基于泛在位置数据的城市道路网精细建模
2019-10-16邓敏1佘婷婷1黄金彩1刘慧敏1张建国郑旭东
邓敏1,佘婷婷1,黄金彩1,刘慧敏1,张建国,郑旭东
(1.中南大学地球科学与信息物理学院,湖南长沙,410083;2.博通智慧城市研究院,湖南长沙,410007)
道路网地理空间数据作为国家基础地理信息的重要组成部分,在智慧城市、智能交通以及居民日常生活方面发挥着重要的作用。随着城市交通的迅速发展,道路网结构日益复杂,几何拓扑精细、语义信息丰富、更新速度高的精细道路网信息成为智能交通和智慧城市建设中的关键需求。然而,传统的道路网数据采集方法需通过专业人员测绘或者卫星影像矢量化等,需要投入大量的人力和物力,成本较高[1]。新兴的泛在位置数据如车辆轨迹数据、社交媒体签到数据、兴趣点POI数据等具有来源广泛、实时、语义信息丰富等优点,在道路网几何、拓扑、语义的精细建模方面具有巨大的潜力,因此,利用泛在位置数据进行道路网精细建模已成为当前研究的热点问题。目前,基于泛在位置数据的道路网提取算法主要包括栅格化方法[2-4]、增量融合法[5-7]以及聚类法[8-10]。其中,栅格化方法的核心思想是将轨迹数据转化为灰度图像或者密度图像,采用数学形态学方法对图像进行膨胀和腐蚀操作来提取道路网;增量融合法主要以随机选取的1条轨迹作为初始路段,不断融入新轨迹线作为新增的路段,并提取整体道路网;聚类化法主要对轨迹点或轨迹线进行聚类并获得点簇或线簇,通过连接聚类中心点或线来提取道路网。这些方法主要用于提取道路网几何形态,且结构不够精细,尤其在交叉口处,几何拓扑结构信息丢失严重。此外,道路网语义信息(如道路名称、等级、速度信息)对于提供个性化导航服务、实现智能交通管控等方面具有重要作用。国内外相关学者利用泛在位置数据提取道路语义信息估计道路的平均行驶时间[11-12],对提取车道速度限制[12]、拥堵[13-15]和道路等级[12,16]等进行了研究,这些信息的获取通常需要与已有道路网匹配。然而,道路网日新月异的变化导致匹配的效果和效率都很不理想,难以提取道路网语义信息。为此,本文作者提出一种利用泛在位置数据对城市道路网几何、拓扑、语义进行精细建模的方法。首先,提取道路交叉口的位置和范围信息,实现交叉口和路段的分治;然后,针对道路交叉口内轨迹和路段轨迹进行分类,实现道路网精细的几何拓扑结构建模;最后,利用签到POI等位置文本和轨迹速度信息,提取道路交叉口转向规则、道路名称、速度等语义信息。
1 道路交叉口和路段分治策略
1.1 交叉口的位置和范围提取
据统计,60%的轨迹都为低频采样轨迹[17]。由于低频轨迹数据存在定位精度低、采样稀疏等问题,若根据角度方向阈值识别转向角变化较大轨迹点,则难以准确识别道路交叉口的位置和区域。然而,大量的轨迹点倾向于在交叉口处表现出较相似的时空、语义特性;轨迹点转向角亦具有较强空间相关性,表现为交叉口区域的高值正相关(热点)和路段区域的低值正相关(冷点)。采用局部空间自相关分析[18]探测交叉口内轨迹转向角热点,并利用自适应空间点聚类方法[19]进行热点聚类,识别交叉口的位置、范围。
令T={P1,P2,…,PN}为任一轨迹,其中,Pi为轨迹第i个采样点,

式中:i=1,2,…,N;xi为轨迹点Pi的横坐标;yi为轨迹点Pi的纵坐标;ti为轨迹点Pi的当前采样时间;νi为轨迹点Pi的瞬时速度;θi为轨迹点Pi的瞬时行驶方向角。利用热点分析识别道路交叉口位置和范围,如图1所示。图1(a)中,轨迹转向角定义为ai=|θi-θi-1|。轨迹点转向角的局部空间G*统计值[18]为


图1 利用热点分析识别道路交叉口位置和范围Fig.1 Identifying location and boundary of road intersections by hotspot analysis
式中:N为空间邻域内轨迹点i的邻域轨迹点个数。wij为点pi的空间权重。局部G*统计值是一种度量空间要素自相关程度的指标,用以测度空间要素与周围领域要素之间的相关程度,其中,正相关表示该要素与周围邻域要素的属性(如轨迹点转向角)呈正相关性,分为热点(高值正相关)和冷点(低值正相关)。某个轨迹点划分为热点的邻域内轨迹点的转向角都普遍较大,在空间上聚集于道路交叉口内,如图1(b)所示。局部G*统计能有效避免空间异常的影响,对轨迹点的噪音具有稳健性。本文将1%置信区间(G*>2.58)下的热点识别为交叉口轨迹点。
轨迹转向角热点分析能有效区分交叉口区域轨迹点和非交叉口区域轨迹点。进而,利用自适应空间点聚类算法(即ASCDT算法[19])进行热点空间聚类,以区分不同道路交叉口并提取交叉口的数量、位置和范围。ASCDT算法能够有效处理轨迹热点的不同形状、密度和等级所造成的空间异质性。通过分析ASCDT算法得到的结果,认为空间点簇的个数即为交叉口的个数,每个空间点簇的最小外接圆所覆盖的空间区域为道路交叉口的覆盖范围。
1.2 交叉口出入口检测
道路交叉口定义为连接3条及以上分支道路的区域[20],而每条分支道路都有1个入口和出口(单向通行道路只有1个入口或出口)。车辆轨迹由于受交叉口几何、拓扑结构的限制,会从分支道路的入口进入交叉口,并选择另一出口离开交叉口区域,因此,每条轨迹会在交叉口区域产生1个入口点和出口点,称为候选入口点和候选出口点。这些候选出入口点可通过计算轨迹和交叉口范围的交点得到。
设轨迹T的一段{Pi,Pi+1}与交叉口边界相交,并产生候选出入口点。由于低频轨迹具有低质量、低采样率等特性,{Pi,Pi+1}可能与多个交叉口相交,如图2所示。轨迹Tj的一段{Ps,Ps+1}与56号和57号交叉口相交。对于某一特定交叉口,轨迹段{Pi,Pi+1}与其空间相交关系仅包含以下3种:
1){Pi,Pi+1}进入交叉口,产生1个候选入口点ei,如轨迹Ti的一段{Pi,Pi+1}与47号交叉口相交,产生1个候选入口点ei。
2){Pi,Pi+1}离开交叉口,产生1个候选出口点ej,如轨迹Ti的一段{Pj,Pj+1}与47号交叉口相交,产生1个候选出口点ej。
3){Pi,Pi+1}通过交叉口区域,同时产生候选入口点ek和候选出口点et,如轨迹Ti的一段{Pk,Pk+1}与58号交叉口相交,产生候选入口点ek和候选出口点et。

图2 轨迹分段Fig.2 Track segmentation
基于上述轨迹段{Pi,Pi+1}与道路交叉口空间相交关系的类型,对研究区域内轨迹进行空间分段,可得到研究区域内所有轨迹与交叉口的交点,即候选出入口点。提取候选出入口点的计算流程见算法1。

其中:CM为研究区域中提取得到的所有交叉口数据;Cm为与该轨迹相交的交叉口数据集;s为循环变量;Cs为Cm的子集。根据算法1,可在研究区域内识别所有候选入口点Eentr和出口点Eexit。记录这些候选点所属轨迹ID、所属交叉口ID、坐标(x,y)等信息,将这些候选点进行标准化记录为
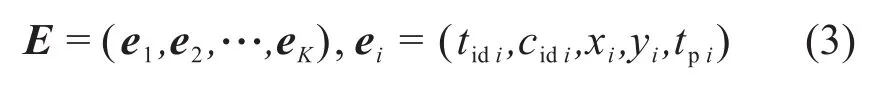
式中:K为研究区域中共有K个候选出入口点;ttid为点ei所属的轨迹编号;cid为点ei所属的交叉口编号;(x,y)为点ei的坐标;tp用以表示点ei为候选入口点(tp=0)或者候选出口点(tp=1)。根据候选出入口点所在轨迹的位置,可以将轨迹划分为交叉口内轨迹Tint(见图2中虚线)和路段轨迹Tout(见图2中实线)。

图3 基于候选出入口点自适应聚类的交叉口的出入口检测Fig.3 Intersection entrance and exit detection by adaptive clustering of candidate entrance and exit points
在提取候选出入口点E的基础上,选择任一交叉口内候选出入口点E(cid=i),利用ASCDT算法对E(cid=i)进行聚类,如图3(b)所示。该交叉口候选出入口点被识别为5个簇,为该交叉口连接了5个分支道路。将识别的簇划分为候选入口点簇E(cid=i,tp=0)和候选出口点簇E(cid=i,tp=1),分别计算候选入口点簇E(cid=i,tp=0)和候选出口点簇E(cid=i,tp=1)的平均坐标即为真实道路出入口位置,如图3(c)所示,其中,红色方框为交叉口入口点检测结果,黑色圆框为交叉口出口点检测结果。
2 道路网几何拓扑精细建模
2.1 交叉口转向模式聚类
2.1.1 轨迹几何相似性度量
为了对交叉口进行精细几何、拓扑建模,需要识别交叉口内转向模式。记T1={P1,P2,…,Pm},T2={P1,P2,…,Pn}为2条交叉口内轨迹,由于轨迹采样的稀疏性,T1和T2轨迹点之间并非存在一一对应关系,从而需要对轨迹进行重新采样。通常在2个采样点之间以dl(通常设置为25 m)为步长,等步长插入轨迹点。然后,以r为阈值(通常设置为25 m),定义2条轨迹之间的公共子轨迹。一般地,轨迹上可能存在多段公共子轨迹,记第i段公共子轨迹为si,最长公共子轨迹为lcstT1,计算式为

同理可计算T2的最长公共子轨迹。于是,T1与T2之间的最长公共子轨迹的相似性定义为

其中:|T1|表示轨迹T1的整体长度。
2.1.2 轨迹方向相似性度量
考虑到道路含2个不同行驶方向,识别交叉口转向模式需要顾及轨迹方向信息。车辆轨迹的方向相似性定义为2条轨迹之间方向的差异。为量化这种差异,对轨迹T1建立一种“距离-方向”函数F1(x),定义为

式中:x∈[0,1],是方向函数F1(x)的独立变量;xi∈[0,1],是从轨迹起点到轨迹上任一点Pi的累积长度与轨迹整体长度的比例,即轨迹段{P1,…,Pi}与轨迹整体{P1,…,Pm}的长度之比;Δxi为相邻轨迹点Pi+1和Pi累计长度比例差异;Δhi为相邻轨迹点Pi+1和Pi的行驶方向角。由式(6)可知,“距离-方向”函数是分段线性函数,如图4所示。
给定变量x∈[0,1],轨迹T1和T2的“距离-方向”函数分别描述为F1(x)和F2(x),进而轨迹T1和T2的方向相似性计算式为

图4 轨迹的“距离-方向”函数Fig.4 “Distance-direction”function of trajectories
式中:xi和xj分别为轨迹点Pi∈T1和Pj∈T2的累积长度比率;m和n分别为T1和T2的轨迹点个数;ΔF(x)为F1(x)和F2(x)的归一化差值,

基于轨迹的几何相似性和方向相似性,轨迹之间的总体相似性则可定义为sim(T1,T2)=simlcst(T1,T2)×0.5+simori(T1,T2)×0.5。则轨迹之间的距离矩阵可以定义为D=(dij)N×N(其中,dij=1-sim(Ti,Tj))。
2.1.3 交叉口转向模式聚类
由于同种转向模式轨迹之间存在较大相似性,因而,可利用轨迹层次聚类[21]的方法,对交叉口内轨迹Tint进行聚类,用于探测交叉口内的转向模式。在层次聚类过程中,利用“凝聚法”自底向上进行聚类,直到所有轨迹合并为1个簇为止。同时,利用Davies-Bouldin指标[22]对聚类结果有效性进行评价(即DB指标),识别合理的转向模式个数。本文将聚类个数设置为n1~n2(实验中设置为2~40),选择DB指数最小时对应的聚类个数K为最佳聚类结果。通过分析DB指标可以发现,有效的聚类簇内部应足够紧密,且簇与簇之间具有较大分离性,可通过计算簇的紧密性和分离性比率对聚类结果进行评价。因此,DB指标越小,聚类有效性越强。
2.2 路段轨迹分类
在出入口识别的基础上,轨迹被划分为交叉口内轨迹Tint和路段轨迹Tout,其中,可从Tout中提取路段的几何、拓扑结构信息。通过分析交叉口连通性对路段进行几何、拓扑精细建模。
Tout可划分为2类:包含1个候选出入口点的轨迹和包含多个候选出入口点的轨迹。交叉口及其拓扑连接矩阵示意图如图5所示(其中,0表示无连接,1表示存在连接)。由图5可知包含1个侯选出入口的轨迹所在的路段为悬挂路段,由于候选出入口点信息包含所属交叉口编号,因此,构造交叉口之间的拓扑连接矩阵D,根据交叉口的拓扑连通性对路段轨迹进行分类。如图5所示,矩阵内元素D(i×j)为交叉口之间的同一类连接模式,即交叉口i与j之间有轨迹连接。由于存在单向通行道路的存在,因此,矩阵D是非对称矩阵,若存在交叉口3到5的轨迹,而5到3的轨迹不存在,则所提方法具有提取车道级道路网的能力。
根据交叉口之间的拓扑连接矩阵D(N×N),可对轨迹进行分类。首先,根据D(N×N)筛选出属于同种连接模式D(i×j)的路段轨迹Tout(i,j);然后,利用2.1.3节所提轨迹聚类方法对Tout(i,j)进行聚类。由于受道路交叉口探测精度影响,若干道路交叉口未被探测,本文对Tout(i,j)进行聚类可识别不同连接路径,从而考虑交叉口探测精度的影响。2条交叉口之间轨迹Tout(i,j)的不同连接模式如图6所示,其中,实线为交叉口的不同连接路径,本文方法能够对其有效识别。
对于悬挂路段(图6中虚线),其特点在于只含1个候选出入口点,因此,分别提取每个交叉口的悬挂轨迹数据Tout(i),根据2.1.3节轨迹聚类方法对Tout(i)进行聚类。在上述基于交叉口连通性分析和悬挂轨迹分类的基础上,可对研究区域路段轨迹Tout进行有效分类,进而对每一类轨迹的中心线进行提取,获得城市道路网的精细几何和拓扑结构。

图5 交叉口及其拓扑连接矩阵示意图Fig.5 Intersections and topological connection matrix

图6 2个交叉口之间轨迹Tout(i,j)的不同连接模式Fig.6 Different connection modes of track Tout(i,j)between intersection i and j
2.3 道路网几何、拓扑结构精细建模
在对Tint和Tout进行聚类、分类的基础上,令CL(i)为Tint或Tout的轨迹簇,采用K段主曲线算法[23]提取CL(i)的中心线即车道线,进而生成道路网,记为RD。
K段主曲线由VERBEEK等提出[24],采用局部主成分分析的方法来计算第K条线段,依据光滑性连接形成主曲线,如图7所示。K段主曲线的算法步骤主要由以下几步组成。
Step 1:初始化。输入轨迹点数据P=(P1,P2,…,Pn),计算第1主成分,并取3σ为初始的线段长度,其中σ是第1主成分的标准差,得到初始线段l1和其Voronoi区域V1。
Step 2:插入新线段。若k≤kmax,则计算Pi并满足:
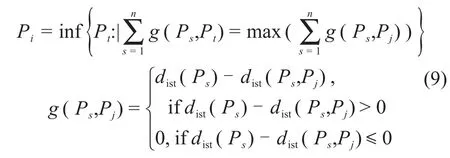
式中:dist(Ps)=mind(Ps,lj),为Ps与线段lj之间的最小距离;dist(Ps,Pj)=||Ps-Pj||2,为Ps与Pj之间距离的平方;j∈1~k。计算点Pi的Voronoi区域Vq并取Vq的第1主成分线,以3σ作为新增线段lk的长度并记录其 Voronoi区域Vk。
Step 3:调整。若新增线段后,所有线段旧的Voronoi区域{V1,V2,…,Vk}与新的 Voronoi区域{V1′,V2′,…,Vk′}不同,则将新的 Voronoi区域赋给旧的Voronoi区域,并重复Step 2,直到Voronoi区域不变为止。
Step 4:优化。将k条线段构造成哈密顿回路,并利用城市旅行商问题(TSP)进行优化形成哈密顿回路。
3 基于车辆轨迹和签到文本的道路网语义信息建模
3.1 交叉口转向规则语义提取
交叉口内轨迹簇的转向规则可通过挖掘每条轨迹的转向规则得到。交叉口转向规则判别如图8所示。
设P1为轨迹起始点,Pm为该轨迹终点,θ1和θ2分别为P1和Pm的行驶方向角,Pi为轨迹上任一点,则该轨迹的转向规则如下:
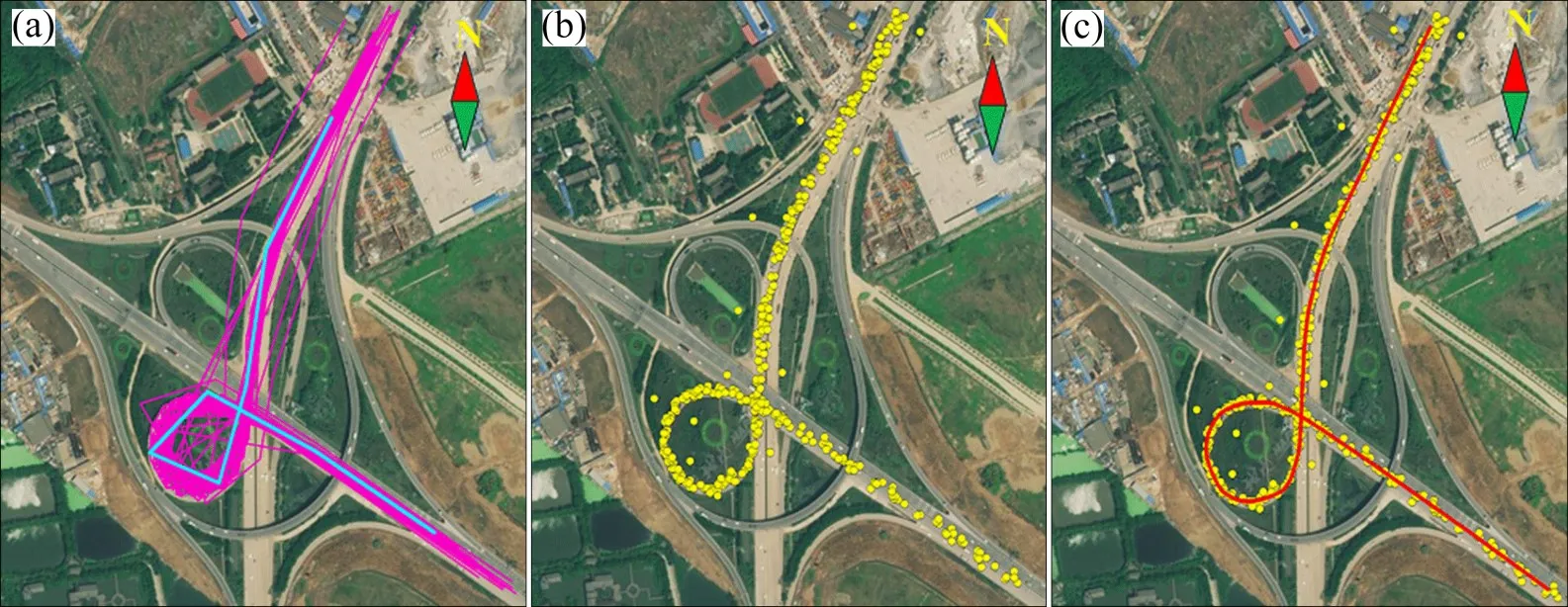
图7 利用K段主曲线提取车道线Fig.7 Extracting lane lines using K-segment principal curve

图8 交叉口转向规则判别Fig.8 Intersection turning rules inference
1)若θ1-θ2≈ ±180°,则转向规则为“掉头”;2)若P1Pm×P1Pi(1<i<m)为正,则转向规则为“右转”;
3)若P1Pm×P1Pi(1<i<m)为负,则转向规则为“左转”;
4)若P1Pm×P1Pi(1<i<m)为零向量,则转向规则为“直行”。
通过上述分析可得到轨迹簇内每条轨迹的转向规则:当簇内超过50%以上轨迹判定为某一特定转向规则时,则该转向规则定义为轨迹簇的转向规则;当交叉口内未发现某个转向规则的轨迹簇时,则认为该转向规则在交叉口内是禁止的。
3.2 道路名称提取
地图POI和微博签到文本中包含大量与道路相关的信息,如道路名称等。本文利用高德地图POI和新浪微博签到文本数据,基于Jiaba分词技术(https://github.com/fxsjy/jiebademo),从这些位置文本的地址字段中将道路名称划分出来。如对于POI地址“湖北省武汉市江汉路527号,武汉美术馆对面”,利用Jieba中文分词之后的结果为:“湖北省/武汉市/江汉路/527/号/,/武汉/美术馆/对面”。进而,提取出含有“路”“大道”“街道”和“街”关键词的词语。
由于POI数量众多,密度空间分布差异大,可将POI与道路网进行匹配,以50 m为缓冲区,提取道路路段的缓冲区内的POI数据,如图9所示。然后,基于Jieba分词技术提取其缓冲区内POI所含道路名称,生成道路名称频度直方图,并选取频度最大的道路名称为该路段道路名称。从图9可见:示例路段的名称可以描述为“丁字桥路”。
3.3 道路网平均速度提取
将所提取道路网按100 m进行重采样(即速度信息识别的空间分辨率设置为100 m),记为RD={e1,e2,…,em},并将GPS轨迹点与所建模的道路网进行匹配。于是,道路网RD的每条边ei都有若干GPS点(记为Pei={P1,P2,…,Pni})与之匹配,这些GPS点的时间和速度信息可用于提取道路网的速度信息。将Pei划分为24个时段,统计路段ei在24个时段内平均速度信息,从而获得整个路网RD在24个时段内的速度信息。
4 实验结果与分析
4.1 实验数据
为验证本文方法的有效性,选取武汉市武昌区一块靠近长江南岸、面积约13 km×11 km的区域作为实验区域。该研究区域为武汉市人口、经济、商业较集中的区域,包含武昌火车站等交通枢纽和洪山广场等商业中心,并包含复杂道路网结构。如研究区域内包含了十字路口、T型路口、Y型路口、立交桥、环形路口等各种形态各异、结构复杂的道路交叉口。此外,在武昌火车站附近,道路网密度高,交叉口密集,适合验证本文所提方法在处理复杂路网、密集路网的有效性。选取2014年5月1日的浮动车GPS轨迹数据,包含1 129 466个轨迹点,经重采样和预处理后,含60 045条轨迹线。
4.2 道路交叉口位置和范围探测
利用热点分析和聚类方法对交叉口的位置和范围进行探测,结果如图10所示。

图9 利用缓冲区内POI进行道路段名称提取Fig.9 Road name extraction using POI in buffer for

图10 研究区域交叉口探测结果Fig.10 Results of intersection detection of study area
从图10可见:转向角热点主要分布于交叉口区域,表明热点分析的有效性;此外,研究区域包含大量复杂类型的道路交叉口,空间分布密度不一、形态各异、大小和范围差异巨大,采用本文方法较好地探测了道路交叉口的位置和范围。为了对道路交叉口探测结果进行定量评价,采用本文方法与文献[24]中方法分别计算交叉口探测结果的精度P、召回率R和F,表达式为:

式中:tp为正确探测交叉口数量;fp为错误探测交叉口数量;fn为未探测交叉口数量。通过与百度地图、高德地图进行人工判别,经统计发现本文所提方法共识别道路交叉口157个,正确识别136个,错误识别21个,未识别26个。由式(10)可知:本文方法交叉口探测精度P、召回率R和F分别为86.6%,84.0%和85.3%;文献[24]所提方法共识别道路交叉口186个,正确识别138个,错误识别48个,未识别24个,因而,交叉口探测精度P、召回率R和F分别为74.2%,85.2%和79.3%。图11所示为本文方法和文献中[24]中方法所提路网与遥感影像的叠加对比结果。从图11可以发现:本文方法提取的道路骨架与影像中道路更加吻合,包含更少误提取的悬挂路段;同时,本文方法计算的交叉口探测精度P以及F明显比文献[24]中方法的效果好。从图11(b)可以发现本文方法可以有效地提取精细的复杂道路交叉口。
4.3 道路网几何拓扑、语义精细建模结果
道路网精细几何拓扑结构、道路名称信息和速度信息的建模结果如图12所示。
从图12可见:所生成的道路网具有名称、方向、速度等信息,在路段上包含2条车道线,也体现了本文方法在道路网精细建模方面的优势。其中,图12(b)所示为立交桥区域模拟结果,由于高程差异导致立交桥几何结构复杂,本文成功地对其进行了精细建模;图12(b)和(c)所示为较复杂道路交叉口模拟结果,其中,图12(b)左上角所示为包含高架式立交桥模拟结果,图12(c)所示为环形路口模拟结果。图12(d)~(f)所示分别为十字路口、“T”型路口、“Y”型路口较常见道路交叉口。可见,研究区域包含的道路交叉口形态各异、结构复杂,所提方法对研究区域道路网实现了精细建模,在路段和交叉口几何拓扑结构上,具有精细车道线;在语义信息方面,提取了道路网名称、速度等信息。

图11 本文方法与文献[24]中方法提取路网与遥感影像比较Fig.11 Comparison between remote sensing image and road network extracted by methods in the paper and Ref.[24]
为了验证本文方法道路名称提取结果的有效性,通过对高德地图、百度地图进行人工判断,共识别含名称的道路237个,其中正确识别的道路名称为229个,错误识别的道路名称为8个,未识别的道路名称有8个,因而,道路名称识别的精度P、召回率R和F分别为97.0%,96.6%和96.8%,表明本文方法在复杂城市场景下道路网几何、拓扑、语义精细建模方面的有效性。
将所建模道路网的平均速度信息划分为24个时段,统计道路网24个时段内的平均速度,并划分到[0,5),[5,10),[10,15)和[15,+∞)共4个区间内,分析其时空特征。图13所示为其中4个主要时刻道路网平均速度的空间分布情况。从图13可见:道路网平均速度的空间分布在一定程度上表征了道路拥堵的时空分布特征。
本实验中采用2014年5月1日的车辆GPS轨迹数据对道路网平均速度进行演化分析,可以发现:1)9:00—12:00,武昌火车站附近具有明显的拥堵现象,这可能由于“五一节”旅游人数增多,导致上午在武昌火车站附近呈现明显的车流高峰,并且一直持续到12:00;2)在24个时段内,研究区域下方的立交桥附近较少出现车辆行驶缓慢的现象,表明该区域无拥堵出现;3)武珞路作为武汉市较繁华的路段,从8:00—16:00都具有明显的车辆行驶缓慢现象,而16:00后车行缓慢现象减轻;4)雄楚大道与岭南路交叉口处,在9:00—12:00易发生拥堵,交通缓慢,此外,在20:00—23:00容易发生拥堵,表明该交叉口具有重要的交通地位。整体上看,10:00—12:00的拥堵情况最严重,这种拥堵现象可能与“五一节”假期出行高峰有关,16:00—22:00则易出现局部车行缓慢现象。
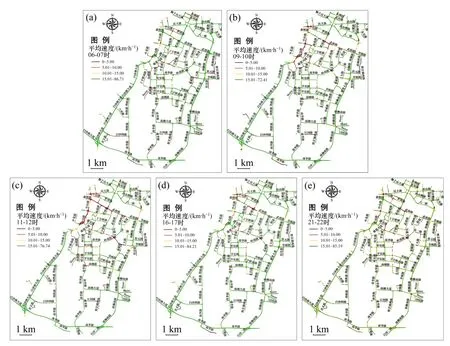
图13 道路网若干典型时段内平均速度信息Fig.13 Road network average speed information of several typical time
5 结论
1)道路网精细几何、拓扑、语义信息是实现智能交通、导航及行车规划的前提。泛在位置数据由于具有动态、实时的特性,为道路网精细信息的实时获取提供了新的数据源。
2)本文提出一种城市道路网几何、拓扑、语义信息一体化精细建模方法。利用武汉市车辆轨迹数据进行实验分析,验证了本文方法的有效性。所提方法可以满足快速实时道路网几何、拓扑、语义信息精细获取需要,为智慧城市建设、智能交通系统提供支持。
