基于多特征融合的恶意代码分类算法
2019-10-23郎大鹏丁巍姜昊辰陈志远
郎大鹏 丁巍 姜昊辰 陈志远


摘 要:针对多数恶意代码分类研究都基于家族分类和恶意、良性代码分类,而种类分类比较少的问题,提出了多特征融合的恶意代码分类算法。采用纹理图和反汇编文件提取3组特征进行融合分类研究,首先使用源文件和反汇编文件提取灰度共生矩阵特征,由n-gram算法提取操作码序列;然后采用改进型信息增益(IG)算法提取操作码特征,其次将多组特征进行标准化处理后以随机森林(RF)为分类器进行学习;最后实现了基于多特征融合的随机森林分类器。通过对九类恶意代码进行学习和测试,所提算法取得了85%的准确度,相比单一特征下的随机森林、多特征下的多层感知器和Logistic回归算法分类器,准确率更高。
关键词: 恶意代码;纹理特征;操作码序列;随机森林;静态分析
中图分类号: TP309
文献标志码:A
Malicious code classification algorithm based on multi-feature fusion
LANG Dapeng1,2, DING Wei1*, JIANG Haocheng1, CHEN Zhiyuang1
1.College of Computer Science and Technology,Harbin Engineerning University, Harbin Heilongjiang 150001, China ;
2.Key Laboratory of Network Assessment Technology, Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China
Abstract: Concerning the fact that most malicious code classification researches are based on family classification and malicious and benign code classification, and the classification of categories is relatively few, a malicious code classification algorithm based on multi-feature fusion was proposed. Three sets of features extracted from texture maps and disassembly files were used for fusion classification research. Firstly, the gray level co-occurrence matrix features were extracted from source files and disassembly files and the sequences of operation codes were extracted by n-gram algorithm. Secondly, the improved Information Gain (IG) algorithm was used to extract the operation code features. Thirdly, Random Forest (RF) was used as the classifier to learn the multi-group features after normalization. Finally, the random forest classifier based on multi-feature fusion was realized. The proposed algorithm achieves 85% accuracy by learning and testing nine types of malicious codes. Compared with random forest under single feature, multi-layer perceptron under multi-feature and Logistic regression classifier, it has higher accuracy.
Key words: malicious code; texture feature; opcode sequence; Random Forest (RF); static analysis
0 引言
隨着互联网技术的迅速发展,恶意软件增长的速度越来越快,其主要原因是由于加壳、混淆、反沙箱、虚拟穿透等技术的兴起与普及,使传统的恶意软件分析技术受到了很大阻碍。分析技术分为静态分析和动态分析两种[1]:静态分析技术主要是通过对文件结构进行静态分析从而获取到文件的恶意特征,无须通过执行程序来判断是否是恶意软件,常用的静态特征检测通常利用文件信息结构、控制流图、静态信息增益(Information Gain, IG)等进行检测;动态方法主要是通过跟踪代码运行时的行为轨迹来判断是否是恶意软件。
1 研究背景
早期与恶意样本相关的一些研究工作主要关注如何鉴别正常软件和恶意软件,如2001年,Schultz等[2]通过使用朴素贝叶斯检测恶意样本,主要利用的特征是字符串序列、动态链接库序列、系统调用等三种典型特征,在他们所使用的数据集上达到了较高的准确率;但由于反分析技术越来越成熟,最初的研究技术已经无法满足需求。
2005年,Christodorescu等[3]提出了静态分析恶意代码混淆技术的思想,利用控制流图作为特征,但不能应对大量出现的恶意程序的混淆变种。
2006年,Kolter等[4]提取二进制可执行文件的N元字节序列作为实验特征,并取得了较好的实验结果,之后这种特征被多次使用和改进。
目前许多工具都能够可视化和操作二进制数据,例如常用的文本编辑器和二进制编辑器。2011年,Nataraj等[5]就提出了将恶意软件转换成可执行文件对应的灰度纹理图,再利用灰度纹理图生成的Gist特征向量,利用k最近邻(k-NearestNeighbor, kNN)算法进行分类;
2014年,韩晓光等[6]又再次对纹理图进行恶意代码的研究,从中提取出灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM)特征,通过位置敏感哈希函数(Location Sensitive Hash, LSH)聚类研究验证了所提方法的有效性;
2015年,在微软kaggle分类大赛[7]中,得到冠军的队伍使用的特征就包括文件图像化特征和深层汇编特征,他们提取了文件转换为图片后的前1500个像素作为特征,虽然他们自己也不知道为什么这么做能得到这么好的分类效果,但也说明了图片分类在恶意软件分类领域是有效的。
對恶意代码分类算法的研究已有很长的一段历史,但随着恶意代码的加密、混淆技术的不断成熟,使得以往研究技术的准确率在不断下降,因此越来越多的人尝试利用已有特征提出不同的分析方法在研究中寻找突破。
Zhang等[8]提取n-gram字节码序列值,利用相似度的方法得到字节码序列的特征向量,再求向量的平均值,发现恶意软件和良性软件的特征向量平均值存在比较大的差异;但只能在恶意和良性样本中检测有效,在种类分类中准确率低。
Kwon等[9]提取应用程序编程接口(Application Programming Interface, API)调用序列和n-gram操作码序列,再利用深度学习多特征融合的特点对恶意家族进行分类,但类别较多时效果不理想。
Fu等[10]在原有的灰度纹理图基础上加了一层颜色属性,对可移植的可执行的文件(Portable Executable, PE)结构的不同区块加上不同的颜色,提取共生矩阵特征、颜色特征还有不同区块的哈希值对恶意家族进行分类,取得了不错的效果。
Ding等[11]提取n-gram操作码序列,基于深度信念网络对恶意软件进行分类,证明了深度学习在恶意软件分类中的效果会比一般的机器学习分类效果好;但该实验样本源于2015年的kaggle比赛,这些比赛的样本并没有恶意样本源文件,只有经过加工的反汇编文件和16进制文件,因此其样本分类不能算严格意义上的恶意代码分类。
李雪虎等[12]通过利用API调用序列作为恶意代码分类,利用随机森林(Random Forest, RF)效率高的特点对90万个样本进行分类,证明了样本数量越多时分类成功率越高;但该实验的样本只分为3类,API调用序列提取还需要白箱等工具,较为麻烦。
通过以上研究可知,多数恶意代码研究都只集中于恶意代码、良性代码的检测和家族分类,而恶意代码种类的分类较少,特别是基于静态分析的恶意代码分类。恶意代码分类存在的问题有:1)动态分析周期较长、较复杂,不适合大量的恶意代码分类;2)由于加密技术的日益成熟,PE文件特征提取需要解决的问题越来越困难;3)由于反静态分析技术越来越成熟、恶意样本日益多样化使得原有的特征选择性越来越差。针对现有研究方法的不足,本文提出了多特征的方法对恶意代码进行分类。
1 特征与算法
1.1 共生矩阵特征
灰度共生矩阵是一种通过研究灰度的空间相关特性来描述纹理的常用的方法。共生矩阵由两个位置的像素的联合概率密度来定义,它不仅反映亮度的分布特征,还反映具有同样亮度或者接近亮度的像素之间的位置分布特性,是有关图像亮度变化的二阶统计特征,也是定义一组纹理特征的基础。
由于纹理是由灰度在空间位置上反复出现而形成的,因而在图像空间中相隔某距离的两像素之间会存在一定的灰度关系,即图像中灰度的空间相关特性。灰度共生矩阵就是一种通过研究灰度的空间相关特性来描述纹理的常用方法。灰度直方图是对图像上单个像素具有某个灰度进行统计的结果,而灰度共生矩阵是对图像上保持某距离的两像素分别具有某灰度的状况进行统计得到的。
1.2 Gist特征
全局特征信息又称为“Gist”信息[13],是场景的低维签名向量。采用全局特征信息对场景进行识别与分类不需要对图像进行分割和局部特征提取,可以实现快速场景识别与分类。Oliva等[14]提出的Gist特征是一种生物启发式特征,该特征模拟人的视觉,形成对外部世界的一种空间表示,捕获图像中的上下文信息。Gist特征通过多尺度多方向Gabor滤波器组对场景图像进行滤波,将滤波后的图像划分为4×4的网格,然后各个网格采用离散傅里叶变换和窗口傅里叶变换提取图像的全局特征信息。
1.3 n-gram提取操作码特征
在计算语言和统计学领域,n-gram是指令文本中连续的n个项目。n-gram算法是基于一种假设:第n个词出现与前n-1个词相关。假设对操作码序列push、mov、mov、push、xor、cmp、jbe进行n-gram特征提取,2-gram提取的操作码序列为{push, mov},{mov, mov},{mov, push},{push, xor}{xor, cmp},{cmp, jbe};3-gram提取的操作码序列为{push, mov, mov}, {mov, mov, push}, {mov, push, xor}, {push, xor, cmp},{xor, cmp, jbe};4-gram提取的操作码序列为{push, mov, mov, push},{mov, mov, push, xor},{mov, push, xor, cmp},{push, xor, cmp, jbe},以此类推,而特征值表示特征操作码序列出现的次数。本文利用递归反汇编算法对文件进行反汇编预处理,反汇编是将目标代码转为汇编代码的过程。
1.4 随机森林
随机森林[15]是采用多个决策树的投票机制来改善决策树的方法,由多个决策树构成森林,算法的分类结果由这些决策树投票得到。
决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(Bootstraping)得到训练数据,列方向上采用无放回随机抽样得到特征子集,并据此得到其最优切分点,这便是随机森林算法的基本原理。
2 算法实现
2.1 代码检测模型
基于纹理图特征和操作码序列特征的恶意软件的检测模型分为训练和检测两个阶段,如图1所示。
分类器的实现主要分为样本预处理、特征提取和训练分类器三个阶段,如图2所示。
样本预处理 用于改变文件的表示形式,本文采用的特征不是从源文件中提取的特征,因此需要对源文件作初步的处理才能进行特征提取,本文使用的工具和方法为交互式反汇编器专业版(IDA Pro)和纹理图生成技术。
特征提取 依据Gist算法和GLCM算法对纹理图进行特征提取,利用n-gram提取操作码序列后,再使用信息增益方法对排列的特征进行特征选择。
训练分类器 主要是实现分类器,考虑到提取的特征不同,差异比较大,本文首先对多特征实现的特征矩陣进行标准化处理,再投入到随机森林中进行训练,将训练好的分类器投到测试样本中进行恶意代码种类划分,分析结果。
2.2 特征提取
样本预处理阶段分为反汇编和生成纹理图两个步骤。
第一步,对原有的恶意样本进行批量反汇编处理,生成反汇编文件Asm文件,反汇编文件主要由汇编语言和部分定义组成。
第二步,利用纹理图生成技术将文件代码生成灰度纹理图(如图3)。以8bit为一个无符号的整型(范围为0~255),固定的行宽为一个向量,整个文件最后生成一个二维数组。将此数组可视化为一个灰阶图像,该二维数组中每个元素的范围为0~255,正好为灰度图像中每个像素的取值范围,即每个数组元素对应图像中的一个像素,本文采用的纹理图以256像素为行宽度,总像素除以行宽度为列高度,图4是md5为0a28b556b4b6998265fa9fe649554533的源文件生成的纹理图和反汇编文件生成的纹理图。
样本提取的特征包括纹理图特征和操作码序列特征。利用Gist、GLCM特征提取算法对已生成的图片进行特征提取,提取出Gist特征集和GLCM特征集,反汇编文件和源文件一共可以提取出4组特征集,太多的特征集不一定会对恶意样本的分类有帮助,因此需要通过实验选择最好的特征集。通过4组特征反复地组合投入到随机森林中进行检测实验,选出分类成功率最高的特征集。操作码序列特征需要将文件所有的操作码提取出来,再利用n-gram算法提取特征,本文将2-gram、3-gram、4-gram、5-gram提取的操作码序列特征投入到随机森林算法中进行比较,通过实验选出分类效果最好的n值。为提高操作码序列的准确性,本文采用信息增益的方法对n-gram操作码序列进行排序,再选择前数个操作码序列作为分类的特征属性。
信息增益公式:
IG(Y | X)=H(Y)-H(Y | X)
(1)
其中:
H(X)=-∑ n i=1 p(xi)logb p(xi)
(2)
H(Y | X)=∑ x p(x)H(Y | X=x)
(3)
H(X)表示的是熵,p(x)表示特征x出现的概率。熵可以表示样本的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对样本集合D划分效果的好坏,H(Y | X)表示划分后的熵。H(Y | X)越小说明使用此特征划分得到的子集的不确定性越小,因此H(Y)-H(Y | X)差异越大,说明使用当前特征划分数据集D,其不确定性越小,反之不确定越大。
2.3 融合分类
将多类特征融合成矩阵后,会存在提取的值相差较大的情况,有些值在1000左右,而有些值在0到1之间。为了防止较大的数据差异,本文最后对合成的特征矩阵进行了标准化处理。标准化处理只是用于数值的缩放,使得所有特征在同一量纲下进行数据处理,避免有些特征整体偏大对整体处理造成偏差。例如MD5为002d9c1c804bd26e362c89b1042b319 提取的特征之一的contrast值为1684.17,而提取的energy值只有0.107。通过计算特征标准差为685.5,平均值为285。标准化处理后的contrast值为2.04,energy值为-0.415。
z=(x-μ)/δ
(4)
其中:其中δ代表标准差,μ代表的是平均值。数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间,使不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
本文利用随机森林为分类器进行分类研究,随机森林对特征集使用Bootstraping方法随机有放回采样选出k个样本集,共进行k次采样,生成k个训练集。对每个不同的训练集利用决策树进行训练,生成k棵决策树组成的随机森林,对于最终的分类问题,按多棵树分类器投票决定最终分类结果,由多棵树预测值的均值决定最终预测的结果,如图5所示。
3 实验及结果分析
3.1 实验样本和度量指标
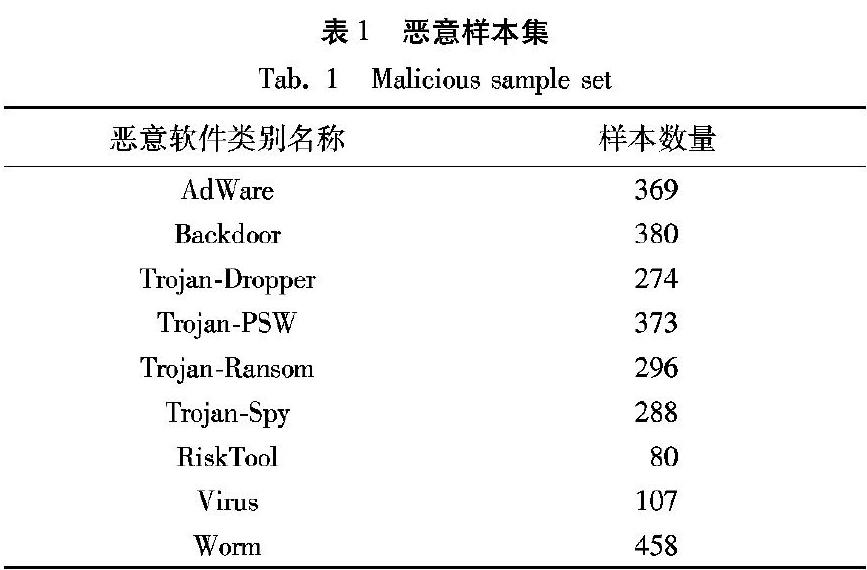
本文实验样本来源malwaredb(http://malwaredb.malekal.com/)筛选的2625个恶意代码组成的数据集,分为9类,恶意样本的分类较多,包括后门、逻辑炸弹、特洛伊木马、蠕虫、细菌、病毒等,本文筛选的样本主要分为广告类(AdWare)、后门类(Backdoor)、木马类(Trojan)、风险工具(RiskTool)、蠕虫(Worm)、病毒(Virus)类,样本分类以卡巴斯基的分类标准为依据。本文还对恶意样本进行了细分,筛选了木马样本中的4类样本进行实验,包括Trojan-Dropper、Trojan-PSW、Trojan-Ransom和Trojan-Spy。恶意软件的分类情况如表1所示。
[2]SCHULTZ M, ESKIN E,ZADOK E, et al. Data mining methods for detection of new malicious executables [C]// Proceedings of the 2001 IEEE Symposium on Research in Security and Privacy. Piscataway, NJ: IEEE, 2001: 38-49.
[3]CHRISTODORESCU M, JHA S, SESHIA S A, et al. Semantics-aware malware detection [C]// Proceedings of the 2005 IEEE Symposium on Security and Privacy. Piscataway, NJ: IEEE, 2005: 32-46.
[4] KOLTER J Z, MALOOF M A. Learning to detect and classify maliciousexecutables in the wild [J]. Journal of Machine Learning Research, 2006, 7(1): 2721-2744.
[5] NATARAJ L, KARTHIKEYAN S, JACOB G, et al. Malware images: visualization and automatic classification[C]// Proceedings of the 8th International Symposium on Visualization for Cyber Security. New York: ACM, 2011: No.4.
[6] 韓晓光,曲武,姚宣霞,等.基于纹理指纹的恶意代码变种检测方法研究[J].通信学报,2014,35(8):125-136. (HAN X G, QU W, YAO X X, et al. Research on malicious code variant detection method based on texture fingerprint [J]. Journal on Communications, 2014, 35(8): 125-136.)
[7] BINDOG. GitHub [EB/OL]. [2018-08-18]. https://github.com/bindog/ToyMalwareClassification/.
[8] ZHANG F, ZHAO T. Malware detection and classification based on n-grams attribute similarity [C]// Proceedings of 2017 IEEE International Conference on Computational Science and Engineering and IEEE International Conference on Embedded and Ubiquitous Computing. Washington, DC: IEEE Computer Society, 2017: 793-796.
[9] KWON I, IM E G. Extracting the representative API call patterns of malware families using recurrent neural network [C]// Proceedings of the 2017 International Conference on Research in Adaptive and Convergent Systems. New York: ACM, 2017: 202-207.
[10] FU J, XUE J, WANG Y, et al. Malware visualization for fine-grained classification [J]. IEEE Access, 2018, 6: 14510-14523.
[11] DING Y, ZHU S. Malware detection based on deep learning algorithm [J]. Neural Computing and Applications, 2017, 31(2): 461-472.
[12] 李雪虎,王发明,战凯.基于大样本的随机森林恶意代码检测与分类算法[J].信息技术与网络安全,2018,37(7):3-5,21. (LI X H, WANG F M, ZHAN K. Large sample-based random forest malicious code detection and classification algorithm [J]. Information Technology and Network Security, 2018, 37(7): 3-5,21.)
[13] 潘良敏.基于GIST全局特征的钓鱼网站聚类算法研究[D].长沙:中南林业科技大学,2018:1-58. (PAN L M. Research on phishing website clustering algorithm based on the global characteristics of GIST [D]. Changsha: Central South University of Forestry and Technology, 2018: 1-58.)
[14] OLIVA A, TORRALBA A. Modeling the shape of the scene: a holistic representation of the spatial envelope [J].International Journal of Computer Vision,2001,42(3):145-175.
[15] 戴逸辉,殷旭东.基于随机森林的恶意代码检测[J].网络空间安全,2018,9(2):70-75. (DAI Y H, YIN X D. Malicious code detection based on random forest [J]. Cyberspace Security, 2018,9(2):70-75.)
