基于用户兴趣的文献个性化推荐研究
2019-10-15关菲李晓静
关菲 李晓静
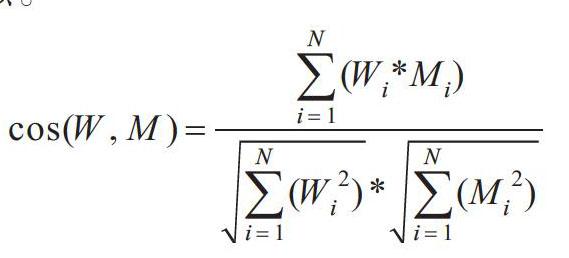

摘 要:针对当前文献推荐中个性化程度不高等问题,提出一种对用户行为重新分配权重的度量算法。运用用户行为数据按照时间顺序重新分配权重,突出近期用户兴趣构建用户兴趣模型。通过LDA主题分布、关键词分布等方法构建学术资源模型,实现两模型间匹配,完成推荐。通过实验验证,该算法准确性达到80%,比传统等权重算法提高近20%,召回率与F值分别提升了7%和5%。研究表明,基于时间因素的用户兴趣度量算法相较于传统等权重算法具有更高的准确性,未来可进一步优化用户兴趣度量以实现精准推荐服务。
关键词:精准推荐;学术资源;用户兴趣;个性化推荐
DOI:10. 11907/rjdk. 191868 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2019)008-0170-04
Personalized Recommendation of Literature Based on User Interest
GUAN Fei,LI Xiao-jing
(School of Mathematics and Statistics, Hebei University of Economics and Trade, Shijiazhuang 050061,China)
Abstract: To solve the problem of low degree of personalization in current literature recommendation, a measurement algorithm for reallocating weights to user behaviors is proposed. The paper uses the user behavior data to redistribute the weight according to the time sequence, and highlights the recent user interest to build the user interest model. Through LDA topic distribution, keyword distribution and other methods to build academic resource model, the two models were matched and the recommendation was completed. The experimental results show that the accuracy of the algorithm reaches 80%, which is nearly 20% higher than the traditional equal weight algorithm. The recall rate and F value are increased by 7% and 5% respectively. The user interest measurement algorithm based on time factor has higher accuracy than the traditional equal weight algorithm. In the future, the user interest measurement can be further optimized to provide ideas for optimizing accurate recommendation services.
Key Words:accurate recommendation; academic resources; user interest; personalized recommendation
基金項目:河北省自然科学基金青年项目(F2017207010)
作者简介:关菲(1985-),女,博士,河北经贸大学数学与统计学学院副教授、硕士生导师,研究方向为模糊对策与决策、数据挖掘;李晓静(1994-),女,河北经贸大学数学与统计学学院硕士研究生,研究方向为大数据分析。
0 引言
数字驱动时代,人们生活方式已完成从手动自给自足到科技信息化的过渡,知识扩张和科技发展为社会的现代化进程提供了助力。现代化主要指以现代工业、科技革命为推动力,由传统社会向现代社会转化的历史过程,涵盖了生活便捷、信息丰富等多方面。现今人们的社交也不限于面对面的交流,更多的是应用电子软件进行网上会话、网上购物等方式。传统学习方式也发生变化,人们可以利用网络搜索自己感兴趣的知识进行学习,方便快捷、省时省力。当前,网络技术支持每一个拥有通讯设备的人完成各种网上操作,无形中会有各种使用痕迹留存网站。研究者可以根据这些代表之前网络行为的历史数据总结用户偏好,预测下一步行为倾向,在实施搜索之前给予推荐,达到智能个性化推荐效果。数据是一种信息资源,网上数据繁多,用户行为呈现指数级增长,如何对其合理利用是实现精准推荐的重点和难点。
目前,学者利用的推荐方法有协同过滤、基于内容推荐和基于知识推荐等,但大多个性化推荐服务都存在个性化程度不高、推荐准确度较低等问题,不能很好地度量用户兴趣。相关研究大多从推荐算法设计和兴趣模型构建两方面着手。黄珊珊[1]利用改进的LDA主题模型对微博短文本和粉丝微博内容进行分析,丰富用户兴趣、拓宽推荐内容,但并未考虑用户兴趣转移问题;徐吉等[2]基于协同过滤算法,构建兴趣迁徙模型和用户信任度模型,提升推荐准确性;林耀进等[3]提出基于用户群体推荐算法,增强推荐系统稳定性;刘珊珊[4]采用混合协同过滤方法完成用户感兴趣数据筛选,从而实现个性化推荐;朱雨晗[5]建立长短期用户兴趣标签,运用最近邻获取动态兴趣进行推荐,但时期分配上只有长短两个时期,还不够充分;陈佳艳[6]提出同伴推荐方法,将个性化推荐思想融入在线学习平台的学习资源个性化推荐;Haifang Wang等[7]将用户各类数据深度融合,考虑数据间逻辑关系,提高了推荐准确性;Tian Qiu等[8]从用户活跃度方面入手构建用户兴趣模型;刘超慧等[9]构建用户—学术资源评价模型,应用基于资源的协同过滤算法完成推荐。通过资源模型构建可以更好地度量学术资源内容,是目前比较受欢迎的一种方式;Divyaa等[10]提出一种基于偏好相似度得分的社交网络子图的聚类细化算法,提升了推荐准确度;姜书浩等[11]依据用户历史偏好和项目类别专家评分采用后过滤技术生成多样化推荐列表;刘电霆、吴丽娜[12]在LDA主题模型基础上,综合社会网络结构、用户间信任关系和社会影响力,打破了推荐结果模式化;高元[13]基于Hadoop平台海量学术资源分词、TF*IDF相关参数提取以及分类模型训练,解决了传统单机模式处理海量文本数据时效率低的问题。在解决冷启动问题、寻找最优解方面,梁仕威等[14]结合表示学习模型与基于矩阵分解的协同过滤算法,解决了传统新闻推荐的冷启动问题;Lei Liu等[15]创建了一个混合教材学习平台,并将其应用于各阶段教学;翟域等[16]基于知识状态生成待学习知识点向量,设计迭代算法找到最佳匹配。本文以精准推荐为目标,结合已有算法,运用用户的历史行为数据,考虑到时间因素下用户兴趣转移的影响,创新性地提出运用用户行为数据按照多个时间顺序重新分配权重的算法,构建用户兴趣模型并与学术资源模型进行匹配,以提高推荐效果。
1 学术资源模型
当前,研究者多利用网络资源实现学习时间碎片化充分利用[17],而这些学术资源中研究论文的参考文献大多需要具备权威性。知网提供各种文献检索、阅读等服务,为我国学者广泛使用,而知网海量论文中的主题、关键词筛选功能无疑为人们搜索学习资源提供了便利[18]。论文中的摘要作为论文的精华部分,涵盖了研究领域、运用方法和结论展示,能够使学者快速把握文章主旨,节约时间和精力。爬取论文摘要进行分析不仅能够节省研究者的精力还能防止文章中的片面信息对提取文章主题造成负面影响。
精准推荐的重点在于准确把握用户需求[19],将其与资源特征进行匹配,从而完成推荐,其中资源特征提取和向量化显得尤为重要。资源特征提取不当不仅不能很好地表达学术资源本身的研究背景,难以运用算法和研究结论,还会造成匹配不当致使资源推送不当,呈现客户不满意度上升甚至客户流失等严重后果[20]。资源特征提取一般运用提取特征词分布的TF-IDF方法,该方法是利用词频计算每篇文档的特征词及其权重。
[TF-IDF=词频(TF)*逆向文件频率(log(1IDF))]
但是传统TF-IDF方法难以把握词语在文章中的顺序差异,无法准确表达不同主题下相同词语的不同含义。而LDA主题模型可以准确得到文章包含主题及每个主题下的关键词和权重,有利于解决上述问题,本文选取LDA算法完成学术资源的文本向量化。LDA算法是运用概率知识进行求解。
[p(w|d)=p(w|t)*p(t|d)]
其中,w代表词语,t代表主题,d代表文檔,则p(w|d)为文档d中词语w的分布概率,p(w|t)为主题t下词语w的分布概率,p(t|d)为文档d中主题t的分布概率。通过分词系统后统计词频,上式左侧可以较容易得到,进而通过矩阵分解得到右侧,这部分涉及较多数学知识,不再深入分析。通过Python编程代码可以较便利得到每篇文档的主题分布T和主题下的词分布W,则文档d可用关键词w与权重表达:
[W=(λ1w1,λ2w2,?,λ10w10)]
为达到文本向量化的目的,每篇文档选取主题数为1,主题下的关键词数量取前10,以便减少数据稀疏性。
2 用户兴趣模型与精准推荐
用户兴趣偏好度量是在资源模型基础上进行推荐的核心部分[21-22],一般从大量用户数据中选取用户行为数据表征用户偏好。准确把握用户偏好有利于增加推荐准确度,本文根据用户历史下载数据判断其偏好倾向,下载行为通常说明用户对该主题感兴趣。但是用户历史行为数据并没有考虑用户兴趣转移因素,随着时间的推移,用户的兴趣很可能发生变化,近期内的用户行为数据更能够表述用户的偏好倾向。因而本文在运用历史数据时考虑时间因素下用户偏好转移,在学术资源模型基础上构建用户兴趣模型时为不同时间段设置不同权重代替偏好倾向度,有:
[M=(u1M1,u2M2,?,unMn)]
其中,M代表用户偏好,[Mi(1in)]为用户历史数据向量,i为时间因素,权重系数有[1u1u2?un0],随着时间的接近其更能够影响偏好倾向,具体权重大小由实验比较得出,且[u1+u2+?+un=1]。
与此对应,排除用户行为时间因素,设置等权重用户兴趣模型作为对照组,有:
[M'=(uM1',uM2',?,uMn')]
其中,[u=1/n],即不考虑时间因素影响,认为用户历史行为数据有相同的权重系数。
在学术资源模型和用户兴趣模型基础上,可以进行每篇文档与用户兴趣向量的相似度计算。鉴于学术资源和兴趣模型的向量化数字表示已经完成,本次选用相似度算法为余弦相似。
[cos(W,M)=i=1N(Wi*Mi)i=1N(Wi2)*i=1N(Mi2)]
选取相似度较高的Top-N进行推荐。
3 实验分析
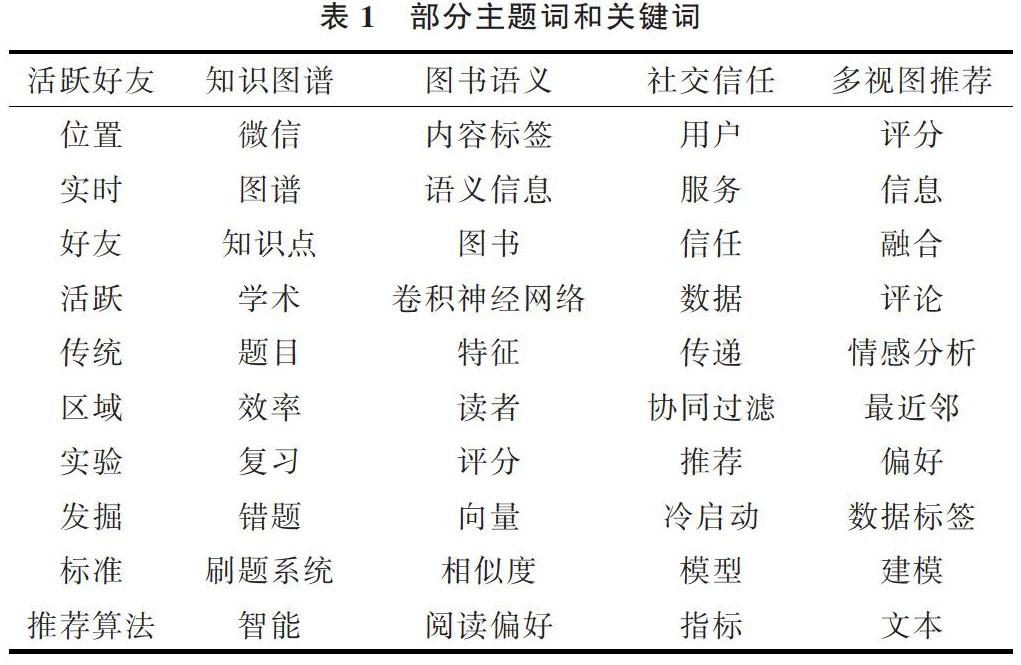
实验数据来源于中国知网,选取推荐系统领域的所有核心期刊论文共2 759篇,爬取论文题目、摘要信息构建学术资源模型。在LDA建模中选择主题—特征词的前十进行文本主题识别和向量化。运用Python代码进行运算,设置主题数为1,表征主题的关键词截取前十,得到部分主题—特征词分布如表1所示。
表1 部分主题词和关键词
在构建用户兴趣模型的系数选择上,选取不同取值进行实验,本次设置了系数范围分别为[u1∈(0,0.1),u2∈(u1,][0.2),u3∈(u2,0.3),u4∈(u3,0.4),u5∈(u4,0.5)]满足时间因素下系数递增,即权重分配不同,通过多次迭代选择推荐准确度较大的系数:[u1=0.048,u2=0.095,u3=0.143,u4=0.238,][u5=0.476],实验过程部分数据如表2所示。
表2 系数效果比较
系数确定后,用户兴趣模型就建立完成,进而计算学术资源模型中每一篇论文与用户兴趣模型的相似度,取相似度值较高的N篇论文进行推荐,在推荐后匹配用户数据,进而确定评价指标数值。
判断考虑时间因素下用户兴趣转移采用不同权重的算法与不考虑时间因素下用户兴趣转移平均算法的指标为准确率P、召回率R和调和平均值F,以期较准确地评价用户推荐效果。3个指标运算公式如下:
[P=推荐中用户喜欢的文献个数推荐的文献总个数]
[R=推荐中用户喜爱文献个数用户在学术库中喜爱的总个数]
[F=2*P*RP+R]
通过运算,得到实验结果如图1-图3所示。
图1 不同推荐个数下准确度比较(P值)
图2 不同推荐个数下召回率比较(R值)
图3 不同推荐个数下F值比较
实验结果显示,当推荐个数依次从5增加到15时,两种方法的准确度、召回率和F-measure值都依次上升。但是考虑时间因素下的用户兴趣转移算法在准确率和召回率上都要优于不考虑兴趣转移的平均权重算法,虽然初始时的F指标不是很高,但随着推荐个数的增加,本文提出算法的F值也很快超过对照组算法的取值。当推荐个数相同时,本文时间因素下用户历史行为不同权重的各项指标均优于平均权重算法,可见考虑用户兴趣转移因素使得推荐效果更佳。
4 结语
推荐系统利用用户以往网络痕迹数据,为用户提供主动式服务,节省用户的时间和精力,也进一步促进网络资源的智能化发展。本文基于用户历史行为数据,考虑到基于时间因素用户兴趣转移的影响,从而提出权重重新非均等分配算法。运用LDA提取文献主题、关键词及权重,达到文本向量化进而建立学术资源模型;运用用户历史行为数据,根据实验得出时间影响下的不同权重系数分配从而得出用户兴趣模型。采用余弦相似度算法计算两模型相似度进行推荐匹配,与不考虑时间因素下用户兴趣转移的均等权重用户兴趣模型算法相比,本文提出的算法无论在推荐准确率、召回率还是随着推荐个数增加的F值上效果均更佳。但本研究仍存在一定缺陷:运用LDA模型提取文献主题,在实验阶段选取了推荐领域专一主题数据,虽然能够反映文献背景、算法和结论的不同,但选用不同领域文献能够自动识别文章主题,推荐效果会更佳,也更符合人们日常搜索习惯;仅利用用户下载行为数据,而更大范围的用户点击、分享等行为数据的综合运用可以更好地度量用户兴趣,这也是下一步研究方向。
参考文献:
[1] 黄珊珊. 基于LDA的微博个性化新闻推荐方法研究[D]. 武汉:武汉邮电科学研究院,2019.
[2] 徐吉,李小波,许浩. 基于用户信任的协同推荐算法研究与分析[J]. 数据通信,2019(2):29-34.
[3] 林耀进,胡学钢,李慧宗. 基于用户群体影响的协同过滤推荐算法[J]. 情报学报,2013,32(3):299-305.
[4] 劉珊珊. 大数据中基于混合协同过滤的动态用户个性化推荐[J]. 软件工程,2019,22(3):16-19.
[5] 朱雨晗. 基于用户兴趣标签的混合推荐方法[J]. 电子制作,2018(22):42-44.
[6] 陈佳艳. 基于学习行为特征的学习资源个性化推荐研究[D]. 南京:南京邮电大学,2018.
[7] WANG H F,WANG Z J,HU S H,et al. DUSKG: a fine-grained knowledge graph for effective personalized service recommendation[J]. Future Generation Computer Systems,2019,100(11):600-617.
[8] QIU T, WAN C,WANG X F,et al. User interest dynamics on personalized recommendation[J]. Physica A: Statistical Mechanics and its Applications,2019,525.
[9] 刘超慧,李宇根,陶浩武,等. 基于用户-图书资源特征的图书资源推荐技术研究[J]. 电子世界,2019(8):86-87.
[10] DIVYAA L R,NARGIS P. Towards generating scalable personalized recommendations: integrating social trust, social bias, and geo-spatial clustering[J]. Decision Support Systems,2019,122:113066.
[11] 姜书浩,张立毅,张志鑫. 基于个性化的多样性优化推荐算法[J]. 天津大学学报:自然科学与工程技术版,2018,51(10):1042-1049.
[12] 刘电霆,吴丽娜. 社会网络中基于信任的LDA主题模型领域专家推荐[J]. 广西师范大学学报:自然科学版,2018,36(4):51-58.
[13] 高元. 面向个性化推荐的海量学术资源分类研究[D]. 宁波:宁波大学,2017.
[14] 梁仕威,张晨蕊,曹雷,等. 基于协同表示学习的个性化新闻推荐[J]. 中文信息学报,2018,32(11):72-78.
[15] LIU L,VERNICA R,HASSAN T,et al. Using text mining for personalization and recommendation for an enriched hybrid learning experience[J]. Computational Intelligence,2019,35(2):1-3.
[16] 翟域,徐朦,黄斌. 基于知识状态的个性化学习资源推荐方法[J]. 吉首大学学报:自然科学版,2019(3):23-27.
[17] 刘扬超. 大学生碎片化学习的现状调查研究[D]. 呼和浩特:内蒙古师范大学,2018.
[18] 涂佳琪,杨新涯,王彦力. 中国知网CNKI历史与发展研究[J/OL]. 图书馆论坛:1-12[2019-06-26]. http://kns.cnki.net/kcms/detail/44.1306.G2.20190619.0848.002.html.
[19] 丁梦晓,毕强,许鹏程,等. 基于用户兴趣度量的知识发现服务精准推荐[J]. 图书情报工作,2019,63(3):21-29.
[20] 刘伟,刘柏嵩,王洋洋. 海量学术资源个性化推荐综述[J]. 计算机工程与应用,2018,54(3):30-39.
[21] 王刚,郭雪梅. 融合用户行为分析和兴趣序列相似性的个性化推荐方法研究[J/OL]. 情报理论与实践:1-11[2019-06-26]. http://kns.cnki.net/kcms/detail/11.1762.G3.20190417.1553.006.html.
[22] 黄宏程,陆卫金,胡敏,等. 用户兴趣相似性度量的关系预测算法[J]. 计算机科学与探索,2017,11(7):1068-1079.
(责任编辑:孙 娟)
