基于大数据的客户细分方法研究
2019-10-21向昆竹黄凯侯皓文
向昆竹 黄凯 侯皓文
摘 要:在如今同质产品的市场环境下,企业的市场竞争从产品质量逐步向客户满意度转变。企业通过客户细分,以客户类群为单位进行针对性的产品销售可以促进提升产品在市场的竞争力。本文通过对客户细分以及聚类分析的研究,运用聚类分析中的K-Means算法来解决客户细分问题。
关键词:大数据;机器学习;数据挖掘;聚类;k-means算法
随着经济的不断发展,市场中的大量产品供大于需,不同企业生产的同类同质产品不免会产生激烈的竞争。在这种市场环境下,企业若想提升产品竞争力,就需要施行有针对性的营销策略,将客户分而治之,将重点逐渐从产品质量的竞争向不同客户满意度的竞争进行转变。
在大数据时代的当下,数据不断反映着我们在日常生活的各种信息。通过对大量数据的分析与处理,对数据进行统一标准、属性筛选从而获取有用的信息。在如今的电子商务中,使用聚类的分析方法可以将客户进行细分,企业则可以将已经细分的客户类群作为销售的单位,提供更有针对性的产品与服务,从而提升企业销售的竞争性。
1 客户细分
1.1 客户细分概念
客户细分是指企业根据客户的属性、行为、需求、偏好以及价值等因素,寻求客户之间的共性特征,从而对客户进行与归类。
1.2 客户细分原因与做法
在信息快速流通的时代,企业与客户之间的关系也不断发生着变化。当企业在没有针对性的营销时,通常会因为企业产品与一类或多类客户需求之间的不匹配,造成该一类或多类客户的流失。若企业想要提升自己的产品竞争性,就必须要了解客户的需求,施行有针对的销售。然而,有些产品若施行一对一的销售会使销售成本加大,从而也会影响销售额。若将客户的不同信息进行筛选分析,从而将其进行分类,对细分后的客户类进行多样化具有针对性的销售,则会达到事半功倍的效果。
在客户细分中,不同方向划分类别的做法也不尽相同。一般可以从不同的业务场景以及客户关注的不同特征出发,结合企业自身实力的有限资源来进行细分。常用的参考种类有:消费行为、消费水平、客户年龄段、消费偏好等以及基于这些种类的多类组合。
消费行为:根据客户的消费频次、最近消费时间、平均消费金额等方面进行分析,可以对客户评级,判断客户的价值。
消费水平:按消费水平划分,对不同消费水平的客户提供不同的产品与服务。如会员卡分级策略。
客户年龄段:客户年龄段不同,客户的消费理念、产品需求也会不同。企业可以根据不同年龄段推荐不同的产品与服务。
消费偏好:根据客户的消费习惯、生活方式、消费场所等各方面的不同,从而整理出生活形态类似的客户群,给客户标上不同的标签,从而推荐不同的产品与服务。如RFM模型。其中R、F、M分别指最近一次消费、消费频次以及每笔平均消费金额。
多类组合:多方面综合分析客户的属性。
2 聚类分析
聚类是数据挖掘的最基本方法,一般在无目标划分中采用。通过聚类,从而将数据的组群分类标签化。其中要根据最大化类内相似性(分类后尽可能保证同类内有较高的相似性)、最小化类间相似性(分类后尽可能保证不同类之间有较低的相似性)原则进行聚类与分组。
聚类的主要方法分为动态聚类和层次聚类。
K-means算法是动态聚类中的常用算法之一。该算法简单且结果直观,适合对多维数据进行聚类,但是仅适用于连续的变量,当初始值与K值不同时结果也会不同。且结果无最优解。
谱系聚类(hierarchical clustering)是层次聚类中经典的方法。因为其可视性强的特点,通过不同公式与算法的多次计算,并根据实际业务分析可以得到最理想的分类。但是当分析的样本容量很大时,会消耗巨大的资源。因此谱系聚类较适合小样本使用。
3 K-means算法在客户细分的应用
3.1 K-means算法基本步骤
(1)选择类群的K个值作为初始的聚类中心。
(2)计算每个数据到K个聚类中心的距离,并且按照其最小距离将每个数据分配到对应最近的类,形成K个类。
(3)计算分类后的均值或者重心作为新的聚类中心,重新计算每个数据到K个聚类中心的距离,并将每个数据分配给对应最近的类。
(4)不断重复(2)、(3),直到前后计算的聚类中心不发生明显的变化为止。
3.2 在客户细分中的应用
客户细分应用的数据来源来自于某市某银行2018年客户交易数据,针对银行客户信息数据量大,采用K-means算法較适合。银行客户的分组应结合业务经验依据多类组合来施行。
异常处理:通过数据清洗,将数据中的异常值进行去除与代替。本实例使用99分位点法对数据进行数据清洗。
相关降维分析:由于数据量大,对数据之间相关性强的变量进行降维,从而降低数据之间的相关性。
数据标准化:将数据转换为各种适当的格式,获取需要的指标。本实例抽取交易次数、平均月交易金额为主要标准数据指标构造。
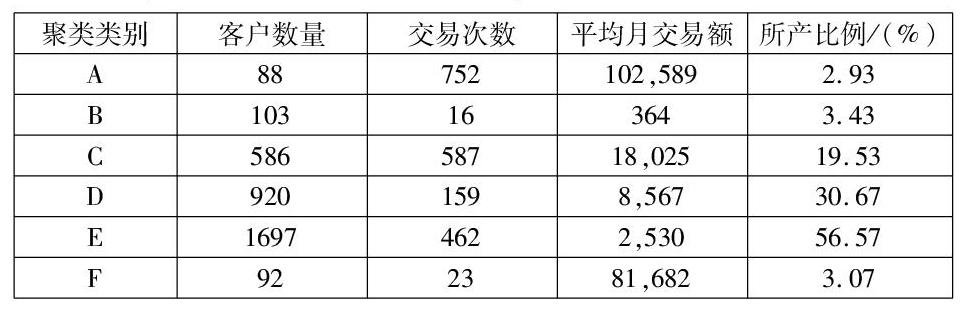
聚类分析:本实例随机抽取3000名客户数据,通过分析将K设为6,经过 K-means算法实验,得到如下表所示聚类结果。
从聚类结果来看,A、B、F类客户数量占比少,其中A类客户月交易额大,交易次数频繁,是银行的重要价值客户;B类客户交易次数少,交易额低,是重要的发展客户;F类客户,交易次数不频繁但交易额大,属于银行的潜力客户。C、D、E类客户数量占比较大,其中C类客户月交易资金较大,交易次数较频繁,属于较重要的价值客户;D类客户数量大,交易次数略低,交易金额处于中等水平,属于重要发展客户;E类客户数量最大,交易次数频繁,月交易额较低,属于一般价值客户。针对不同类别的客户,银行就可以推荐不同的产品以及服务。例如针对F类用户,银行可以推荐定期存款或其他适合理财产品。
4 结语
在聚类分析中,K-Means算法是最常用且应用最广泛的算法之一,K-means算法简单,对计算机性能要求不高,因此适合大量数据样本的聚类。该算法运用迭代的方式使不同类间的距离达到最优,最终得到聚类中心(类内某一特征的均值)。通过K-means算法对企业中客户进行细分,便于企业针对不同客户推荐不同的产品与服务。这样不仅促进了企业的产品竞争力,而且使客户拥有更好的产品体验。
参考文献:
[1]Jiawei Han,Micheline Kamber,Jian Pei.数据挖掘概念与技术[M].第三版.北京:机械工业出版社,2012-07.
[2]张建萍,刘希亚.基于聚类分析的K-means算法研究与应用[J].计算机应用研究,2007-05.
[3]李鑫鑫.聚类算法在电子商务客户细分中的应用研究[J].中国海洋大学,2012.
[4]王丽萍,刘建平.基于密度的K-Means算法在客户细分中应用的研究[J].工业控制计算机,2016-05-26.
作者简介:向昆竹(1998-),男,汉族,河南信阳人,2016级本科生在读,主要研究方向:网络工程;侯皓文(1998-),男,汉族,河南信阳人,2016级本科生在读,主要研究方向:软件工程。
通讯作者:黄凯(1997-),男,河南南阳人,2016级本科生在读,主要研究方向:网络工程。
