基于概要数据结构的全网络持续流检测方法
2019-10-23周爱平朱琛刚
周爱平 朱琛刚


摘 要:持續流是隐蔽的网络攻击过程中显现的一种重要特征,它不产生大量流量且在较长周期内有规律地发生,给传统的检测方法带来极大挑战。针对网络攻击的隐蔽性、单监测点的重负荷和信息有限的问题,提出全网络持续流检测方法。首先,设计一种概要数据结构,并将其部署在每个监测点;其次,当网络流到达监测点时,提取流的概要信息并更新概要数据结构的一位;然后,在测量周期结束时,主监测点将来自其他监测点的概要信息进行综合;最后,提出流持续性的近似估计,通过一些简单计算为每个流构建一个位向量,利用概率统计方法估计流持续性,使用修正后的持续性估计检测持续流。通过真实的网络流量进行实验,结果表明,与长持续时间流检测算法(TLF)相比,所提方法的准确性提高了50%,误报率和漏报率分别降低了22%和20%,说明全网络持续流检测方法能够有效监测高速网络流量。
关键词:网络测量;持续流检测;网络攻击;概要数据结构;概率统计方法
中图分类号: TP393.08
文献标志码:A
Detection method for network-wide persistent flow based on sketch data structure
ZHOU Aiping1,2*, ZHU Chengang3
1.School of Computer Science and Technology, Taizhou University, Taizhou Jiangsu 225300, China ;
2.Key Laboratory of Computer Network and Information Integration of Ministry of Education (Southeast University), Nanjing Jiangsu 211189, China ;
3.School of Computer Science and Engineering, Southeast University, Nanjing Jiangsu 211189, China
Abstract: Persistent flow is an important feature of hidden network attack. It does not generate a large amount of traffic and it occurs regularly in a long period, so that it brings a large challenge for traditional detection methods. Network attacks have invisibility, single monitors have heavy load and limited information. Aiming at the above problems, a method to detect network-wide persistent flows was proposed. Firstly, a sketch data structure was designed and was deployed on each monitor. Secondly, when the network flow arrived at a monitor, the summary information was extracted from network data stream and one bit in the sketch data structure was updated. Thirdly, at the end of measurement period, the summary information from other monitors was synthesized by the main monitor. Finally, the approximate estimation of flow persistence was presented. A bit vector was constructed for each flow by some simple computing, flow persistence was estimated by using probability statistical method, and the persistent flows were detected based on revised persistence estimation. The experiments were conducted on real network traffic, and their results show that compared with the algorithm of Tracing Long Duration flows (TLF), the proposed method increases the accuracy by 50% and reduces the false positive rate, false negative rate by 22%, 20% respectively. The results illustrate that the method of detecting network-wide persistent flows can effectively monitor network traffic in high-speed networks.
Key words: network measurement; persistent flow detection; network attack; sketch data structure; probabilistic statistical method
0 引言
网络流量测量是流量工程、异常检测、用户行为分析等的基础。大流挖掘[1]、超点识别[2]和持续流检测[3-4]一直是网络流量测量的三个重要问题。大流挖掘指在测量周期内从海量网络流量中挖掘流长超过一定阈值的流,大流也称为heavy hitters、elephant flows、frequent items等,如流量计费。超点识别指在测量周期内识别连接数超过一定阈值的节点,如分布式拒绝服务(Distributed Denial of Service,DDoS)攻击检测。持续流检测指在测量周期内检测持续时间超过一定阈值的流,如僵尸网络检测。持续流不同于大流、超点,可能不产生大量流量或建立大量连接,而是在较长周期内有规律地建立连接,往往与异常网络行为相关。因此,传统的网络流量测量方法难以解决持续流检测问题。随着互联网的快速发展和网络应用的多样化,持续产生的网络流给高速网络流量测量带来了诸多挑战。
由于网络攻击者故意在某些时间段内不发送报文,躲避了传统的长持续时间流检测。长持续时间流检测方法只能识别持续不间断的攻击行为,而无法识别隐蔽的网络攻击行为。为了能够检测隐藏的网络攻击行为,需要重新定义持续流测度。持续流表示在测量周期内有规律地发生,而不一定在连续的时间区间内发送报文以及产生大量流量。将测量周期划分为多个时间槽,流的持续性表示流在测量周期内出现的时间槽数量。因此,持续流定义为持续性大于一定阈值的流,即令测量周期为T,时间槽为Ti(0≤i≤d),阈值为,如果流f的持续性满足p(f)>,那么f为持续流。
持续流检测已经引起工业界和学术界的广泛关注。对于网络安全,攻击者可以在较长周期内通过少量的攻击主机降低目标服务器的性能而不使目标服务器瘫痪,持续流检测能够识别隐蔽的DDoS攻击;另外,通过监测僵尸主机与命令控制服务器之间的通信,持续流检测有助于发现网络僵尸主机[5];对于点击诈骗,广告发布商通过自动点击工具周期性地点击广告,从而提高广告发布商的收入而增加广告客户支出,持续流检测有助于识别点击欺骗行为。
持续流检测大致划分为三种类型:1)简单检测方法存储每个流的状态信息。虽然简单检测方法能够准确地检测持续流,但需要消耗大量的系统资源,因此该方法缺乏可扩展性。2)基于抽样的流持续时间估计方法通过流时间间隔分布和流长分布估计流持续时间分布[6]。长持续时间流跟踪方法利用两个Bloom Filter分别存储过去和当前时间区间内候选的活跃长持续时间流,使用Hash表存储识别的长持续时间流,通过抽样过滤大部分的短持续时间流[3]。抽样检测方法只存储抽样流的状态信息。虽然抽样检测方法需要较少的系统资源,但由于检测准确性受到抽样率的影响,降低了检测准确性。
3)长持续时间流检测的数据流方法利用两种数据结构:计数Bloom Filter和Bloom Filter,
不产生漏报且节省内存空间[4]。研究表明傳统的长持续时间流检测在安全监控方面存在严重的不足,攻击者能够轻易躲避检测[7-8]。因此,Shin等[9]提出躲避的长持续时间流检测数据流方法,利用持续性识别躲避的长持续时间流。Lahiri等[10]研究表明持续项的在线检测方法需要大内存,不能运行在单流量监测点上,所以在固定窗口和滑动窗口场景下提出了空间有效的持续项近似跟踪方法。持续项跟踪的分布式方法在无限窗口和滑动窗口场景下能够近似地跟踪持续项,具有低通信开销、低漏报率和低误报率[11]。持续项识别方法首先利用Raptor Code存储每项的标识,然后恢复持续项的标识。该方法利用少量的内存以一定的误报率识别持续项[12]。网络数据流检测方法能够存储每个流的概要信息,保证检测准确性,同时满足存储空间和处理速度的要求。
目前,大部分检测方法通过单监测点分析用户行为,这些分析结论往往具有一定的局限性。而且持续产生的网络流导致单监测点负荷较重,无法及时处理。通常攻击者通过多条路径实施网络攻击,单监测点难以及时准确地识别一些异常行为。
一些攻击者正是利用单监测点的局限性,才能够成功躲避网络安全检测。
因此,只有将多个监测点的分析结果进行综合,才能准确有效地识别异常用户行为。为了能够有效识别异常用户行为,提出了全网络持续流概念。令监测点的数量为k,每个监测点i处理网络流为Si(0 ≤ i ≤ k),网络总流量为S= ∪ k i=0 Si。如果流f在S中出现的时间槽总数高于阈值,那么流f认为是全网络持续流。即使同一个流f多次出现在相同的时间槽,流f的持续性只能增加1。
此外,数据流方法能够将海量网络流量压缩到较小的存储空间并保持一定的精确度,同时具有在线实时处理和有限存储空间的特性。数据流方法通过概要数据结构存储报文的概要信息,如Bitmap[13]、Bloom Filter[14]、Count-Min Sketch[15]、HyperLogLog[6, 16],广泛使用于流长估计[15]、大流识别[17]、流长分布估计[18]、连接度估计[2]等。
传统持续流检测方法一定程度上改善了检测性能,但仍存在不足之处。其一,高速链路上通过大量存储空间维护所有流是不可行的,虽然抽样能够降低存储空间,但持续流估计的准确性依赖于抽样率;其二,网络攻击往往利用大量节点向目标节点发送大量链接,集中式检测方法难以发现此类攻击;其三,为了躲避检测,网络攻击通常不发送大量流量,而是在相当长的时间内间断地发送少量流量,现有检测方法存在较高的误报和漏报。因此,针对传统检测方法的局限性和网络攻击的特点,提出基于概要数据结构的全网络持续流检测方法。多个监测点使用相同的数据结构,对到达的网络流进行信息提取,然后对概要数据结构进行更新。当测量周期结束时,主监测点将来自其他所有监测点的概要信息进行综合。当用户提出查询请求时,估计流的持续性,如果持续性超过设定阈值,进行相应的响应,显示持续流信息。实验利用中国教育和科研计算机网的实际网络流量traces,结果表明本文方法具有良好的检测性能。
1 全网络持续流检测算法
1.1 算法描述
全网络持续流检测(Detect Network-wide Persistent Flows,DPF)包括流处理模块和持续流检测模块:流处理模块主要负责流信息的提取和数据更新,持续流检测模块主要负责持续性估计和持续流检测。当报文流到达监测点时,提取流的相关信息,如源IP地址、目的IP地址、源端口、目的端口、协议类型、时间戳,然后利用流的标识信息更新数据结构。当测量周期结束时,将来自多个监测点的概要信息进行综合,更新主监测点的数据结构。当用户发送查询请求时,进行流的持续性估计,显示持续流信息。首先,为每个流建立一个位向量,统计位向量中0的位数,根据概率统计方法推断流的持续性估计;然后,将持续性估计超过阈值的流识别为持续流。算法的相关定义如下:
定义1
报文流表示顺序到达的报文序列,记为S=p1, p2, …, pi, …,其中pi表示第i个报文,由多个字段构成,如源IP地址、目的IP地址、源端口、目的端口、协议类型、时间戳。
定义2
流f表示具有相同源IP地址、目的IP地址的报文序列,记为P=pi1,pi2,…,pii,…,其中pii表示第i个报文,同样由多个字段构成,也称pii∈f。
定义3
持续性表示流f出现的时间槽数,将测量周期T等分为多个时间槽Ti(0 ≤i≤ d-1),记为p(f)。
定义4
持续流表示在测量周期内持续性大于一定阈值的流集合,即:
F1={f | p(f)>1,pi∈S∩pi∈f}
定义5
假设网络中k个监测点,监测节点i处理报文流Si(0≤i≤k-1),全网络持续流表示在测量周期内持续性大于一定阈值的流集合,即
F2= { f | p(f)>2,pi∈ ∪ k-1 i=0 Si∩pi∈f }
1.2 数据结构
DPF使用的数据结构为位向量 A i(0≤i≤k-1),其大小为m, A i[j](0≤i≤k-1,0≤j≤m-1)是一个比特位,如图1所示。位向量 A i(0≤i≤k-1)共享Hash函数hi(0≤i≤s-1),它将流f映射到 A i(0≤i≤k-1)的某个位置。Hash函数hi(0≤i≤s-1)的定义如式(1):
hi:{0,1,…,N-1}→{0,1,…,m-1}
(1)
其中,N表示地址空间的大小。
测量周期结束后,将来自每个监测点的概要信息进行综合,形成位向量 A ,为每个流f构造一个位向量 B (f),其大小为s, B (f)由随机地选择位向量 A 的s位构成。位向量 B (f)的定义如式(2):
B (f)=( A[h0(f)], A [h1(f)], …, A [hs-1(f)])
(2)
數据结构由位向量 A i构成,其大小为m比特,测量周期内所有流共享位向量 A i。估计流持续性时为每个流f构造一个虚拟位向量,构造s个Hash函数,从位向量 A i中随机均匀地选择s位构成虚拟位向量。因此,不需要为虚拟位向量分配额外存储空间,相同时间槽内属于同一流的所有报文仅需更新位向量 A i中的一位。另外,两个流的虚拟位向量可能共享位向量 A i中相同位,Hash冲突可能产生。然而,因为每个流的虚拟位向量中位是随机选择的,所以选择不同位向量中任意两位的概率是相同的。因此,通过概率统计方法可以估计产生的误差,配置参数降低误差,如m、s。
1.3 流处理
测量周期开始时,对位向量 A 、 A i(0 ≤ i ≤ k-1)进行初始化。当报文流Si到达监测点i时,提取报文的源IP地址、目的IP地址、时间戳,分别表示为s、d、t,将时间戳转换成相应的时间槽,流标识f表示(s, d),构造向量(f, t),这里时间槽也用t表示。然后,计算哈希值h0(t),将位向量中第h0(t) mod s位设置为1,即:
A i[hh0(t) mod s(f)]=1; 0≤i≤k-1
当测量周期结束时,主监测点对来自其他监测点的位向量 A i(0 ≤ i ≤ k-1)进行按位或运算,更新位向量 A ,即:
A [i]= A 0[i] | A 1[i] | … | A k-1[i]; 0 ≤ i ≤ m-1
1.4 持续流检测
当用户发送查询请求时,首先需要估计流的持续性,然后进行持续流检测,对查询请求进行响应。令Ci表示位向量 B (f)的第i位仍为0的随机事件,当Ci发生时,随机变量1Ci的值为1,否则为0。Ci的发生由两个因素决定:1)流f映射到位向量 B (f)的任意位的概率1/m;2)其他流映射到位向量 B (f)的任意位的概率1/s。因此,Ci发生的概率表示如式(3):
P(Ci)=(1-1/m)n-k·(1-1/s)k; 0 ≤i≤s-1
(3)
其中:n表示测量周期内所有流的持续性总和,k表示流f的持续性真实值。
令Vs表示位向量 B (f)中0的比例,Vs的数学期望表示如式(4):
E[Vs]=E ∑ s-1 i=0 1Ci s = 1 s ·E [ ∑ s-1 i=0 P(Ci) ]
(4)
将式(3)代入式(4),得到式(5):
E[Vs]≈e-n/m-k/s
(5)
因此,持续性的真实值k近似表示为式(6):
k≈-s·n/m-s·lnE[Vs]
(6)
令Vm表示位向量 A 中0的比例,Vm的数学期望表示为式(7):
E[Vm]= 1- 1 m n≈e -n m
(7)
式(7)经变换得到式(8):
- n m =ln E[Vm]
(8)
将式(8)代入式(6),得到式(9):
k=s·ln E[Vm]-s·E[ln Vs]
(9)
因此,持续性估计量表示为式(10):
k ^ =s·ln Vm-s·ln Vs
(10)
为了估计流f的持续性,根据式(10),需要统计位向量 A 、 B (f)中0的位数比例Vm、Vs。在此基础上,进行持续流的检测。为了降低持续流的漏报率,即真实的持续流没有被识别,持续性阈值设定为(1-ε),其中ε为误差因子。如果流的持续性估计值大于(1-ε),那么该流被识别为持续流。
由于高速链路上海量网络流量存在,需要大量存储空间维护所有流。另一方面,通常流量流经多个网络节点到达目的节点。为了能够在网络设备上及时准确地检测网络攻击行为,提出基于概要数据结构的全网络持续流检测算法。该算法主要包括流处理和流持续性估计,仅涉及一些Hash计算和多次内存访问,计算复杂度为O(1)。概要数据结构由一个大小为m的位向量构成,为每个流构造的虚拟位向量不占用存储空间,空间复杂度为O(m)。通过分析发现持续性估计量是极大似然估计。因此,该算法能够有效提取流的概要信息,同时保证一定的流持续性估计精度,满足高速网络流量监测应用需求。
2 实验分析
2.1 数据集
为了验证DPF方法的有效性,实验使用真实流量traces[19],其采集于中国教育和科研计算机网的边界路由器。所有报文经过匿名化处理,仅包含首部信息。该流量traces持续3min,包含3102550个报文,41957个不同的源IP地址,45432个不同的目的IP地址,111958个不同流。实验通过多线程技术模拟多个监测点,其中一个担当主监测点;时间槽为1s。图2显示了流持续性的分布,大约87%流的持续性小于10,大约0.5%流的持续性大于100,表明大部分流的持续性较小,少部分流的持续性较大。
从估计准确性、检测精度方面将DPF方法与相关方法TLF(Trace Long Flows)[3]、DLF(Detect Long Flows)[4]进行比较。TLF算法使用两个Bloom Filter数据結构分别存储过去和当前时间区间内候选的活跃长持续时间流,使用Hash表存储识别的长持续时间流,通过抽样过滤大部分短持续时间流,降低了存储开销,提高了识别精度。DLF算法使用计数Bloom Filter和Bloom Filter数据结构,在测量时间周期内更新计数Bloom Filter,测量时间周期结束后更新Bloom Filter,进一步提高了识别精度。通过相对误差评价持续性估计的准确性,通过漏报率和误报率评价持续流的检测精度。在实验对比过程中,需要知道实际的持续流,表1显示了不同阈值下实际的持续流,其中SIP(Source Internet Address)表示源IP地址,DIP(Destination Internet Address)表示目的IP地址。
2.2 估计准确性
首先,分析持续性的估计误差。通过相对误差分析参数s对估计精度的影响。相对误差定义如式(11):
δ= | k ^ -k | k ×100%
(11)
将式(10)代入式(11),并用E[Vm]、E[Vs]分别代替Vm、Vs,得到式(12)。
δ= | ln 1- 1 s ·s-ln 1- 1 m ·s-1 | ×100%
(12)
由图3可知,当m一定时,持续性估计的相对误差随着参数s的增加而降低,当s > 50时,持续性估计的相对误差δ小于1.0%。因此,通过调整参数s可以提高持续性估计的准确性。
其次,比较三种方法的持续性估计值。由图4可知,横坐标表示持续性的真实值,纵坐标表示持续性的估计值,持续性估计值分布于对角线两侧。与其他两种方法相比,通过DPF方法得到持续性估计值更接近对角线,表明DPF方法具有更高的估计准确性,归因于相等内存下DPF方法的冲突率明显低于其他两种方法。
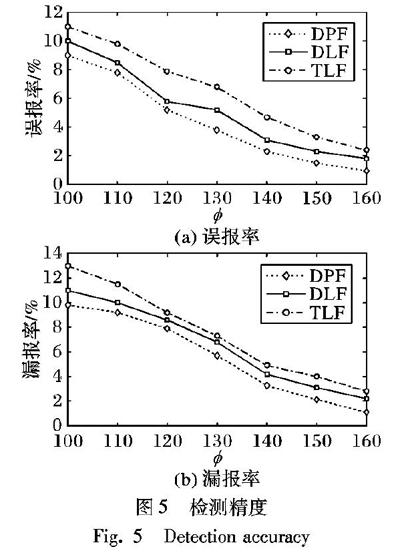
2.3 检测精度
从误报率和漏报率两方面评价方法的检测精度:误报率fpr(false positive rate)指错误识别的持续流在总识别的持续流中的比例;漏报率fnr(false negative rate)指没有识别的持续流在实际持续流中的比例。因此,误报率和漏报率定义如式(13)、式(14):
fpr= | B-A | / | B |
(13)
fnr= | A-B | / | A |
(14)
其中:实际的持续流集合为A,总识别的持续流集合为B。
图5显示了三种方法在不同阈值下的误报率和漏报率。由图5可知,随着阈值的增加,三种方法的误报率和漏报率逐渐下降。然而,与其他两种方法相比,DPF方法具有更低的误报率和漏报率,表明它具有良好的检测精度。
2.4 參数影响
从上述分析可知,位向量 B 的大小s是持续性估计的重要影响因素,因此,分析s对检测精度的影响。图6显示了参数s与误报率、漏报率之间的关系。由图6可知,随着s增加,误报率、漏报率逐渐降低,表明s也是影响DPF方法检测精度的重要参数。理论上,随着参数s增加,DPF方法的检测精度逐渐提高,可能导致时间复杂性增加和冲突率提高。在内存一定的条件下,调整参数s,使得满足持续流检测精度要求。
Fig. 6 Influence of size s of bit vector B on detection accuracy
3 结语
为了躲避检测,网络攻击者在较长周期内有规律地发动攻击,导致传统的检测方法失效。针对负荷重、信息局限性以及网络攻击的隐蔽性,提出基于概要数据结构的全网络持续流检测方法。首先,监测点通过概要数据结构提取网络流的概要信息,测量周期结束时,主监测点对来自其他监测点的概要信息进行综合。然后,当用户发送查询请求时,通过概率统计方法估计流的持续性,依据持续性估计检测持续流。然而,全网络持续流检测方法只进行了一些简单计算和内存访问操作。实验结果表明,与相关检测方法相比,本文方法能够有效地识别持续流,有助于检测隐蔽的网络攻击。
参考文献
[1] 赵小欢,夏靖波,付凯,等.高速网络流频繁项挖掘算法[J].计算机研究与发展,2014,51(11):2458-2469. (ZHAO X H, XIA J B, FU K, et al. Frequent items mining algorithm over network flows at high-speed network [J]. Journal of Computer Research and Development, 2014, 51(11): 2458-2469.)
[2] LIU W, QU W, GONG J, et al. Detection of superpoints using a vector bloom filter [J]. IEEE Transactions on Information Forensics and Security, 2016, 11(3): 514-527.
[3] CHEN A, JIN Y, CAO J, et al. Tracking long duration flows in network traffic [C]// Proceedings of the 2010 International Conference on Information Communications. Piscataway, NJ: IEEE, 2010: 206-210.
[4] LEE S, SHIN S, YOON M. Detecting long duration flows without false negatives [J]. IEICE Transactions on Communications, 2011, 94(5): 1460-1462.
[5] GIROIRE F, CHANDRASHEKAR J, TAFT N, et al. Exploiting temporal persistence to detect covert botnet channels [C]// Proceedings of the 2009 International Workshop on Recent Advances in Intrusion Detection, LNCS 5758. Berlin: Springer, 2009: 326-345.
[6] HEULE S, NUNKESSER M, HALL A. HyperLogLog in practice: algorithmic engineering of a state of the art cardinality estimation algorithm [C]// Proceedings of the 16th International Conference on Extending Database Technology. New York: ACM, 2013: 683-692.
[7] ZHOU Y, ZHOU Y, CHEN M, et al. Persistent spread measurement for big network data based on register intersection [J]. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 2017, 1(1): No.15.
[8] XIAO Q, QIAO Y, ZHEN M, et al. Estimating the persistent spreads in high-speed networks [C]// Proceedings of the 22nd IEEE International Conference on Network Protocols. Piscataway: IEEE, 2014: 131-142.
[9] SHIN S, YOON M. Virtual vectors and network traffic analysis [J]. IEEE Network, 2012, 26(1): 22-26.
[10] LAHIRI B, CHANDRASHEKAR J, TIRTHAPURA S. Space-efficient tracking of persistent items in a massive data stream [C]// Proceedings of the 5th International Conference on Distributed Event-based System. New York: ACM, 2011: 255-266.
[11] SINGH S A, TIRTHAPURA S. Monitoring persistent items in the union of distributed streams [J]. Journal of Parallel and Distributed Computing, 2014, 74(11): 3115-3127.
[12] DAI H, SHAHZAD M, LIU A X, et al. Finding persistent items in data streams [J]. Proceedings of the VLDB Endowment, 2016, 10(4): 289-300.
[13] STAN C, VARGHESE G, FISK M. Bitmap algorithms for counting active flows on high-speed links [J]. IEEE/ACM Transactions on Networking, 2006, 14(5): 925-937.
[14] KUMAR A, XU J, WANG J. Space-code bloom filter for efficient per-flow traffic measurement [J]. IEEE Journal on Selected Areas in Communications, 2006, 24(12): 2327-2339.
[15] CORMODE G, MUTHUKRISHNAN S. An improved data stream summary: the count-min sketch and its applications [J]. Journal of Algorithms, 2005, 55(1): 58-75.
[16] FLAJOLET P, FUSY , GANDOUET O, et al. HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm [J]. Discrete Mathematics and Theoretical Computer Science, 2007, 28(3): 127-146.
http://pdfs.semanticscholar.org/75ba/51ffd9d2bed8a65029c9340d058f587059da.pdf
[17] HUANG Q, LEE P P C. A hybrid local and distributed sketching design for accurate scalable heavy key detection in network data streams [J]. Computer Networks: The International Journal of Computer and Telecommunications Networking, 2015, 91(C): 298-315.
[18] ANTUNES N, PIPIRAS V. Estimation of flow distributions from sampled traffic [J]. ACM Transactions on Modeling and Performance Evaluation of Computing Systems, 2016, 1(3): No.17.
[19] IP Trace And Service [DS/OL]. [2018-11-20]. http://iptas.edu.cn/src/system.php.
