基于高阶近似的链路预测算法
2019-10-23杨燕琳冶忠林赵海兴孟磊
杨燕琳 冶忠林 赵海兴 孟磊

摘 要:目前大部分鏈路预测算法只研究了节点与邻居节点之间的一阶相似性,没有考虑节点与邻居的邻居节点之间的高阶相似性关系。针对此问题,提出一种基于高阶近似的链路预测算法(LP-HOPA)。首先,求出网络的归一化邻接矩阵和相似度矩阵;其次,利用矩阵分解的方法将相似度矩阵进行分解,得到网络节点的表示向量以及其上下文的表示向量;然后,通过高阶网络表示学习的网络嵌入更新(NEU)算法对原始相似度矩阵进行高阶优化,并利用归一化的邻接矩阵计算出更高阶的相似度矩阵表示;最后,在四个真实的数据集上进行大量的实验。实验结果表明,与原始链路预测算法相比,大部分利用LP-HOPA优化后的链路预测算法准确率提升了4%到50%。此外,LP-HOPA算法能够将基于低阶网络局部结构信息的链路预测算法转换为基于节点高阶特征的链路预测算法,在一定程度上肯定了基于高阶近似链路预测算法的有效性和可行性。
关键词:链路预测;高阶近似;相似度矩阵;矩阵分解;网络嵌入更新算法
中图分类号: TP393
文献标志码:A
Link prediction algorithm based on high-order proximity approximation
YANG Yanlin1,2,3, YE Zhonglin1,2,3,4, ZHAO Haixing1,2,3,4*, MENG Lei1,2,3
1.College of Computer, Qinghai Normal University, Xining Qinghai 810016, China ;
2.Tibetan Information Processing and Machine Translation Key Laboratory of Qinghai Province (Qinghai Normal University), Xining Qinghai 810008, China ;
3.Key Laboratory of Tibetan Information Processing of Ministry of Education (Qinghai Normal University), Xining Qinghai 810008, China ;
4.School of Computer Science, Shaanxi Normal University, Xian Shaanxi 710062, China
Abstract: Most of the existing link prediction algorithms only study the first-order similarity between nodes and their neighbor nodes, without considering the high-order similarity between nodes and the neighbor nodes of their neighbor nodes. In order to solve this problem, a Link Prediction algorithm based on High-Order Proximity Approximation (LP-HOPA) was proposed. Firstly, the normalized adjacency matrix and similarity matrix of a network were solved. Secondly, the similarity matrix was decomposed by the method of matrix decomposition, and the representation vectors of the network nodes and their contexts were obtained. Thirdly, the original similarity matrix was high-order optimized by using Network Embedding Update (NEU) algorithm of high-order network representation learning, and the higher-order similarity matrix representation was calculated by using the normalized adjacency matrix. Finally, a large number of experiments were carried out on four real datasets. Experiments results show that, compared with the original link prediction algorithm, the accuracy of most of the link prediction algorithms optimized by LP-HOPA is improved by 4% to 50%. In addition, LP-HOPA can transform the link prediction algorithm based on local structure information of low-order network into the link prediction algorithm based on high-order characteristics of nodes, which confirms the validity and feasibility of the link prediction algorithm based on high order proximity approximation to a certain extent.
Key words: link prediction; high-order proximity approximation; similarity matrix; matrix decomposition; Network Embedding Update (NEU) algorithm
0 引言
随着网络科学的不断进步,网络的演化机制[1]受到了学者们的广泛关注,而链路预测为网络的演化提供了一个高效简单的比较机制,因此,对链路预测的研究也受到了学者们的广泛关注。网络中的链路预测是指如何通过已知网络的特征、结构和节点信息等预测不相连的两个节点之间产生链接的可能性[2]。链路预测的应用对实际生活产生了重要的意义。例如,蛋白质网络[3]可预测没有产生相互作用的蛋白质节点未来产生相互作用的可能性,将最可能产生相互作用的蛋白质做实验, 可提高实验的成功率;社交分析网络[4]可预测陌生人成为朋友的可能性;标签分类[5]可通过节点的特征和性质去预测节点的类别;异常检测[6]可以通过链路预测预测网络中的错误链接,对错误链接进行纠正;信息推荐系统[7]则通过链路预测向用户自动推荐可能需要的物品。除此之外,链路预测还应用到了网络建模[8]、知识获取[9]等领域。为了将链路预测应用到实际生活中,研究者们已经提出了很多链路预测算法,大多是基于相似性和最大似然估计的链路预测算法,可是现实生活中产生的数据越来越多,网络越来越复杂,规模越来越大,而这些链路预测算法大多存在着高计算复杂性和低精确性的问题,主要适用于小规模网络,这就造成了链路预测应用的局限性。
邻接矩阵可以将网络简单直接地表示出来,但是邻接矩阵占用了大量的存储空间,数据十分稀疏,因此,研究者们转而思考如何将网络数据高效地表示出来。网络表示学习(Network Representation Learning, NRL) [10]将网络的节点信息转化为低维稠密的向量来表示。因此,将链路预测与网络表示学习相结合,可以更全面地读取网络节点信息,使链路预测结果更精确。DeepWalk[11]和LINE (Large-scale Information Network Embedding) [12]是最具代表性的基于神经网络的网络表示学习算法。DeepWalk算法利用了网络结构的随机游走序列信息,并通过节点及其上下文节点之间的关系训练神经网络;LINE算法考虑了网络的两种相似度,用两节点是否直接相连来刻画一阶相似度,用不相连的两个节点的共同邻居来刻画二阶相似性,该算法可被应用于大规模网络表示学习任务,但其精度却不如DeepWalk算法。网络嵌入更新(Network Embedding Update, NEU)算法 [13]是一种通过简单的矩阵转换构建高阶网络表示的方法,但并不需要重新训练网络表示学习模型,该算法可以应用到任意的NRL方法,来提高它们的性能。例如,将该算法应用在DeepWalk算法时,只用了DeepWalk算法运行时间的1%,即有显著的提升。
目前大部分链路预测算法只研究了节点与邻居节点之间的一阶相似性,忽略了节点与邻居的邻居节点的高阶相似性关系,比如二阶相似性、三阶相似性等。本文基于NEU表示学习算法,提出了一种基于高阶近似的链路预测算法(Link Prediction algorithm Based on High Order Proximity Approximation, LP-HOPA)。该方法能够将基于低阶网络局部结构信息的链路预测算法转化为节点高阶特征相似链路预测算法,提升其链路预测性能。该方法在相似矩阵分解的结果上进行高阶转换,以获得节点之间高阶的关系,从而可以得到高阶近似的相似度矩阵,该相似度矩阵给了节点之间的一阶相似性、二阶相似性,并可以推广到节点之间的n阶相似性,因此可以更精准地预测节点间的相似性。
本文的主要工作有:1) 将NEU表示学习算法引入到网络的链路预测中,提出了一种基于高阶近似的链路预测算法LP-HOPA。
2)基于四个真实的数据集在17个常见的链路预测指标进行了链路预测实验,结果表明,LP-HOPA可有效学习网络的结构特征,具有一定程度的可行性和有效性,而且它的链路预测性能优于本文中用来对比的链路预测指标。
LP-HOPA能够将基于低阶网络局部结构信息的链路预测算法转换为基于节点高阶特征的链路预测算法,从而提升链路预测性能。
1 相关工作
近10年,得益于Clauset等2008年在Nature上发表的论文[14]以及Redner对这篇论文的评论文章[15],链路预测的研究方法被相继提出。目前,主要包括以下三大类方法:
第一类是基于相似性的链路预测方法,即节点相似性越大,说明连边可能性越大。主要有如下三小类:
1)基于网络局部结构信息相似性方法,主要包括基于共同邻居(Common Neighbors, CN)[7]的相似性指标、基于Adamic-Adar(Adamic-Adar, AA)[7]算法的相似性指标、基于资源分配(Resource Allocation, RA)[7]的相似性指标和基于優先链接(Preferential Attachment, PA)[7]的相似性指标。在共同邻居的基础上,可以详细分成6种相似性指标,包括基于余弦相似性指标Salton[7]、Jaccard相似性指标[7]、Sorenson相似性指标[7]、大度节点有利相似性指标HPI(Hub Promoted Index)[7]、大度节点不利相似性指标HDI(Hub Depressed Index)[7]和节点对分配相似性指标LHN-1(Leicht-Holme-Newman)[16]。在CN、AA和RA的基础上,
文献[17]中提出了基于局部朴素贝叶斯算法的相似性指标LNBCN
(Local Naive Bayes model-CN)、LNBAA(Local Naive Bayes model-AA)和LNBRA(Local Naive Bayes model-RA)。
2)基于路径的相似性方法,包括:基于局部路径(Local Path, LP)[18]的相似性指标、基于节点声望的相似性指标Katz[19]和LHN-II(Leicht-Holme-Newman II)指标[16]。
3)基于随机游走的相似性方法,包括:基于平均通勤时间(Average Commute time, ACT)[20]的相似性指标、基于随机游走的余弦相似性指标Cos+[21]、局部随机游走(Local Random Walk, LRW)[18]的相似性指标、有叠加效应的随机游走(Superposed Random Walk, SRW)[18]相似性指标和有重启的随机游走(Random Walk with Restart, RWR)[18]相似性指标。
第二类是基于概率和最大似然估计的链路预测方法。基于概率的链路预测方法通过构建贝叶斯、马尔可夫等数学模型预测未知的链接,基于最大似然估计的链路预测方法利用网络的结构信息得到最大似然数。Clauset等[14]最初提出基于最大似然估计的链路预测方法,将其应用到有明显层次的网络结构中,发现有比较高的精确度;
田甜等[22]提出了一种基于最大似然估计的链路预测模型,将脑网络的数据建立了层次随机图,再结合马尔可夫算法计算脑网络边的连接概率,结果显示出了良好的预测性能。
第三类是基于机器学习的链路预测方法。该类方法在相似性链路预测方法的基础之上进一步获取网络特征。如廖亮等[23]针对机会网络研究了基于
支持向量机(Support Vector Machine, SVM)
的链路预测,构建了基于节点对空间相似性和时间特征加权融合的支持向量机模型,从空间相似性和时间特征两个角度分析单节点对的连接概率,并证明了其具有很好的预测效果;吴祖峰等[24]将AdaBoost集成学习算法应用到了链路预测中,在论文合作网络和电子邮件网络等进行了实验验证;吕伟民等[25]将基于机器学习的链路预测方法应用到了科研合作网络中,提高了推荐合作的精确度。
基于相似性的链路预测方法不能充分挖掘网络的结构特征,尤其是基于网络局部结构信息的相似性方法,预测准确度较低;基于概率和基于最大似然估计的链路预测方法预测准确度高,但算法复杂度较高,导致了此类方法应用的局限性,主要适用于预测低阶小规模网络;
基于机器学习的链路预测方法的预测效果较好,可以预测大规模网络,但是节点特征矩阵占用了大量的存储空间,数据稀疏,因此大大增加了特征读取时间;而网络表示学习可以将特征信息用低维稠密的向量表示出来,这就降低了算法的时间复杂度,应用到链路预测中,具有低算法复杂度和高精确度的特点。
因此,有越来越多的学者提出了基于网络表示学习的链路预测算法。如杨晓翠等[26]提出了基于网络表示学习的链路预测算法,冶忠林等[27]提出了基于矩阵分解的DeepWalk链路预测算法,刘思等[28]提出了基于网络表示学习与随机游走的链路预测算法,均得到了较好的预测结果,但他们都只考虑了节点与邻居节点之间的一阶相似性,忽略了节点与邻居的邻居节点的高阶相似性关系;而本文提出的LP-HOPA能够将基于低阶网络局部结构信息的链路预测算法转化为节点高阶特征相似链路预测算法,提升链路预测性能。
2 基于高阶近似的链路预测
2.1 定义描述
信息网络[29]:定义一个信息网络为G=(V,E),其中V表示顶点集,E表示边集。定义G的特征矩阵为 X , X 是 | V | ×m维的,m表示节点的特征属性个数。如果网络G对应的特征矩阵 X 是非空的,则G是一个信息网络。
网络表示学习[29]:给定一个信息网络G=(V,E), X 为G的特征矩阵,满足任意顶点v∈V,学习将网络用低维向量 r v∈ R k表示,其中 r v是一个低维稠密的实数向量,且满足k | V | 。
链路预测[2]:给定一个无向网络G=(V,E),其中V表示顶点集,E表示边集。定义M为该网络中的最大边数,满足M= | V | ( | V | -1)/2,M-E表示该网络中不存在的边集,而链路预测则是在集合M-E中找出未来可能连边的顶点对。通过某种链路预测方法可计算出每对未连边的顶点对的相似性分数,分数越高则连边可能性越大。
2.2 高阶网络表示学习NEU算法
NEU算法是由Yang等[13]提出的一种基于矩阵转换的高阶近似网络表示方法,可以应用到任意的网络表示学习算法中,以提高基类网络表示学习算法的性能。
给定超参数λ∈(0,1/2],归一化的邻接矩阵 A , R 和 C 分别表示信息网络的网络表示和上下文表示,通过NEU算法更新后, R ′和 C ′分别为更新后的网络表示和上下文表示的方法如下:
R ′= R +λ A · R
C ′= C +λ A T· C
(1)
計算出 A · R 和 A T· C 的时间复杂度是O( | V | d),因为矩阵 A 是稀疏的并且有O( | V | )个非零项,因此,式(1)一次迭代的整体时间复杂度为O( | V | d)。
式(1)可以在进一步推广到二阶形式,以获得二阶近似的网络表示。首先更新 R 和 C :
R ′= R +λ1 A · R +λ2 A ·( A · R )
C ′= C +λ1 A T· C +λ2 A T·( A T· C )
(2)
式(2)的时间复杂度仍然是O( | V | d),但是它在一次迭代中可以得到比式(1)更高的相似矩阵近似。同时也可以使用比式(2)更复杂的更新公式来探索更高的近似,例如三阶、四阶……n阶近似的网络表示。
NEU算法避免了高阶相似矩阵的精确计算,也避免了通过模型训练高阶网络表示模型,但可以产生高阶近似的网络表示,因此该算法可以有效提高网络表示的质量。直观上,式(1)和(2)允许学习到的节点表示进一步传播到它们的邻居,因此,顶点之间距离较长的相似将被嵌入。
2.3 基于高阶近似的链路预测算法
通过NEU算法中节点向量的表示过程发现,该算法在矩阵分解的结果上更新以获得更高阶的网络表示,使最后的向量效果蕴含更多的网络结构特征,因此将NEU算法运用到链路预测后可以得到高阶相似矩阵,可以更精准地预测节点间的相似性。在此基础上,本文将NEU算法融入到链路预测中,提出了一种基于高阶近似的链路预测算法LP-HOPA。
LP-HOPA流程如图1所示,具体如下:
1)输入网络G=(V,E),其中V为顶点集,E为边集。
2)将网络分割成训练集和测试集,将训练集转化为邻接矩阵 A ~ ∈ R |V|×|V|,如果vi和vj之间有连边,则 A ~ ij=1,否则 A ~ ij=0。对角矩阵 D ∈ R |V|×|V|,Dii的数值即为vi的度。
3)将 A ~ 转化为归一化邻接矩阵 A , A = D -1 A ~ ,即每行之和等于1。
4)通过AA、CN、RA和MFI等链路预测基准指标计算相似矩阵 S ,并使用SVDS算法将 S 分解为 U |V|×k、 Σ k×k和 V Tk×|V| (此 V 为矩阵,区别于2.1小节的V,该V为顶点集) 三个矩阵。SVDS是奇异值分解(Singular Value Decomposition, SVD)的一种Matlab方法,表示取最大的6个特征值。
接着,将分解得到的这三个矩阵转化为两个矩阵的乘积:
ne = U · Σ
(3)
nc = Σ · V T
(4)
使得 S ≈ ne · nc 。
根据NEU算法得知, ne 为节点的表示向量, nc 为上下文的表示向量。
5)利用NEU算法在矩阵分解结果的基础之上进行更新,以获得更高阶的网络特征相似度矩阵结果:
ne ′= ne +λ1 A · ne +λ2 A ·( A · ne )
(5)
nc ′= nc +λ1 A T· nc +λ2 A T·( A T· nc )
(6)
通过以上更新结果,可得到接近高阶近似的相似矩阵: S ′≈ ne ′· nc ′。将该相似矩阵应用到链路预测算法中,利用链路预测准确度度量指标AUC(Area Under the receiver operating characteristic Curve)指标计算出AUC值,从而评估本文所提出的链路预测性能。
3 实验结果与分析
3.1 实验数据
本文选择四个真实网络数据集进行测试,分别为:
1)Citeseer网络: http://citeseerx.ist.psu.edu/index。它是由3312篇世界顶级会议论文构成的引文网络,包含4732篇文章之间引用或被引用的关系。
2)DBLP(DataBase systems and Logic Programming)网络: https://dblp.uni-trier.de/。它是由3119个作者构成的合作网络,顶点表示作者,连边表示作者之间的合作关系,包含39516个作者间的合作关系。
3)Cora网络: http://www.cs.umd.edu/~sen/lbc-proj/data/cora.tgz。它是由2708份科学出版物组成的引文网络,包含5429条连边。
4)Wiki网络: https://www.wikipedia.org/。该网络是维基百科网页链接网络,本文只取了2405个网页之间的17981个链接关系。
表1进一步列出了这四个数据集的网络拓扑结构特征,其中: | V | 表示节点数, | E | 表示连边数, | Y | 表示网络标签数,K表示平均度,D表示网络直径,L表示平均路径长度,P表示密度,C表示平均聚类系数。
3.2 评价指标
本文链路预测准确度的度量指标采用AUC指标[30]。AUC可以从整体上衡量算法的精确度,可以描述为在测试集中随机选择一条存在连边的分数值高于随机选择一条不存在连边的分数值的概率,如果独立重复比较n次,有n1次在测试集中存在连边的分数大于不存在连边的分数,有n2次在测试集中存在连边的分数等于不存在连边的分数,则AUC值可以定义为:
AUC=(n1+0.5n2)/n
(7)
一般意义上,计算出的AUC值至少应大于0.5,至多不超過1。AUC值越高,算法的准确度越高。
3.3 基准方法
本文将常用的17种基于相似性的链路预测算法作为基准进行性能比较。其中包括基于网络局部结构信息的基准方法:CN、Salton、HPI、HDI、LHN-1、AA、RA、PA、LNBAA、LNBCN、LNBRA;基于路径的基准方法:LP、Katz;基于随机游走的基准方法:ACT、Cos+;基于矩阵森林理论的相似性指标(Matrix-Forest theory Index, MFI)[18];基于传递的相似性指标(Transferring Similarty Common Neighbor,TSCN)[31]。下面分别对各基准方法作简要介绍。
Katz指标考虑了x和y之间的所有路径数,对于短路径赋予大权重,对于长路径赋予小权重。其中,β为可调参数。
SKatzxy=β A +β2 A 2+β3 A 3…=( I -β A )-1- I
(22)
16)基于平均通勤时间的相似性指标ACT。
一个随机粒子从节点x到达节点y平均要走的步数m(x,y),那么,节点x和y的平均通勤时间定义为:
n(x,y)=m(x,y)+m(y,x)
则其数值求解可以通过求该网络拉普拉斯矩阵的伪逆 L +得到。如果节点x和y的平均通勤时间越短,则这两个节点的相似度越高。
SACTxy= 1 l+xx+l+yy-2l+xy
(23)
17)基于随机游走的余弦相似性指标cos+。
在由向量 v x= Λ 2 U T e x展开的欧氏空间中, U 是一个标准正交矩阵, Λ 为对角矩阵,对角线元素为特征根, e x表示一个只有第x个为1,其他元素为0的一维向量; L +中的元素l+xy为vx和vy的内积。
Scos+xy=cos(x,y)+=(l+xy) / l+xxl+yy
(24)
3.4 实验设置
在LP-HOPA中,本文设置了四个网络训练集的训练比例分别为0.7、0.8、0.9,測试集的训练比例分别为0.3、0.2、0.1;特征维度d设为100;超参数λ1=0.5,λ2=0.25;迭代次数maxIter设为3;最终实验结果为各网络独立运行10次的平均值。
3.5 实验结果
首先求出网络的归一化邻接矩阵 A 和相似度矩阵 S :其次,通过SVDS将 S 进行分解,得到网络节点的表示向量 ne 以及其上下文的表示向量 nc :接着,通过高阶网络表示学习NEU算法在原始相似度矩阵的结果上进行高阶优化;然后,利用归一化的邻接矩阵计算出更高阶的相似度矩阵表示;最后,在Citeseer、DBLP、Cora和Wiki四个数据集上进行实验验证。为验证上述方法的可行性及有效性,本文使用3.3节的所有相似性链路预测基准指标进行对比。
表2列出了在上述四个数据集上,其训练集的训练比例分别为0.7、0.8、0.9时,3.3节中原始方法和本文方法在各链路预测基准算法的AUC值对比。
观察表2中的数据结果,对于原始链路预测方法,在四个数据集上链路预测准确率都高于80%的仅有4个算法,即LP、Katz、Cos+和MFI。其中Katz和MFI算法链路预测性能较优,尤其是在Citeseer数据集上准确率都达到了97%以上;而CN、Salton、HPI等算法在Citeseer数据集上显示链路预测准确率较差,最低低至65%。
对比相关工作中所列出的基于相似性的链路预测算法发现,基于路径的相似性方法链路预测性能较优,基于网络局部结构信息相似性方法性能较差。对于本文方法,在四个数据集上链路预测准确率都高于80%的有14个算法,即为CN、Salton、HPI、HDI、LHN-1、AA、RA、LP、Katz、LNBAA、LNBCN、LNBRA、Cos+和MFI。其中HDI、LNBRA和Salton算法链路预测性能较优,尤其是在DBLP数据集上准确率都达到了93.5%以上;而ACT在Citeseer数据集上显示链路预测准确率较差,最低低至35.9%。
对比相关工作中所列出的基于相似性的链路预测算法发现,基于网络局部结构信息相似性方法性能较优,基于随机游走的相似性方法链路预测性能较差。
通过对比原始链路预测方法和本文方法可以发现,利用LP-HOPA后,链路预测准确率都高于80%的算法个数比原始链路预测算法多10个,这些算法为CN、Salton、HPI、HDI、LHN-1、AA、RA、LNBAA、LNBCN和LNBRA。大部分相比原始链路预测算法准确率提升了4%到50%不等,仅有极个别算法有较小幅度的下降。
原始算法基于路径的相似性方法链路预测性能较优,而利用LP-HOPA后基于网络局部结构信息相似性方法性能较优,在一定程度上肯定了本文方法的可行性和有效性。
利用LP-HOPA后,在四个数据集上,CN、Salton、HPI、HDI、LHN-1、AA、RA、LNBAA、LNBRA和LBNCN算法的AUC值得到了大幅度提升,尤其是在Citeseer、Cora数据集上基本都提升了20个百分点,PA算法略微下降,但Katz、ACT、MFI和TSCN算法上链路预测准确度却有一定程度的下降,尤其是在Citeseer数据集上ACT算法AUC值比原始方法下降了40个百分点。PA算法是一种只考虑节点度对相似度影响的链路预测算法,而本文方法对PA算法进行优化时,由于并未考虑连边,所以性能略微下降;Katz是基于全部路径的链路预测算法,因此Katz是一个n阶特征的链路预测算法,然而本文方法结合节点的高阶特征,仅考虑了节点间6阶以内的相似性,因此将n阶特征降至6阶特征导致了链路预测性能下降;MFI是一种基于森林树的算法,考虑的是两个节点所在的相同网络生成树数量,因此考虑了网络节点的高阶特征相似性;ACT算法实质上是考虑了两个节点之间随机游走来回的平均路径长度之和,路径越短,相似性越高,而LP-HOPA考虑了节点间6阶以内的相似性,因此性能有大幅度下降。
为了更进一步分析个别相似性指标使用本文方法后预测准确率下降的原因,表3比较了1、3、5阶对最终预测结果的影响。为使对比结果更加鲜明,2、4、6阶对比结果未展示。
表3所示为Citeseer数据集在训练率为0.7时,对1、3、5阶使用本文方法后的AUC值。可以看出,除了ACT相似度指标外,其他指标的AUC值都是呈增加状态。阶数越高,ACT的预测准确率反而越来越低,说明ACT路径越短,相似性越高;Katz指标呈增加趋势,也可以由此说明若不断将阶数增加到n,Katz相似性指标的AUC值也会不断递增;CN、Salton、AA和LNBRA等这些低阶的相似性指标呈现了一个很好的增加趋势。
本文所采用的方法是结合节点间的二阶相似、三阶相似、n阶相似综合考虑节点的相似性,所以对于能够转换为高阶特征的链路预测算法使用本文方法后性能会有所下降,但对于低阶链路预测算法使用本文方法的链路预测准确率都会有一定程度的提升,由此说明本文方法主要适用于基于网络局部结构信息的低阶链路预测基准方法。
3.6 时间复杂度对比
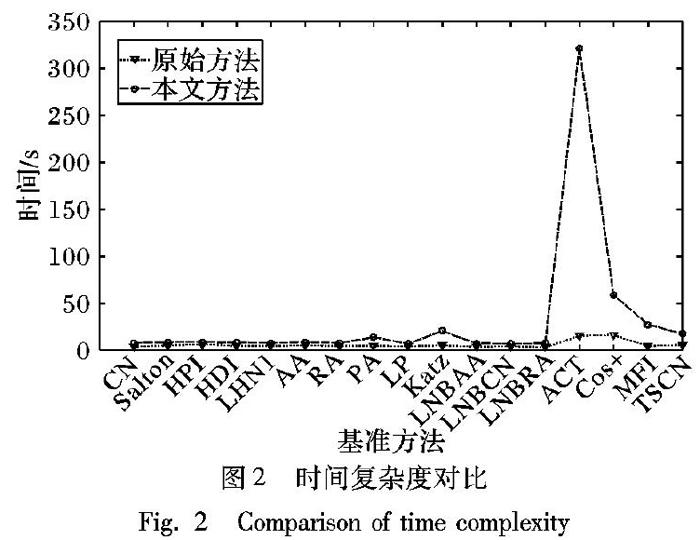
图2所示为Citeseer数据集下训练率为0.7时的链路预测算法时间复杂度对比,不同的数据集在不同的训练率下结果虽然不同,但是时间变化规律一致,因此时间复杂度对比结果具有代表性。横坐标表示相似性基准方法,纵坐标表示运行时间。通过对比可以看出,CN、Salton、HPI、HDI、LHN1、AA、RA、LP、LNBAA、LNBCN和LNBRA使用本文方法优化后,时间复杂度基本与原始方法的时间复杂度持平,说明本文方法对低阶链路预测算法能够在不提升算法复杂度的情况下转化为高阶特征的链路预测算法,并提升其链路预测性能;PA、Katz、ACT、Cos+、MFI和TSCN在使用本文方法后的算法复杂度有不同程度的提高,尤其是MFI的运行时间有大幅度的增加,由此说明本文方法并不适用于可转化为高阶特征的链路预测算法。
3.7 度分布可视化
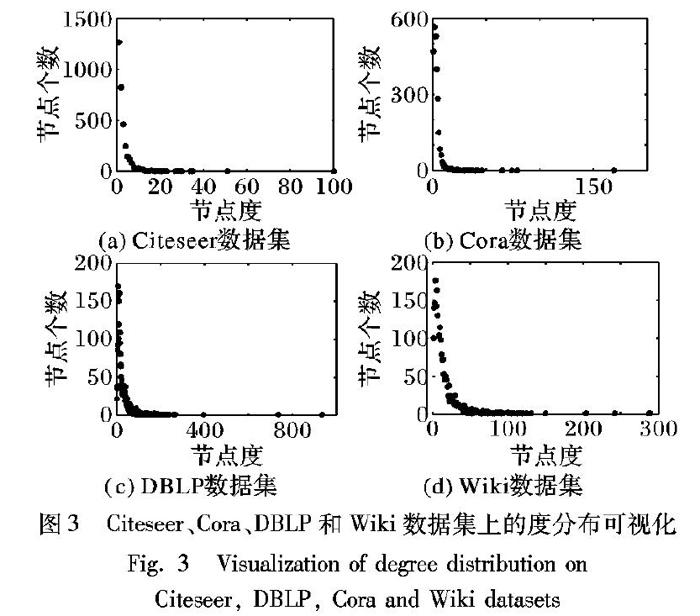
度分布是网络的基本性质之一,指网络中节点的度的概率分布。度分布与网络的拓扑结构性质密切相关,因此,研究网络的度分布可以基本确定网络的类型。本文使用Matlab实现了Citeseer、Cora、DBLP和Wiki四個数据集的度分布可视化。具体结果如图3所示,横坐标表示该数据集节点度值,纵坐标表示该度值对应的节点个数。
通过对比四个数据集可以看出,Citeseer数据集中节点最大度仅为100,但度为1的节点高频出现,高达1270次;Cora数据集节点的最大度值为169,度为2的节点较多,有567次;DBLP数据集中节点的最大度高于900,度为6的节点较多,有170次;Wiki数据集中节点最大度大于280,度为4的节点较多,有176次。通过对比,Citeseer和Cora数据集是相对比较稀疏的网络,而DBLP和Wiki数据集是相对稠密的网络。再通过对比表2和表3可以发现,不管是原始方法还是本文方法,DBLP和Wiki数据集链路预测效果比Citeseer和Cora数据集好。由此可以说明,链路预测对稠密的网络的预测结果比稀疏的网络好。
4 结语
本文针对目前大部分链路预测算法未考虑节点与邻居的邻居节点之间的高阶相似性关系,提出了一种基于高阶近似的链路预测算法LP-HOPA。首先,利用矩阵分解将相似度矩阵进行分解;其次,通过高阶网络表示学习NEU算法在矩阵分解的结果上进行更新,得到高阶的相似度矩阵;最后,在Citeseer、DBLP、Cora和Wiki四个数据集上进行了实验验证。实验结果表明,在实际网络的链路预测中,利用LP-HOPA可以进行更加有效的高阶转换,使其链路预测性能比现有的众多链路预测算法更加优异。但是LP-HOPA也存在着不足,主要有以下两点:1)LP-HOPA对于能够转换为高阶特征的链路预测算法使性能会有所下降;2)本文只考虑了6阶以内的相似性,因此基于随机游走的ACT算法性能有大幅度下降。在下一步的研究中,将尝试考虑在高阶转换时融入外部信息,充分挖掘网络的相关特征,并且将相似性阶数提升,使其不仅能适用于网络低阶的链路预测算法,同样基于高阶特征的链路预测算法也有一定程度的提升。除此之外,还可基于本文方法结合边的权值尝试构造相似性指标。
参考文献
[1] ALBERT R, BARABSI A-L. Statistical mechanics of complex networks [J]. Reviews of Modern Physics, 2002, 74(1): 47-97.
https://doi.org/10.1103/RevModPhys.74.47
[2] GETOOR L, DIEHL C P. Link mining: a survey [J]. ACM SIGKDD Explorations Newsletter, 2005, 7(2): 3-12.
[3] YU H, BRAUN P, YILDIRIM M A, et al. High-quality binary protein interaction map of the yeast interactome network [J]. Science, 2008, 322(5898): 104-110.
[4] XIE X, LI Y, ZHANG Z, et al. A joint link prediction method for social network [C]// Proceedings of the 2015 International Conference of Young Computer Scientists, Engineers and Educators, CCIS 503. Berlin: Springer, 2015: 56-64.
[5] KUMAR R, NOVAK J, TOMKINS A. Structure and evolution of online social networks [M]// Link Mining: Models, Algorithms, and Applications. New York: Springer, 2010: 337-357.
[6] ZHANG X, ZHAO C, WANG X, et al. Identifying missing and spurious interactions in directed networks [C]// Proceedings of the 2014 International Conference on Wireless Algorithms, Systems, and Applications, LNCS 8491. Berlin: Springer, 2014: 470-481.
[7] ZHOU T, LYU L, ZHANG Y. Predicting missing links via local information [J]. European Physical Journal B, 2009, 71(4): 623-630.
[8] LEICHT E A, HOLME P, NEWMAN M E J. Vertex similarity in networks [J]. Physical Review E:Statistical Nonlinear & Soft Matter Physics, 2006, 73(2): No.026120.
[9] ZADEH P M, KOBTI Z. A knowledge based framework for link prediction in social networks [C]// Proceedings of the 2016 International Symposium on Foundations of Information and Knowledge Systems, LNCS 9616. Cham: Springer, 2016: 255-268.
[10] 涂存超, 杨成, 刘知远,等. 网络表示学习综述[J]. 中國科学:信息科学, 2017, 47(8): 980-996. (TU C C, YANG C, LIU Z Y, et al. Network representation learning: an overview [J]. SCIENTIA SINICA Information, 2017, 47(8): 980-996.)
[11] BEROZZI B, AL-RFOU R, SKIENA S. DeepWalk: online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York: ACM, 2014: 701-710.
[12] TANG J, QU M, WANG M, et al. LINE: Large-scale information network embedding [C]// Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015: 1067-1077.
[13] YANG C, SUN M, LIU Z, et al. Fast network embedding enhancement via high order proximity approximation [C]// Proceedings of the 2017 26th International Joint Conference on Artificial Intelligence. Pola Alto, CA: AAAI, 2017: 3894-3900.
[14] CLAUSET A, MOORE C, NEWMAN M E J. Hierarchical structure and the prediction of missing links in networks [J]. Nature, 2008, 453(7191): 98-101.
[15] REDNER S. Networks: teasing out the missing links [J]. Nature, 2008, 453 (7191): 47-48.
[16] LEICHT E A, HOLME P, NEWMAN M E J. Vertex similarity in networks [J]. Physical Review E: Statistical Nonlinear & Soft Matter Physics, 2006, 73(2): No. 026120.
[17] LIU Z, ZHANG Q-M, LYU L, et al. Link prediction in complex networks: a local Naive Bayes model [J]. Europhysics Letters, 2011, 96(4): No. 48007.
[18] 王富田,张鹏,肖井华.链路预测算法错边识别能力的评测[J/OL]. 中国科技论文在线, 2015 [2015-12-30]. http://www.paper.edu.cn/releasepaper/content/201512-1363. (WANG F T, ZHANG P, XIAO J H. Evaluation the ability of link prediction methods in the spurious link detection [J/OL]. Sciencepaper Online, 2015 [2015-12-30]. http://www.paper.edu.cn/releasepaper/content/201512-1363.)
[19] KATZ L. A new status index derived from sociometric analysis [J]. Psychometrika, 1953, 18(1): 39-43.
[20] KLEIN D J, RANDIC M. Resistance distance [J]. Journal of Mathematical Chemistry, 1993, 12(1): 81-95.
[21] FOUSS F, PIROTTE A, RENDERS J, et al. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation [J]. IEEE Transaction on Knowledge & Data Engineering, 2007, 19(3): 355-369.
[22] 田甜, 杨艳丽, 郭浩,等. 基于层次随机图模型的脑网络链路预测[J]. 计算机应用研究, 2016, 33(4):1066-1069. (TIAN T, YANG Y L, GUO H, et al. Link prediction of brain networks based on hierarchical random graph model [J]. Application Research of Computers, 2016, 33(4):1066-1069.)
[23] 廖亮, 张恒锋. 基于支持向量机的机会网络链路预测[J]. 信息通信, 2018(9):28-30. (LIAO L, ZHANG H F. Link prediction based on support vector machine chance network [J]. Information & Communications, 2018(9):23-25.)
[24] 吳祖峰,梁棋,刘峤,等.基于AdaBoost的链路预测优化算法[J]. 通信学报, 2014,35(3):116-123. (WU Z F, LIANG Q, LIU Q, et al. Modified link prediction algorithm based on AdaBoost [J]. Journal on Communications, 2014, 35(3):116-123.)
[25] 吕伟民,王小梅,韩涛.结合链路预测和ET机器学习的科研合作推荐方法研究[J]. 数据分析与知识发现, 2017,1(4):38-45. (LYU W M, WANG X M, HAN T. Recommending scientific research collaborators with link prediction and extremely randomized trees algorithm [J]. Data Analysis and Knowledge Discovery, 2017, 1(4):38-45.)
[26] 杨晓翠,宋甲秀,张曦煌.基于网络表示学习的链路预测算法[J/OL].计算机科学与探索, 2018[2018-06-25]. http://kns.cnki.net/kcms/detail/11.5602.TP.20180622.1301.008.html. (YANG X C, SONG J X, ZHANG X H. Link prediction algorithm based on network representation learning [J/OL]. Journal of Frontiers of Computer Science and Technology, 2018[2018-06-25]. http://kns.cnki.net/kcms/detail/11.5602.TP.20180622.1301.008.html.)
http://www.cnki.com.cn/Article/CJFDTOTAL-KXTS201905009.htm
[27] 冶忠林,曹蓉,赵海兴,等.基于矩阵分解的DeepWalk链路预测算法[J/OL].计算机应用研究, 2018 [2018-12-12 ]. http://kns.cnki.net/KCMS/detail/51.1196.TP.20181211.1539.012.html. (YE Z L, CAO R, ZHAO H X, et al. Link prediction based on matrix factorization for DeepWalk [J/OL]. Application Research of Computers, 2018 [2018-12-12 ]. http://kns.cnki.net/KCMS/detail/51.1196.TP.20181211.1539.012.html.)
http://kns.cnki.net/KCMS/detail/51.1196.TP.20181211.1539.012.html
[28] 刘思, 刘海, 陈启买, 等. 基于网络表示学习与随机游走的链路预测算法[J]. 计算机应用, 2017, 37(8) :2234-2239. (LIU S, LIU H, CHEN Q M, et al. Link prediction algorithm based on network representation learning and random walk [J]. Journal of Computer Applications, 2017, 37(8): 2234-2239.)
[29] 陈维政,张岩,李晓明.网络表示学习[J].大数据,2015,1(3):8-22. (CHEN W Z, ZHANG Y, LI X M. Network representation learning [J]. Big Data Research, 2015, 1(3): 8-22.)
[30] HANLEY J A, MCNEIL B J. The meaning and use of the area under a Receiver Operating Characteristic (ROC) curve [J]. Radiology, 1982, 143(1): 29-36.
[31] CHEBOTAREV P, SHAMIS E. The matrix-forest theorem and measuring relations in small social groups [J]. Automation & Remote Control, 1997, 58(9): 1505-1514.
