意见得分(Mean Opinion Score,MOS)的相关程度达到097,能有效地通过客观评价来模拟主观评价,同时又避免了MOS打分中的主观因素。 图5是混合0dB白噪声与0dB volvo噪声的情况下,用相干滤波GSC算法、文献[7]的算法及本文算法进行语音增强后的信号的时域波形对比。 从图5中可以看出:与相干滤波GSC算法相比,本文算法的消噪效果提升明显;同时与文献[7]的算法相比,本文算法残留噪声更少,消噪效果有一定的提升。 表4是不同算法在不同混合噪声环境下的PESQ得分,更为客观地反映了不同算法消噪性能的优劣。 通过表4的仿真数据可以看出,在多噪声混合的噪声环境中,本文算法比相干滤波GSC算法及文献[7]算法的消噪效果均有所提高。与相干滤波GSC算法相比,本文算法的PESQ得分提高了近1.2分,与文献[7]所提出的算法相比较,本文算法的PESQ得分也提高了0.2分左右。这说明,利用双微阵列在多噪声环境下消噪时,采用本文算法比相干滤波GSC算法及文献[7]的算法效果更好。 6 结语 本文根据双微阵列模型的特点,提出了改进互功率估计的相干滤波结合GSC与MCRA子带谱减的语音增强方法。通过对比实验验证了本文算法在多噪声环境下对双微阵列信号中的强相关噪声、弱相关噪声及非相关噪声都有较好的消除效果。同时,本文算法也存在一些问题,与CF-GSC算法及文獻[7]提出的算法相比,本文算法计算量偏大。在Matlab仿真环境中,CF-GSC算法及文献[7]的算法处理一段5s左右带噪语音文件所需时间分别为3.5s和4.9s,而本文算法则需要9.7s。这主要是由于改进互功率谱估计相干滤波算法中互功率谱估计方式需要多次迭代计算导致的。因此本文算法的进一步的研究方向旨在寻找更为快速且有效的互功率谱估计方式以提高本文算法的计算速度。 参考文献 [1] BOLL S F. Suppression of acoustic noise in speech using spectral subtraction [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2): 113-120. [2] 靳立燕,陳莉,樊泰亭,等.基于奇异谱分析和维纳滤波的语音去噪算法[J].计算机应用,2015,35(8):2336-2340. (JIN L Y, CHEN L, FAN T T, et al. Speech denoising algorithm based on singular spectrum analysis and Wiener filtering [J]. Journal of Computer Applications, 2015, 35(8): 2336-2340.) [3] PALIWAL K, SCHWERIN B, WóJCICKI K. Speech enhancement using a minimum mean-square error short-time spectral modulation magnitude estimator [J]. Speech Communication, 2011, 54(2): 282-305. [4] 李斌,张玲华.一种广义旁瓣抵消器结构的语音增强改进算法[J].数据采集与处理,2017,32(2):307-313. (LI B, ZHANG L H. Improved speech enhancement algorithm with generalized sidelobe canceller [J]. Journal of Data Acquisition and Processing, 2017, 32(2): 307-313.) [5] 杨立春,钱沄涛.基于相干性滤波器的广义旁瓣抵消器麦克风小阵列语音增强方法[J].电子与信息学报,2012,34(12):3027-3033. (YANG L C, QIAN Y T. Speech enhancement with generalized sidelobe canceller based on a coherence-based filter for small microphone arrays [J]. Journal of Electronics & Information Technology, 2012, 34(12): 3027-3033. [6] 马金龙,曾庆宁,胡丹,等.基于麦克风小阵的多噪声环境语音增强算法[J].计算机应用,2015,35(8):2341-2344. (MA J L, ZENG Q N, HU D, et al. Speech enhancement algorithm based on microphone array under multiple noise environments [J]. Journal of Computer Applications, 2015, 35(8): 2341-2344.) [7] 毛维,曾庆宁,龙超.基于双微阵列的语音增强算法[J].计算机工程与设计,2018,39(8):2490-2494. (MAO W, ZENG Q N, LONG C. Speech enhancement algorithm based on dual-mini microphone array [J]. Computer Engineering and Design, 2018, 39(8): 2490-2494.) [8] PARK J, KIM W, HAN D K, et al. Two-microphone eneralized sidelobe canceller with post-filter based speech enhancement in composite noise [J]. ETRI Journal, 2015, 38(2): 366-375. [9] ZHANG M, WU S, GUO W, et al. A microphone array dereverberation algorithm based on TF-GSC and postfiltering [C]// Proceedings of the 2016 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. Piscataway, NJ: IEEE, 2016: 1-4. [10] JEANNS W L B, SCALART P, FAUCON G, et al. Combined noise and echo reduction in hands-free systems: a survey [J]. IEEE Transactions on Speech & Audio Processing, 2001, 9(8): 808-820. [11] MARTIN R. Noise power spectral density estimation based on optimal smoothing and minimum statistics [J]. IEEE Transactions on Speech and Audio Processing, 2001, 9(5): 504-512. [12] COHEN I, BERDUGO B. Noise estimation by minima con-trolled recursive averaging for robust speech enhancement [J]. IEEE Signal Processing Letters, 2002, 9(1): 12-15. [13] KAMATH S, LOIZOU P C. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise [C]// Proceedings of 2002 IEEE International Conference on Acoustics, Speech and Signal Processing. Washington, DC: IEEE Computer Society, 2002, 4: IV-4164-IV-4164. [14] 李真,吳文锦,张勤,等.基于最大后验相位估计的多带谱减语音增强算法[J].电子与信息学报,2017,39(9):2282-2286. (LI Z, WU W J, ZHANG Q,et al. Multi-band spectral subtraction of speech enhancement based on maximum posteriori phase estimation [J]. Journal of Electronics & Information Technology, 2017, 39(9): 2282-2286.) [15] DELLER J R, Jr., HANSEN J H L, PROAKIS J G. Discrete-Time Processing of Speech Signals [M]. Upper Saddle River, NJ: Prentice Hall, 2000: 127-167. [16] RIX A W, BEERENDS J G, KIM D-S, et al. Objective assessment of speech and audio quality — technology and applications [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(6): 1890-1901. Journal of the Audio Engineering Society, 2002, 50(10): 755-764.
