基于改进TF-IDF-CHI算法的农业科技文献文本特征抽取*
2019-10-17杜若鹏鲜国建寇远涛
杜若鹏 鲜国建 寇远涛
(中国农业科学院农业信息研究所/农业农村部农业大数据重点实验室,北京 100081)
在海量的科技信息中,文本文献是最重要的部分[1],文本自动分类技术是组织和管理海量科技信息的重要手段[2]。文本自动分类研究中,对内容相似类目(用词上非常接近的不同类别)的处理是其中一个重要课题[3]。
在农业科技文献中,相近的研究领域的文献,其文本特征信息是高度重合的,在很多情况下,虽然研究的对象不同,但研究方向相同或相近时,其研究手段、分析方法往往都是相同或相似的。如番茄、辣椒和茄子,虽然是不同的作物,但是产品器官均为果实,其育种目标、育种途径及应用的主要技术方法基本相同,因此这3种作物在遗传育种方面的文献,其关键词、高频词以及全文用词的相似度非常高。如何对这种内容相似类目进行精准分类,是农业数字图书馆进行专题文献分类以及开展个性化检索服务时需要解决的重要问题。
文本自动分类中较为关键的环节是文本特征抽取,特征抽取准确与否,直接影响文本分类的最终效果。基于信息测度的特征选择算法是目前最常用的,包括文档频率(Document Frequency,DF)、信息增益(Information Gain,IG)、词频-逆文档频率(Term Frequency-Inverse Document Frequency,TFIDF)、卡方检验(Chi-squared,CHI)、互信息(Mutual Information,MI)以及期望交叉熵(Expected Cross Entropy,ECE)等[4]。上述方法在实践应用中各自表现出优点和不足,所以一直处于不断改进和完善中。
笔者从探索适合农业科研领域内容相似类目文献精准分类方法的目的出发,在前人对TF-IDF改进的基础上,结合实际应用情况作进一步改进,形成改进的TF-IDF-CHI(ImpTF-IDF-CHI)方法。本实验中运用该方法以及传统的文档频率法、信息增益法、TF-IDF法,对从农业专业知识服务系统中文科技期刊论文数据中选取的近十年有关番茄、辣椒、茄子、黄瓜、马铃薯和模式植物拟南芥等遗传育种主题文献4 000多篇进行文本特征抽取,并应用于朴素贝叶斯分类实验,比较其效果。结果表明,ImpTF-IDF-CHI方法效果最好,抽取的主题词代表性强,主题分类平均准确率达94%,且稳定性好,为今后进一步开展农业科技文献主题词扩展、专题文献分类、检索,以及个性化专题情报服务打下一定基础。
1 实验中采用的3种传统方法
1.1 文档频率法
文档频率法是统计文档集中包含每一个词的文档个数,设置阈值,保留高于阈值的文档频数所对应的词作为特征词,过滤掉低于阈值的低频词。文档频率法简单易行,但是较为粗糙,而且词条的文档频率阈值不好确定,阈值过大易导致具有代表性的词条丢失,过小又会导致入选词条包含大量无贡献的低频词,影响分类效果[5]。
1.2 信息增益法
信息增益法是根据词条能为整个分类系统提供的信息量的多少来决定其重要程度。信息增益用特征词在文本中出现时与不出现时的信息熵之差表示,依据差值的大小决定其作为特征词的取舍[6]。信息增益算法相对简单。但是由于考虑特征词出现与不出现两种情况,对于小数据集,或在类别分布不平衡的情况下,不出现的特征权值将产生主导作用,因此很难提取小样本集特征,或者增益比较大的特征词的实际词频较低[7-8]。由于在实际应用中很多增益比较大的特征词的实际词频较低,当选择的特征数量偏小时容易陷入数据稀疏的问题,所以本实验中的信息增益法采用IG方法与DF文档频率法结合(IG-DF)的方式进行。
1.3 TF-IDF
TF-IDF由Salton在1988年提出[9-10],利用词频和逆文档频率(出现某词条的文档的倒数)的乘积来衡量词条作为特征词的分类能力,该算法在文本分类领域得到广泛应用。但是传统的TF-IDF法存在不足[10-18],如同一个特征词在长文档中往往比在短文档中出现的频数更大,会影响到分类效果;还有就是忽略了数据集偏斜(数据集中各类文档数不均衡,可能存在数量级的差距)和特征词在类间和类内的分布(在一类中经常出现而在其他类中很少出现的特征词权重会被低估)等问题。众多学者针对TF-IDF算法存在的不足进行过多次改进。如使用特征词在文档中的频率代替其在文档中的频数[10],来减弱文档长短带来的影响;How等[11]提出CTD(Category Term Descriptor)法,以弥补类别数据集偏斜带来的困扰;沈志斌等[12]提出BOR-TFIxDF法,张瑜等[13]提出由“权重调整因子-类内离散度-类间偏斜度”组成的WA-DI-SI算法,赵小华等[14]将TF-IDF与CHI相结合的算法,路永和等[15]将特征权重(Term Weight,TW)与TF-IDF结合的算法等,都是重新修正各个特征词的权重,以减弱特征词在类间、类内分布带来的影响。
2 改进的TF-IDF-CHI(ImpTF-IDFCHI)
笔者改进的TF-IDF-CHI(ImpTF-IDF-CHI)方法包括重新构造卡方值加权函数、特征词词频加权函数以及逆文档频率加权函数,并对特征词加权函数引入修正因子。
(1)重新构造卡方值加权函数。通过重新构造卡方值加权函数对特征词权重计算进行优化。构造函数见公式(1)。
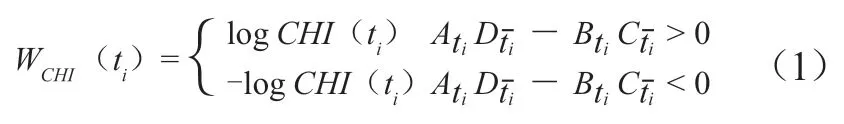
其中,ti代表第i个特征词;CHI(ti)表示该特征词的卡方值,计算方式见公式(2)。
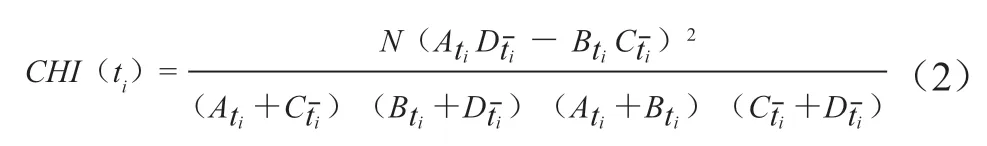
N代表总文档数,Ati表示包含特征词ti且属于假设目标分类的文档数,Bti表示包含特征词ti且不属于假设目标分类的文档数,Cti表示不包含特征词ti且属于假设目标分类的文档数,Dti表示不包含特征词ti且不属于假设目标分类的文档数。构造函数中,对卡方值进行取对数运算是为避免直接使用卡方值导致加权值波动剧烈,出现过大或过小的情况。同时,根据AtiDti与BtiCti差值,对构造函数进行了分段处理。对于BtiCti大于AtiDti这种情况,通过对特征加权值判定为负值的方式,对其进行特征过滤。
(2)重新构造特征词词频加权函数。对TF-IDF特征词加权函数进行优化处理。首先是对特征词词频加权部分进行函数重构,见公式(3)。
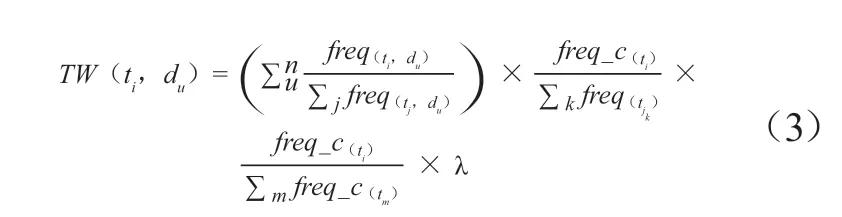
其中,第u篇文档用du表示,freq(ti,du)表示文档du中的特征词ti的绝对词频,∑j freq(ti,du)表示文档du中所有特征词的总词频。二者相除等于特征词ti在文档du中的相对词频,然后再计算每篇文档中的特征词ti的相对词频并且相加求和,得到特征词ti的总相对词频。所以使用相对词频代替传统方法中绝对词频,是为避免特征加权计算时词频计算偏向长文本。同时,引入2个修正因子,对特征词ti的加权计算进行优化。freq-C(ti)表示目标分类C所包含的全部文档中特征词ti的绝对词频之和,∑k freq(tik)表示特征词ti在所有文档中的绝对词频之和。二者之比,表示特征词ti在目标分类C中的词频占自身总词频的多少。该比值取值范围在[0,1][19]。比值越大、越接近1,表示特征词ti主要分布在目标分类C的所属文档,从侧面反应特征词ti的词频分布与目标分类C文档的相关性。同理,∑mfreq-C(tm)表示目标分类C文档中所有特征词的词频之和,freq-C(ti)与其比值越大、越接近1,表示特征词ti在目标分类C文档中的词频比重大。该比值可以一定程度上反应特征词ti在分类C中的重要程度。在实际应用中,多个小数相乘的结果往往会很小,甚至接近0。因此,引入常数λ对运算结果进行放大。本试验中常数λ设置为10 000,取得了良好效果。引入上述2个修正因子,理论上可以有效地筛选与目标分类C契合度高且重要的特征词。
(3)重新构造逆文档频率加权函数。对逆文档频率加权计算部分进行优化改造,见公式(4)。
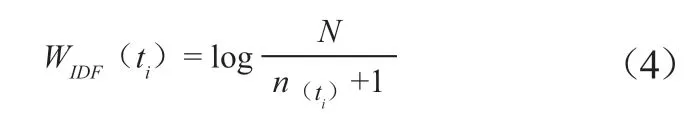
N表示文本集中的总文档数,n(ti)代表包含特征词ti的文档数,即ti的文档频率。采用对数运算是为了使逆文档频率更加平滑。为应对特征词的文档频率为0的情况,在分母增加常数项,从而避免导致无法计算的局面。
综上所述,改进的文本特征词加权函数见公式(5)。
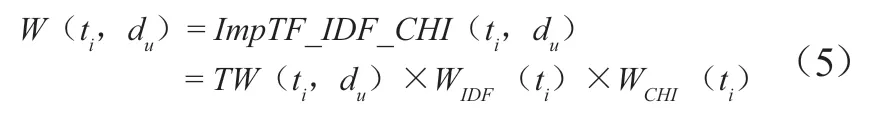
最终的特征词加权计算公式,分别从特征词词频的相关性及贡献度、文档频率普遍性、特征词与目标分类间的独立性等多维度对特征词的加权进行综合衡量。
3 实验的方法与步骤
3.1 实验方法
为了检验ImpTF-IDF-CHI(ti,du)对文本特征词抽取加权算法的有效性,进行文本分类实验。首先,对农业专业领域的相近主题文献进行特征词抽取,然后通过文本分类验证所抽取的特征词对所在分类文献的区分效果,证明其具有很强的文本特征代表性。同时,为证明ImpTF-IDF-CHI(ti,du)方法的优越性,将其分类效果与前述的3种特征抽取方法进行比较。实验平台的硬件、软件环境,如表1所示。
表1 实验平台
3.2 实验步骤
采用农业专业知识服务系统的近十年的部分中文期刊论文数据,从中选取番茄遗传育种、辣椒遗传育种、黄瓜遗传育种、茄子遗传育种、马铃薯遗传育种以及以模式植物拟南芥为研究主体的6类文献(其主要特点是高频词、关键词重合,全文用词相似度高),采用文档频率(DF)法、信息增益与文档频率相结合(IGDF)法、TF-IDF法和ImpTF-IDF-CHI 4种特征抽取方法进行二元分类。实验流程如图1所示。
首先,选取6类主题文献共计4 297篇作为本实验的文本集,其中番茄遗传育种主题为1 387篇,其余5类主题文献为2 910篇。设定番茄遗传育种主题为二元分类的目标分类,其余5类分类为干扰分类。从文本集中,各自选取目标分类与干扰分类主题文献各1 000篇作为训练集,其余2 297篇作为测试集,6类主题比例接近1∶1,平均每类主题测试集文档近390篇。
对文本集的预处理主要包括剔除非文本标点符号与中文分词处理。由于所涉及文献包含大量农业专业领域词汇,如果使用日常生活词库进行中文切词,则会破坏专业词汇的完整性,导致分词错误。因此,需要构建农业专业领域词表作为专业分词词库。农业专业分词词库主要包括中国农业叙词表(CAT)、搜狗农业专业词表以及农业专业知识服务系统论文词表。其中,农业专业知识服务系统论文词表中的词汇主要来源于服务系统收录的近十五年的350万篇农业专业中文核心期刊论文的关键词。最终通过去重、过滤低频词等,将上述专业词表与日常用语词表进行整合,形成包含120万词条的中文分词词库。
对分词后的训练集数据进行DF、IG-DF、TF-IDF和ImpTF-IDF-CHI 4类特征抽取方法测试,生成各自对应的特征词表。通过特征词表,实现对文本集数据的降维文本表示。将原本一篇数千字的科技论文,使用特征词表中出现的词汇进行表达,过滤特征词表中未出现的非特征词,从而达到降维、优化文本分类计算的效果。特征表中的词汇数量就是特征维度。特征维度的选取对文本分类效果具有决定性影响。为更好地对比分析4类特征抽取方法的效果,通过分组选取不同特征维度进行测试对比的方式,找出最优的特征抽取方法。每种方法为一组,分别进行特征维度为100、150、200、250、3 000、3 200等16次特征抽取实验。通过向量空间模型(VSM)将降维后的文本集进行文本向量化表示,供分类器进行文本分类运算。分类算法采用朴素贝叶斯分类算法[20]。
对分类结果的评价指标主要有准确率(accuracy)、精确率(precision)、召回率(recall)、F1值(F1-measure)及上述指标的宏观平均值[21]。
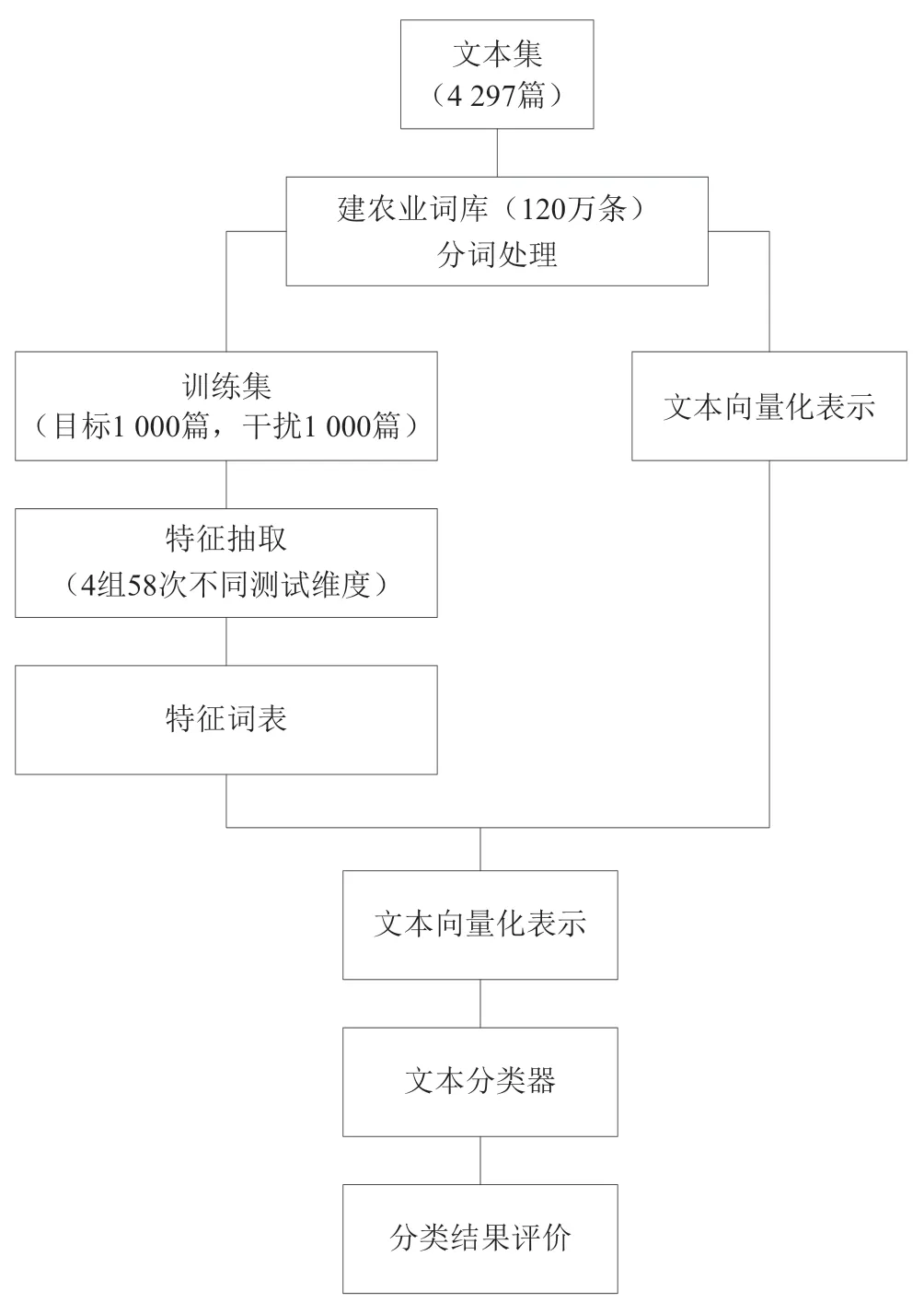
图1 特征抽取及文本分类实验流程
4 实验结果与分析
DF、IG-DF、TF-IDF和ImpTF-IDF-CHI 4种特征抽取方法在朴素贝叶斯分类下的应用评价结果如图2和表2所示。
(1)ImpTF-IDF-CHI方法相较TF-IDF方法,改进效果明显,无论从准确率与精确率,还是从召回率与F1值而言,均存在较大优势。在采用相同特征数量进行对比实验中,ImpTF-IDF-CHI方法的4个评价指标均大幅优于TF-IDF方法。ImpTF-IDF-CHI方法的16组实验的平均准确率为94.07%,平均F1值为0.844,而TF-IDF方法的平均准确率只有78.00%,平均F1值为0.566%。
(2)ImpTF-IDF-CHI方法相较IG-DF方法,结果更加稳定。由于进行信息增益计算的特征词必须满足文档词频超过预设的阈值,从而避免数据稀疏性问题。通过反复实验,在全部文本集中,满足超过阈值的全部特征词数为1 000词左右,所以在实验中IG-DF方法的对比实验截止到特征词数为1 000。由实验结果可以看出,IG-DF方法的不足在于特征抽取词的分类正确率波动太大,在本实验中,在特征词数为1 000时效果最好,但特征词数较少时,则效果较差,正确率方差为6.2%。IG-DF方法还面临数据稀疏性问题。在本实验中通过反复迭代设置阈值测试,最终确定阈值为190文档频率时,才能完全避免稀疏性问题。同时,阈值的大小与避免稀疏性存在一定正相关性,但绝非严格递进关系,如当阈值取200文档频率时,反而有些文档无法用IG-DF方法抽取出的特征词来表示,导致该文本为空的现象。ImpTF-IDF-CHI方法与之相比,稳定性优势较为突出,本实验中在特征词数量为250时效果最好,而整体上,在实际应用中任取某一组特征数量进行文本分类任务,其效果都较好。
(3)ImpTF-IDF-CHI方法相较DF方法,准确率、精确率和F1值都较高且稳定,但平均召回率(95.27%)略低于DF(96.27%),说明DF方法与朴素贝叶斯文本分类方法的组合,在应对长文本分类任务时有不错的表现。但从表3可以看出,DF方法仅从统计维度进行考量,提取的前N个特征词往往不具有该分类的主题代表性,如“研究”“表”“分析”“采用”“图”等。相比之下,ImpTF-IDF-CHI方法抽取的Top N个词就具有一定的主题代表性。
(4)ImpTF-IDF-CHI方法与3种传统方法整体比较,4单位评价指标中,3单位均为第一,且3单位指标的方差均为最小。在较为重要的平均准确率对比中,ImpTF-IDF-CHI方法高出第二名4个百分点,同时16次测试的准确率方差只有0.667%(方差最小说明最为稳定)。从图2中也可以看出,ImpTF-IDF-CHI方法曲线较为平滑。综合加权统计指标F1值高且接近于1,意味着精确率与召回率双高且较为平衡。ImpTF-IDFCHI方法的F1值领先第二名0.074,近8个百分点。另外,ImpTF-IDF-CHI方法抽取的主题词在4种方法中代表性最强(见表3)。
因此,综合比较可以得出:ImpTF-IDF-CHI方法在4种特征抽取方法中正确率最高、稳定性最好,与其他3种方法相比具有明显的优越性。

图2 DF、IG-DF、TF-IDF和ImpTF-IDF-CHI方法的准确率、F1值、精确率和召回率对比
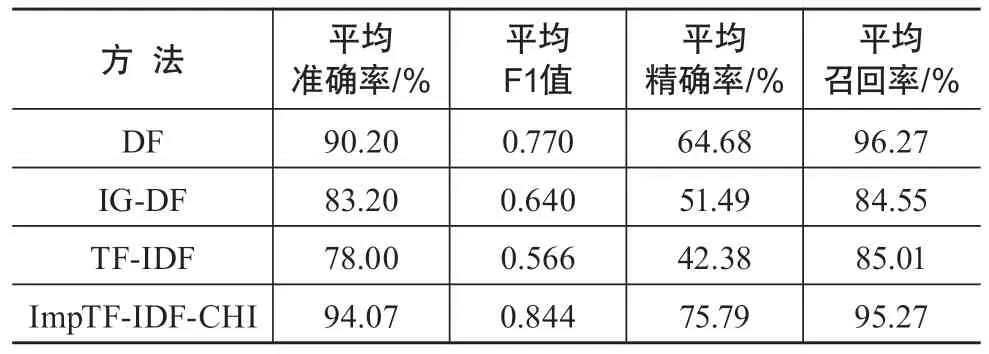
表2 DF、IG-DF、TF-IDF和ImpTF-IDF-CHI的平均准确率、F1值、精确率和召回率对比
5 结束语
本文针对相近农业科研领域文献的文本特征信息高度重合的特点,以及传统的文本特征抽取方法存在的不足,对TF-IDF算法进行优化并加以应用验证,提出了ImpTF-IDF-CHI方法,通过对照实验证明其与其他3种传统特征抽取方法相比具有较高的正确性与可靠性。ImpTF-IDF-CHI方法主要从特征词的重要性、代表性等因素考虑,通过使用相对词频与引入贡献因子等手段,提升特征词词频加权的代表性;同时,在构造函数中加入了卡方检验因子,强化特征词的分类特征一致性,使得同一分类下的特征词,在加权得分上更加聚合。
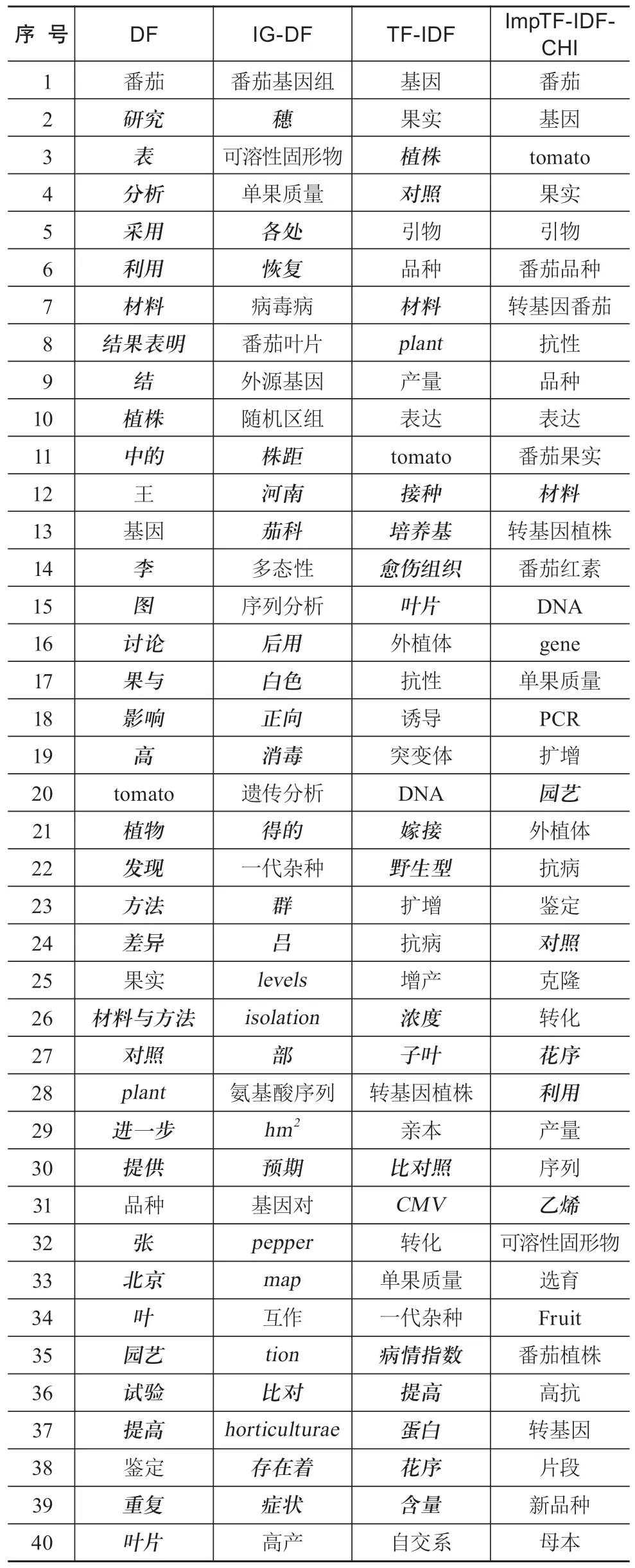
表3 4种特征抽取方法的Top 40特征词对比
首先本文用于实验的文本语料仅限于中文,尚未证明加权改进方法对英文等语种文献是否同样有效;其次,本文的文本分类任务是二元分类,尽管目前需要对科技文献进行二元分类的应用场合依然很多,但要满足需求的多元化,需要继续进一步优化方法及实现,以便适应多元分类需求,拓展ImpTF-IDF-CHI方法的应用范围;最后,词语在文档中位置不同,对文本特征的贡献度是不一样的,这也是需要在今后对该项技术进一步修改时要考虑的。
