基于属性分区的(αi,k)-p隐私保护算法
2019-10-15武绍欣

摘 要:针对(αi,k)—匿名算法使用有损链接思想无法对用户身份进行保护的问题,引入属性分区置换概念,提出基于属性分区的(αi,k)-p匿名算法,对桶中QI属性采取分区、置换的方式保护用户身份信息。在人口真实数据集21 956条数据上对两种算法进行敏感值保护和会员身份保护有效性对比实验。结果表明,敏感值泄露概率最高时只刚好超过0.05,接近传统方法的1/4;在会员身份保护方面,FOR值在0.7以上。相对于(αi,k)—匿名算法,该算法能更好地保护敏感值信息和会员身份信息。
关键词:隐私保护;数据发布;属性分区
DOI:10. 11907/rjdk. 191457 开放科学(资源服务)标识码(OSID):
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2019)008-0063-03
(αi,k)-p Privacy Preserving Algorithm Based on Attribute Partition
WU Shao-xin
(College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao 266590, China)
Abstract: The (αi,k)-anonymity algorithm proposed by Jinhua uses the idea of lossy links, and it can not provide the protection of user identity. In this paper, the idea of attribute partition replacement is introduced, and an (αi,k) - p anonymity algorithm based on attribute partition is proposed. QI attribute partition and replacement in bucket are adopted to protect user's identity information. This paper implements two algorithms for 21 956 data sets of real population, and compares the effectiveness of sensitive value protection and membership protection. The results show that the leakage probability of sensitive value is just over 0.05, which is close to 1/4 of the traditional method, and FOR value is above 0.7 in membership protection. Compared with (αi,k)-anonymous algorithm, the proposed algorithm can better protect sensitive value information and membership information.
Key Words: privacy protection; data publishing; attribute partition
作者簡介:武绍欣(1995-),男,山东科技大学计算机科学与工程学院硕士研究生,研究方向为网络安全、隐私保护。
0 引言
随着计算机技术的快速发展,数据交互越来越方便,大量数据被政府机构或企业收集[1-2],对此进行数据挖掘等研究,能帮助决策并创造商业价值,但也存在个人隐私泄露风险[3-5]。因此,隐私保护越来越受到重视。但对数据过分保护使挖掘的信息减少,因此隐私保护研究的重点是在数据可用性与隐私保护之间求得平衡。
现有的隐私保护技术大体分为数据失真、数据加密和限制发布3类[6]。数据失真技术主要通过添加噪声等方式使数据失真,从而达到保护数据隐私的目的;数据加密是通过加密算法实现数据的隐私保护;限制发布则是将数据中的隐私信息先进行泛化或匿名等操作后再发布,限制性地发布处理后的数据。
Sweeney等[7]通过对数据匿名化研究提出k—匿名模型,该模型对数据表中的准标识符属性进行约束,要求发布的数据表任意一条记录,在准标识符属性上都无法与其它 k-1 条记录区分,这样即使攻击者能够了解目标用户的所有QI信息,也无法确切知道用户的敏感信息。
为克服 k—匿名模型难以抵御同质性攻击的缺陷,Machanavajjhala A等[8]提出了l—多样性匿名方法,要求在同一等价类中都有l个表现良好的敏感值,解决了某些情况下由于敏感属性取值单一导致的隐私泄漏问题。但是该模型下的数据集会有遭受到偏斜攻击和相似性攻击的可能。
Li等[9]提出t—接近模型,它要求每个等价类中所有敏感值的分布要与原始数据表中敏感值的分布接近,差异不要超过预先设定的阈值,但是没有给出具体算法,且由于较为严格的限制致使该模型难以实现。
随后,Wong等[10]提出了(α,k)—匿名模型。(α,k)—匿名模型要求匿名数据集在等价组上满足k值约束条件下,任意敏感属性值在等价组中出现的概率都小于等于α值约束,即0≤α≤1。
解剖[11]与泛化和抑制不同,该方法在两个单独的表中给出关于QI和SA上的数据:包含QI属性的QIT、包含SA的ST以及QIT和ST都具有一个共同属性,即组ID。解剖学的最大好处是QIT和ST都没有数据修改。
这些方案可以应对一些攻击类型,如背景知识攻击[12]和合成攻击[13]等,但依然有别的攻击方式不能抵御,如相似性攻击和敏感性攻击。
在上面模型基础上,姜火文[14]提出基于贪心的聚类算法,减小了信息损失,但不能应对敏感性攻击。张健沛[15]提出基于敏感值语义桶分组的隐私保护模型;曹敏姿[16]提出个性化(α,l)-多样性k-匿名模型,可以应对敏感性攻击,但却改变了一些元组的敏感值;毛庆阳[17]提出基于聚类的S-KACA算法,能够提供敏感性保护,但存在很多等价类没有最小化,增加了信息损失;刘湘雯[18]提出了个性化扩展(α,k)匿名模型,根据敏感度将敏感属性值分为若干组,每组都有自己的频率约束阈值,为每个人设置一个保护节点,必要时替换敏感值,但该模型同样改变了一些元组的敏感值。
金华[19]提出(αi,k)—匿名模型,预先设置每个敏感值的敏感级别,然后在一个桶中限制所有级别敏感值的频率从而实现对隐私的保护。一个等价类中,任意一条元组的敏感值比例不高于α,且任意级别的敏感值占比均不超过阈值αi,则称该等价类满足(αi,k)—匿名,但它无法提供会员身份保护。
为改善(αi,k)-匿名模型缺点,本文提出一种基于属性分区的(αi,k)-p匿名算法,在选取元组构成等价类之前先对元组中的QI信息进行分区,在构成等价类后再置换QI组。该算法在会员身份保护和敏感值保护方面均有很大优势,可应对敏感性攻击。
1 基于属性分区的(αi,k)-p算法
(αi,k)-anonymity模型无法对身份信息进行保护,因此算法需对属性进行分区,使高度相关的属性位于同一列中,这有利于实用性和隐私性。在数据实用性方面,将高度相关的属性分组以保留这些属性之间的相关性。在隐私方面,不相关属性的关联比高度相关属性的关联具有更高的识别风险,因为不相关属性值的关联频率要低得多,更容易识别。为保护隐私,就要打破不相关属性之间的关联,具体算法如下:
算法
输入:原始数据表T,参数k,敏感性分级(L1,L2,…,Li,…),频率约束(α1,α2,…,αi,…)
输出:置换匿名表Tanony
步骤如下:
使用均方偶然系数计算出QI属性中的相关度;
使用PAM聚类算法对列属性进行聚类;
将T中每个元组的的QI值按照列聚类的结果使用集合代替;
[j=max(1α,k),θi=j?αi,i=1,2,?];
while 剩余元组可以构造元组桶;
E=Φ;
while 元组桶E不满足(αi,k)匿名;
在所有级别的 Li中按照级别从高到低的顺序一次选取敏感属性为个数最多的元组加入元组桶E,在T中取出该元组,且在下一次选择当前敏感级时跳过该敏感值的元组;
检查在每一级别挑选的个体个数是否小于对应的θi,如果不小于θi,则下一次选取个体时跳过该敏感级。如果当前敏感级除去选择的SA为空,则下次选择SA时跳过该敏感级;
end while;
将E中每一列随机置换;
将E添加到Tanony,并标注classID;
end while;
对于剩余的元组,添加到某个元组桶中,该元组桶仍然满足(αi,k)匿名,则將该元组添加到该等价类中。
隐匿所有的无法添加到等价类的元组;
输出匿名表Tanony。
给定两个属性A1、A2,其中值域分别为{V11,V12,…,V1d1}、{V21,V22,…,V2d2},其对应的值域大小分别是d1、d2。A1、A2之间的均方偶然系数计算方法如公式(1)所示。
[φ2(A1,A2)=1min(d1,d2)-1i=1d1j=1d2(fij-fi?f?j)2fi?f?j] (1)
其中[fi?]、[f?j]分别是数据表中V1i、V2j,[fij]表示数据表中
2 实现方法
硬件环境:Intel(R) Core(TM)i5-3230M CPU@2.6GHz,内存4G,操作系统Win7 x64旗舰版;软件环境:使用python编程语言实现,IDE开发工具为Pycharm。
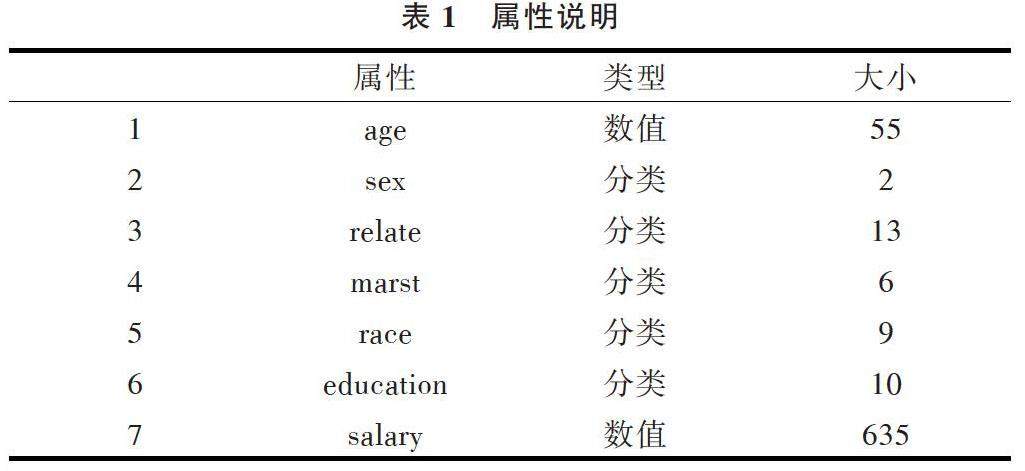
本文使用真实的美国人口普查数据作为实验数据[20],去除其中的无效数据,随机挑选21 956条数据。其中,age、sex、relate、marst、race、education作为QI属性,salary作为敏感属性,详细信息如表1所示。
表1 属性说明
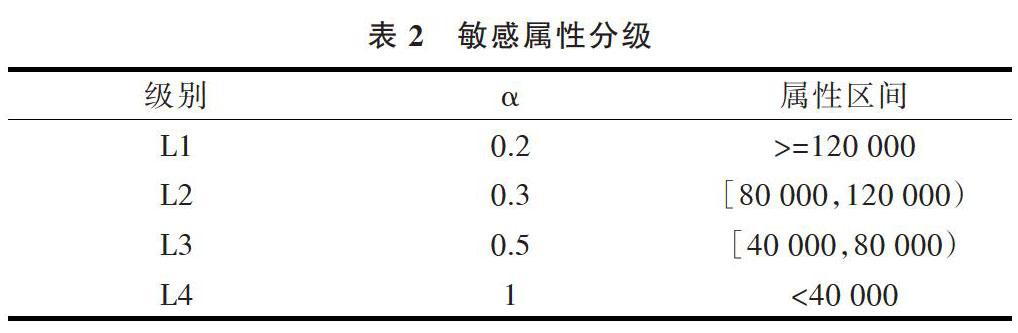
对数据集中敏感属性salary的属性值采用如表2所示的分级,并设置在同一合并桶中每一级别敏感属性出现的频率。
表2 敏感属性分级
2.1 敏感值泄露概率
假定攻击者已经了解所有用户的QI信息,并且知道用户在这种匿名表上,攻击者通过将QI值匹配该匿名表获得敏感信息。下面通过敏感值泄露概率[21]验证算法对敏感值的保护能力。
选择任意一个元组t,计算t的匹配个体数量Numtuples(t),匹配桶MB中t的匹配个体数量,记作Num(t,MB),以及t的敏感值s在MB中出现的次数Num(t,MB),[MB]表示MB中包含个体的数量,计算公式如下:
[p(t,s)=MBNum(t,MB)?Num(s,MB)Numtuples(t)?MB] (2)
2.2 伪元组比率
使用伪元组比率[22]验证两个算法对会员披露的保护,定义为伪元组的数量除以总元组的数量。FOR越大,提供的会员披露保护越多。计算公式如下:
[FOR=tuplefaketupleall] (3)
假定每个桶有k个元组,被分为c列,每列有k个不同的值,那么伪元组个数为kc-k个,FOR=1-1/kc-1。
3 实验结果
采用(αi,k)-pGCA算法和(αi,k)-GCA算法[19]对数据集进行匿名分析。取k为固定值5,c值为2,随着α值的变化,对比两种算法结果。首先对比两个算法的敏感值泄露概率,结果如图1所示。
图1 敏感值泄露概率
因为(αi,k)-GCA算法完全没有对元组的QI值提供保护,所以所有的元组几乎能百分之百匹配到所在的元组桶,因此该算法对敏感值的保护取决于元组桶大小。而(αi,k)-pGCA算法对QI值分区,并对每一个元组桶内的QI值置换,所以对每一个元组都能匹配到多个元组桶,因此敏感值泄露概率远低于(αi,k)-GCA算法。在敏感值保护方面,(αi,k)-pGCA算法更好。
每次实验值选取1 000个元组桶,计算FOR的平均值,对比结果如图2所示。
图2 伪元组比率
因为(αi,k)-GCA算法对QI值做匿名操作,所以在一个元组桶中不会产生任何伪元组,因此FOR都为0。(αi,k)-pGCA算法的元组桶中产生更多的元组,伪元组比率随着元组桶的增大而增大,在α取到1/15及更小时,元组桶中伪元组的比重已经占到绝大多数,能更好地应对会员身份披露。
4 结语
为解决现有(αi,k)-GCA算法无法保护身份和无法应对会员身份披露的问题,本文提出一种新的(αi,k)-pGCA算法。通过对原始数据集元组的QI信息进行分区置换,可以更好地保护隐私信息。可以看到,在分区置换后,敏感值泄露概率远远超过需求。未来将通过优化算法进一步研究如何最小化元组桶大小,使其既符合隐私保护需求,又能减少后续数据分析误差。
参考文献:
[1] 冯登国,张敏,李昊. 大数据安全与隐私保护[J]. 计算机学报, 2014, 37(1):246-258.
[2] 闫蒲. 互联网社交大数据下行为研究的机遇与挑战[J]. 中国统计,2016(3):15-17.
[3] 王博. 大数据发展背景下网络安全与隐私保护研究[J]. 软件导刊,2016, 15(8):171-172.
[4] 刘雅辉,张铁赢,靳小龙,等. 大数据时代的个人隐私保护[J]. 计算机研究与发展,2015,52(1):229-247.
[5] 孟小峰,张啸剑. 大数据隐私管理[J]. 计算机研究与发展, 2015, 52(2):265-281.
[6] JIA J J,YAN G L,XING L C. Personalized sensitive attribute anonymity based on p-sensitive k anonymity[C]. International Conference on Intelligent Information Processing. ACM, 2016: 54.
[7] SWEENEY L. K-anonymity: a model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570.
[8] MACHANAVAJJHALA A,GEHRKE J,KIFER D, et al. L-diversity: privacy beyond k-anonymity[C]. Atlanta:Proceedings of the 22nd International Conference on Data Engineering,2006: 24-24.
[9] LI N,LI T,VENKATASUBRAMANIAN S. t-Closeness: privacy beyond k-anonymity and l-diversity[C]. 2007 IEEE 23rd International Conference on Data Engineering. IEEE Computer Society, 2007.
[10] WONG R C, LI J, FU A W, et al. (α,k)-Anonymity: an enhanced k-anonymity model for privacy preserving data publishing[C]. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2006:754-759.
[11] XIAO X ,TAO Y.Anatomy: simple and effective privacy preservation[C]. Proceedings of the 32nd International Conference on Very Large Data Bases, 2006,139-150.
[12] 谷汪峰,饶若楠. 一种基于K-anonymity模型的數据隐私保护算法[J]. 计算机应用与软件,2008(8):65-67.
[13] 焦佳. 社会网络数据中一种基于K-degree-l-diversity匿名的个性化隐私保护方法[J]. 现代计算机:专业版,2016(29):45-47,60.
[14] 姜火文,曾国荪,马海英. 面向表数据发布隐私保护的贪心聚类匿名方法[J]. 软件学报, 2017,28(2):341-351.
[15] 张健沛,谢静,杨静,等. 基于敏感属性值语义桶分组的T-closeness隐私模型[J]. 计算机研究与发展,2014,51(1):126-137.
[16] 曹敏姿. 微数据发布中的个性化隐私保护方法研究[D]. 乌鲁木齐:新疆大学, 2018.
[17] 毛庆阳,胡燕. 基于聚类的S-KACA匿名隐私保护算法[J]. 武汉大学学报:工学版, 2018,51(3):276-282.
[18] LIU X W,XIE Q Q,WANG L M. Personalized extended (α, k)-anonymity model for privacy preserving data publishing[J]. Concurrency & Computation Practice & Experience, 2016,33(2):55-67.
[19] 金华,张志祥,刘善成,等. 基于敏感性分级的(αi,k)-匿名隐私保护[J]. 计算机工程,2011,37(14):12-17.
[20] DOCIN[EB/OL]. https://usa.ipums.org/usa/index.shtml
[21] LI T,LI N,JIAN Z,et al. Slicing: a new approach for privacy preserving data publishing[J]. IEEE Transactions on Knowledge & Data Engineering,2012, 24(3):561-574.
[22] LI B,LIU Y,XU H,et al. Cross-bucket generalization for information and privacy preservation[J]. IEEE Transactions on Knowledge & Data Engineering,2017,30(3):449-459.
(責任编辑:杜能钢)
