位置隐私保护的虚拟轨迹填充算法
2019-10-23付宇王红
付宇 王红


摘 要:针对位置隐私保护中路网环境和欧氏空间环境对移动对象不同的约束限制,提出一种适用于这两类不同空间约束特点的虚拟轨迹填充算法。该算法接管了用户与位置服务提供者之间的交互,并构建了虚拟用户轨迹对真实轨迹进行混淆填充,从而实现了真实轨迹的隐藏和保护。首先,对目标区域进行分区和汇聚点提取;随后,以汇聚点为基础进行轨迹分段和虚拟轨迹的生成;最后,通过构建时序预置算法和轨迹混淆填充算法实现了虚拟轨迹的合理分布,增加了将轨迹信息关联到特定目标对象的难度。实验结果表明,所提算法能够在每用户15次以内的填充后将位置隐私披露风险概率从60%下降并稳定在10%左右,轨迹隐私披露概率从50%下降并稳定在6%左右,能达到较好的位置隐私保护的效果。
关键词:基于位置的服务;路网环境;位置隐私保护;虚拟轨迹;汇聚点
中图分类号: TP309.2
文献标志码:A
Virtual trajectory filling algorithm for location privacy protection
FU Yu*, WANG Hong
College of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China
Abstract: In view of the different constraints on the moving objects between road network environment and Euclidean space environment, a virtual trajectory filling algorithm was proposed, which was applicable to both constraints. The interaction between the user and the provider of Location-Based Services (LBS) was taken over by the algorithm, and virtual user trajectory was constructed to confuse and fill the real trajectory, realizing the hiding and protection of the real trajectory. Firstly, the target region was partitioned and the points of convergence were extracted. Then, the trajectory segmentation and virtual trajectory were generated based on the convergence points. Finally, the reasonable distribution of the virtual trajectory was achieved by constructing the timing preset algorithm and the trajectory confusion filling algorithm, which increased the difficulty of associating the trajectory information with a specific target object. Experimental results show that after less than 15 virtual trajectories per user being filled, the probability of the location privacy disclosure of the target object is dropped from 60% to and stabilizes at around 10%, and the trajectory privacy disclosure probability is decreased from 50% to and stabilizes at about 6%, achieving good effect of location privacy protection.
Key words: Location-Based Service (LBS); road network environment; location privacy protection; virtual trajectory; convergence point
0 引言
基于位置的服務(Location-Based Service,LBS)是智能交通系统中各项综合性交通运输管理服务的基础,其基本形式是客户端将用户身份标志号(IDentity,ID)、当前时刻、当前位置、将要前往的兴趣点(Point Of Interest,POI)等数据发往LBS的服务提供端,然后期待后者返回兴趣点的位置和导航路径等[1-2]。攻击者如果获得这些信息则能够挖掘出用户的兴趣、爱好、健康状况等私人敏感信息,从而造成隐私泄露[3-5]。对于部分人员和场合而言,位置隐私泄露甚至超过定位精度成为客户在接受智能交通服务时最为关心的问题。
目前的位置隐私保护方法主要包括K-匿名法和L-多样性法等[6-8]。K-匿名法[9-10]将K个邻近的移动对象泛化为 一个整体区域从而使得攻击者无法将这K个对象单个区分开来;但该方法的位置服务精度不高,而且当区域内对象过于集中时较易暴露目标对象的大概位置。
L-多样性法[11-12]是将泛化技术作用于查询内容,使攻击者不能将其与特定对象关联起来。这两类方法主要适用于欧氏空间,而现实中的LBS应用更多地存在于路网空间。对象的运动方向在欧氏空间中几乎不受限,而路网环境下只能沿路径方向。若将上述方法直接用于路网环境,由于可供猜测的空间大为减少,先前有效的方法在路网环境下被破解的可能性会增加[13-14]。本文提出的虚拟轨迹填充算法能够在避免位置服务精度损失的同时,实现路网与欧氏空间通用环境下的位置隐私保护。
1 问题描述
路网模型可表示为一个无向图 G 〈 V , E 〉。其中: V 包括了路网中的端点和交叉点,起始点和兴趣点属于其子集; E 代表边集,e=〈vi, vj〉∈ E ,指两点间的路段。通常基于位置的服务涉及客户端user和服务提供端LBS provider。客户端先向服务端发送兴趣点位置请求,服务端则发回从当前位置到兴趣点的路径;运行一段时间后,LBS服务端能够积累大量的与用户ID关联的足迹信息,如图1(a)所示。假定攻击者对LBS服务端的用户轨迹信息具有持续观察能力,则攻击者较容易从中抽取出某个ID的轨迹,如图1(b)所示。
本文的出发点是尽可能增加攻击者通过历史轨迹信息挖掘出真实用户身份的难度。对攻击者而言,在LBS服务端能够得到的数据包括:1)某ID在地图上在某时刻的位置以及其关心的兴趣点;2)某ID形成的轨迹;3)不同时刻兴趣点所形成的目标集合。
然而即便拥有这些信息,攻击者能否正确关联出目标对象,仍存在以下不确定性:1)通过ID不能简单对应到某个真实用户;2)服务端收到的位置点坐标可能经过了刻意模糊或干扰;3)轨迹可能是杂乱无章的——轨迹和ID的对应关系经过了某种变换。
K-匿名法就是利用了上述中的第2)点,位置信息经过了匿名后成为模糊的信息,从而不再能够通过位置来区分不同的用户[15-16]。但对于用户密度较高的区域,经匿名后,其位置信息并没有获得足够的模糊化。本文提出的虚拟轨迹填充算法综合利用了另外两种不确定性来避免这一缺陷。
2 虚拟轨迹填充算法
如图2所示,整个虚拟轨迹填充系统涉及三个对象:客户端user、位置隐私保护服务器(Location Privacy Protection Server,LPPS)和LBS服务端, 主要的虚拟轨迹填充功能由介于客户端和LBS服务端之间的位置隐私保护服务器LPPS完成。算法总体分为离线预处理、汇聚点提取和轨迹填充三个阶段。
2.1 离线预处理阶段
离线预处理为数据训练阶段,主要完成以下三项工作:1)为隐私保护服务器LPPS建立目标区域的基本路网结构;2)根据历史交通流量信息产生交通汇聚点列表;3)针对目标区域生成分区模板。图3给出了一个针对图1的分区示例,空间划分为两个中央分区(分区1和2)以及4至8个周边分区(图中的分区3至8)。每个分区包含一个分区汇聚点,分区及分区汇聚点的确定在汇聚点提取阶段进行绑定。中央分区一般包含流量较大的汇聚点,并且对周边分区具有较好的可达性。两个中央分区中的一个为真实对象所经过,而另一个中央分区为填充的虚拟对象汇聚所用。两个中央分区的设置增加了攻击者破解真实轨迹的难度。
2.2 汇聚点提取阶段
在图2中,用户user首先发出的一个POIA兴趣点服务请求给隐私保护服务器LPPS。
图2中各步骤具体操作如下:
(1)发送查询q=〈IDuser, T, LOCuser, POI〉;
(2)初步预测轨迹并对之分段,对原始ID和POI进行混淆保护;
(3)发送保护后的q′=〈ID_temporary_user, T, LOC_temporary_user, POI′〉;
(4)返回POI′的路径信息;
(5)进行分区绑定,确定路径关键汇聚点list_of_candidate_point;
(6)根据起始时间、运动速度,对user关键汇聚点预置时序(算法1);
(7)将主轨迹的起点、关键汇聚点序列、兴趣点填入new_query_list;
(8)进行主轨迹填充,将汇聚点按时序放入待混淆列表mix_list;
(9)从mix_list取出表头节点进行虚拟轨迹填充(算法2);
(10)对填充中产生的汇聚点预置时序;
(11)判断是否需要进行均衡填充,若是,则将新产生的汇聚点按时序放入mix_list;
(12)将虚拟轨迹的起点、关键汇聚点序列、兴趣点填入new_query_list,并返回(9)进行循环,直到mix_list列表被取空;
(13)依次取出new_query_list中的每個节点,对进入该节点的轨迹进行ID混淆(算法3),随后根据这些节点对构造新的〈LOC, POIX〉请求;
(14)发送新请求fq=〈ID_F_user, T, LOC_F_user,POIX〉;
(15)为所有请求计算并返回〈LOC_F_user,POIX〉.route;
(16)恢复用户user真实请求的POI与路径;
(17)将恢复后的结果返回给终端用户。
对LPPS而言,在接到请求后先对用户ID和POI进行保护,见图2中第(1)、(2)步,保护措施包括初步预测用户轨迹并进行原始请求变换。随后在第(3)步将变换后的请求转发给LBS服务者。在得到返回的相关兴趣点位置后,LPPS将根据客户端当前位置、兴趣点目的地位置以及预处理阶段建立起来的路网结构和汇聚点信息,在第(5)步进行分区绑定,并确立目标轨迹的候选汇聚点列表list_of_candidate_point。
分区绑定时将根据候选汇聚点列表中的真实对象轨迹对预处理时生成的分区模板进行调整,使得真实轨迹中除起始节点和目标节点外的中间汇聚点至少有一个落在中央分区(如图3的分区1或2)中,而其他汇聚点按时间先后顺序分别落入不同的周边分区。绑定过程中,从真实轨迹在每个分区的候选汇聚点中选择一个作为分区汇聚点,并最终形成待混淆列表mix_list,其内容为list_of_candidate_point的子集,是虚拟轨迹注入并发生ID交换的地方。这里的中央分区是针对真实轨迹的中间段而言的,非地理中央概念。当真实轨迹偏置于地图某一边角地区时,中央分区亦需跟随调整,此时可能在某个方向没有周边分区。
随后在图2第(6)步中依据移动对象的起始时间和运动速度调用route_timing算法(算法1)设定候选汇集点的到达时序,这里list_of_candidate_point列表作为输入,与算法中的route_list列表进行合一。算法流程如下:待填充的路径放在route_list路由列表中,并且从基准点开始,分别向前填充前序路径(算法1步骤2))和向后填充后继路径(算法1步骤3))。填充需要以当前节点(cur_node)、到达当前节点时刻(node.time)和目标对象的运动速度speed[user_id]为输入,得到对象到达下一节点的时刻。
算法1 route_timing。
程序前
输入 user_id, route_list[ ], base_node, base_time
//用户id,关键汇聚点列表,基准节点,基准时间
输出 route_list[ ] with timing slot filled
//填充了时序域的关键汇聚点列表
BEGIN:
步骤1
1)
route ← route_list.get_route(user_id);
//从关键汇聚点列表中得到当前用户的路径
pre_route_list ← route.get_pre_route_list(node_base);
//得到当前基准点的前序路径
post_route_list ← route.get_post_route_list(node_base);
//得到当前基准点的后继路径
步骤2
2)
cur_node ← base_node;
//得到基准节点
while(pre_node ← get_next_pre(cur_node))
{ //基于基准时间,对前序路径填充时序
route[pre_node(cur_node)].time ← base_time-distance(pre_node,cur_node)/speed[user_id]
cur_node ← pre_node;
//将前一个节点作为当前待填充节点
}
步骤3
3)
cur_node ← base_node;
//回到基准节点,开始填充后继节点的时序
while(post_node ← get_next_post(cur_node))
{ //基于基准时间,对后继路径填充时序
route[post_node].time ← time_base+ distance(post_node,cur_node)/speed[user_id]
cur_node ← post_node;
}
END
程序后
在本阶段的最后(图2的第(7)步)将会产生输出工件new_query_list,其内容为替换后的新兴趣点列表。这样原用户的一个兴趣点(对应完整的一条轨迹)替换为多个兴趣点(对应多个分段轨迹)。在算法的最后,该列表中所有的兴趣点请求将会发往LBS服务端(但原有用户与兴趣点之间的对应关系已被破坏)。在算法随后的步骤中,new_query_list将进一步加入新的虚拟对象兴趣点请求。
2.3 虚拟轨迹填充阶段
从图2的第(8)步开始,LPPS针对真实对象轨迹进行虚拟轨迹的注入,称为主轨迹填充。填充方法是不断从mix_list中取出表头节点作为注入点调用trace_mixing算法(算法2)進行填充。算法调用时,作为参数的mix_list列表与算法内的list_of_rendezv列表合一。第(9)、(10)步的虚拟轨迹注入并配置新节点时序的工作将会被反复进行,直到判断为不再需要注入新的虚拟轨迹。
算法2 trace_mixing。
程序前
输入 route[base_user.id]
//用户id的待混淆轨迹,内容为关键汇聚点序列
//〈start_node, {list_of_rendezv[ ]}, end_note〉
输出 fake_trace[i] for each rendezv[i]
//针对每个汇聚点的填充轨迹
BEGIN:
步骤1 1)
1)当CURRENT_RENDEZVA属于周边区域时(如图4、图5中的分区SE),从以下四种情况中任选其一进行填充(由于相似性,算法2只列出了步骤2.1)和步骤2.3)的伪码):
a)对应算法2步骤2.1)与图4,假定当前注入点为〈n1:t1〉,随机选择当前汇聚点相邻周边区域作为虚拟轨迹X的起始区域(图4中AREA_STARTX),选取其区域内一汇聚点(如图4中n5)为虚拟轨迹X的前序节点;此时虚拟路径不通过中央区域,且当前汇聚点CURRENT_ RENDEZVA所在区域为路径X的目的区,虚拟兴趣点POIX(步骤2.1)中的poi_fake,图4中的n7)在CURRENT_ RENDEZVA 所在区域(图4中分区SE)。
b)随机选择一个与待混淆兴趣点区域不同的相邻周边区域作为虚拟轨迹X的目的区域(AREA_ ENDX),选取其区域内一汇聚点作为虚拟轨迹X的后继节点;此时虚拟路径不通过中央区域,且当前汇聚点CURRENT_ RENDEZVA所在区域为路径X的起始区,需在该区生成一个虚拟起始点START_ NODEX(对应算法2步骤2.2))。
图4示例填充虚拟轨迹之前:
mix_list: {n1:t1; n2:t2; n3:t3; …}
new_query_list: {〈A, n0→n1, t0〉; 〈A, n1→n2, t1〉; …}
图4示例填充虚拟轨迹之后:
mix_list: {n5:(t1-s0); n2:t2; n3:t3; …}
new_query_list: {〈X, n5→n1, (t1-s0)〉; 〈A, n0→n1, t0〉; 〈A, n1→n2, t1〉; 〈X, n1→n7, t1〉; …}
c)对应算法2步骤2.3)与图5,选择另一中央区域内汇聚点(如图5中分区C1的节点n5)为虚拟轨迹X的前序节点,此时虚拟轨迹X通过中央区域(图5分区C1),且当前汇聚点CURRENT_ RENDEZVA所在区域(图5分区SE)为虚拟轨迹X的目的区(AREA_ENDX),其虚拟兴趣点POIX在CURRENT_ RENDEZVA所在区域选择(图5中的n8)。
d)选择另一中央区域(如图3中的分区1)内汇聚点为虚拟轨迹X的后继节点,此时虚拟轨迹通过中央区域,且当前汇聚点(CURRENT_RENDEZVA)所在区域为虚拟轨迹X的起始区(AREA_ STARTX),需在该区生成一个虚拟起始点START _NODEX(对应算法2步骤2.4))。
图5示例填充虚拟轨迹之前:
mix_list: {n1:t1; n2:t2; n3:t3; …}
new_query_list: {〈A, n0→n1, t0〉; 〈A, n1→n2, t1〉; …}
图5示例填充虚拟轨迹之后:
mix_list: {n5:(t1-s0); n6:(t1-s1); n2:t2; n3:t3; …}
new_query_list: {〈X, n5→n1, (t1-s0)〉; 〈A, n0→n1, t0〉; 〈A, n1→n2, t1〉; 〈X, n1→n8, t1〉; …}
2)当CURRENT_RENDEZVA属于中央区域时(如图6分区C2):
a)随机选择一个与待混淆用户A起始区域不同但相邻的周边区域(图6中分区E)作为虚拟轨迹X的起始区域(AREA _STARTX),并在该区域内随机选择虚拟轨迹起始点START_NODEX(如图6中节点n6);
b)在与起始区对应(相对于中央区域)的另一个半区随机选择一个周边区域(如图6中分区W)作为虚拟轨迹目的区(AREA_ENDX),并在该区域内随机选择虚拟轨迹兴趣点POIX(如图6中节点n9)。
图6示例填充虚拟轨迹之前:
mix_list: {n2:t2; n3:t3; …}
new_query_list: {〈A, n1→n2, t1〉; 〈A, n2→n3, t2〉; …}
图6示例填充虚拟轨迹之后:
mix_list: {n5:(t2-s0); n6:(t1-s1); n2:t2; n3:t3; …}
new_query_list: {〈X, n5→n2, (t2-s0)〉; 〈A, n1→n2, t1〉; 〈A, n2→n3, t2〉; 〈X, n2→n7, t2〉; …}
主轨迹填充完毕后可能出现干扰轨迹依然数量不多的情况,因而在图2的第(11)步对交汇轨迹数较少的汇聚点进行补充填充,称为均衡填充。该过程与主轨迹填充算法相似,但只针对出入度较少的汇聚点。填充的过程中所产生新的轨迹汇聚点是否继续放入mix_list列表取決于填充的终止条件。若需要终止,则新产生的汇聚点不加入mix_list中,该列表中的节点取空后填充过程将终止。判断是否终止填充的依据可以是一个给定的总填充轨迹数量上限,也可以根据填充所达到的隐私保护度。除了mix_list列表,新产生虚拟轨迹的中间汇聚点和虚拟兴趣点也会在图2的第(12)步中加入到new_query_list列表,并最终会被发往LBS服务提供端。
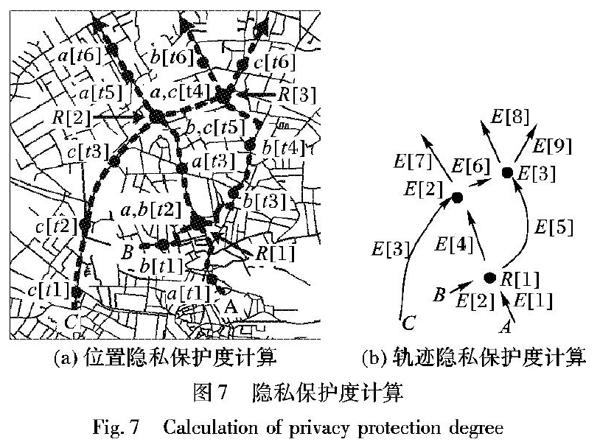
接下来在图2的第(13)步调用id_mixing过程(算法3)对时间窗time_margin范围内近似同时进入汇聚点的轨迹进行ID混淆。此过程使得进入汇聚点的轨迹-ID对应关系在离开汇聚点时发生错乱,从而使得攻击者追踪识别某条完整轨迹的难度大为增加。
算法3 id_mixing。
程序前
步骤 current_rendez, route_list[ ], time_margin
//当前汇集点,路由列表,时间窗
步骤 route_list[ ] with user_id has been changed at current_ rendez
//ID混淆后的路由列表
BEGIN:
步骤1
1)
cur_node ← current_rendez.get_node;
cur_time ← current_rendez.get_time;
步骤2
2)
for each route[i] ∈ route_list[ ] that cur_node ∈ route[i]
//经过当前节点的所有路径
if route[i].get_time(cur_node)- cur_time //在时间窗内到达可视为交汇 步骤2.1 2.1) arriv_list[i].user_id←route[i]. user_id; //arriv_list為在时间窗内进入此汇集点的所有用户 //轨迹,分别得到此轨迹的用户ID和轨迹ID 步骤2.2 2.2) arriv_list[i].route_id←route[i]. route_id; } 步骤3 3) depart_ list[ ] ← Collections.shuffle(arriv_list[ ]. user_ id, arriv_list[i].route_id); // depart_ list为用户ID混淆后的输出路由 END 程序后 在算法3的步骤3执行完后,new_query_list列表中用户ID(如图4至图6中new_query_list结构里的用户X和A)与兴趣点请求之间的对应关系将会被修改,从而通过①轨迹分段和②ID混淆,实现了对原始用户信息和POI请求信息对应关系的隐藏。在图2的第(14)步至(15)步,这些错乱的信息通过new_query_list被传递给了LBS服务提供者;后者不能分辨哪些是真实用户,哪些是虚拟用户,所有请求都被视为正常请求并返回这些请求的兴趣点位置和路由。 在图2的第(16)步,LPPS从收到的LBS服务端回复中,过滤出真实用户的兴趣点坐标和路径,并将这些结果在第(17)步返回给终端用户。而对终端用户而言,就如同直接从LBS服务者拿到请求结果一样。隐私保护服务器LPPS所做的虚拟轨迹注入等保护措施对终端用户而言是透明的。 3 隐私保护度 位置隐私保护的度量体现在位置隐私披露风险LD(Lacation Disclosure)和轨迹隐私披露风险TD(Trajectory Disclosure)两个层面上。当攻击者没有关于用户特别的背景信息时(比如用户经常访问的路径或区域),则针对某个位置攻击者只能以等概率猜测方式猜测其和某个特定对象的关联关系。若整个轨迹观测期共m个时间片,位置隐私披露风险可以定义为: LD= 1 m ∑ m i=1 1 Si (1) 其中Si为第i个时间片内观测到的可区分位置个数。 同样,在没有过多的背景信息下,攻击者也只能以等概率猜测方式猜测某条轨迹可能对应于某个特定对象。假定n为LBS服务端看到的至少存在一个与其他轨迹交点的轨迹数,在经过位置隐私保护算法处理后,因为没有特别的背景知识,只能等概率从这n条相交的轨迹所可能形成的轨迹形态总数中进行猜测。设Tn为这样的轨迹总数,且另有k条轨迹不与任何其他轨迹相交,则轨迹隐私披露风险可定义为: TD= 1 Tn+k (2) 以图7(a)所示场景为例,攻击者需要猜测A、B、C三个用户的轨迹哪条可能是目标对象的,其位置隐私披露概率计算如表1所示。根据式(1),在t1、t3和t6时刻,因为能区分3个不同对象,因而S1、S3、S6均为3;而在t2、t4、t5时刻因为轨迹相交的原因,S2、S4、S5均为2。就这6个时间片而言,其平均位置隐私披露风险LD为(1/3+1/2+1/3+1/2+1/2+1/3)/6=0.417,大于1/3。 图7(b)显示了整个轨迹被汇聚点分割成片段后多条轨迹相互混淆的情况。初始的A、B、C三个移动对象经过交汇点R[1]、R[2]和R[3]后因为发生了ID混淆,若没其他背景信息,攻击者只能从以下可能轨迹中进行等概率猜测: 1)A: E[1]→E[4]→E[7],B: E[2]→E[5]→E[8],C: E[3]→E[6]→E[9]。 2)A: E[1]→E[4]→E[7],B: E[2]→E[5]→E[9],C: E[3]→E[6]→E[8]。 3)A: E[1]→E[5]→E[8],B: E[2]→E[4]→E[7],C: E[3]→E[6]→E[9]。 4)A: E[1]→E[5]→E[8],B: E[2]→E[4]→E[6]→ E[9],C: E[3]→E[7]。 5)A: E[1]→E[5]→E[9],B: E[2]→E[4]→E[6]→ E[8],C: E[3]→E[7]。 6)A: E[1]→E[5]→E[9],B: E[2]→E[4]→E[7],C: E[3]→E[6]→E[8]。 7)A: E[1]→E[4]→E[6]→ E[8],B: E[2]→E[5]→E[9],C: E[3]→E[7]。 8)A: E[1]→E[4]→E[6]→ E[9],B: E[2]→E[5]→E[8],C: E[3]→E[7]。 一共8种可能的轨迹,根据式(2),Tn=8,k=0,轨迹隐私披露风险TD的值为1/(8+0)=0.125,远小于没有经过任何位置隐私保护处理时的值1/3。 4 算法性能评估 1)计算复杂度。 在汇聚点提取阶段中汇聚点的确定和地图分区主要依据积累的热点历史信息,其时间复杂度与所关注地区的面积相关,可以作为预处理放在系统主循环之外。算法主体的时间复杂度由主轨迹填充和均衡填充过程决定,其时长取决于对路径经过的汇聚点和关联分区的遍历。若n为路径经过的汇聚点数,q为目标区域分区数,算法时间复杂度可表示为Ο(n×q)。 2)可扩展性与隐私保护度。 为考察算法实现位置隐私保护的效果,以及待保护对象的数量和填充的虚拟轨迹的数量对算法性能的影響,在运行环境为Intel Core i5-4300M CPU、8GB PC3-12800 RAM的64位Windows 10机器上,以图3所示的路网环境对算法进行了验证。简单起见,路网被划分为固定的2个中央分区和6个边缘分区;待保护用户的服务发起点和兴趣点也固定为在路由中有适中出入度的节点。图8(a)给出了分别为单个用户、3个待保护并发用户和5个待保护并发用户的情况下,位置隐私披露概率随填充虚拟用户数变化的对比结果;图8(b)为相应的轨迹隐私披露概率的对比情况。鉴于算法2中生成虚拟轨迹的随机性,实验中位置隐私披露概率值和轨迹隐私披露概率值为3次实验的平均值。 从图8可以看出,对于单个待保护用户而言,经过大约10次虚拟用户的注入后,位置隐私披露概率从62%下降到12%左右,轨迹隐私披露概率从50%下降到7%左右,两者下降效果显著,且之后趋于平稳。考虑到算法生成的虚拟请求对LBS服务端造成的载荷增长,可以认为多于10个虚拟用户之后的填充不是必要的。 对于多个用户需求位置隐私保护情况,当多个用户之间时间间隔比较大,即不能看作是并发时,每个用户的轨迹填充可看作是独立、互不影响的,算法效果等同于单用户。当多个用户可看作并发时,对某个用户填充的轨迹会对其他用户的隐私披露概率产生影响。从图8的实验结果看到,3个并发用户填充5轮15次后,以及5个并发用户填充4轮20次后,其保护效果与单用户14次的填充相当,总体上节省了填充开销。不过由于算法是针对每个用户逐次进行填充,当并发用户过多时,新生成的虚拟轨迹在地图中的路径重叠现象会造成算法的保护性能下降。 3)通信开销与负荷。 算法中一次兴趣点POI请求的消息格式为q=〈IDuser, time, Location(x, y), POI〉,LBS回复消息格式为〈IDuser, time, start_node(x,y), {list_of_route}, end_note(x,y)〉。算法的Java版本中这些消息使用JSON-Gzip压缩格式传送,单个请求消息大小约为5KB量级,平均包含3个中间路由节点的回复消息大小约为20KB量级。 实验中,一条真实用户轨迹大多被分为初始分区、中央分区和目的分区三段,主轨迹填充阶段会有3条虚拟轨迹与主轨迹相交,而均衡填充阶段会有6至10条的虚拟轨迹相互进行填充(假设均衡填充的结束条件为所有8个分区的汇聚点至少有2条轨迹交汇)。因此在没有加入隐私保护功能前,客户端和LBS服务端之间的通信在路网信息每个更新周期内只有一个POI请求和返回组成的通信开销,而在加入隐私保护服务器LPPS后,LPPS与LBS提供者之间的通信开销上升为每更新周期约9至13个POI请求和返回消息对;相应的LBS服务提供端在单更新周期内,原本只需为每个客户提供1次POI定位和导航服务的工作负荷,现在变成了需进行9至13次的定位和导航服务。 与近期同样针对路网结构的位置隐私保护算法相比较,文献[14] 使用锚点的概念实现路网环境下位置服务的间接查询,在连续查询时利用缓存信息减少查询的次数,通信开销要低于本文的方法。但组织用户共用锚点的操作其实与构造匿名框的优缺点是相似的,从锚点到用户本地的导航需要更多的支撑数据和计算量。文献[17] 专门针对连续查询中查询发起时间的设置问题进行了研究,通过构建匿名子网和k近邻安全区对达成匿名区时占用的计算资源进行了优化。该方法随着查询者运动速度和POI兴趣点密度的增加,匿名保护服务器端处理时间增幅越大。本文方法POI的定位是在算法开始时一次性计算完成,不会出现隐私保护服务器的工作负荷随着POI数目的增长而发生激增的现象。文献[18] 对兴趣点记录和查询结果进行了加密,以路网顶点作为基础进行相对位置查询,其特点是对LBS服务的基本模式进行了改动,需要修改原有的LBS服务方代码来加入加密和解密模块。本文的方法LBS服务方代码无需任何变化。 5 结语 本文提出的虚拟轨迹填充算法 通过注入一定数量的虚拟用户、虚拟请求和虚拟轨迹,并将它们与真实轨迹混杂在一起,降低了LBS服务端的攻击者追踪和关联到正确移动对象的概率。该算法首先对真实轨迹进行分段,并对初始ID和POI进行混淆和保护;在生成新的虚拟轨迹后与原轨迹分别进行主轨迹混淆填充和多轮均衡填充,并在LBS服务端形成干扰性的虚拟用户和虚拟请求。这些虚拟请求与真实轨迹请求混杂在一起,增加了攻击者追踪真实轨迹的难度。验证实验结果表明,本文算法能够以不大的计算开销实现位置隐私披露概率和轨迹隐私披露概率的显著下降并趋于稳定。由于算法基于针对每个用户作为单独的个案逐例进行虚拟轨迹的填充,因而适合针对少量VIP用户实现无位置服务精度损失的隐私保护;而对于大量并发用户的保护需求,本文算法生成合理虚拟路径的计算开销较大,同时也面临着虚拟路径重叠问题,此时需要考虑与其他算法相结合,并解决如何降低对LBS服务精度的影响以及如何适用于路网环境等问题。 参考文献 [1] 刘成.LBS定位技术研究与发展现状[J].导航定位学报,2013,1(1):78-83. (LIU C. Research and development status of LBS positioning technology[J]. Journal of Navigation and Positioning, 2013, 1(1): 78-83.) [2] 赵军,车红岩.基于位置服务的应用技术和发展趋势[J].测绘科学,2016,41(4): 171-176, 189. (ZHAO J, CHE H Y. Application techniques and development trends of LBS[J]. Science of Surveying and Mapping, 2016, 41(4): 171-176, 189.) [3] ANDRS M E, BORDENABE N E, CHATZIKOKOLAKIS K, et al. Geo-indistinguishability: differential privacy for location-based systems [C]// Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2013: 901-914. [4] WERNER M. Privacy protected communication for location based services [J]. Security and Communication Networks, 2016, 9: 130-138. http://xueshu.baidu.com/s?wd=paperuri%3A%282c39078868f290710a285aaa8668c2cf%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fonlinelibrary.wiley.com%2Fdoi%2F10.1002%2Fsec.330%2Fpdf&ie=utf-8&sc_us=5825488878314576246&sc_as_para=sc_lib%3A [5] ZHOU T. Understanding location-based services users privacy concern: an elaboration likelihood model perspective [J]. Internet Research, 2017, 27(3): 506-519. [6] 張学军,桂小林,伍忠东.位置服务隐私保护研究综述[J].软件学报,2015,26(9):2373-2395. (ZHANG X J, GUI X L, WU Z D. Privacy preservation for location-based services: a survey[J]. Journal of Software, 2015, 26(9): 2373-2395.) [7] 许明艳,赵华,季新生.位置服务隐私保护技术研究综述[J].信息工程大学学报,2015,16(5):543-551. (XU M Y, ZHAO H, JI X S. Survey of location privacy protection technology [J]. Journal of Information Engineering University, 2015, 16(5): 543-551.) [8] 万盛,李凤华,牛犇,等.位置隐私保护技术研究进展[J].通信学报,2016,37(12):1-18. (WAN S, LI F H, NIU B, et al. Research progress on location privacy-preserving techniques [J]. Journal on Communications, 2016, 37(12): 1-18.) [9] HE Z Q, CHEN G. Improvement of K-anonymity location privacy protection algorithm based on hierarchy clustering [J]. Applied Mechanics and Materials, 2014, 3360(599/600/601): 1553-1557. [10] 熊婉竹,李晓宇.基于匿名路由的移动位置隐私保护[J].计算机科学,2018,45(10):142-149. (XIONG W Z, LI X Y. Mobile location privacy protection based on anonymous routing [J]. Compuer Science, 2018, 45(10): 142-149.) [11] 孙丹丹,罗永龙,范国婷,等.基于轨迹形状多样性的隐私保护算法[J].计算机应用,2016,36(6):1544-1551. (SUN D D, LUO Y L, FAN G T, et al. Privacy protection algorithm based on trafectory shape diversity[J]. Journal of Computer Applications, 2016, 36(6): 1544-1551.) [12] 胡德敏,詹涵.差分扰动的均衡增量近邻查询位置隐私保护方法[J].小型微型计算机系统,2018,39(7):1482-1486. (HU D M, ZHAN H. Homogeneous incremental nearest neighbor query method based on differential perturbation for location privacy protection [J]. Journal of Chinese Computer Systems, 2018, 39(7): 1482-1486.) [13] LIU K G, ZHANG J P, YANG J. Privacy preserving for location-based services in road networks [J]. Advanced Materials Research, 2014, 3349(998/999): 1165-1168. [14] 周長利,马春光,杨松涛.路网环境下保护LBS位置隐私的连续KNN查询方法[J].计算机研究与发展,2015,52(11):2628-2644. (ZHOU C L, MA C G, YANG S T. Location privacy-preserving method for LBS continuous KNN query in road networks [J]. Journal of Computer Research and Development, 2015, 52(11): 2628-2644.) [15] PALANISAMY B, LIU L, LEE K, et al. Anonymizing continuous queries with delay-tolerant mix-zones over road networks [J]. Distributed and Parallel Databases, 2014, 32(1): 91-118. [16] KIM J-S, LI K-J. Location K-anonymity in indoor spaces [J]. GeoInformatica, 2016, 20(3): 415-451. [17] 倪巍伟,马中希,陈萧.面向路网隐私保护连续近邻查询的安全区域构建[J].计算机学报,2016,39(3):628-642. (NI W W, MA Z X, CHEN X. Safe region scheme for privacy-preserving continuous nearest neighbor query on road networks[J]. Chinese Journal of Computers, 2016, 39(3): 628-642.) [18] 周长利,田晖,马春光,等.路网环境下基于伪随机置换的LBS隐私保护方法研究[J].通信学报,2017,38(6):19-29. (ZHOU C L, TIAN H, MA C G, et al. Research on LBS privacy preservation based on pseudorandom permutation in road network[J]. Journal on Communications, 2017, 38(6): 19-29.)
