藏文情感语料库的构建与分析
2019-10-20杨欣群诺郭龙银孟姚媛
杨欣 群诺 郭龙银 孟姚媛

摘 要: 针对藏文情感分析的要求,建立藏文情感语料库。建库主要分三大步骤,爬取原始语料、开发标注平台、建立结构化语料。在标注体系上,糅合并参考英文和中文中相对优秀的情感语料库的标注体系的优点,结合藏文情感文本的特点,建立藏文情感语料标注规范。实验表明,该语料库具有扩展性和实用性,在该标注平台上标注藏语词句能减轻标注人员工作量,同时有效建立结构化语料,满足情感分析需求。
关键词: 藏文; 情感语料库; 标注平台; 情感标注
中图分类号:TP319 文献标志码:A 文章编号:1006-8228(2019)09-05-03
Construction and analysis of Tibetan emotional corpus
Yang Xin, Qun Nuo, Guo Longyin, Meng Yaoyuan
(School of Information Science and Technology, Tibet University, Lhasa, Tibet 850000, China)
Abstract: A Tibetan emotional corpus was established for the requirements of Tibetan sentiment analysis. There are three main steps in building a database, crawling the original corpus, developing an annotation platform, and establishing a structured corpus. On the labeling system, combines the advantages of the labeling system of the relatively good emotional corpus in English and Chinese, and combines the characteristics of Tibetan emotional text to establish the Tibetan emotional corpus labeling specification. Experiments show that the corpus is extensible and practical, and labeling Tibetan words and phrases on the labeling platform can reduce the workload of the labeling staff, and effectively establish structured corpus to meet the needs of sentiment analysis.
Key words: Tibetan; emotional corpus; labeling platform; sentiment tagging
0 引言
语料库是存储于计算机中并可利用计算机进行检索、查询、分析的语言素材总体[1]。随着互联网的发展,藏语情感语料层出不穷,例如从电子书上的文章,社交软件的信息,论坛网站和app上的评论,这些信息带有复杂的情感倾向。收集和训练这些语料,将其作为情感分析的语料库,在实际中可用于舆情监测和舆情分析。在文本情感语料库建设方面,目前已有的英文语料库包括Pang语料库[2],Whissell语料库[3],Berardinelli电影评论语料库[4],产品评论语料库[5]等等。但是藏文的情感分析研究目前还处于初步阶段,没有统一的情感语料库标注规范,也没有统一的测试标准,因此构建一个良好规范体系的藏文情感语料库已成为研究的首要任务。本文制定藏文情感语料库的标注规范,设计并实现藏文情感标注平台,建立结构化语言,为后续的研究工作提供基础条件。
1 原始语料收集
我们使用爬虫进行网站上的信息收集。我们使用Python3制作脚本,我们分析网页结构,找到想要数据的地址,分析出数据地址与html5其他标签的不同。之后,我们再使用正则表达式精准匹配到我们所需要资源的地址,从而得到相应的数据,最后清洗数据,将非藏文的其他语言去除。
2 语料库的标注体系
语料库是以是以自然交互的方式产生的机器可读文本的集合[1]。而情感语料库是将文本的语义和情感一一单独标注使得具有标注性质的机器可读,且情感的标注要有限的种类和明确的情感倾向性。
标注要有相应的规范,而在情感标注规范中,对情感种类和倾向性也有要求,如果类别划分过粗,就不能全面、细致地描述语言的复杂现象;但如果类别划分过细、标注信息过于庞大,不但会增加标注难度、降低标注效率,关系之间只有细微差别的情况也会使标注结果呈现严重的不一致性[6]。因此需要权衡现有的情感分析的要求和标注规范的局限性,而为了保证情感倾向的直接性以及标注的快速性和单文本的数量,我们选择句子级别的情感标注。
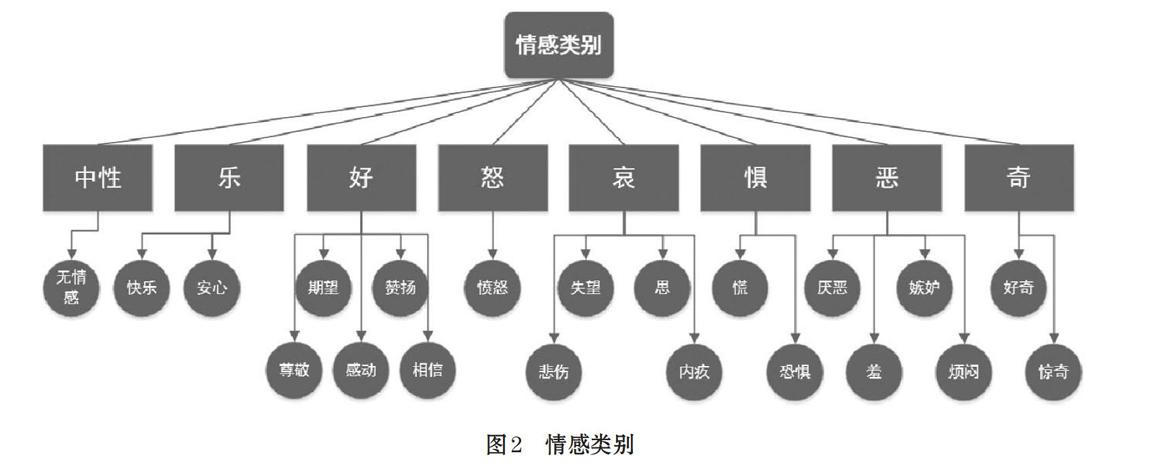
在标注规范的基础上,我们确立标注体系,即情感种类和结构化的标注,情感种类参考大连理工大学的情感语料标注种类共分8大类和21小类。
在情感类别划分之后,标注也有诸多问题。例如??????????????????????????????????????????????????????????????(今天,我要给妻子一个惊喜)对于情感所有者以及句子整体而言更适合标注为“好”。还有情感类别可能不仅仅是一种,例如????????????????????????????????????????????????????????????????????????????????????????????????????????(这个礼物太惊喜了,我期望很久了,好感动),对于这类句子,情感类别应该比较出程度最高的,对于情感标注而言礼物若是满足人的需求的更倾向于“乐”,若是满足人的遗憾的,更倾向于“好”。综合体系和要求,我们设计了如下的句子模型Sentence(line_index,topic,source,time,owner,recipient,label,rehetorical,degree_word,negative _word,sentence,)。句子模型描述了语料库需要收集的信息。Line_index就是给所标的句子赋予主码,topic为评论主题或文章题目,sourse为来源地,time为标记时间,owner为情感所有者,recipient為情感接受者,label为情感类别(可以不止一个排序由高到低),rehetorical修辞方法,degree_word程度副词,negative_word否定词,sentence为句子主题。
3 结构化语言
标注结果的保存方式有很多种,常见的有数据库保存(其容量很大满足构建大语料库的需求)和格式文件保存(xml等),本文利用xml格式文件保存标注后的结果。Xml文件的结构化使得文本标注简洁而明了,利用Python的xml库可以很方便地写XML文件和解析XML文件,xml首先将XML文件读人内存,然后在内存构建一个树状结构,通过遍历这棵树可以快速地得到每一个节点的值[3]。xml库,所建立的结构如下:
<?xml version="1.0" encoding="UTF-8"?>
第一行表示xml版本以及编码格式。藏文适用于utf-8,格式为一个标注属性的开始和结束,senti_corpus为根元素,为子元素。
4 情感标注平台的设计
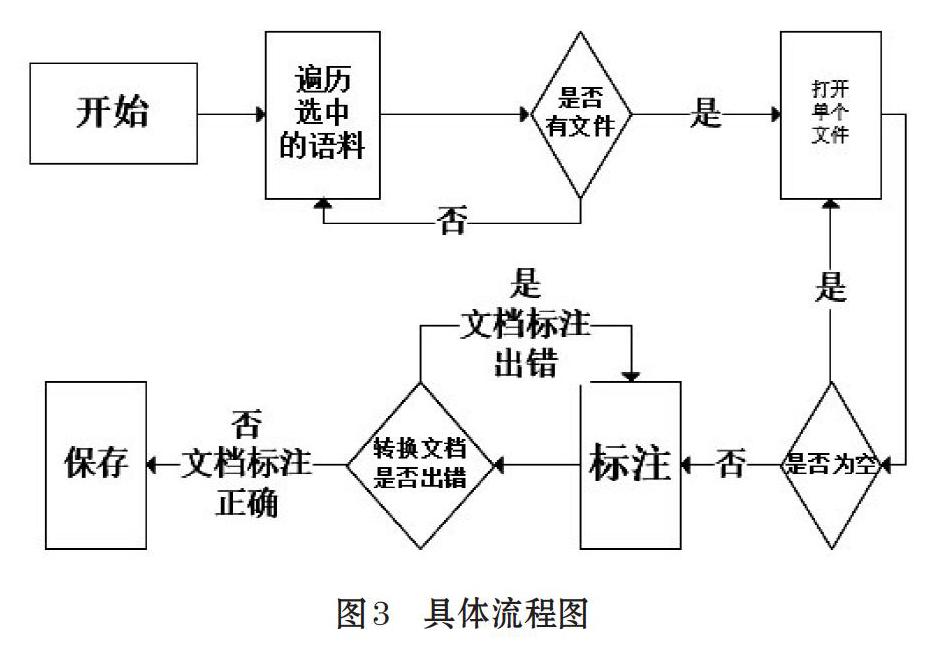
情感标注平台主要是显示语料、标注语料以及存储成结构化语言,具体流程如图3,显示语料:打开语料,遍历其中的所有文本,文本内容直接显示在屏幕上。标注语料:在平台的右侧有标注标签,各标签文本框用藏文显示属性的所有取值并用数字排列,但topic、source在打开文本时根据文本名和文件夹名生成,Line_index、time将在存储时产生,便于标注人员的工作,标注人员只需按顺序将标注属性名和属性中的数字编号依次写下,导出时后台自动在每一句后面识别标签并转换成xml文档。平台具体窗口如图4。
5 实验分析
从网站获取的藏语语料有效度较低,内容极为杂乱,有效语料不足总体的30%。综合总有效预料为23444条。为了测试本文设计的标注平台,总共标了4723条语句,其中无情感语句占到54%,惧和惊占比较少,分别为4%和2%。其中每一个类别包含的语句数目如图5所示。
实验结果显示,本语料库的标注体系具有可扩展性且歧义较少,平台的显示、标注、存储功能无误,较大程度的降低了标注人员的工作量。
6 结束语
本语料库收集了23444条,已标注语句4723条,确立了标注规范和体系,开发了人工标注平台, xml语料已投入极性情感分析。但构建大型的语料库才能提高情感分析算法的有效性和研究深度。本语料目前较大的问题在于藏文的否定词、程度词、修辞手法概括不足,需要标注人员汇报整理,本文还将继续扩充语料,加入质量检测,优化标注平台功能以提高标注速度,如有需求也会改善标注体系,进一步切合藏文语种,改善xml文档。总之,本语料库将为深度情感分析的研究而不断努力和改善。
参考文献(References):
[1] 徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[J].中文信息学报,2008.1:116-122
[2] http://www.cs.cornell.edu/People/pabo/movie-reviewdata/[DB/OL].
[3] Theologos Athanaselis,Stelios Bakamidis,and Ioannis- Dologlou.Recognizing Verbal Content of Emotionally-Colored Speech [A].European Signal Processing-Conference[C]. 2006.
[4] http://www.reelviews.net/[DB/OL].
[5] http://epinions.com/[DB/OL].
[6] Zhou X.,Hu X.,Zhang X..Using Concept-BasedIndexing to Improve Language Modeling Approach toGenomic IR[ A]. ECIR 2006[ C]. LNCS 3936,2006:444-455
[7] 伊爾夏提·吐尔贡,吾守尔·斯拉木,热西旦木·吐尔洪太,于清.维吾尔文情感语料库的构建与分析[J].中文信息学报,2017.31(1):177-183,191
