基于生成对抗网络的图像盲去运动模糊算法
2019-10-15陈富成陈华华
陈富成 陈华华


摘 要:针对运动图像盲去模糊问题,基于生成对抗网络,提出利用一种端对端方式恢复模糊图像算法。运用生成对抗神经网络方法对运动模糊图像直接复原,跳过估计模糊核过程,增加感知损失作为损失项,使图片内容和全局结构接近。此外,增加结构相似性损失函数作为约束项,进一步提升生成图片与清晰图片的相似性。实验结果表明,新算法可有效去除运动图像模糊。与其它算法相比,所提算法获得的图像更加清晰。
关键词:生成对抗网络;去运动模糊;感知损失;结构相似性损失
DOI:10. 11907/rjdk. 182666 开放科学(资源服务)标识码(OSID):
中图分类号:TP317.4 文献标识码:A 文章编号:1672-7800(2019)008-0208-04
Image Blind Motion Deblur Algorithm Based on Generative Adversarial Network
CHEN Fu-cheng,CHEN Hua-hua
(School of Communication Engineering, Hangzhou Dianzi University, Hangzhou 310018,China)
Abstract: Non-uniform blind deblurring of motion scenes has been a challenging problem in the field of image processing. Aiming at the blind deblurring problem of moving images, we propose a neural network based on conditional generation confrontation to recover the motion blur algorithm caused by motion in an end-to-end manner. The method of generative adversarial network is used to directly recover the motion blurred image, and the process of estimating the blur kernel is skipped. Increasing the perceptual loss as a loss term makes the content of the picture close to the global structure. In addition, the structural similarity loss function is added as a constraint term to further constrain and enhance the similarity between the generated image and the clear picture. The experimental results verify that the proposed new algorithm can effectively remove the blur of moving images. Compared with other algorithms, the proposed algorithm can obtain clearer images.
Key Words: generative adversarial network; motion deblur; perceptual loss; structural similarity loss
作者简介:陈富成(1993-),男,杭州电子科技大学通信工程学院硕士研究生,研究方向为图像处理;陈华华(1976-),杭州电子科技大学通信工程学院副教授,研究方向为图像处理、计算机视觉、模式识别。本文通讯作者:陈华华。
0 引言
在医学成像[1-2]、交通安全[3-4]、摄影学[5-6]、目标识别与追踪[7-8]、天文探测[9-10]等领域,获得一幅清晰图像尤为重要。但在图像成像过程中,拍摄设备与成像物体之间很难保持相对静止状态,会造成图像模糊。运动图像的模糊过程可看作是清晰图像和一个二维线性函数卷积运算后,受到加性噪声污染得到的。该线性函数称为点扩散函数[11]或卷积核,包含图像的模糊信息。图像的盲去模糊指在模糊方式未知(即模糊核未知)的情况下,仅依靠模糊图像本身信息还原出原始清晰图像。
针对图像盲去模糊问题,文献[12]基于自然图像梯度服从重尾效应的统计规律,推演出模糊核;文献[13]根据模糊图像的突出边缘与低秩先验,为模糊核估计提供可靠的边缘信息,低秩先验为中间图像提供数据可靠的先验。但这些方法对模糊核的估计仍然不准确,尤其是在运动遮挡或不连续情况下,这种不准确的核估计会导致振铃效应。
传统方法在解决函数逼近问题时存在不足,导致图像去模糊效果不理想。大数据时代,深度学习得到了迅猛发展,其在图像盲去运动模糊中的应用越来越广泛。文献[14]提出了一種准确估计模糊核算法:首先训练一个卷积神经网络,把模糊图像恢复成中间图像,然后结合模糊图像与中间图像准确估计单个全局模糊核;文献[15]提出一种连续去模糊方法,通过似然项和平滑先验优化卷积神经网络得到模糊核。以上方法都需要结合传统的优化方法进行,所以需要精确的核估计步骤;文献[16]采用条件对抗网络,以端到端方式直接生成清晰图像,其在损失函数中加入感知损失以提高生成图像与输入图像在内容和全局结构上的相似性。
理想情况下,该输出目标应该与输入样本相似,但是生成对抗网络[17]并不会限制生成器输出,这就造成很多时候生成器的输出不稳定。本文在文献[16]的基础上引入结构相似性作为生成器约束项,以限制生成器输出。将训练好的模型在几个不同的运动模糊场景中测试,结果表明该模型能高效恢复模糊图像。
1 盲去运动模糊模型
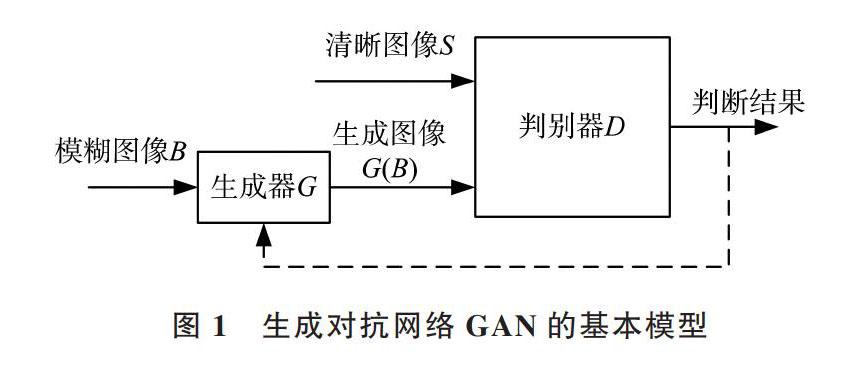
生成对抗网络模型基本框架如图1所示,将由运动造成的模糊图像B输入到生成器G得到生成图像G(B),生成图像G(B)与清晰图像S一同输入判别器D中,分别将其映射为一个判别器,以判别为真的概率值。生成对抗网络是一个互相博弈的过程,生成器依据判别器的判别结果进行优化,而判别器则努力去判别清晰图像与生成图像,直到判别器无法区分清晰图像与生成图像为止,此时生成器的去模糊效果达到最好。
图1 生成对抗网络GAN的基本模型
本文在生成对抗网络的图像盲去运动模糊模型中,训练一个CNN作为生成器G, 判别器由卷积层、全连接层和激活层构成,对抗网络的目标函数为:
式(1)中,[S~psharp(S)]表示清晰图像S取自真实清晰图像集,[B~pblurry(B)]表示模糊图像,B取自模糊图像集,E表示期望,D表示判别器对输入图像为真的概率。该损失函数存在判别器越好生成器梯度消失越严重的问题,故采用WGAN[18]方法,将损失函数改为:
[l=n=1N-DθD(GθD(IB))] (2)
为提高生成图像、输入图像内容与全局结构的相似性,引入感知损失函数[19]。为限制生成器输出,引入结构相似性函数作为生成器G的约束项。
1.1 总损失函数
总损失函數由对抗损失、感知损失、结构相似性损失组合而成。
[L=lGAN+λ?lX+κ?LSSIM(P)] (3)
1.2 感知损失函数
理论上生成图像I与清晰图像S在内容及全局结构上的相似性应尽可能接近,故以感知损失函数表示生成图像I与清晰图像S之间的差异。
[lX=1Wi,jHi,jx=1Wi,jy=1Hi,j(φi,j(S)x,y-φi,j(I)x,y)2] (4)
式(4)中,[φi,j]是在VGG19[20]网络下第i层最大池化之前通过第j层卷积层获得的特征映射,[Wi,j]和[Hi,j]是特征映射的宽度和高度。
1.3 结构相似性(SSIM)损失函数
原始GAN在生成图像时是没有约束的,故生成器很容易失去训练方向,导致训练不稳定、梯度消失和模式崩溃问题,故引入图像结构相似性损失函数[21]作为约束项,约束生成器的训练。结构相似性定义为:
[SSIM(p)=2μxμy+c1μx2+μy2+c1?2σxy+c2σ2x+σ2y+c2] (5)
式(5)中,[μx]、[μy]是图像块像素的平均值,[σx]、[σy]是图像像素值的标准差,[σxy]是两个图像像素的协方差,[c1]、[c2]为常数。
SSIM越大越好,所以把损失函数改写成:
[LSSIM(P)=1Np∈P1-SSIM(P)] (6)
即求[LSSIM]的最小值。但是这样无法解决图像像素的边界问题,所以重写损失函数如下:
[LSSIM(P)=1-SSIM(p)] (7)
[p]表示像素块的中间像素值。
2 网络模型
2.1 生成器网络
生成器网络模型如图2所示。生成器网络共由14块组成,其中每一块里面包含了卷积层、Instance归一化层、Relu激活函数层。在每个残差块的第一个卷积层后面添加概率为0.5的Dropout正则化。第一块卷积层为3通道,卷积核大小为7×7,步长为1。第二块与第三块的卷积核大小为3×3,步长为2,补零宽度为1。后面接入9个卷积核大小为3×3、步长为2、padding为2的残差块。最后是两个卷积核为3×3、步长为2、padding为1、output_padding为1的反卷积块。第一层卷积核大小为4×4×3,步长为2,共有128个卷积核生成128张输出;第二层卷积核大小为3×3×128,卷积步长为2,共有512个卷积核生成512张输出;第三层卷积核大小为3×3×512,卷积步长为2,共有1 024个卷积核生成1 024张输出;接着连接一个1 024维输出的全连接层,再连接一个一维的全连接层和sigmoid函数得到输出。此外,引入全局跳跃连接使生成器可从模糊图像学习到残差校正。
2.2 判别器网络
判别器是在生成器训练完毕后对生成器生成的图像判定为真的概率。当概率大于0.5时,将输入图像判为清晰图像,反之将其判定为生成图像。判别器网络前面由4个卷积块组成,其中每块包含卷积块、Instance归一化层和LeakyReLU激活层。第一层卷积核大小为4×4×3,步长为2,共有128个卷积核生成128张输出;第二层卷积核大小为3×3×128,卷积步长为2,共有512个卷积核生成512张输出;第三层卷积核大小为3×3×512,卷积步长为2,共有1 024个卷积核生成1 024张输出;接着连接一个1 024维输出的全连接层,再连接一个一维全连接层和sigmoid得到输出。
2.3 网络结构
该模型的网络结构如图3所示。将模糊图像B作为生成器输入,并输出恢复的模糊图像G(B)。在生成器训练期间,恢复图像G(B)和清晰图像S作为输入并估计它们之间的结构相似性差异与特征差异。完整的损失函数有对抗损失、结构相似性损失和感知损失。
图3 算法模型
3 实验结果分析
3.1 实验设计
本实验在Linux操作系统下基于PyTorch深度学习框架实现。计算机配置参数如下:3.4GHz的i3处理器台式机,NVIDA GTX1060显卡,16GB RAM。模型在随机剪裁的256×256像素的GoPro数据集上训练。因为该模型是全卷积,又是在剪裁的图像块上训练,故可应用在任意大小的图像中。将生成器和判别器的学习速率设置为1×10-4效果最好。经过150次迭代后,后150次迭代的学习速率呈线性衰减。本模型参数经过多次实验调整,将[λ]设置为100,[κ]设置为0.84,[C1]、[C2]分别设置为2.55、 6.75。经过实验优化,选择自适应矩估计优化策略。验证表明,将batch size设置为1时效果最好。
3.2 数据集预处理
GoPro数据集分训练集和测试集。该数据集内含有车辆、行人等多个运动场景造成的图像模糊,所以在运动去模糊领域应用较为广泛。训练集含有2 103张运动模糊图片和与之相对应的清晰图片,测试集内含有1 000张运动模糊图像和与之对应的清晰图像。将训练集尺寸随机剪裁为256×256,把模糊图像与对应的清晰图像相匹配同时作为生成器的输入。
3.3 实验结果
该模型在GoPro数据集上训练迭代60万次后达到收敛状态。在不同的运动模糊场景中进行测试,本文模型的输出结果与文献[16]模型的输出结果对比见图4。
图4 原模糊图像与各类算法去模糊结果
结果表明,本文算法模型的去模糊效果比文献[16]在细节方面有明显提升,该模型可解决由拍摄设备与物体间相对运动造成的模糊,而不仅仅是人为的模糊。表1列出了几种算法比较,可以看出,平均PSNR与SSIM表现得更为突出。
表1 GoPro测试集下的平均值
实验结果表明,本文模型对运动模糊图像有较好的去模糊效果,但是图像细节部分依然存在模糊现象。由于图像运动是一个连续的过程,而图像的成像是在曝光时间内所有影像的集合。所以,硬件设备越差,成像过程丢失的信息就越多,这对去运动图像模糊来说是个很大的难题。若要降低圖像成像过程中信息丢失对图像去模糊的不利影响,可采用高帧数拍摄设备。
4 结语
本文提出的图像盲去运动模糊算法,针对GAN网络模型训练不稳定问题,引入结构相似性损失函数作为约束项进行创新。实验证明本文方法优于其它算法,提高了图像去模糊效果。但是本文提出的算法训练参数过多,增加了训练复杂度,而且在实际处理运动模糊图像时仍存在不足,下一步将重点研究如何在去模糊效果不降低的情况下减少训练参数、降低训练复杂度。因为真实运动模糊图像一般都具有多种模糊情况,所以要考虑适当增加卷积核的感受野大小。
参考文献:
[1] MICHAILOVICH O V, ADAM D. A novel approach to the 2-D blind deconvolution problem in medical ultrasound[J]. IEEE Transactions on Medical Imaging, 2005, 24(1):86-87.
[2] MICHAILOVICH O, TANNENBAUM A. Blind deconvolution of medical ultrasound images: a parametric inverse filtering approach.[J]. IEEE Transactions on Image Processing, 2007, 16(12):3005-3019.
[3] 隋晔,马钺. 交通监控系统中运动目标分类和跟踪研究[J]. 信息与控制, 2003, 32(1):61-64.
[4] 张敏. 视频监控中运动目标检测与清晰化方法的研究[D]. 镇江:江苏大学,2010.
[5] YOU Y L, KAVEH M. A regularization approach to joint blur identification and image restoration[M]. Piscataway:IEEE Press, 1996.
[6] SROUBEK F,FLUSSER J. Multichannel blind deconvolution of spatially misaligned images[J]. IEEE Transactions on Image Processing,2005,14(7):874-875.
[7] WU Y. Blurred target tracking by blur-driven tracker[C]. IEEE International Conference on Computer Vision. IEEE, 2011:1100-1107.
[8] DAI S, YANG M, WU Y, et al. Tracking motion-blurred targets in video[C].IEEE International Conference on Image Processing, 2006:2389-2392.
[9] SCHULZ T J. Multiframe blind deconvolution of astronomical images[J]. Journal of the Optical Society of America A, 1993, 10(5):1064 - 1073.
[10] HANISCH R J, JACOBY G H. Astronomical data analysis software and systems x[J]. Publications of the Astronomical Society of the Pacific, 2001, 113(784):772-773.
[11] 郎锐. 数字图像处理学[M]. 北京:希望电子出版社, 2002.
[12] FERGUS R, SINGH B, HERTZMANN A, et al. Removing camera shake from a single photograph [J]. ACM Transactions on Graphics, 2006, 25(3):787-794.
[13] PAN J, LIU R, SU Z, et al. Motion blur kernel estimation via salient edges and low rank prior[C].IEEE International Conference on Multimedia and Expo, 2014:1-6.
[14] CHAKRABARTI A. A neural approach to blind motion deblurring[C]. European Conference on Computer Vision. Springer, Cham, 2016:221-235.
[15] SUN J, CAO W, XU Z, et al. Learning a convolutional neural network for non-uniform motion blur removal[C].IEEE Conference on Computer Vision and Pattern Recognition,2015:769-777.
[16] KUPYN O,BUDZAN V,MYKHAILYCH M,et al. Deblurgan: blind motion deblurring using conditional adversarial networks[EB/OL]. https://cloud.tencent.com/developer/article/1096122
[17] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. International Conference on Neural Information Processing Systems,2014:2672-2680.
[18] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein gan[J]. arXiv preprint,2017(3):1701-1711 .
[19] JUSTIN JOHNSON,ALEXANDRE ALAHI,LI F F. Perceptual losses for real-time style transfer and super-resolution[EB/OL]. https://github.com/jcjohnson/fast-neural-style.
[20] KAREN SIMONYAN,ANDREW ZISSERMAN.Very deep convolutional networks for large-scale image recognition[EB/OL]. https://arxiv.org/abs/1409.1556.
[21] ZHAO H,GALLO O,FROSIO I,et al. Loss functions for neural networks for image processing[J]. Computer Science,2015(3):2411-2419.
[22] NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring[DB/OL]. https://arxiv.ogr/abs/1612.02177.
[23] KIM T H,LEE K M. Segmentation-free dynamic scene deblurring[C]. Columbus:IEEE Conference on Computer Vision and Pattern Recognition, 2014.
(責任编辑:杜能钢)
