全参数动态学习深度信念网络在滚动轴承寿命预测中的应用
2019-10-19程军圣
杨 宇,张 娜,程军圣
(湖南大学 汽车车身先进设计制造国家重点实验室,长沙 410082)
设备故障预测与健康管理(Prognostics Health Management,PHM)是设备寿命周期管理中的重要一环,剩余使用寿命预测(Remaining Useful Life,RUL)是实现的关键技术之一。滚动轴承是决定机械健康状态与寿命的关键部件之一,其寿命是衡量滚动轴承性能的重要指标,因此开展滚动轴承寿命预测研究具有重要的意义,也一直是人们关注的焦点。
目前滚动轴承寿命预测方法主要有:基于统计分析、基于断裂力学、基于状态监测的轴承寿命预测模型[1]。基于状态监测的寿命预测方法是近年来滚动轴承寿命预测研究领域的热点,它随着信息技术与人工智能的快速发展而产生。传统的智能预测步骤一般为:首先借助传感技术获得能够反映滚动轴承主要性能的动态信号;然后借助特征提取与信号分析技术获得能够表示滚动轴承性能变化的主要特征;最后借助人工智能技术建立特征参数与剩余使用寿命之间的映射关系,从而实现滚动轴承剩余使用寿命的预测。在这个过程中,需要人为参与特征值的选取,因此降低了预测的智能性。
相比之下,深度学习可以直接处理原始数据,机器自动学习特征,降低了人工选择与参与性,提高了机器学习的智能性。深度神经网络分为:前馈深度网络、反馈深度网络和双向深度网络[2-4]。深度信念网络(Deep Belief Networks,DBN)是双向深度网络中的模型之一,是由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)堆叠成的多层感知器神经网络,采用低层表示原始数据信息,采用高层表示数据的特征与属性信息,训练过程中从低层到高层逐层抽象表示,从而达到深度挖掘数据本质特征的目的。
DBN预测方法与传统预测方法比较,如图1所示。

图1 分析过程比较图Fig.1 Analytical process comparison
本文将深度信念网络应用于滚动轴承寿命预测中,尽管DBN预测方法具有可以直接处理原始数据、自动提取特征值、深度挖掘数据信息、构建精度较高的预测模型等优点,但是仍然存在需要根据经验手动调整学习率、通过不断尝试才可确定固定学习率等缺点,从而导致预测网络存在很多不可控因素,大大降低了网络的智能性。传统DBN网络采用固定学习率,如果学习速率太小,则会使收敛过慢,影响计算时间;如果学习速率太大,则会使代价函数振荡,导致算法不稳定。而且目前传统的方法是根据具体情况通过不断尝试找到合适的学习率,这种方法工作量很大,且不一定能找到最优值,不利于迭代寻优;有学者在此基础上为RBM 模型的三个参数设置了相同的动态学习率,但是权重与偏置属于不同类型的参数,设置相同的动态学习率存在很大的不合理性。在RBM训练过程中,运算初期在大范围内调整,而到迭代后期,网络基本趋于稳定,只需要部分且小步的调整,因此传统的固定长度的学习速率不适用于迭代寻优;且RBM模型中的三个参数属于不同类型,为其设置相同的学习率是不合理的。基于此,本文提出了全参数动态学习策略:即在RBM前向堆叠和后向微调的两个过程中,均根据不同类型参数的特点设置不同的动态学习率。并在此基础上提出了一种改进的深度信念网络——全参数动态学习深度信念网络(Global Parameters Dynamic Learning Deep Belief Networks,GPDLDBN),首先采用自下而上的逐层无监督贪婪算法训练参数;然后采用自上而下的监督学习算法微调整个网络参数,两个过程均采用新的全参数动态学习策略设置各参数。采用GPDLDBN预测模型对实测的滚动轴承寿命数据进行了预测,并与传统DBN预测结果进行对比,预测结果验证了本文所提方法的有效性。
1 全参数动态学习深度信念网络算法(GPDLDBN)
DBN是由多个RBM堆叠成的多层感知器神经网络[5-7],低层表示原始数据细节,高层表示数据属性类别或特征,从低层到高层逐层抽象,可以深度挖掘数据本质特征。训练过程主要为两步:第一,使用无监督学习方法训练每一层RBM,且每个RBM的输入为上一个 RBM的输出,即每一层RBM都要单独训练,确保特征向量映射到不同的特征空间时,尽可能多的保留特征信息;第二,使用最后一层的BP网络接收最后一个RBM的输出,用有监督的方式训练整个网络,对其进行微调。
如图2是一个典型的由三个RBM堆叠成的DBN结构模型。这些网络被“限制”为一个可视层v和一个隐含层h,层与层之间通过权值w连接,但层内的单元间不存在连接。隐含层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。第一可视层v1为初始输入数据,和第一隐含层h1组成第一个RBM 1;第一隐含层h2作为第二可视层v2,并和第二隐含层h2组成第二个RBM 2;第二隐含层h2作为第三可视层v3,并和第三层隐含层h3组成第三个RBM 3。
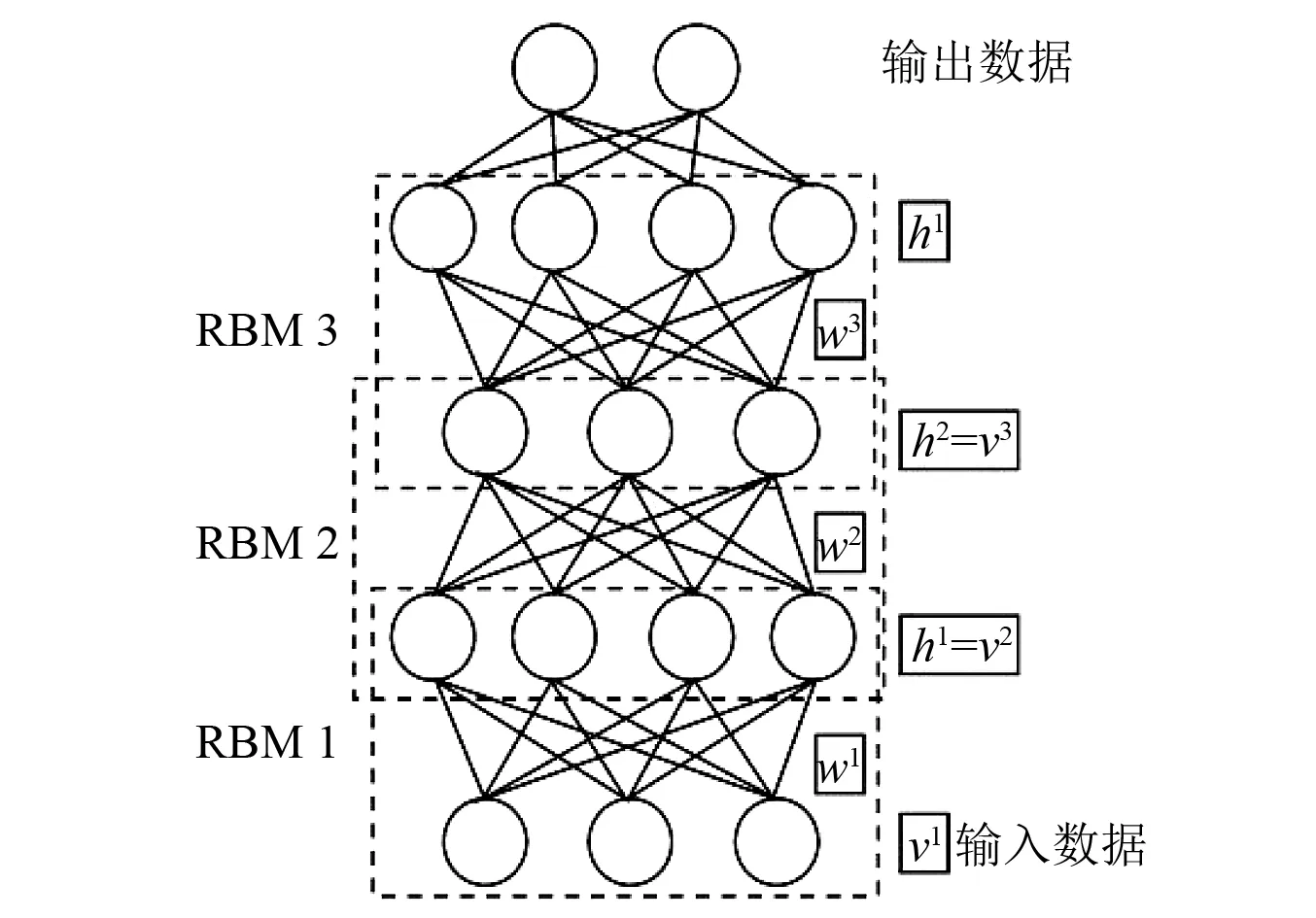
图2 DBN结构Fig.2 DBN structure
1.1 无监督前向堆叠RBM学习
采用对比散度(Contrastive Divergence,CD)算法进行预训练获得生成模型的权值,这是Hinton在2002年提出的RBM的一个快速学习算法[8],是一种有效的非监督贪婪逐层训练方法。
无监督前向堆叠RBM学习,首先在可视层生成一个向量v,v将输入数据从可视层传到隐层。在这个过程中,可视层的输入会被随机选择,用来尝试重构原始的输入信号;接着,新得到的可视层神经元激活单元将继续前向传递,来重构隐层神经元激活单元,获得h;这些重复后退和前进的步骤就是Gibbs采样[9]。整个过程中,权值更新的主要依据就是隐层激活单元与可视输入信号之间的相关性差别。
这个训练过程,可以归纳为以下几个步骤:
步骤1确定参数并初始化
样本数据x,可视层v、可视层偏置b,隐含层h、隐含层偏置c,连接可视层与隐含层单元的权重w,sigm为sigmoid函数,η为学习率,隐含层节点数m,可视层节点数n。
令v1=x;w,b,c初始化为零,因为这三个参数在后续的算法中均会被迭代更新,所以初始化的具体值对结果影响不大。
步骤2对所有的隐含层单元
(j=1,2,...,m),计算
(1)

步骤3对所有的可视层单元
(i=1,2,...,n),计算
(2)
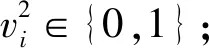
步骤4对所有的隐含层单元
(j=1,2,...,m),计算
(3)

步骤5参数更新
(4)
步骤6按上述步骤完成迭代更新,并依次训练下一个RBM,最终得到DBN网络的最后更新参数。
1.2 有监督后向微调学习
无监督前向堆叠RBM学习完成后可以初始化RBM每层的参数,相当于为后续的监督学习提供了输入数据的先验知识,然后使用有监督后向微调算法[10-11]对DBN的权值进行微调,接着利用输出误差值进行输出层与前一层之间的误差估计,同理,经过逐层的反向传播训练,来获取其余各层之间的误差,最后使用批梯度下降法计算并更新各节点权值,直到输出误差满足要求。后向微调是从DBN网络的最后一层出发的,若是用于解决多分类问题,例如故障分类识别,则使用Soft-max作为分类器模型;若是用于解决回归问题则使用线性传递函数sigmoid函数,本文解决的寿命预测问题使用的是sigmoid函数。
DBN的BP算法只需要对权值参数空间进行一个局部的搜索,这样的权值微调算法克服了传统BP神经网络因随机初始化权值参数而容易陷入局部最小和训练时间过长的缺点[12],只需在已知权值空间内进行微调即可,大大缩减了参数寻优的收敛时间。其次,使用CD算法可进行快速训练,将DBN整体框架简化为多个RBM结构,这样避免了直接从整体上训练DBN的复杂度。采用这种方式进行网络训练,再使用传统反向传播算法进行网络微调,大大提升了网络的建模能力,使模型快速收敛到最优。
1.3 全参数动态学习策略
DBN模型中有两个过程使用了学习率:RBM前向堆叠和后向微调过程。学习率能够影响网络的学习进度,合适的学习速率是保证参数θ=(W,b,c)学习到最佳状态的必要条件。
DBN模型中参数优化,即权重与偏置的一般更新公式为
θ(t+1)=θ(t)-η(t)L(θ(t))
(5)
式中:θ(t+1)为迭代t+1次的参数值;θ(t)为迭代t次的参数值,η(t)为学习率(步长);L(θ(t))为定义在数据集上的损失函数的梯度。
根据连接权重和偏置的不同特点和作用,本文提出了一种全参数动态学习策略,数学表达式如下:
(1)RBM前向堆叠过程中参数的学习策略
(6)
D(t)=ξd(t-1)2+d(t)2
(7)
(8)
(9)
式中:η(t+1)为连接权重下一回合的学习率;η(t)为当前回合连接权重的学习率;K取1;D(t)为一定比例的上一梯度和当前梯度的平方和,ξ为衰减因子,取值为0.9;α(t+1)和β(t+1)分别为迭代第t+1次可见单元和隐含单元偏置的学习率;α(t)和β(t)分别为迭代第t次可见单元和隐含单元偏置的学习率;使用呈下降趋势的幂指数函数;E为最大迭代次数;q取0.75。
(2)后向微调过程中参数的学习策略
(10)
G(t)=ξd(t-1)2+d(t)2
(11)
式中:μ(t+1)为后向微调过程中连接权重下一回合的学习率;μ(t)为当前回合连接权重的学习率。
该学习策略的思想是:对于权重而言,利用当前学习率与最近两个梯度平方和,自适应调节下一回合的学习率。只使用最近两个梯度的平方和,减少了历史梯度的冗长计算;同时学习率随着迭代次数动态变化,这样都使得模型的收敛速度有所加快。对于偏置而言,从减少计算量的角度出发,为其设置了只与当前学习率有关的幂指数函数,这样可以加快模型的收敛速度。
2 基于GPDLDBN的滚动轴承寿命预测实验分析
2.1 实验平台设计及实验数据
为了验证本文所提方法在滚动轴承寿命预测中的适用性,本文采用两组不同的实验数据进行预测。
(1)首先采用辛辛那提大学的智维护系统(Intelligent Maintenance Systems,IMS)的滚动轴承寿命实验数据[13]。实验台简图如图3所示。轴承转速为2 000 r/min,采样频率为20 kHz。采用第一通道采集到的轴承1的数据,共984个文件,每个文件为1 s采集到的振动信号,每隔10 min记录一组数据,采样的点数为20 480个点。滚动轴承寿命实验结束时,轴承1的外圈发生故障。
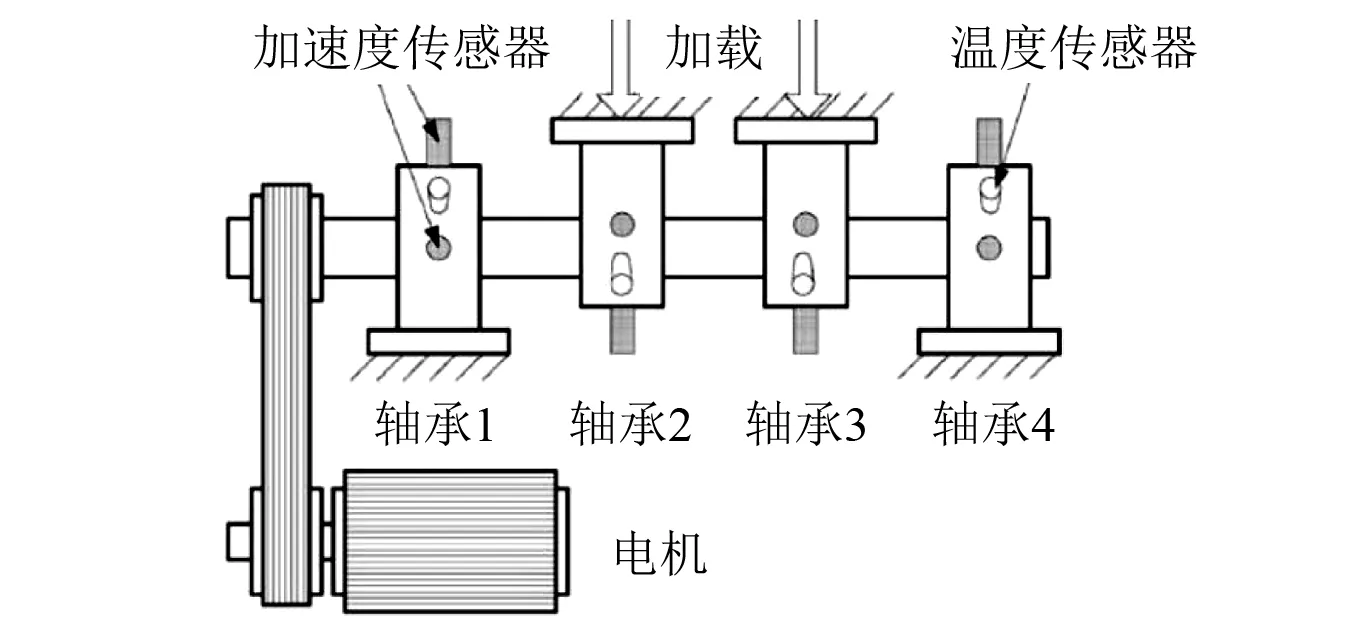
图3 滚动轴承寿命数据采集实验台简图Fig.3 Rolling bearing life data acquisition experiment platform
(2)接着采用法国弗朗什孔泰大学IEEEPHM 2012 Prognostic challenge的滚动轴承寿命实验数据。轴承转速为2 000 r/min,采样频率为25.6 kHz。所使用的数据集一共有2 803组数据,采集时间间隔为10 s,每组数据采样时间为0.1 s。滚动轴承的寿命实验以振动信号振幅超过20g为实验停止的标志。
根据两组实验数据分别画出滚动轴承的时域图,如图4、图5所示。从图中可知,轴承正常运行、开始退化、退化加剧和完全失效几个状态。需要注意的是,对于IMS滚动轴承寿命数据而言,在运行到约8 500 min的时候滚动轴承已经发生了中度故障,处于退化加剧阶段,那么使用明显失效的数据来预测滚动轴承之后的寿命已经没有任何工程实际意义,则只需预测0~8 500 min的寿命即可。
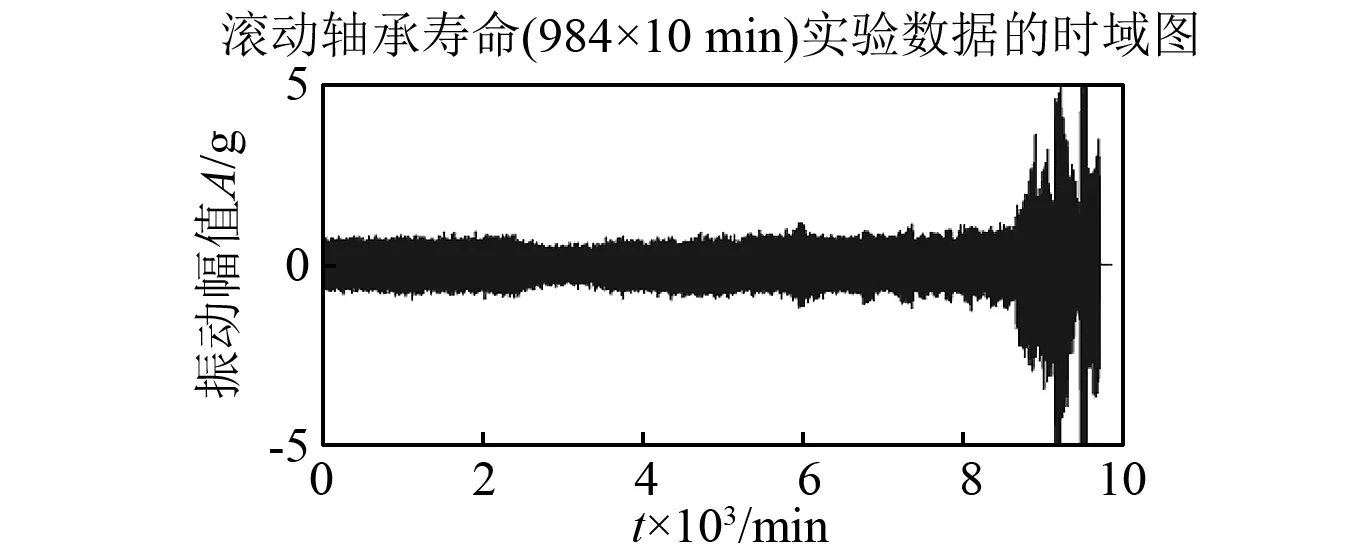
图4 IMS轴承寿命时域图Fig.4 The time domain waveform diagram of IMS rolling bearing life

图5 IEEEPHM轴承寿命时域图Fig.5 The time domain waveform diagram of IEEEPHM rolling bearing life
根据上述两组数据的具体情况设置参数,如表1所示。
深度学习的“深度”体现在多隐含层,一般而言,网络层次越多,网络越能从更多更细方面挖掘数据本质特征,但是网络层数越多,结构越长,网络计算耗时越大,会降低效率。本文采用由三个RBM堆叠而成的DBN,即三个隐含层,结果显示三个隐含层的预测结果已经有足够的精度。节点数的确定方法:根据数据样本长度,把数据分为合理的几段,在这些数据中选取效果最优的数据作为隐含层节点数。例如IMS数据,转轴转一圈,传感器约采集600个数据点,则可以60个数据点为步长,设置成10段不同样本长度的数据,作为隐含层的节点数,分别为60,120,180,240,300,360,420,480,540,600。首先让第一个RBM的隐含层节点数在这10种数据中进行计算,分别得到各数据作为隐含层节点数时对应的重构误差;然后选择10个重构误差中最小的重构误差所对应的数据300作为第一隐含层的节点数。在确定第一隐层节点数的基础上,同理,可确定第二隐含层节点数600,第三隐含层节点数360。最后,通过上述方法可得到IMS数据的隐含层结构为[300,600,360]。
根据DBN算法,每次挑出一个批量大小的数据来进行训练,也就是每用批量大小个样本就调整一次权值,而不是把所有样本都输入了,计算所有样本的误差了才调整一次权值。
批量大小不是一成不变的,需要根据具体数据集规模、设备计算能力去选。数据集较小时,可采用全数据集;一般情况下需选择一个适中值,即批梯度下降法(Mini-Batches Learning),因为当数据集足够充分时,用一般甚至更少的数据训练出来的梯度与全部数据训练出来的梯度几乎是一样的。本文根据批梯度下降法确定了具体值。对相同样本集的训练次数,原则上迭代次数越多,预测结果越精确,但是会导致训练时间越长。而且当迭代次数达到一定数值时,预测结果的精度变化越来越微弱,与花费的时间成本比较,提升的精度已经没有太大的价值。因此需要根据具体情况,平衡预测精度与时间成本,选择合理的迭代次数。
需要注意的是,以上参数的设置都要考虑到实验平台(CPU与MATLAB)的处理能力。
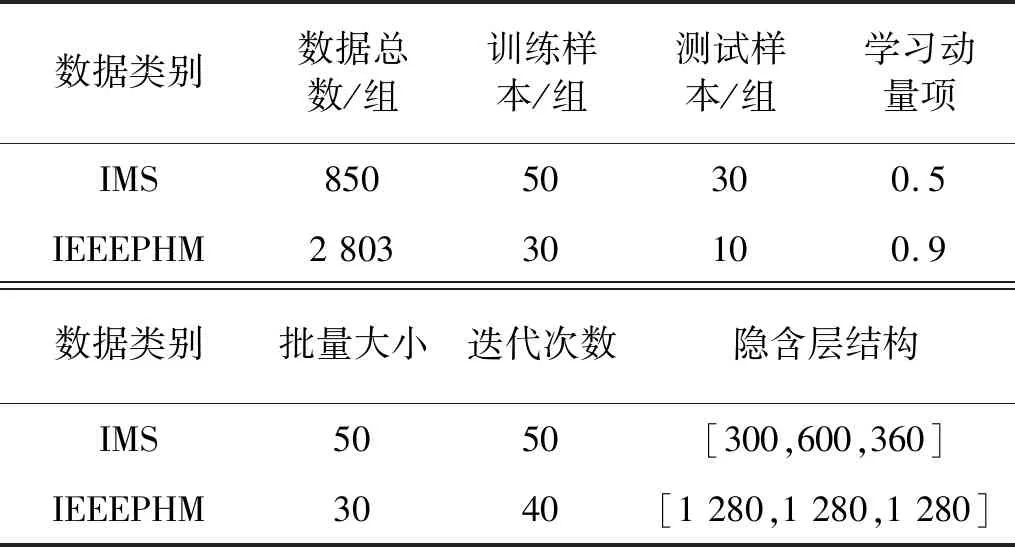
表1 参数设置Tab.1 Parameter settings
2.2 基于GPDLDBN预测模型的寿命预测分析
本文所采用的滚动轴承寿命预测方法的操作流程图,如图6所示。
按照上述流程图,首先读取全部实验数据;然后把数据归一化到[0,1];接着按照一定的比例设置训练样本与测试样本(例如,IMS实验数据,按照5∶3设置训练样本为50组,测试样本为30组);然后使用全参数动态学习策略构建GPDLDBN模型,把训练样本输入该模型并进行训练;接着把测试样本输入训练好的模型则可得到相应的预测数据;最后按照上述方法循环训练模型并得到全部的测试结果。对两组实验数据分别进行训练并预测,可得到基于GPDLDBN的滚动轴承寿命预测结果,并在图中做出真实寿命值,以便比较,如图7、图8所示。从预测结果图可以看出基于GPDLDBN的滚动轴承寿命预测结果与真实值已经非常接近,而且基于GPDLDBN网络得到的预测结果非常稳定,只在轴承运行的开始与结束附近有轻微的波动。
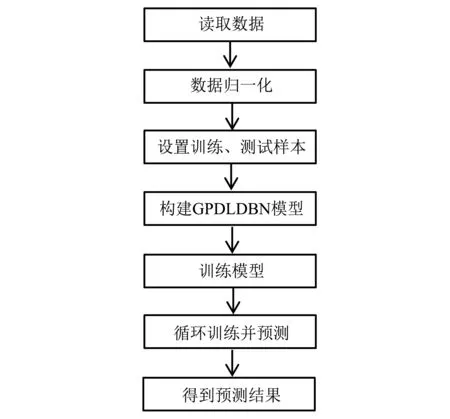
图6 基于GPDLDBN的滚动轴承寿命预测流程图Fig.6 A flowchart of rolling bearing life prediction based on GPDLDBN

图7 IMS滚动轴承寿命预测结果Fig.7 The results of IMS rolling bearing life prediction

图8 IEEEPHM滚动轴承寿命预测结果Fig.8 The results of IEEEPHM rolling bearing life prediction
选取IEEEPHM滚动轴承寿命预测结果中第1 001~1 020共20组数据,得到其预测值与真实值的对比表格,如表2所示。
为了能够定量的描述本文所采用的方法的有效性,使用均方误差(Main Squared Errar,MSE)来衡量网络的重构误差(训练误差),使用平均绝对百分比误差(Mean Aboolute Percent Error,MAPE)来衡量预测结果,误差如表3所示。
误差公式为
(12)

表2 滚动轴承剩余可使用寿命真实值与预测值对比表(IEEEPHM)Tab.2 The comparative tab about real value and predicted value
(13)


表3 预测结果误差表Tab.3 The error table of predicted results
同时得到IMS数据和IEEEPHM数据的基于GPDLDBN预测模型的重构误差与迭代次数的关系图,如图9、图10所示。重构误差是对RBM的似然度的评估,可作为评价预测模型的一个参考指标,可以看出对于IMS数据当迭代到30次以后,对于IEEEPHM数据当迭代到40次以后,重构误差已趋于稳定。同时,得到损失函数(即预测误差)与迭代次数的关系图,如图11、图12所示,可以看出对于IMS数据迭代50次时,预测误差已经足够小,所以本章确定的迭代次数50是合理的;可以看出对于IEEEPHM数据迭代40次时,预测误差已经足够小,所以本章确定的迭代次数40是合理的。

图9 重构误差与迭代次数关系曲线图(IMS)Fig.9 Reconstruction error-iteration times(IMS)
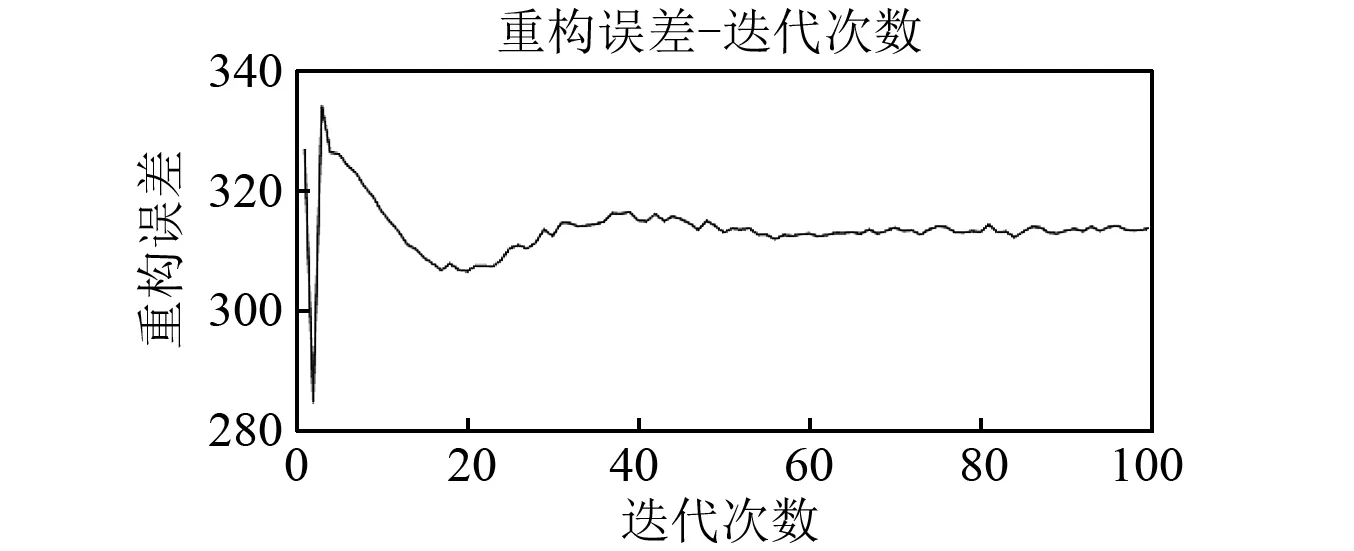
图10 重构误差与迭代次数关系曲线图(IEEEPHM)Fig.10 Reconstruction error-iteration times(IEEEPHM)

图11 损失函数与迭代次数关系曲线图(IMS)Fig.11 Loss function-iteration times(IMS)
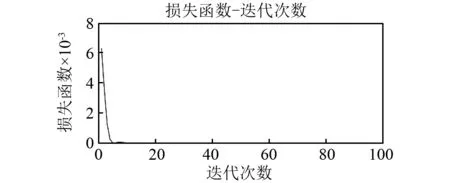
图12 损失函数与迭代次数关系曲线图(IEEEPHM)Fig.12 Loss function-iteration times(IEEEPHM)
为了进一步说明本文提出的基于GPDLDBN的预测模型的效果,分别采用IMS和IEEEPHM滚动轴承寿命数据,比较GPDLDBN模型与传统DBN模型的预测效果,预测结果如图13、图14所示,误差指标如表4、表5所示。

图13 GPDLDBN与传统DBN预测结果对比图(IMS)Fig.13 Rolling bearing life prediction results of GPDLDBN and traditional DBN(IMS)

图14 GPDLDBN与传统DBN预测结果对比(IEEEPHM)Fig.14 Rolling bearing life prediction results of GPDLDBN and traditional DBN(IEEEPHM)
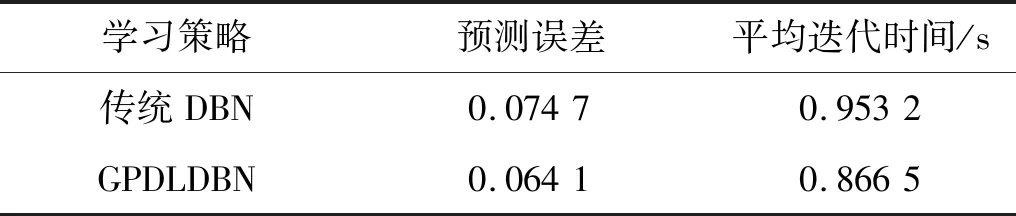
表4 GPDLDBN与传统DBN滚动轴承寿命预测各项误差指标对比表(IMS)Tab.4 The comparison table of error indicators

表5 GPDLDBN与传统DBN滚动轴承寿命预测各项误差指标对比表(IEEEPHM)Tab.5 The comparison table of error indicators
滚动轴承寿命预测所花费的时间与实验平台(CPU与MATLAB)的处理能力有很大的关系,本次实验是在64位Inter Xeon CPU E3-1231 v3、主频3.40 GHz、内存8 GB 的计算机配置下进行的。对于IMS实验数据,GPDLDBN预测模型一共迭代了50次,共花费时间43.326 0 s,则其平均迭代时间为0.866 5 s;对于IEEEPHM实验数据,GPDLDBN预测模型一共迭代了40次,共花费时间15.050 2 s,则其平均迭代时间为0.376 3 s。
从图13、图14可知,对于滚动轴承寿命预测,GPDLDBN预测模型相对于传统DBN预测模型更接近于真实值,能够得到精度更高的预测值;对表4、表5中的模型评价指标进行分析可知,GPDLDBN预测模型相对于传统DBN预测模型,预测误差和平均迭代时间均有明显的下降,表明GPDLDBN预测模型较好的克服了传统DBN预测模型中固定学习率带来的缺陷,提高了预测精度,GPDLDBN方法可以建立性能更优的滚动轴承寿命预测模型。
对上述实验结果分析可知,基于GPDLDBN的滚动轴承预测模型是一种高精度、预测结果可靠、收敛速度较快的预测模型,具有工程实际意义。
3 结 论
针对复杂且数据量较大的滚动轴承寿命振动信号,本文提出了一种可以更好地刻画数据之间复杂非线性关系的滚动轴承预测模型——GPDLDBN预测模型。该预测模型为RBM前向堆叠过程与后向微调过程分别设置了全参数动态学习策略,分别采用传统DBN预测模型与改进DBN预测模型(GPDLDBN)进行了滚动轴承寿命预测对比实验,实验结果证实了本文提出的预测模型能够更好反映滚动轴承寿命的变化,预测精度高且收敛速度快。但是,滚动轴承寿命预测效果与DBN网络的结构、节点数、数据长度等参数都有很大的联系,目前还没有比较完善的选择标准,这些都有待研究来进一步提高预测精度或加快收敛速度。
