基于深度多视图特征距离学习的行人重识别
2019-10-23邓轩廖开阳郑元林袁晖雷浩陈兵
邓轩 廖开阳 郑元林 袁晖 雷浩 陈兵
摘 要:传统手工特征很大程度上依赖于行人的外观特征,而深度卷积特征作为高维特征,直接用来匹配图像会消耗大量的时间和内存,并且来自较高层的特征很容易受到行人姿势背景杂波影响。针对这些问题,提出一种基于深度多视图特征距离学习的方法。首先,提出一种新的整合和改善深度区域的卷积特征,利用滑框技术对卷积特征进行处理,得到低维的深度区域聚合特征并使其维数等于卷积层通道数;其次,通过交叉视图二次判别分析方法,从深度区域聚合特征和手工特征两个角度出发,提出一种多视图特征距离学习算法;最后,利用加权融合策略来完成传统特征和卷积特征之间的协作。在Market-1501和VIPeR数据集上的实验结果显示,所提融合模型的 Rank1 值在兩个数据集上分别达到80.17% 和75.32%;在CUHK03数据集新分类规则下,所提方法的 Rank1 值达到33.5%。实验结果表明,通过距离加权融合之后的行人重识别的精度明显高于单独的特征距离度量取得的精度,验证了所提的深度区域特征和算法模型的有效性。
关键词:行人重识别;卷积神经网络;区域聚合特征;加权融合策略;距离度量
中图分类号: TP183; TP391.4
文献标志码:A
Person re-identification based on deep multi-view feature distance learning
DENG Xuan1, LIAO Kaiyang1,2*, ZHENG Yuanlin1,3, YUAN Hui1, LEI Hao1, CHEN Bing1
Abstract: The traditional handcrafted features rely heavily on the appearance characteristics of pedestrians and the deep convolution feature is a high-dimensional feature, so, it will consume a lot of time and memory when the feature is directly used to match the image. Moreover, features from higher levels are easily affected by human pose or background clutter. Aiming at these problems, a method based on deep multi-view feature distance learning was proposed. Firstly, a new feature to improve and integrate the convolution feature of the deep region was proposed. The convolution feature was processed by the sliding frame technique, and the integration feature of low-dimensional deep region with the dimension equal to the number of convolution layer channels was obtained. Secondly, from the perspectives of the deep regional integration feature and the handcrafted feature, a multi-view feature distance learning algorithm was proposed by utilizing the cross-view quadratic discriminant analysis method. Finally, the weighted fusion strategy was used to accomplish the collaboration between handcrafted features and deep convolution features. Experimental results show that the Rank1 value of the proposed method reaches 80.17% and 75.32% respectively on the Market-1501 and VIPeR datasets; under the new classification rules of CHUK03 dataset, the Rank1 value of the proposed method reaches 33.5%. The results show that the accuracy of pedestrian re-identification after distance-weighted fusion is significantly higher than that of the separate feature distance metric, and the effectiveness of the proposed deep region features and algorithm model are proved.
Key words: person re-identification; Convolutional Neural Network (CNN); regional integration feature; weighted fusion strategy; distance metric
0 引言
行人重识别问题是通过多个摄像机视图判断行人是否为同一目标的过程,当前已广泛应用于跟踪任务的视频分析和行人检索中。但是在实际生活中,由于行人重识别受到视角、光照、姿态、背景杂波和遮挡等因素的影响,使得行人图像在不重叠的摄像机视图中的差异性较大,如何减少和降低这种差异性对行人重识别的影响,是当前行人重识别中存在的巨大问题和面临的严峻挑战。
特征表示和度量学习是行人重识别系统中的两个基本要素,而且由于特征表示是构成距离度量学习的基础,使其在行人重识别系统中显得尤为重要。虽然度量学习具有一定的有效性,但它很大程度上取决于特征表示的质量。因此,当前许多研究致力于开发更加复杂和具有鲁棒性的特征,用以描述可变条件下的视觉外观,可以将其提取的特征划分为两类:传统特征和深度特征。
部分学者对传统特征的研究多集中于设计具有区分性和不变性特征,着手于不同外观特征的拼接,克服了重识别任务中的交叉视图的外观变化,使得识别更加可靠。Liao等[1]提出局部最大出现特征(Local Maximal Occurrence Feature, LOMO)来表示每个行人图像的高维特征,不仅从图像中提取尺度不变的局部三元模式(Scale Invariant Local Ternary Pattern, SILTP)和HSV(Hue, Saturation, Value)颜色直方图以形成高级描述符,还分析局部几何特征的水平发生,并最大化出现以稳定地表示行人图像。
当前深度学习提供了一种强大的自适应方法来处理计算机视觉问题,而无需过多地对图像进行手工操作,广泛应用于行人重识别领域。部分研究侧重于通过卷积神经网络(Convolutional Neural Network, CNN)框架学习特征和度量,将行人重新编码作为排序任务,将图像对[2]或三元组[3]输入CNN。由于深度学习需要依赖于大量的样本标签,因而使得该方法在行人重识别领域中具有应用的局限性。
度量学习旨在开发一种判别式匹配模型来测量样本相似性,例如针对类内样本数目少于类间样本数目的情况,丁宗元等[4]提出了基于距离中心化的相似性度量算法。Kestinger等[5]通过计算类内和类间协方差矩阵之间的差异,设计了简单而有效的度量学习方法,但是所提出的算法对特征表示的维度非常敏感。作为一种改进,Liao等[1]通过同时学习更具辨别性的距离度量和低维子空间提出了一种交叉视图二次判别分析(Cross-view Quadratic Discriminant Analysis, XQDA)方法。从实验结果来看,XQDA是一种可以实现高性能的鲁棒性方法。
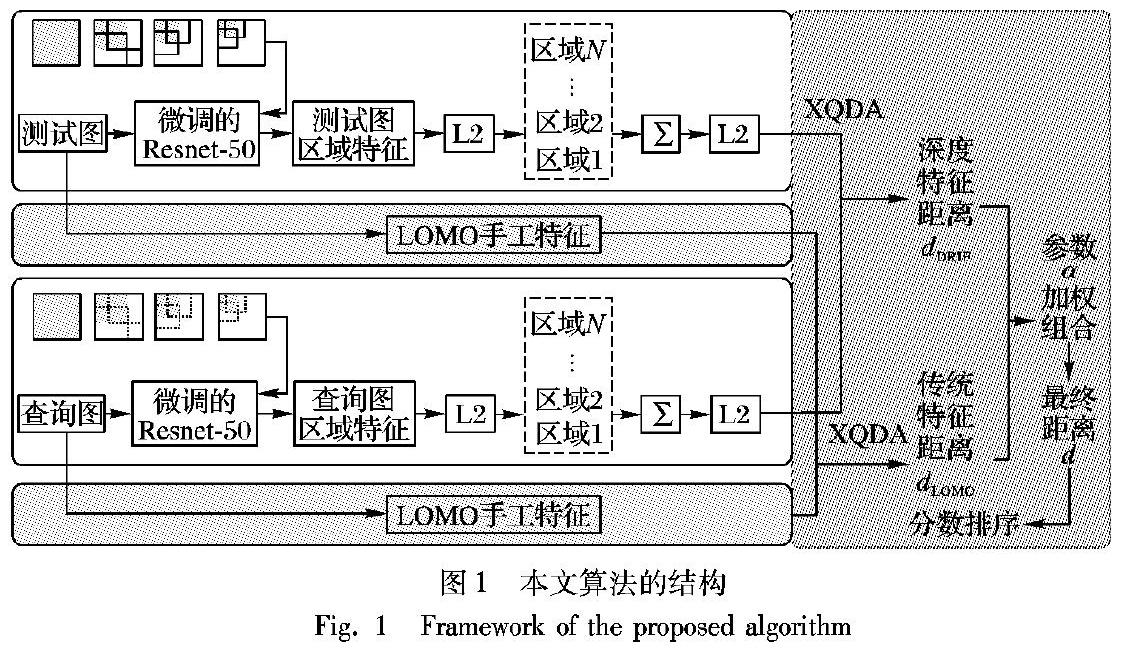
卷积神经网络提取的特征对图像具有较强的描述能力,通常可以提取三维的卷积特征以及单维的全连接特征向量,但卷积层特征比全连接层特征更适合用来识别图像,故本文使用微调过的Resnet-50模型作为研究的网络模型,提取其卷积层的特征。由于卷积特征是三维特征,如果将其展成一维的特征向量,其维数必然很高,使用高维特征在数据库中的图像进行匹配,必然会花费大量的时间,增加计算的复杂度。因此如何将三维特征变成一维,并能够保证特征的简单化是本次研究的一个核心问题,基本思路是将通过滑框操作,将三维的卷积特征压缩成一维的特征向量。由于来自较高层的特征具有大的感受野,容易受到人类姿势和背景杂波的污染,不能充分地应用于行人的重识别。而手工制作的不同的外观特征,旨在克服重新识别任务中的跨视图外观变化,有时会更加独特和可靠。所以本次研究的另一个核心问题是如何通过操作完成深度特征和传统手工特征的融合,使之相互影响、互相协作,进而提高识别的准确度。于是,本次研究利用区域特征向量聚合的方法,在微调卷积神经网络的基础上,提出了一个新的低维深度特征向量,并提出了一种深度多视图特征距离学习的算法模型,从深度区域聚合特征和传统手工特征两个角度出发,利用加权策略,以一种有效的方式完成深度特征与传统手工特征之间的协作,用参数加权融合来调整两个特征的相对重要性。
本文的工作主要体现在以下两个方面:
1)提出新的区域特征向量聚合的方法,将高维卷积特征向量变成低维的全局特征向量,并提高了图像局部信息的描述能力。
2)提出了深度多视图特征距离学习的新方案,从深度区域聚合特征和传统手工特征两个角度出发,通过XQDA度量学习完成传统特征和深度特征之间的协作,利用参数加权融合的方式来判断传统特征和深度特征的相对重要性。
1 相关工作
特征表示是行人重识别的基本问题。许多现有的研究集中于开发强大和复杂的特征来描述在显著不同的条件下产生的高度可变的视觉外观。
手工制作的特征经常用于行人识别,例如通过利用对称和不对称的感性主体,Farenzena等[6]提取了三种特征类型来模拟人类外观,包括最大稳定颜色区域、加权颜色直方图和经常性高结构色块。LOMO通过分析局部特征的水平发生,并最大化出现以稳定地表示重新识别图像。这些方法对解决低分辨率和遮挡图像以及姿态、照明和视点变化带来的识别问题都很有效。由于传统的颜色信息不是描述颜色的最有效的方法,张耿宁等[7]将颜色标签特征与颜色和纹理特征融合,并通过区域和块划分的方式提取直方图来描述图像特征。不同外观组合成的传统特征向量通常维数较高,为了解决这个问题,孙金玉等[8]提出典型相关分析(Canonical Correlation Analysis, CCA)方法进行特征投影变换,通过提高特征匹配能力来避免高维特征运算引起的维数灾难问题,
鉴于CNN的成功,使用CNN学习深度特征最近受到关注。目前有许多研究在寻求行人外观的独特和有效特征的组合,并且证明利用集成编码的补充信息来发现完整数据表示的多视图特征是可行的。Wu等[2]提出的特征融合网络(Feature Fusion Network, FFN)将卷积神经网络(CNN)深度特征和手工提取的特征(RGB、HSV、YCbCr、Lab、YIQ五种颜色空间提取的颜色特征和多尺度多方向Gabor滤波器提取的纹理特征)相结合,认为传统的直方图特征可以补充CNN特征,并将两者融合,得到了一个更具辨别性和紧密性的新的深度特征表示。Tao等[9]提出用折衷参数来完成深度特征与传统特征的协作,文中所构建的網络模型卷积层数少,深度特征采用全连接层特征。相比之下,对于特定任务的识别来说,较高的卷积层特征更适合用于图像识别,故本文采用微调的深度网络模型,并对卷积特征采用滑框操作,形成区域特征向量,并利用加权融合策略来判断深度区域特征和LOMO特征的相对重要性。
子空间 W 通过学习优化广义瑞利熵来得到:
J( w )= w T Σ E w w T Σ I w
(5)
其中具有交叉视图数据的子空间 W =( w 1, w 2,…, w r),表示在r维子空间中去学习交叉视图相似性度量的距离函数。
来自不同摄像机下的一对行人样本数据( x i, x j)在子空间 W 的距离函数如式(6)所示:
d( x i, x j)= ( x i- x j)T W ×(( W T Σ I W )-1-( W T Σ E W )-1)× W T( x i- x j)
(6)
2.4 加权融合策略
由于提出的深度特征学习模型与实际问题直接相关,但来自较高层的特征可能受到行人姿势背景杂波等显著变化的污染,不能充分地定位于行人的重识别;并且深度网络依赖大量的样本标签,而传统的LOMO特征与样本数量无关,在克服重新识别任务中的跨视图外观变化时会更加可靠。所以整合两种特征的编码补充信息以克服它们各自的缺陷是有效的。
具体而言,从深度区域聚合特征和LOMO特征这两个角度考虑,XQDA从这两个特征分别学习测试库和查询库图像之间的距离。基于 LOMO、本文提出的DRIF两个特征,采用式(6)定义的距离函数可分别获取每个特征优化的距离度量,如式(7)所示:
dk( x ik, x jk)= ( x ik- x jk)T W k×(( W Tk Σ I W k)-1-
( W Tk Σ E W k)-1)× W kT( x ik- x jk)
(7)
式中:k分别代表LOMO和DRIF两个不变特征。
为了更好地表达传统和深度学习功能之间的协作,最终用于排序的距离可以通过以下加权平均方案将深度特征得到的距离与传统特征得到的距离融合:
d=αdLOMO+(1-α)dDRIF
(8)
其中
参数0≤α≤1用来调整区域聚合深度特征和传统特征的相对重要性。
3 实验结果与分析
3.1 数据集和评估协议
本文使用三个重识别数据集,其中在两个大规模行人重识别基准数据集Market-1501[12]和CUHK03[13]上进行实验,这两个数据集包含每个测试图像的多个正样本。另外,本文还在具有挑战性的数据集VIPeR上进行重识别实验。
本文使用三个重识别数据集进行实验,包括:Market-1501[12]、CUHK03[13]和VIPeR,它们的
具体信息如表1所示。其中:#ID表示数据集中含有的行人身份;#image表示数据集中含有的行人的图像的数量;#camera表示该数据集使用的相机的数量;evaluation表示实验中对数据集所用的评估方法。
所有行人图像的大小调整为224×224,用调整后的行人图像来微调网络,提取卷积特征。
Market-1501是目前最大的基于图像的行人基准数据集。它包含32668个标记的边界框,其中包含从不同视点捕获的1501个身份,每个行人身份的图像最多由6台摄像机拍摄。根据数据集设置,将数据集分为两部分:训练集有751人,包含12936张图像;测试集有750人,包含19732张图像。
实验时,从测试集中人为选取750 人,共有3368幅图像作为查询集合,对于查询集中给定的行人样本,需要在测试集中找出和该样本一样的行人,最后根据相似度排名给出识别结果。
CUHK03包含1467位行人的13164幅图像。每个行人都是由CUHK校园的两台摄像机拍摄的,每位行人在一个摄像头下平均有4.8张图像。该数据库提供了labeled和detected两个数据集,本文对这两个数据集分别进行了实验。
VIPeR是行人重识别中使用最广泛的数据集,包含632个行人,每个行人包含不同视点中的两幅图像,这使得难以从两个不同的视点中匹配同一个人。此外,诸如拍摄地点、照明条件和图像质量等其他变化也使得匹配相同行人更加困难。因此,VIPeR数据集具有挑战性。
本文将行人重识别作为图像检索问题来处理,使用Rank1即第一次命中的匹配准确率和平均准确率(mean Average Precision, mAP)两个评估指标来评估Market-1501和CUHK03数据集上重识别方法的性能,而使用累计匹配曲线(Cumulative Matching Characteristic, CMC)来评估数据集VIPeR上重识别方法的性能。
3.2 在Market-1501上的实验
本文首先在最大的基于图像的重识别数据集上评估提出的算法模型。在此数据集中,在微调的ResNet-50上提取最后一层卷积特征,并对产生的卷积映射进行滑框操作,产生多个局部特征向量,经过L2归一化处理,并直接相加操作后,得到低维的深度特征,其向量维数等于卷积层通道数,故得到的新的深度特征向量维数为2048维。接着使用LOMO特征和本文提出的区域整合特征向量通过参数α的加权融合完成二者的协作。在此数据集上,本文设置滑框尺度L=4,加权参数α=0.5,用参数α加权来评估传统LOMO特征和区域聚合深度特征的相对重要性。
与本文提出的算法模型Fusion Model进行比较的算法包括:
对称驱动的局部特征积累(Symmetry-Driven Accumulation of Local Features, SDALF)[6],词袋模型(Bag-of-Words model, BOW)[12],LOMO[1],CAN[14],ID判别嵌入(ID-discriminative Embedding, IDE)[15](其中IDE(C)表示所用模型為Caffe,IDE(R)表示所用模型为Resnet-50),姿态不变嵌入(Pose Invariant Embedding, PIE)[161和Spindle Net[17]。
表2的结果显示,本文的Fusion Model与PIE(Res50)相比Rank 1性能要高1.52个百分点。本文提出了深度区域聚合特征向量(DRIF),在此特征向量的基础上提出了距离融合模型,所以将本文的Fusion Model与DRIF相比较,Rank1的值提高了3.77个百分点,mAP值提高了5.46个百分点,说明本文提出的算法模型是有效的。
为了说明通过微调网络得到的新的区域整合特征向量的鲁棒性,将XQDA度量应用于新的区域整合向量与另外几种已有的特征包括BOW[12]、LOMO[1]、IDE(C)[15]、IDE(R)[15]进行比较,结果如表3所示,本文提出的DRIF特征与IDE(R)特征相比Rank1值提高了4.99个百分点,mAP值提高了7.15个百分点。
图2是三个示例图片的查询结果,对应每一幅查询图片,右边第一行和第二行分别是使用IDE和DRIF特征得到的排名结果,框中的行人图片表示与查询图属于同一个行人。由图2可以看出,对于DRIF特征,在排名列表顶部能够得到更多正确匹配的行人,而正确匹配的行人图片在IDE的排名列表中被遗漏,进一步说明本文提出的DRIF特征是具有判别性的。
3.3 在CUHK03上的实验
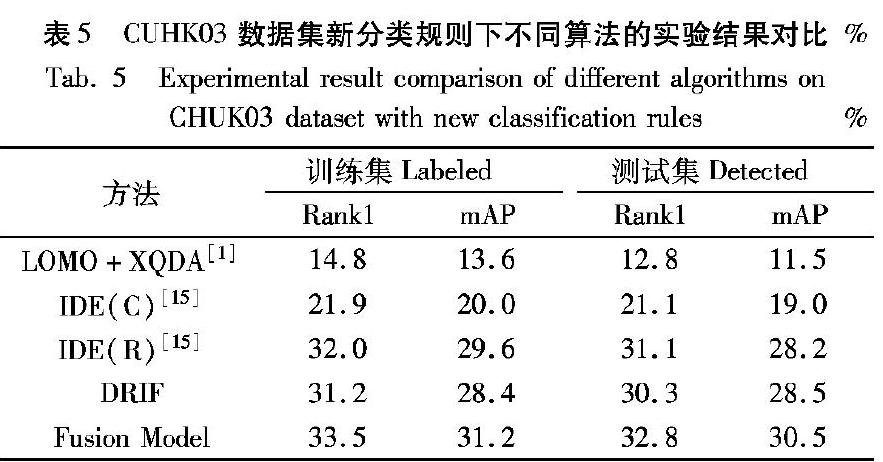
在CUHK03上数据集上,本文使用类似于Market-1501的新训练/测试协议重新评估性能。新协议将数据集分为训练集和测试集,分别由767个行人和700个行人组成。在测试中,从每个摄像机中随机选择一个图像作为每个图像的查询,并使用其余图像构建测试。新协议将数据集均匀地划分为训练集和测试集,有利于避免重复训练和测试。对于CUHK03数据集的新的分类情况如表4所示。
本文设置滑框尺度L=4、加权参数α=0.5,表5的结果表明,本文提出的Fusion Model比LOMO特征[1]、IDE(C)[15]和IDE(R)[15]得到的性能要好。
本文提出的Fusion Model与DRIF相比:在训练集“Labeled”上的Rank1值要高2.3个百分点,mAP值要高2.8个百分点;在测试集“Detected”上的Rank1值要高2.5个百分点,mAP值要高2.0个百分点。这说明本文提出的加权融合模型(Fusion Model)是有效的。
3.4 在VIPeR上的实验
VIPeR数据集包含的行人图像样本数量少,因此无法用该数据集的图像作为标签来微调网络,所以本文采用的仍然是使用Market-1501数据集的图像微调过的Resnet-50模型。实验结果表明,在提取同一层卷积特征,并都对卷积特征进行区域特征提取的条件下,使用微调过后的模型比未改进的模型效果要好,说明使用行人重识别数据集微调网络使模型对于判别不同身份的行人是非常有效的。
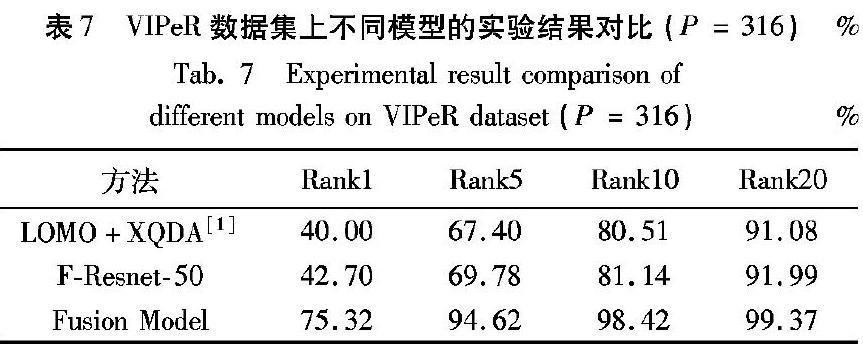
本文采用了广泛使用的CMC方法对性能进行定量评估。 对于VIPeR,随机选取大约一半人(316人)进行训练,其余人员用于测试。使用单次评估方法,并将VIPeR测试集划分为参考集和测试集。在VIPeR数据集上,设置滑框尺度L=4,加权参数α=0.8,对比算法包括深度多视图特征(Deep Multi-View Feature, DMVFL)[9]、Deep Feature Learning[3]、LOMO特征[1]、CNN[18]。当α=0.8时, Rank1的值为7532%。排名前1、5、10、20(即Rank1、Rank5、Rank10和Rank20)的结果见表6。
由表6可知,本文提出的加权融合策略在此数据集上得到的性能最好;而且与另外两大数据集Market-1501和CHUK03相比,该算法模型在VIPeR数据集上得到的效果是最显著的。
为了进一步说明文中所提融合模型在VIPeR数据集上的有效性,在使用同一度量方法XQDA的前提下,使用融合模型、LOMO特征、Resnet-50模型和微调的Resnet-50模型得到的性能如表7所示。表7中的结果表明本文所提算法模型效果显著,由于LOMO特征强调HSV和SILTP直方图,因此它在特定照明条件下表现效果更佳。视角和光照的多样性是VIPeR数据集的特点,表7中的结果表明本文提出的加权融合模型在背景、照明和视点等方面有大幅变化的数据集上效果最明显,能够显著提高行人重识别的性能。本文提出的融合模型得到的性能优于LOMO特征,与单独使用
LOMO特征以及使用F-Resnet-50模型提取卷积特征并对特征进行滑框操作得到的区域聚合特征进行距离度量相比,融合
LOMO特征和深度区域聚合特征(DRIF)这两个特征距离能够得到较高的识别率,说明这两个特征距离的融合具有强烈的判别能力,并进一步表明本文提出的区域聚合特征是LOMO特征的互补特征。
3.5 微调策略分析
使用MatConvNet(Convolutional neural Networks for Matlab)工具,利用ImageNet模型训练Market-1501数据集。对于网络Resnet-50使用默认参数设置,并从ImageNet预先训练好的模型中进行微调。图像在被送入网络之前被调整224×224大小;初始学习率设置为0.001,并在每次迭代后减少至上一次的1/10,训练迭代36次之后完成。
为了证明微调策略的有效性,在VIPeR数据集上用微调的模型进行实验,分别用Resnet-50网络以及微调过后的Resnet-50网络(Fine-tuning Resnet-50, F-Resnet-50)提取卷積层特征,并对两个模型提取的同一层三维卷积特征利用区域聚合特征方法变成2048维的特征向量,并进行距离度量。表8中的结果表明,利用行人重识别数据集微调过后的网络模型提高了区分能力,减少了错误检测对背景的影响,并提高了识别率。
3.6 参数分析
如图1区域聚合部分所示,在滑框与滑框之间,都存在一定的重叠区域,而最终采用简单的加和方式把局部的区域特征向量整合成全局特征,其中那些重叠的区域可以认为是给予了较大的权重。因此,并不是将特征平面分得越细越好。在本文中,滑框之间的重叠率取40%。在实验中,使用L种不同尺度的滑框处理特征平面在数据集CUHK03上进行实验,结果如表9所示,可以看出,当L=4时,将提出的新的区域聚合特征向量用于度量时的效果最好。
当L=4时,将提出的新的区域聚合特征向量用于度量时的效果最好。 为了克服传统特征和深度特征各自的缺陷,用参数α加权评估深度区域特征向量和传统LOMO特征的相对重要性。其中0≤α≤1,由图3可知,当α=0.5时,在Labeled和Detected两个数据集上的Rank1和mAP值都最高,即在CUHK03数据集得到的性能最好。
3.7 运行时间分析
如表10所示是VIPeR数据集上单个图像的平均特征提取时间。可以看出,本文提出的深度区域特征提取方法比一些手工特征提取方法更快,例如基于生物启发特征的协方差描述符(Covariance descriptor based on Bio-inspired features, gBiCov)[19];与LOMO手工特征、CNN特征、FFN特征相比,本文提出的DRIF特征的维度是2048维,具有更低的维度,并且其维度等于卷积层通道数。通过在速度和维度复杂性之间取得平衡,本文提出的区域特征向量提取算法可以实际应用。
4 结语
本文构建了一个完整的行人重识别的算法模型,通过微调的Resnet-50网络提取三维卷积特征,并把不同尺度的滑框作用于卷积激活映射,得到了低维的区域聚合特征向量;从深度区域聚合特征和传统手工特征LOMO两个角度出发,用参数加權来评估各自的相对重要性,并利用有效的加权融合方式得到最终用于计算的距离,用最终距离进行识别排序。在Market-1501、CHUK03和VIPeR三个数据集上进行测试,在重新训练网络的情况下,大量实验表明本文提出的算法模型在指标Rank1和mAP上均具有较明显的提升,展示了所提算法模型的有效性。下一步的研究方向是提取出更鲁棒性的特征,使其能够更具有判别性,使多视图特征融合方法能够显著提高行人重识别的性能。
参考文献 (References)
[1] LIAO S, HU Y, ZHU X, et al. Person re-identification by local maximal occurrence representation and metric learning [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 2197-2206.
[2] WU S, CHEN Y-C, LI X, et al. An enhanced deep feature representation for person re-identification [C]// Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision. Washington, DC: IEEE Computer Society, 2016: 1-8.
[3] DING S, LIN L, WANG G, et al. Deep feature learning with relative distance comparison for person re-identification [J]. Pattern Recognition, 2015, 48(10): 2993-3003.
[4] 丁宗元,王洪元,陈付华,等.基于距离中心化与投影向量学习的行人重识别[J].计算机研究与发展,2017,54(8):1785-1794. (WANG Z Y, WANG H Y, CHEN F H, et al. Person re-identification based on distance centralization and projection vectors learning [J]. Journal of Computer Research and Development, 2017, 54(8): 1785-1794.)
[5] KSTINGER M, HIRZER M, WOHLHART P, et al. Large scale metric learning from equivalence constraints [C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012, 1: 2288-2295.
[6] FARENZENA M, BAZZANI L, PERINA A, et al. Person re-identification by symmetry-driven accumulation of local features [C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 2360-2367.
[7] 張耿宁,王家宝,李阳,等.基于特征融合与核局部Fisher判别分析的行人重识别[J].计算机应用,2016,36(9):2597-2600. (ZHANG G N, WANG J B, LI Y, et al. Person re-identification based on feature fusion and kernel local Fisher discriminant analysis [J]. Journal of Computer Applications, 2016, 36(9): 2597-2600.)
[8] 孙金玉,王洪元,张继,等.基于块稀疏表示的行人重识别方法[J].计算机应用,2018,38(2):448-453. (SUN J Y, WANG H Y, ZHANG J, et al. Person re-identification method based on block sparse representation [J]. Journal of Computer Applications, 2018, 38(2): 448-453.)
[9] TAO D, GUO Y, YU B, et al. Deep multi-view feature learning for person re-identification [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(10): 2657-2666.
[10] GONG Y, WANG L, GUO R, et al. Multi-scale orderless pooling of deep convolutional activation features [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8695. Cham: Springer, 2014: 392-407.
[11] GRAY D, BRENNAN S, TAO H. Evaluating appearance models for recognition, reacquisition, and tracking [C]// Proceedings of the 2007 IEEE International Workshop on Performance Evaluation for Tracking and Surveillance. Piscataway, NJ: IEEE, 2007: 41-49.
[12] ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 1116-1124.
[13] LI W, ZHAO R, XIAO T, et al. DeepReID: deep filter pairing neural network for person re-identification [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 152-159.
[14] LIU H, FENG J, QI M, et al. End-to-end comparative attention networks for person re-identification [J]. IEEE Transactions on Image Processing, 2017, 26(7): 3492-3506.
[15] ZHENG L, ZHANG H, SUN S, et al. Person re-identification in the wild [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 3346-3355.
[16] ZHENG L, HUANG Y, LU H, et al. Pose invariant embedding for deep person re-identification [J]. arXiv E-print, 2018: arXiv:1701.07732. [J/OL]. [2018-12-06]. https://arxiv.org/abs/1701.07732.
[17] ZHAO H, TIAN M, SUN S, et al. Spindle net: person re-identification with human body region guided feature decomposition and fusion [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 907-915.
[18] PAISITKRIANGKRAI S, SHEN C, van den HENGEL A. Learning to rank in person re-identification with metric ensembles [C]// Proceedings of the 2015 Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1846-1855.
[19] MA B, SU Y, JURIE F. Covariance descriptor based on bio-inspired features for person re-identification and face verification [J]. Image and Vision Computing, 2014, 32(6/7): 379-390
