区间值决策表的正域增量式属性约简算法
2019-10-23鲍迪张楠童向荣岳晓冬
鲍迪 张楠 童向荣 岳晓冬

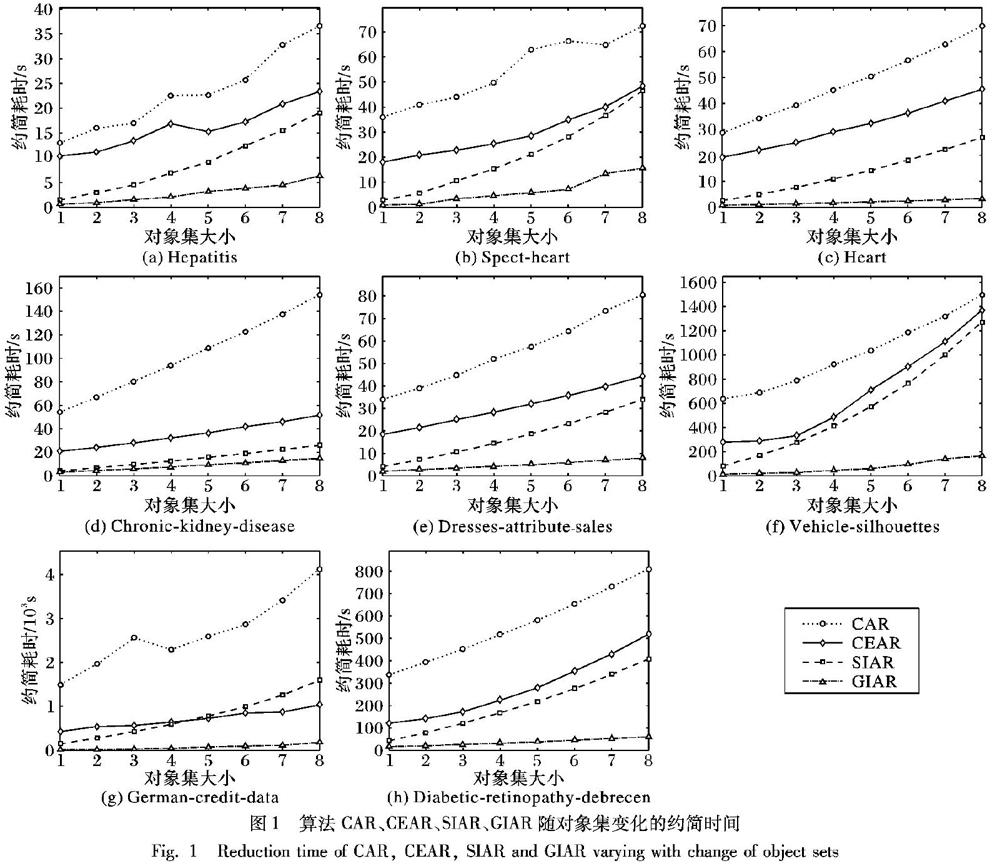

摘 要:實际应用中存在大量动态增加的区间型数据,若采用传统的非增量正域属性约简方法进行约简,则需要对更新后的区间值数据集的正域约简进行重新计算,导致属性约简的计算效率大大降低。针对上述问题,提出区间值决策表的正域增量属性约简方法。首先,给出区间值决策表正域约简的相关概念;然后,讨论并证明单增量和组增量的正域更新机制,提出区间值决策表的正域单增量和组增量属性约简算法;最后,通过8组UCI数据集进行实验。当8组数据集的数据量由60%增加至100%时,传统非增量属性约简算法在8组数据集中的约简耗时分别为36.59s、72.35s、69.83s、154.29s、80.66s、1498.11s、4124.14s和809.65s,单增量属性约简算法的约简耗时分别为19.05s、46.54s、26.98s、26.12s、34.02s、1270.87s、1598.78s和408.65s,组增量属性约简算法的约简耗时分别为6.39s、15.66s、3.44s、15.06s、8.02s、167.12s、180.88s和61.04s。实验结果表明,提出的区间值决策表的正域增量式属性约简算法具有高效性。
关键词:粗糙集;区间值决策表;相容关系;正域;增量式属性约简
中图分类号: TP181
文献标志码:A
Incremental attribute reduction algorithm of positive region in interval-valued decision tables
BAO Di1,2, ZHANG Nan1,2*, TONG Xiangrong1,2, YUE Xiaodong3
1.Key Lab for Data Science and Intelligence Technology of Shandong Higher Education Institutes (Yantai University), Yantai Shandong 264005, China ;
2.School of Computer and Control Engineering, Yantai University, Yantai Shandong 264005, China ;
3.School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China
Abstract: There are a large number of dynamically-increasing interval data in practical applications. If the classic non-incremental attribute reduction of positive region is used for reduction, it is necessary to recalculate the positive region reduction of the updated interval-valued datasets, which greatly reduces the computational efficiency of attribute reduction. In order to solve the problem, incremental attribute reduction methods of positive region in interval-valued decision tables were proposed. Firstly, the related concepts of positive region reduction in interval-valued decision tables were defined. Then, the single and group incremental mechanisms of positive region were discussed and proved, and the single and group incremental attribute reduction algorithms of positive region in interval-valued decision tables were proposed. Finally, 8 UCI datasets were used to carry out experiments. When the incremental size of 8 datasets increases from 60% to 100%, the reduction time of classic non-incremental attribute reduction algorithm in the 8 datasets is 36.59s, 72.35s, 69.83s, 154.29s, 80.66s, 1498.11s, 4124.14s and 809.65s, the reduction time of single incremental attribute reduction algorithm is 19.05s, 46.54s, 26.98s, 26.12s, 34.02s, 1270.87s, 1598.78s and 408.65s, the reduction time of group incremental attribute reduction algorithm is 6.39s, 15.66s, 3.44s, 15.06s, 8.02s, 167.12s, 180.88s and 61.04s. Experimental results show that the proposed incremental attribute reduction algorithm of positive region in interval-valued decision tables is efficient.
Key words: rough set; interval-valued decision table; tolerance relation; positive region; incremental attribute reduction
0 引言
粗糙集理论中,属性约简[1-4]是重要研究内容之一。属性约简的主要目标是移除冗余属性,提高数据处理效率。目前,诸多学者通过深入研究给出了一系列求解约简的方法。苗夺谦等[5]引入互信息用于选择对决策重要的条件属性,并基于互信息给出了启发式的属性约简方法;Xu等[6]在不协调序信息系统下给出了计算分布约简的矩阵方法;Min等[7]基于信息增益设计了测试代价敏感的约简算法;Hu等[8]首次以正域定义属性重要度启发式求解约简;Qian等[9]定义了局部粗糙集的理论框架,给出目标概念的局部约简方法;Jia等[10]将代价敏感和最优化问题引入决策粗糙集,进而求得最小代价约简。
目前,区间型数据广泛存在于工程测量、医学等领域。在决策表中,若条件属性值为区间值,则该决策表称为区间值决策表。针对区间值决策表,众多学者进行了属性约简研究。Leung等[11]定义了基于错误分类率的相容关系,分析了区间值决策表下的规则获取;张楠等[12]针对分类结果冗余度大和错分率高的问题,在区间值决策表中定义了α极大相容类,给出了广义决策保持约简;刘鹏惠等[13]定义了区间值决策表下的变精度相容关系,给出了决策属性约简与相对约简的方法;徐菲菲等[14]以电力数据为背景,基于互信息和依赖度提出了区间值约简算法,并给出了多决策表下的全局约简方法,增强了算法的实用性;Dai等[15]分析了基于区间值相似度的扩展条件熵,讨论了区间值决策表的不确定性度量问题。
现实应用中的数据集通常动态增加到数据库,为及时从数据中获得知识,相关学者给出了不同的增量更新方法[16-19]。在决策表中,数据动态变化有三种类型:对象集的动态增加、属性集的动态增加和属性值的动态改变。Hu等[20]针对单个对象的动态变化定义了正、负基本集,根据正、负基本集的改变更新约简;Xu等[21]运用0-1整数运算,提出一种属性约简的增量式算法;杨明[22]改进了差别矩阵定义,避免了差别函数的计算,在动态更新核属性的基础上增量更新约简;Liang等[23]分析了对象集增加后信息熵的变化规律,给出了高效处理海量数据的组增量方法;Shu等[24]在对象集动态变化的不完备决策表中提出了基于正域的增量式算法;Yu等[25]在区间值信息系统下定义了区间相似度,分析了近似集随对象集变化的增量更新方法;Wang等[26]讨论了信息熵的属性增量机制,从属性的角度分析了数据集融合;Liu等[27]在概率粗糙集模型下分析了近似集的更新策略,采用增量方法计算近似集;Cheng[28]针对属性集的动态改变,基于边界域和截集变化更新模糊算子;Chen等[29]分析了属性值域与知识粒的变化关系,给出了增量更新近似集的原理和相应算法。
上述研究主要針对完备决策表或不完备决策表讨论增量更新方法,由于实际应用中存在大量的区间型数据,而针对区间值决策表的增量式属性约简研究未见报道,因此,本文提出区间值决策表正域属性约简的增量方法,该增量方法可以在不重新计算的情况下获得更新后区间值决策表的正域约简,提高约简的计算效率。本文首先介绍了区间值决策表的相关概念,然后分析了对象集动态变化时正域的单增量和组增量更新机制,提出了区间值决策表的正域单增量和组增量属性约简算法,最后通过实验验证了增量算法的高效性。
1 预备知识
本章将介绍区间值决策表和上、下近似等相关概念,给出区间值决策表的传统正域非增量属性约简算法。
1.1 区间值决策表的上、下近似
定义1 [12] 区间值信息表是四元组IT=(U,A,V, f),其中:U={x1,x2,…,xn}为有限对象集,称为论域;A为有限属性集;V= ∪ ak∈A Vak为区间的集合,Vak为属性ak∈A的值域; f是U×A→V的映射,表示xi∈U在ak∈A上存在对应的区间属性值。
若有限属性集A=C∪D,其中:条件属性集C={a1,a2,…,am},决策属性集D={d};V=VC∪VD,VC是条件属性值集,VD是决策属性值集,其中决策属性值为单值,则DT=(U,C∪D,V, f)称为区间值决策表。
论域U关于决策属性集D的不可分辨关系IND(D)={(xi,xj)∈U×U | d∈D,d(xi)=d(xj)},其中d(x)是对象x关于决策属性d∈D的属性值。不可分辨关系IND(D)对U的划分U/IND(D)={D1,D2,…,Dr}(1 定义2 [30] 给定两个区间值λ1=[lki,uki]和λ2=[lkj,ukj],区间值的交、并运算定义如下: λ1∩λ2= 0, (uki [max(lki,lkj),min(uki,ukj)], 其他 (1) λ1∪λ2=[min(lki,lkj),max(uki,ukj)] (2) 区间值交、并运算的介绍,为描述Jaccard相似率提供了方便,下面给出区间值Jaccard相似率的定义。 定义3 给定区间值决策表DT=(U,C∪D,V, f),xi,xj∈U,ak∈C,令ak(xi)=[lki,uki],ak(xj)=[lkj,ukj],则区间值ak(xi)和ak(xj)的Jaccard相似率[30]: αkij= | [lki,uki]∩[lkj,ukj] | | [lki,uki]∪[lkj,ukj] | (3) 其中: | · | 表示闭区间长度。αkij值越大,对象xi和xj关于属性ak的相似度越高。 定义4 [13] 设区间值决策表DT=(U,C∪D,V, f),PC,相似率阈值α∈[0,1],定义关于属性子集P的α-相容关系为: TRαP={(xi,xj) | (xi,xj)∈U×U,αkij>α,ak∈P} (4) α-相容关系具有以下性质: 性质1 [12] 设区间值决策表DT=(U,C∪D,V, f), PC, α∈[0,1],则TRαP满足自反性和对称性。 性质2 [12] 设区间值决策表DT=(U,C∪D,V, f), PC, α∈[0,1],则TRαP= ∩ ak∈P TRα{ak}。 定义5 [13] 区间值决策表DT=(U,C∪D,V, f), PC, α∈[0,1], 在属性子集P下定义对象xi的α-相容类为: SαP(xi)={xj | xj∈U,(xi,xj)∈TRαP} (5) 所有SαP(xi)(xi∈U)的集合形成对U的覆盖SαP(U)={SαP(x1),SαP(x2),…,SαP(x|U|)}。 基于上述概念,给出区间值决策表上、下近似的定义。 定义6 [14] 区间值决策表DT=(U,C∪D,V, f),XU,PC,α∈[0,1],对象xi的相容类为SαP(xi),定义X关于属性子集P的上、下近似分别为: aprαP (X)={xi | xi∈U,SαP(xi)∩X≠} (6) aprαP (X)={xi | xi∈U,SαP(xi)X} (7) X关于P的正域、边界域和负域分别定义为: POSαP(X)=aprαP (X) (8) BNDαP(X)=aprαP (X)-aprαP (X) (9) NEGαP(X)=U-(POSαP(X)∪BNDαP(X)) (10) 定义7 [14] 区间值决策表 α,α,α∈[0,1],U/IND(D)={D1,D2,…,Dr} DT=(U,C∪D,V, f), PC,α∈[0,1], IND(D)对 U/IND(D)={D1,D2,…,Dr} U的划分U/IND(D)={D1,D2,…,Dr}(1 aprαP (D)={aprαP (D1),aprαP (D2),…,aprαP (Dr)} (11) aprαP (D)={aprαP (D1),aprαP (D2),…,aprαP (Dr)} (12) 定義正域POSαP(D)= ∪ r i=1 aprαP (Di)。为便于后续章节讨论,正域可定义为POSαP(D)={xi∈U | | SαP(xi)/IND(D) | =1}, 其中 | SαP(xi)/IND(D) | =1表示xi的相容类中所有对象的决策值唯一。 定义8 [11] 设区间值决策表DT=(U,C∪D,V, f), U={x1,x2,…,xn},相似率阈值α∈[0,1],对PC,论域U和属性集P确定的布尔相似矩阵 M αP定义为: M αP= r11 r12 … r1n rn1 rn2 … rnn 若对ak∈P,对象xi和xj在属性ak上的相似率αkij>α(i, j∈[1,n]),则rij=1,表示对象xi和xj相似;否则rij=0,表示对象xi和xj不相似。 例1 区间值决策表DT=(U,C∪D,V, f)如表1所示,U={x1,x2,x3,x4,x5,x6}为论域,C={a1,a2,a3,a4}为条件属性集,D={d}为决策属性集。令相似率阈值α=0.6,计算正域POSαC(D)。其中区间值ak(xi)=[lki,uki]为条件属性值,单值d(xi)为决策属性值,例如:a1(x3)=[0.75,3.02],d(x3)=1。 根据表1计算布尔相似矩阵 M 0.6C如下: M 0.6C= 1 0 0 0 0 00 1 0 1 0 10 0 1 0 0 00 1 0 1 0 10 0 0 0 1 00 1 0 1 0 1 由布尔相似矩阵可得相容类集合:S0.6C(U)={S0.6C(x1),S0.6C(x2),S0.6C(x3),S0.6C(x4),S0.6C(x5),S0.6C(x6)},其中S0.6C(x1)={x1}, S0.6C(x2)=S0.6C(x4)=S0.6C(x6)={x2,x4,x6}, S0.6C(x3)={x3}, S0.6C(x5)={x5}。 由于: | S0.6C(x1)/IND(D) | =1, | S0.6C(x2)/IND(D) | ≠1, | S0.6C(x3)/IND(D) | =1, | S0.6C(x4)/IND(D) | ≠1, | S0.6C(x5)/IND(D) | =1, | S0.6C(x6)/IND(D) | ≠1。根据定义7,D关于C的正域为POS0.6C(D)={x1,x3,x5}。 定义9 [14] 设区间值决策表DT=(U,C∪D,V, f),PC,若P是DT的一个约简,则需满足以下两个条件: 1)POSαP(D)=POSαC(D); 2)P′P,满足POSαP′(D)≠POSαP(D)。 条件1)保证了约简前后区间值决策表的正域相同,条件2)保证了无冗余属性存在于约简结果。 例2 区间值决策表DT=(U,C∪D,V, f)如表1所示,U={x1,x2,x3,x4,x5,x6}为论域,C={a1,a2,a3,a4}为条件属性集,D={d}为决策属性集,计算区间值决策表DT的一个约简。 通过例1计算正域POS0.6C(D)={x1,x3,x5},由于POS0.6{a1,a3}(D)=POS0.6C(D),POS0.6{a1}(D)≠POS0.6C(D),POS0.6{a3}(D)≠POS0.6C(D),根据定义9,属性子集{a1,a3}与属性集C保持的正域相同,且属性子集{a1,a3}中无冗余属性,因此{a1,a3}是一个约简。 定义10 [14] 设区间值决策表DT=(U,C∪D,V, f), PC,α∈[0,1],a∈P,定义属性a在属性子集P中的内部重要度为: siginner(a,P,D)= | POSαP(D)-POSαP-{a}(D) | (13) 若siginner(a,P,D)>0,则a是核属性;若siginner(a,P,D)=0,则a是可去属性。在属性约简过程中,内部重要度用于计算核属性或删除属性集中的冗余属性。 定义11 [14] 设区间值决策表DT=(U,C∪D,V, f), PC,α∈[0,1],a∈C-P,定义属性a相对于属性子集P的外部重要度为: sigouter(a,P,D)= | POSαP∪{a}(D)-POSαP(D) | (14) 1.2 区间值决策表的正域非增量属性约简算法 本节根据文献[14]给出区间值决策表的传统正域非增量属性约简算法,对于对象集动态增加的区间值决策表,该算法要重新计算约简结果。区间值决策表的传统正域非增量属性约简算法(Classic non-incremental Attribute Reduction algorithm based on positive region in interval-valued decision tables,CAR)具体描述如下: 算法1 区间值决策表的传统正域非增量属性约简算法(CAR)。 输入 区间值决策表DT=(U,C∪D,V, f)。 输出 约简结果Red。 步骤1 令Red←; 步骤2 对所有属性ai∈C,计算siginner(ai,C,D),若siginner(ai,C,D)>0,令Red←Red∪{ai}; 步骤3 若POSαRed(D)≠POSαC(D),重复: 步骤3.1 对所有属性aj∈C-Red,计算sigouter(aj,Red,D); 步骤3.2 选取ak=arg max{sigouter(aj,Red,D)},令Red←Red∪{ak}; 步骤4 对b∈Red,计算siginner(b,Red,D),若siginner(b,Red,D)=0,令Red←Red-{b}; 步骤5 返回Red。 算法1计算正域的时间复杂度是O( | C | | U | 2),计算核属性的时间复杂度是O( | C | 2 | U | 2),选择属性添加到核属性集的时间复杂度是O( | C | 3 | U | 2),删除冗余属性的时间复杂度是O( | C | 2 | U | 2),所以算法1整体的时间复杂度是O( | C | 3 | U | 2)。 2 单增量属性约简 针对对象集动态变化的区间值决策表,2.1节分析了单个对象增加后决策类和相容类的变化规律,给出了单增量的正域更新机制;2.2节讨论了增加单个对象与初始约简结果的变化关系,给出了不同的约简更新策略,提出了区间值决策表的正域单增量属性约简算法。 2.1 单增量的正域更新机制 属性约简过程中,若使用非增量方法更新正域,会导致正域的计算效率低。为了提高正域的计算效率,可采用增量方法更新正域,下面介绍单个对象增加后的正域更新机制。 定理1 设区间值决策表DT=(U,C∪D,V, f),任意属性子集PC,增加对象x后更新论域为U′=U∪{x},POSαP(D)为论域U在属性子集P下的初始正域,Sα(P,U′)(x)为论域U′中对象x的相容类,[x]D为x所在决策类中的对象集合,论域U′在属性子集P下更新正域为: POSα(P,U′)(D)=POSαP(D)∪{y∈{x} | | Sα(P,U′)(y)/IND(D) | =1}-{y∈Sα(P,U′)(x) | | Sα(P,U′)(y)/IND(D) | ≠1}。 若 | Sα(P,U′)(y)/IND(D) | =1,则表示相容类Sα(P,U′)(y)中所有对象的决策属性值相同;反之,则表示相容类Sα(P,U′)(y)中对象的决策属性值存在差异。 证明 对象x增加到区间值决策表后分以下四種情况进行讨论: 1)Sα(P,U′)(x)={x}且[x]D={x}。显然 | Sα(P,U′)(x)/IND(D) | =1,由正域定义可知,POSα(P,U′)(D)={y∈U | | Sα(P,U′)(y)/IND(D) | =1}∪{y∈{x} | | Sα(P,U′)(y)/IND(D) | =1},由于Sα(P,U′)(x)={x}且[x]D={x},所以{y∈U | | Sα(P,U′)(y)/IND(D) | =1}={y∈U | | SαP(y)/IND(D) | =1},因此,更新正域POSα(P,U′)(D)=POSαP(D)∪{x}。 2)Sα(P,U′)(x)={x}且[x]D≠{x}。显然 | Sα(P,U′)(x)/IND(D) | =1,POSα(P,U′)(D)={y∈U | | Sα(P,U′)(y)/IND(D) | =1}∪{y∈{x} | | Sα(P,U′)(y)/IND(D) | =1},由于Sα(P,U′)(x)={x}且[x]D≠{x},所以{y∈U | | Sα(P,U′)(y)/IND(D) | =1}={y∈U | | SαP(y)/IND(D) | =1},因此,更新正域POSα(P,U′)(D)=POSαP(D)∪{x}。 3)Sα(P,U′)(x)≠{x}且[x]D={x}。显然 | Sα(P,U′)(x)/IND(D) | ≠1,对于y∈Sα(P,U′)(x)满足 | Sα(P,U′)(y)/IND(D) | ≠1,由正域定义知,POSα(P,U′)(D)={y∈U | | SαP(y)/IND(D) | =1}-{y∈Sα(P,U′)(x) | | Sα(P,U′)(y)/IND(D) | ≠1}∪,因此,更新正域POSα(P,U′)(D)=POSαP(D)-{y∈Sα(P,U′)(x) | | Sα(P,U′)(y)/IND(D) | ≠1}。 4)Sα(P,U′)(x)≠{x}且[x]D≠{x}。更新正域POSα(P,U′)(D)=POSαP(D)-{y∈Sα(P,U′)(x) | | Sα(P,U′)(y)/IND(D) | ≠1},证明与上类似,不再赘述。 综上,更新后的正域POSα(P,U′)(D)=POSαP(D)∪{y∈{x} | | Sα(P,U′)(y)/IND(D) | =1}-{y∈Sα(P,U′)(x) | | Sα(P,U′)(y)/IND(D) | ≠1}。 例3 区间值决策表DT=(U,C∪D,V, f)如表1所示,新增对象x如表2所示,更新论域U′=U∪{x},令相似率阈值α=0.6,计算区间值决策表DT′=(U′,C∪D,V, f)的正域POS0.6(C,U′)(D)。 由例1计算初始正域POS0.6C(D)={x1,x3,x5}。计算对象x关于论域U′的相容类S0.6(C,U′)(x)={x5,x},对象x5关于论域U′的相容类S0.6(C,U′)(x5)={x5,x}。由于 | S0.6(C,U′)(x)/IND(D) | ≠1并且 | S0.6(C,U′)(x5)/IND(D) | ≠1,根据定理1更新正域:POS0.6(C,U′)(D)=POS0.6C(D)∪-{x5}={x1,x3,x5}-{x5}={x1,x3}。 2.2 区间值决策表的正域单增量属性约简算法 属性约简是保持决策表分类能力不变的条件下,移除冗余属性,获得最小属性子集。当单个对象增加到区间值决策表,决策表的分类能力可能发生变化,因此需要更新初始约简结果。下面讨论单个对象增加后初始约简结果的变化情况。 给定区间值决策表DT=(U,C∪D,V, f),相似率阈值α∈[0,1],初始约简结果B,新增对象x,更新后的区间值决策表DT′=(U′,C∪D,V, f),其中U′=U∪{x}。对象x关于B和C的相容类存在以下三种情况: 1) | Sα(C,U′)(x)/IND(D) | =1且 | Sα(B,U′)(x)/IND(D) | =1; 2) | Sα(C,U′)(x)/IND(D) | =1且 | Sα(B,U′)(x)/IND(D) | ≠1; 3) | Sα(C,U′)(x)/IND(D) | ≠1且 | Sα(B,U′)(x)/IND(D) | ≠1。 只有满足1)时,区间值决策表DT′的约简结果依然是初始约简结果。 定理2 若满足 | Sα(C,U′)(x)/IND(D) | =1且 | Sα(B,U′)(x)/IND(D) | =1,则初始约简结果B是区间值决策表DT′的约简结果。 证明 根据正域定义,由于 | Sα(C,U′)(x)/IND(D) | =1,故POSα(C,U′)(D)=POSαC(D)∪{x},由于 | Sα(B,U′)(x)/IND(D) | =1,故POSα(B,U′)(D)=POSαB(D)∪{x}。又因为B是初始约简结果,POSαB(D)=POSαC(D),所以POSα(C,U′)(D)=POSα(B,U′)(D)。由定义9可知,对于B′B,有POSαB′(D)≠POSαB(D),POSαB′(D)POSαB(D),POSα(B′,U′)(D)POSαB′(D)∪{x},POSα(B′,U′)(D)POSαB(D)∪{x}=POSα(B,U′)(D),故POSα(B′,U′)(D)≠POSα(B,U′)(D)。因此,初始约简结果B是区间值决策表DT′的约简结果。 证毕。 基于以上分析,下面給出区间值决策表的正域单增量属性约简算法(a Single Incremental Attribute Reduction algorithm based on positive region in interval-valued decision tables, SIAR)。 算法2 区间值决策表的正域单增量属性约简算法(SIAR)。 输入 区间值决策表DT=(U,C∪D,V, f),初始约简结果B0,初始正域POSαC(D),新增对象x。 输出 论域U′上的约简结果Red。 步骤1 令B←B0,U′←U∪{x}。 步骤2 计算相容类Sα(C,U′)(x)。 步骤3 计算相容类Sα(B,U′)(x)。 步骤4 若满足 | Sα(C,U′)(x)/IND(D) | =1且 | Sα(B,U′)(x)/ IND(D) | =1, 令Red←B,返回约简结果Red;否则,转至步骤5。 步骤5 若POSα(B,U′)(D)≠POSα(C,U′)(D),重复: 步骤5.1 对所有属性ak∈C-B,计算sigouterU′(ak,B,D); 步骤5.2 选取ai=arg max{sigouterU′(ai,B,D)},令B←B∪{ai}。 步骤6 对b∈B,计算siginnerU′(b,B,D)= | POSα(B,U′)(D)-POSα(B-{b},U′)(D) | ,若siginnerU′(b,B,D)=0,令B←B-{b}。 步骤7 Red←B,返回Red。 当对象增加到区间值决策表,根据定理1更新正域,更新正域的时间复杂度是O( | U | | C | +∑ |SαC(x)| t=1 | SαC(xt) | ),为表示简洁,令Φ1=∑ |SαC(x)| t=1 | SαC(xt) | 。分别计算相容类Sα(C,U′)(x)和Sα(B,U′)(x)的时间复杂度是O( | U′ | | C | )和O( | U′ | | B | ),计算外部属性重要度的时间复杂度是O( | C-B | ( | U | | B | +Φ1)),选取属性添加到初始约简的时间复杂度是O( | C-B | ( | U | | B | +Φ1)),删除冗余属性时间复杂度是O( | B | ( | U | | B | +Φ1))。所以算法2整体的时间复杂度是O( | U | | C | 2+ | C | Φ1)。 例4 区间值决策表DT=(U,C∪D,V, f)如表1所示,新增对象x如表2所示,更新论域U′=U∪{x},令相似率阈值α=0.6,计算区间值决策表DT′=(U′,C∪D,V, f)的一个约简。 由例2得初始约简结果B={a1,a3},由例3得正域POS0.6(C,U′)(D)={x1,x3}。计算对象x在条件属性集C下的相容类S0.6(C,U′)(x)={x5,x},对象x在条件属性集B下的相容类S0.6(B,U′)(x)={x1,x5,x},由于 | S0.6(C,U′)(x)/IND(D) | ≠1且 | S0.6(B,U′)(x)/IND(D) | ≠1,故应更新初始约简结果。通过计算得POS0.6(B,U′)(D)≠POS0.6(C,U′)(D),从剩余属性集{a2,a4}中选择外部重要度最大的属性a4,POS0.6(B∪{a4},U′)(D)=POS0.6(C,U′)(D),因此B=B∪{a4}={a1,a3,a4}。由于siginner(a3,B,D)=0,所以a3为冗余属性,删除冗余属性后的约简结果Red={a1,a4}。 3 组增量属性约简 现实应用中,数据库中的数据通常批量增加,传统的非增量和单增量属性约简算法已不能满足高效处理数据的要求。针对对象集动态增加的区间值决策表,本章将分析组增量的正域更新机制,提出区间值决策表的正域组增量属性约简算法。 3.1 组增量的正域更新机制 对象集的动态增加可能导致正域发生改变,下面给出组增量的正域更新机制。 定理3 设区间值决策表DT=(U,C∪D,V, f),论域U={x1,x2,…,xn},任意条件属性子集PC,TRαP对U的分类U/TRαP={SαP(x1),SαP(x2),…,SαP(xn)},IND(D)对U的划分U/IND(D)={D1,D2,…,Dm},U在P下的初始正域为POSαP(D)。新增对象集U1={y1,y2,…,ys},TRαP对U1的分类 U1/TRαP={SαP(y1),SαP(y2),…,SαP(ys)},IND(D)对U1的划分U1/IND(D)={T1,T2,…,Tm′}。论域Ua=U∪U1,Ua在属性子集P下更新正域为:POSα(P,Ua)(D)=POSαP(D)∪POSα(P,U1)(D)-{xi∈X∧xi∈U | | Sα(P,Ua)′(xi)/IND(D) | ≠1}-{yj∈X∧yj∈U1 | | Sα(P,Ua)′(yj)/IND(D) | ≠1}。 其中,Sα(P,Ua)′(xi)和Sα(P,Ua)′(yj)表示变化的相容类,Sα(P,Ua)′(xi)=SαP(xi)∪{yj | yj∈U1,(xi,yj)∈TRαP},Sα(P,Ua)′(yj)=SαP(yj)∪{xi | xi∈U,(xi,yj)∈TRαP},X表示P在Ua上形成的具有相容关系的对象集合,X={xi∈POSαP(D),yj∈POSα(P,U1)(D) | (xi,yj)∈TRαP}。 证明 为表示简洁,令SαP′(xi)=Sα(P,Ua)′(xi), SαP′(yj)=Sα(P,Ua)′(yj)。 假设在分类U/TRαP和U1/TRαP中, 存在一些对象在属性集P下形成相容关系, 相容关系TRαP对论域Ua的分类Ua/TRαP={SαP′(x1), SαP′(x2), …, SαP′(xu), SαP(xu+1), SαP(xu+2), …, SαP(xn), SαP′(y1), SαP′(y2), …, SαP′(yu′), SαP(yu′+1), SαP(yu′+2), …, SαP(ys)},其中u∈[1, l],l为论域U中发生变化的相容类个数, u′∈[1, h], h为论域U1中发生变化的相容类个数。SαP′(xi)和SαP′(yj)表示变化的相容類,其中i∈[1,u], j∈[1,u′],对于yj∈U1,若yj∈SαP(xi),则SαP′(xi)=SαP(xi)∪{yj},由相容关系的对称性可得SαP′(yj)=SαP(yj)∪{xi}。SαP(xe)和SαP(yw)表示未改变的相容类,SαP(xe)={xf | xf∈U,(xe,xf)∈TRαP},SαP(yw)={yq | yq∈U1,(yw,yq)∈TRαP},其中e∈[u+1,n],w∈[u′+1,s]。IND(D)对Ua的划分Ua/IND(D)={D′1,D′2,…,D′v,Dv+1,…,Dm,Tv+1,…,Tm′},其中,D′z=Dz∪Tz(z=1,2,…,v),表示决策类Dz∈U/IND(D)与决策类Tz∈U1/IND(D)有相同的决策属性值。则正域更新为: POSα(P,Ua)(D)= ∪ v z=1 POSα(P,Ua)(D′z)∪ ∪ m z=v+1 POSα(P,Ua)(Dz)∪ ∪ m′ z=v+1 POSα(P,Ua)(Tz) 其中: ∪ v z=1 POSα(P,Ua)(D′z)={xk∈U | SαP(xk)D′z} ∪{yr∈U1 | SαP(yr)D′z} (k∈[1,n],r∈[1,s])-{xi | SαP′(xi)D′z}-{yj | SαP′(yj)D′z} (i∈[1,u], j∈[1,u′])。 同理可得: ∪ m z=v+1 POSα(P,Ua)(Dz) = {xk∈U | SαP(xk)Dz} - {xi | SαP′(xi)Dz} (k∈[1,n],i∈[1,u]), ∪ m′ z=v+1 POSα(P,Ua)(Tz)={yr∈U1 | SαP(yr)Tz}-{yj | SαP′(yj)Tz}(r∈[1,s], j∈[1,u′])。 通过合并化简可得正域:POSα(P,Ua)(D)=POSαP(D)∪POSα(P,U1)(D)-{xi∈X∧xi∈U | | Sα(P,Ua)′(xi)/IND(D) | ≠1}-{yj∈X∧yj∈U1 | | Sα(P,Ua)′(yj)/IND(D) | ≠1}。 证毕。 例5 区间值决策表DT=(U,C∪D,V, f)如表1所示,新增对象集U1={y1,y2,y3}如表3所示。更新论域Ua=U∪U1,令相似率阈值α=0.6,计算论域Ua在属性集C下的正域POS0.6(C,Ua)(D)。 由例1得初始正域POS0.6C(D)={x1,x3,x5},计算U1在C下的正域POS0.6(C,U1)(D)={y1,y2,y3}。对象集增加后x5和y1的相容类发生改变,S0.6(C,Ua)′(x5)=S0.6C(x5)∪{y1}={x5,y1},S0.6(C,Ua)′(y1)=S0.6(C,U1)(y1)∪{x5}={y1,x5},由于 | S0.6(C,Ua)′(x5)/IND(D) | ≠1且 | S0.6(C,Ua)′(y1)/IND(D) | ≠1,根据定理3,正域更新为POS0.6(C,Ua)(D)={x1,x3,x5}∪{y1,y2,y3}-{x5}-{y1}={x1,x3,y2,y3}。 3.2 区间值决策表的正域组增量属性约简算法 单增量约简方法每次只更新一个对象增加后的约简结果,而组增量约简方法将新增对象集视为一个整体,然后更新初始约简结果。下面给出区间值决策表的正域组增量属性约简算法(Group Incremental Attribute Reduction algorithm based on positive region in interval-valued decision tables,GIAR)。 算法3 区间值决策表的正域组增量属性约简算法(GIAR)。 输入 区间值决策表DT=(U,C∪D,V, f),初始约简结果B0,初始正域POSαC(D),新增对象集U1。 输出 论域Ua上的约简结果Red。 步骤1 令B←B0,Ua←U∪U1。 步骤2 分别计算Ua在属性集B和C上的正域POSα(B,Ua)(D)和POSα(C,Ua)(D)。若POSα(B,Ua)(D)=POSα(C,Ua)(D), 转至步骤4;否则,转至步骤3。 步骤3 若POSα(B,Ua)(D)≠POSα(C,Ua)(D),重复: 步骤3.1 对所有属性ak∈C-B,计算sigouterUa(ak,B,D); 步骤3.2 选取ai=arg max{sigouterUa(ak,B,D)},令B←B∪{ai}。 步骤4 对b∈B,计算siginnerUa(b,B,D)= | POSα(B,Ua)(D)-POSα(B-{b},Ua)(D) | ,若siginnerUa(b,B,D)=0,令B←B-{b}。 步骤5 Red←B,返回Red。 对于对象集增加的区间值决策表,根据定理3更新正域,更新正域的时间复杂度是O( | U1 | | U | | C | +∑ |X| l=1 | SαC(xl) | ),其中X表示C在U和U1上形成的具有相容关系的对象集合。为表示简洁,令Φ2=∑ |X| l=1 | SαC(xl) | 。计算外部属性重要度的时间复杂度是O( | C-B | ( | U | | U1 | | C | +Φ2)),选取属性添加到初始约简的时间复杂度为O( | C-B | ( | U | | U1 | | C | +Φ2)),删除冗余属性的時间复杂度是O( | B | ( | U | | U1 | | C | +Φ2))。所以算法3整体的时间复杂度是O( | C | ( | U | | U1 | | C | +Φ2))。 例6 区间值决策表DT=(U,C∪D,V, f)如表1所示,论域U={x1,x2,x3,x4,x5,x6}。新增对象集如表3所示,论域U1={y1,y2,y3}。计算U1增加到DT后的一个约简。 由例1得初始正域POS0.6C(D)={x1,x3,x5},由例2得初始约简结果B={a1,a3}。 对象集增加后论域更新为Ua=U∪U1,计算论域Ua在属性子集B下的正域POSα(B,Ua)(D)={x3,y2,y3},论域Ua在属性集C下的正域POSα(C,Ua)(D)={x1,x3,y2,y3}。由于POSα(B,Ua)(D)≠POSα(C,Ua)(D),从剩余属性集{a2,a4}中选择外部重要度最大的属性a4,满足POSα(B∪{a4},Ua)(D)=POSα(C,Ua)(D),因此B=B∪{a4}={a1,a3,a4}。通过计算a3为冗余属性,删除冗余属性后的约简结果Red={a1,a4}。 4 实验结果及分析 实验选取区间值决策表中基于信息熵的属性约简算法[31]与本文所提算法进行比较,为方便表示,将文献[31]中的算法记为CEAR。本章实验分为两部分:第一部分比较单增量算法SIAR、组增量算法GIAR、非增量算法CAR与算法CEAR的约简结果;第二部分比较算法SIAR、GIAR、CAR与CEAR的约简效率。 实验环境:操作系统Windows 7;处理器Intel Corei5-6500;内存8.00GB;程序运行环境python3.6;采用PyCharm编码。实验选取8组UCI数据集,数据集描述如表4所示。实验使用WEKA3.6对数据进行预处理,对于属性缺失值,取该属性下比重最大的属性值,使用等频分割方法[32]处理连续型的数据,用整数代替名词性数据。由于实验数据采用区间型数据,文献[32]已给出单值数据转化为区间型数据的方法,阈值ω用于调节区间值长度,取ω=2.4。 4.1 约简结果比较 本节通过实验比较单增量算法SIAR、组增量算法GIAR、非增量算法CAR与算法CEAR的约简结果。实验中,令阈值ω=2.4,相似率阈值α=0.8。对表4中每个UCI数据集,选取60%的对象作为基础对象集,剩余40%作为新增对象集,当新增对象集增加到基础对象集后,分别利用算法SIAR、GIAR、CAR和CEAR计算约简结果。四种算法的约简结果比较如表5所示。 集合1={1,2,3,4,5,6,8,10,12,16,17,18,19},集合 2={2,3,4,5,6,7,8,10,12,16,17,18,19},集合3={1,2,3,4,5, 6,8,10,12,16,17,18,19},集合4={1,2,3,4,5,6,8,10,12,16,17,18,19},集合5={1,2,3,4,6,7,9,10,12,13,14,15,17,20,21,22},集合6={1,2,4,7,8,9,10,12,13,14,15,17,19,20,21,22},集合7={1,2,3,4,5,7,9,10,12,13,14,16,17,20,21,22},集合8={1,2,3,4,5,7,9,10,12,13,14,16,17,20,21,22},集合9={1,2,3,4,5,6,9,11,13,15,16,18},集合10={1,2,3,4,5,6,7,11,14,15,16,18},集合11={1,2,3,4,5,6,7,11,14,15,16,18},集合12={1,2,3,4,5,6,9,11,13,15,16,18},集合13={1,2,3,4,5,7,8,9,12,13,14},集合14={1,2,3,5,6,7,8,9,12,13,14},集合15={1,2,3,4,5,7,8,9,12,13,14},集合16={1,2,3,4,5,7,8,9,12,13,14}。 表5中实验结果表明,增量算法SIAR、GIAR与非增量算法CAR的约简结果可能不同,但三个算法的约简结果不仅保持了相同的正域,而且不存在冗余属性,即算法SIAR、GIAR所得约简均为正确约简结果,存在差异的原因是启发式约简算法执行一次只能获得一个约简结果。由表5可知,单增量算法SIAR和组增量算法GIAR的约简结果可能不同,例如:编号为7的数据集,单增量算法SIAR的约简结果为{1,2,3,5,6,7,8,9,12,13,14},组增量算法GIAR的约简结果为{1,2,3,4,5,7,8,9,12,13,14}。导致约简结果不同的可能原因:一是由于约简过程中属性的添加顺序不同,导致删除的冗余属性不同。例如:若存在两个属性都为冗余属性,则优先删除两者中位于前面的属性,因此所得约简结果不同。二是由于单增量算法SIAR和组增量算法GIAR更新约简结果的方式不同,算法SIAR执行一次只能获得单个对象增加后的约简结果,而算法GIAR将对象集视为整体更新约简结果。由表5中算法CAR、SIAR、GIAR、CEAR的约简长度可以看出,增量算法SIAR和GIAR可以有效去掉冗余属性,对于8组UCI数据集,增量算法SIAR、GIAR和非增量算法CAR所得约简结果的长度相同。 4.2 約简效率比较 本节通过实验比较算法CAR、SIAR、GIAR和CEAR的约简效率,验证组增量算法GIAR的高效性。对表4中每个UCI数据集,取60%的对象作为基础对象集,剩余40%分为8等份,每份表示为xi(i=1,2,…,8),Xi= ∪ i j=1 xi(i=1,2,…,8)为实验中每次新增的对象集,例如:第1次新增对象集X1=x1,第2次新增对象集X2=x1∪x2,以此类推,第8次新增对象集X8=x1∪x2∪…∪x8。令相似率阈值α=0.8,分别将X1,X2,…,X8增加到基础对象集后,采用算法CAR、SIAR、GIAR和CEAR计算约简。图1给出了算法CAR、SIAR、GIAR和CEAR计算约简的时间对比,其中x轴表示不同规模的新增对象集,数值1,2,…,8分别表示将对象集X1,X2,…,X8增加到基础对象集,y轴表示计算约简的时间耗费。 图1中的实验结果表明,当不同规模的对象集增加到基础对象集后,组增量算法GIAR的约简效率优于单增量算法SIAR,单增量算法SIAR的约简效率优于非增量算法CAR。增量算法SIAR和GIAR比非增量算法CAR的约简效率高,原因是对象集每次动态增加时,非增量算法CAR要重新计算约简,而增量算法SIAR和GIAR在初始约简的基础上获得更新后区间值决策表的约简结果,因此提高了约简效率。单增量算法SIAR和组增量算法GIAR相比,算法GIAR计算约简的时间少于算法SIAR,原因是算法GIAR将新增对象集视为整体,更新一次可得约简结果,而算法SIAR每次只增加一个对象,要重复更新求解约简。算法CEAR与组增量算法GIAR相比,算法GIAR计算约简的时间远远少于算法CEAR。而且在大多数的数据集中,随着新增对象集规模不断增大,算法GIAR的高效性更明显。因此,实验结果表明了算法GIAR的高效性。 5 结语 针对区间值决策表中对象集动态增加的情况,本文分析了单增量和组增量的正域更新机制,提出了区间值决策表的正域单增量和组增量属性约简算法。实验选取8组UCI数据集,分别运用非增量、单增量和组增量的正域属性约简算法和算法CEAR计算约简,实验结果验证了增量算法的高效性。本文主要针对对象集的动态增加分析了增量式属性约简,下一步将针对属性集的动态增加和属性值的动态改变进行增量式属性约简的研究。 参考文献 [1] PAWLAK Z. Rough sets [J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356. [2] 王国胤,姚一豫,于洪.粗糙集理论与应用研究综述[J].计算机学报,2009,32(7):1229-1246. (WANG G Y, YAO Y Y, YU H. A survey on rough set theory and applications [J]. Chinese Journal of Computers, 2009, 32(7): 1229-1246.) [3] LI D, ZHANG B, LEUNG Y. On knowledge reduction in inconsistent decision information systems [J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2004, 12(5): 651-672. [4] QIAN Y, LIANG J, PEDRYCZ W, et al. Positive approximation: an accelerator for attribute reduction in rough set theory [J]. Artificial Intelligence, 2010, 174(9/10): 597-618. [5] 苗夺谦,胡桂荣.知识约简的一种启发式算法[J].计算机研究与发展,1999,36(6):681-684. (MIAO D Q, HU G R. A heuristic algorithm for reduction of knowledge [J]. Journal of Computer Research and Development, 1999, 36(6): 681-684.) [6] XU W, LI Y, LIAO X. Approaches to attribute reductions based on rough set and matrix computation in inconsistent ordered information systems [J]. Knowledge-Based Systems, 2012, 27: 78-91. [7] MIN F, HE H, QIAN Y, et al. Test-cost-sensitive attribute reduction [J]. Information Sciences, 2011, 181(22): 4928-4942. [8] HU X, CERCONE N. Learning in relational databases: a rough set approach [J]. International Journal of Computational Intelligence, 1995, 11(2): 323-338. [9] QIAN Y, LIANG X, WANG Q, et al. Local rough set: a solution to rough data analysis in big data [J]. International Journal of Approximate Reasoning, 2018, 97: 38-63. [10] JIA X, LIAO W, TANG Z, et al. Minimum cost attribute reduction in decision-theoretic rough set models [J]. Information Sciences, 2013, 219: 151-167. [11] LEUNG Y, FISCHER M M, WU W-Z, et al. A rough set approach for the discovery of classification rules in interval-valued information systems [J]. International Journal of Approximate Reasoning, 2008, 47(2): 233-246. [12] 張楠,苗夺谦,岳晓冬.区间值信息系统的知识约简[J].计算机研究与发展,2010,47(8):1362-1371. (ZHANG N, MIAO D Q, YUE X D. Approaches to knowledge reduction in interval-valued information systems [J]. Journal of Computer Research and Development, 2010, 47(8): 1362-1371.) [13] 刘鹏惠,陈子春,秦克云.区间值信息系统的决策属性约简[J].计算机工程与应用,2009,45(28):148-151. (LIU P H, CHEN Z C, QIN K Y. Decision attribute reduction of interval-valued information system [J]. Computer Engineering and Applications, 2009, 45(28): 148-151.) [14] 徐菲菲,雷景生,毕忠勤,等.大数据环境下多决策表的区间值全局近似约简[J].软件学报,2014,25(9):2119-2135. (XU F F, LEI J S, BI Z Q, et al. Approaches to approximate reduction with interval-valued multi-decision tables in big data [J]. Journal of Software, 2014, 25(9): 2119-2135.) [15] DAI J, WANG W, XU Q, et al. Uncertainty measurement for interval-valued decision systems based on extended conditional entropy [J]. Knowledge-Based Systems, 2012, 27: 443-450. [16] SHU W, QIAN W, XIE Y. Incremental approaches for feature selection from dynamic data with the variation of multiple objects [J]. Knowledge-Based Systems, 2019, 163: 320-331. [17] JING Y, LI T, FUJITA H, et al. An incremental attribute reduction method for dynamic data mining [J]. Information Sciences, 2018, 465: 202-218. [18] WEI W, WU X, LIANG J, et al. Discernibility matrix based incremental attribute reduction for dynamic data [J]. Knowledge-Based Systems, 2018, 140: 142-157. [19] XIE X, QIN X. A novel incremental attribute reduction approach for dynamic incomplete decision systems [J]. International Journal of Approximate Reasoning, 2018, 93: 443-462. [20] HU F, WANG G Y, HUANG H, et al. Incremental attribute reduction based on elementary sets [C]// Proceedings of the 10th International Conference on Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing, LNCS 3641. Berlin: Springer, 2005: 185-193. [21] XU Y, WANG L, ZHANG R. A dynamic attribute reduction algorithm based on 0-1 integer programming [J]. Knowledge-Based Systems, 2011, 24(8): 1341-1347. [22] 楊明.一种基于改进差别矩阵的属性约简增量式更新算法[J].计算机学报,2007,30(5):815-822. (YANG M. An incremental updating algorithm for attribute reduction based on improved discernibility matrix [J]. Chinese Journal of Computers, 2007, 30(5): 815-822.) [23] LIANG J, WANG F, DANG C, et al. A group incremental approach to feature selection applying rough set technique [J]. IEEE Transactions on Knowlede and Data Engineering, 2014, 26(2): 294-308. [24] SHU W, QIAN W. An incremental approach to attribute reduction from dynamic incomplete decision systems in rough set theory [J]. Data and Knowledge Engineering, 2015, 100(Part A): 116-132. [25] YU J, XU W. Incremental knowledge discovering in interval-valued decision information system with the dynamic data [J]. International Journal of Machine Learning and Cybernetics, 2017, 8(3): 849-864. [26] WANG F, LIANG J, QIAN Y. Attribute reduction: a dimension incremental strategy [J]. Knowledge-Based Systems, 2013, 39: 95-108. [27] LIU D, LI T, ZHANG J. Incremental updating approximations in probabilistic rough sets under the variation of attributes [J]. Knowledge-Based Systems, 2015, 73: 81-96. [28] CHENG Y. The incremental method for fast computing the rough fuzzy approximations [J]. Data and Knowledge Engineering, 2011, 70(1): 84-100. [29] CHEN H, LI T, QIAO S, et al. A rough set based dynamic maintenance approach for approximations in coarsening and refining attribute values [J]. International Journal of Intelligent Systems, 2010, 25(10): 1005-1026. [30] 張楠,许鑫,童向荣,等.不协调区间值决策系统的知识约简[J].小型微型计算机系统,2017,38(7):1585-1589. (ZHANG N, XU X, TONG X R, et al. Knowledge reduction in inconsistent interval-valued decision systems [J]. Journal of Chinese Computer Systems, 2017, 38(7): 1585-1589.) [31] DAI J-H, HU H, ZHENG G-J, et al. Attribute reduction in interval-valued information systems based on information entropies [J]. Frontiers of Information Technology and Electronic Engineering, 2016, 17(9): 919-928. [32] ZHANG X, MEI C, CHEN D, et al. Multi-confidence rule acquisition and confidence-preserved attribute reduction in interval-valued decision systems [J]. International Journal of Approximate Reasoning, 2014, 55(8): 1787-1804.
