基于改进型协同过滤算法的研究
2019-10-11徐志超单剑锋
徐志超,单剑锋
(南京邮电大学 电子与光学工程、微电子学院,江苏 南京 210046)
0 引 言
互联网社会中,人在社会生产生活中产生了源源不断的历史数据。文献[1]中较为全面地论述了推荐算法在电子商务中的应用,并且分析了推荐策略,同时指出了当前策略的优缺点和未来的研究方向。如何从大量的、复杂、冗余的历史数据中挖掘出有价值的数据,分析这些数据的规律,对人的生产和生活做一些预测和相应的建议,这有利于生产力的提高和为人们提供更好的服务。相比于传统的软件工程,大数据、人工智能越来越被大众所熟悉[2]。大数据的应用场景在生活中比比皆是,天猫、淘宝等购物网站通过消费者的历史消费数据对用户进行商品个性化推荐;学校图书馆中,根据不同读者的借书数据和读者的角色进行个性化推荐;淘淘网根据用户的影评和用户的历史观看数据对用户进行推荐;内容搜索行业的今日头条能够根据用户的历史阅览轨迹实时推荐用户感兴趣的内容,这大大提升了头条的用户流量。
目前,主流的推荐算法主要有三种,第一种是基于协同过滤的推荐算法,主要包括基于内存和基于模型两种。基于内存有包括基于用户或商品;基于模型主要利用统计学、机器学习、数据挖掘来研究[3]。文献[4]提出的基于协同过滤算法的高校图书馆推荐系统,主要利用专业、角色、学历等多维特征构建读者模型,结合基于商品评分的系统过滤算法,相比于单一的基于商品评分协同推荐算法,该算法的有效性、实用性大大提高。第二种是基于内容的推荐算法,主要包括基于TF-IDF文本的推荐算法和基于潜在语义分析的推荐算法,但它们都只能基于历史的文本信息进行挖掘。文献[5]针对特征高维问题,提出一种基于中心词扩展的TF-IDF特征提取算法,增加了特征节点的表达能力,实现了特征降维。第三种是基于图结构的推荐算法,文献[6]提出了一种基于随机森林修正的加权二部图推荐算法。算法经过改进和融合后,提高了推荐的准确度,解决了基于二部图网络结构的算法中仅考虑用户与商品之间关系、忽略兴趣偏好影响的问题,从而增强了推荐的可解释性。另外,协同过滤算法也可以和其他经典算法相结合,文献[7]很好地将遗传算法与协同过滤算法进行有效结合。
在计算仿真平台和工具的选择上,以MapReduce为主的Hadoop体系和基于内存计算的Spark体系在计算上变得越来越重要。
针对传统的单机集中式计算已无法满足推荐系统的实时性和扩展性要求的问题,基于主流的大数据平台Spark在迭代计算以及内存计算方面的优势,设计了基于项目的协同过滤算法在Spark上的并行化方案[8-9]。文献[10-11]都提出了基于Hadoop的协同过滤算法,成功提高了算法的运行速度,扩大了算法输入数据的规模。由此可见计算工具的提升,有助于算法性能的提升。
1 协同过滤算法
协同过滤算法主要是将与目标用户具有相似特征的用户的商品推荐给目标用户[12];或者根据目标用户历史消费的商品,推荐相类似的商品。前者属于基于用户的推荐算法,后者属于基于商品的推荐算法。协同过滤算法大致思路见图1。
1.1 协同过滤算法的相似度
相似度的计算方法主要有两种:皮尔森相似度计算和余弦相似度计算。
皮尔森相似度[13]计算公式如下:
(1)
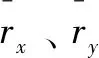
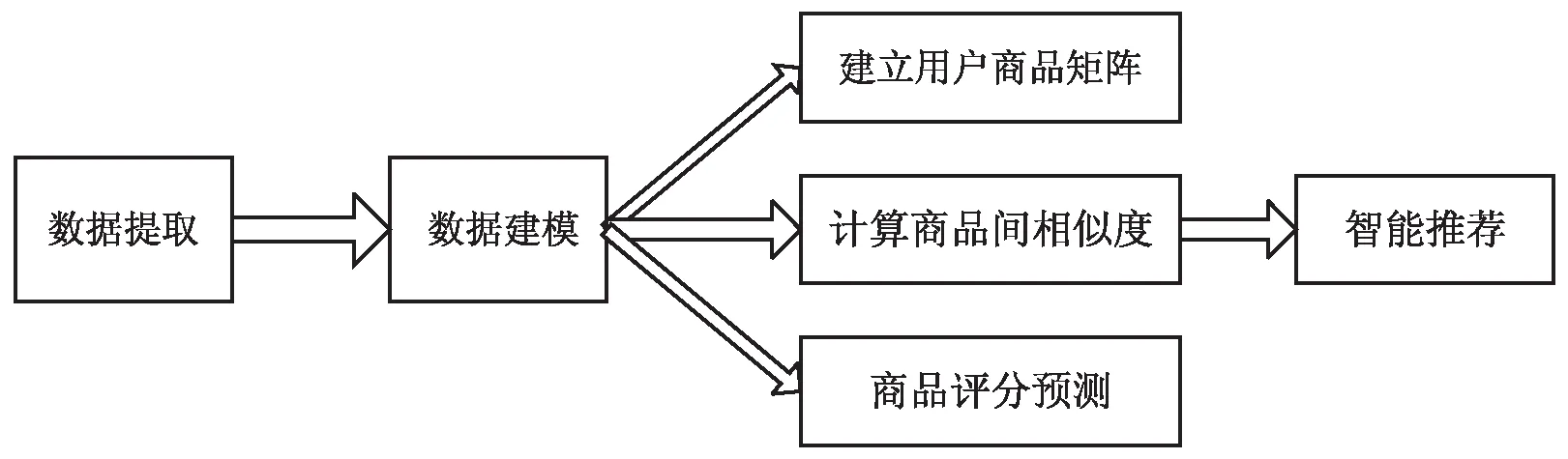
图1 视频网站电影智能推荐流程
余弦相似度[13]计算公式如下:
(2)
相比于余弦相似度计算公式,皮尔森相似度计算公式考虑了不同用户评分平均分不同的情况。
1.2 评分估计方法
设U={u1,u2,…,un}为用户集合,V={v1,v2,…,vm}为商品集合,ruv表示用户u对商品v的评分估计。常见的评分估计方法[13]如下:
(3)
(4)
(5)
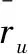
1.3 基于用户的内存推荐算法
基于用户的内存推荐算法主要先计算用户的相似度,然后根据相应的算法求出目标用户对目标商品的估计评分。表1中的数据来自某电商网站的用户评价商品的部分数据。表中U表示用户,V表示商品,评分范围为1至10。表中“-”表示未评价,“?”表示待评价。

表1 不同用户对已购商品的评分
基于用户的协同过滤算法,可以计算出目标用户Ui对商品Vj的评分结果Rij。以表1中的数据为例,可以计算评估用户U5对商品V2的评分。具体步骤如下:第一,分别计算U5和Ui(i=1,2,3,4)的相似复杂度;第二,根据除目标用户以外的其他用户对目标商品的评分和相似度,计算目标用户U5对目标商品V2的相似度r5,2。文中使用余弦计算用户之间的复杂度,U5和Ui(i=1,2,3,4)的相似复杂度如下:

0.993
(6)
sim(U5,U2)=0.974
(7)
sim(U5,U3)=0.947
(8)
sim(U5,U4)=0.914
(9)
r52=[sim(U5,U1)r12+sim(U5,U2)r22+sim(U5,U3)r32+sim(U5,U4)r42]/[sim(U5,U1)+sim(U5,U2)+sim(U5,U3)+
sim(U5,U4)]=8.43
(10)
2 推荐系统评价准则
在协同过滤算法中,不论是采用基于哪一种推荐算法用于用户估计商品的评分,或者是用于对用户推荐一个商品的列表,都需要对估计的评分和推荐的列表进行评价,检验实际评分值和估计评分值之间的误差。误差越小,说明评分估计越准确,则实际推荐商品越准确。文献[14]对现有的推荐系统评价指标进行了系统回顾,总结了推荐系统评价指标的最新研究进展,从准确度、多样性、新颖性及覆盖率等方面进行多角度阐述,并对各自的优缺点以及适用环境进行了深入分析。特别讨论了基于排序加权的指标,强调了推荐列表中商品排序对推荐评价的影响。一般地,对于用户对商品评分结果的检验可用平均绝对误差(MAE)或均方根误差(RMSE)评估评分的误差程度。
2.1 平均绝对误差
MAE[14]用于度量用户估计评分和真实值之间的误差,其表达式为:
(11)
2.2 均方根误差
表达式为:
(12)
其中,U和I分别为用户集合和商品集合;pij为真实值;rij为估计评分值。
3 改进型的基于用户推荐算法
传统的基于用户推荐算法中,只是根据用户对商品的评分来估计对其他商品的评分以及将评分高的商品推荐给用户,单一的评分尺度往往无法挖掘用户深层次的需求。同时考虑到用户因生活背景、消费习惯等各种因素的不同,带来评分差异的不同。在有些情况下,由于这种评分差异巨大使得在使用余弦相似度计算用户间的相似度时,出现了极大的偏差[15]。例如用户U1、U2、U3对4种样品进行评分,见表2。
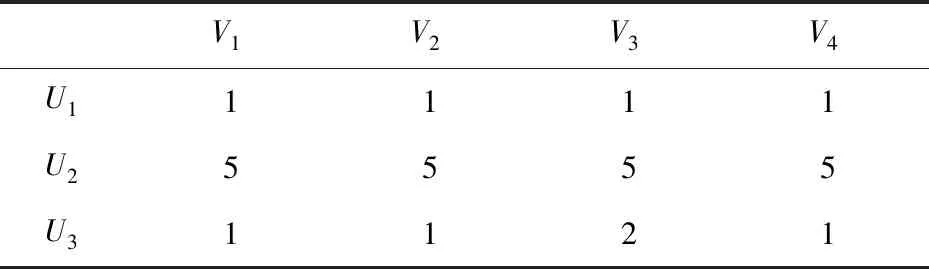
表2 不同用户对于不同商品的差异评分
根据计算可知,用户U1和用户U2的相似度为1,明显大于U1和U3的相似度。出现这种相似度计算结果偏差极大的原因,一方面是不同用户自身的评价差异性大;另一方面是余弦相似度只是根据不同用户的共同评分商品计算的,没有考虑到所选商品对不同用户的影响,也就是说,所选参与计算复杂度的商品有可能偏向用户U2,U1和U3虽然参与评分,但不一定真正感兴趣。另外也有可能用户U1和U3相对于用户U2来说,更加理性,评分更加严格,也就是说不同用户的评分体系有可能不一致。
根据这种情况,从相似度本身出发,提出一种融合型的相似度计算公式,它由两部分组成。
3.1 余弦相似度修正型参数α
余弦相似度修正型参数α主要是针对用户的评价体系不同而造成相似度计算偏差大的问题。其修正后的相似度表达式为:
(13)
(14)
其中,s为用户u、v的共同评价商品的集合;|S|为用户u、v的共同评价商品数。该修正型参数α与不同用户对相同商品评分的差异性呈负相关,当用户评分差异性大时,α值偏小;反之,α值偏大。
3.2 用户特征属性向量
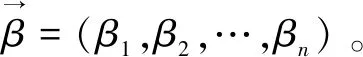
改进后的余弦相似度表达式为:
(15)
其中,T为特征属性的集合。
根据上述提出的两种改进型余弦相似度计算方法,提出一种融合型的余弦相似度计算方法,即:
sim(x,y)=γ*simα(x,y)+(1-γ)simβ(x,y)
(16)
其中,γ是一种平衡参数,可以看作是一种权重因子,取值为[0,1]。
4 实验仿真
在TipDM-HB平台进行视频网站的电影推荐建模仿真步骤如下:
(1)导入经过简单预处理的csv数据,部分数据见表3;
(2)构建用户-商品矩阵,分别根据余弦相似度公式和融合型的余弦相似度公式计算商品相似度;
(3)根据用户相似度和用户-商品矩阵,使用式4估算测试用户对不同商品的评分(步骤2和步骤2被封装成协同过滤算法建模平台系统组件)以及将评分高的电影推荐给用户;
(4)部分评分和推荐结果见表4,分析电影推荐结果。
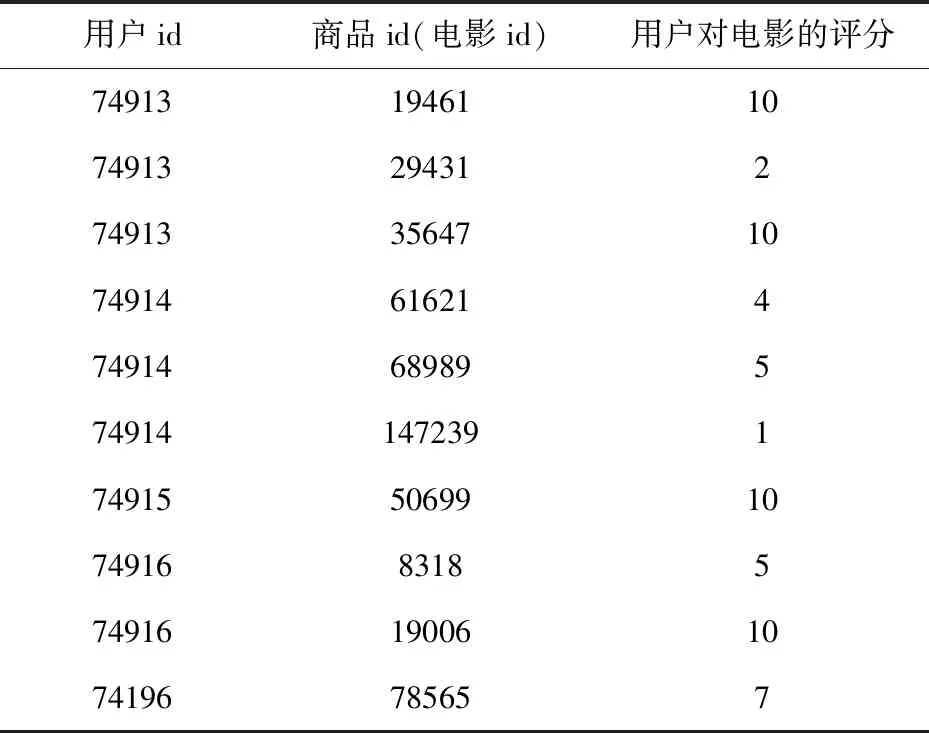
表3 导入的部分用户电影评价数据
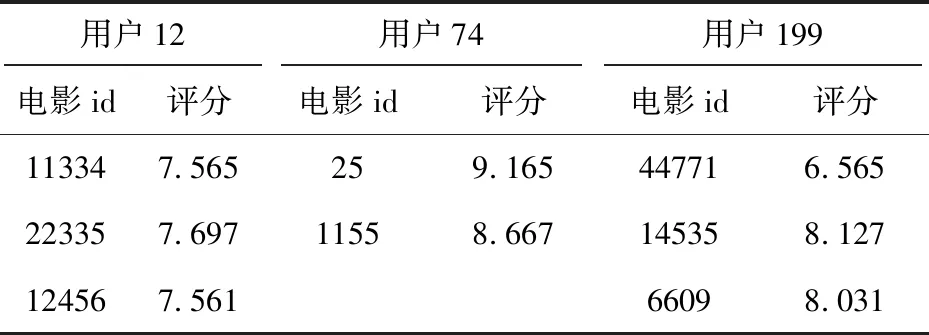
表4 控制台输出的对部分用户推荐结果
根据表4的推荐结果分析,用户12、用户74和用户199所推荐电影的评分都高于7分,这样的推荐结果是有意义的,会产生较好的用户体验。改进型的基于用户协同过滤算法有效解决了由于新项目冷启动导致的用户推荐不准确问题,提高了推荐的精准度,进而影响平台的受欢迎程度。
由MAE误差曲线(见图2)可知,对比传统的基于用户的协同过滤算法和改进型的基于用户的协同过滤算法的平均绝对误差,在相同的用户邻居个数的条件下,改进型的协同过滤算法的MAE明显小于传统的基于用户的协同过滤算法的MAE。
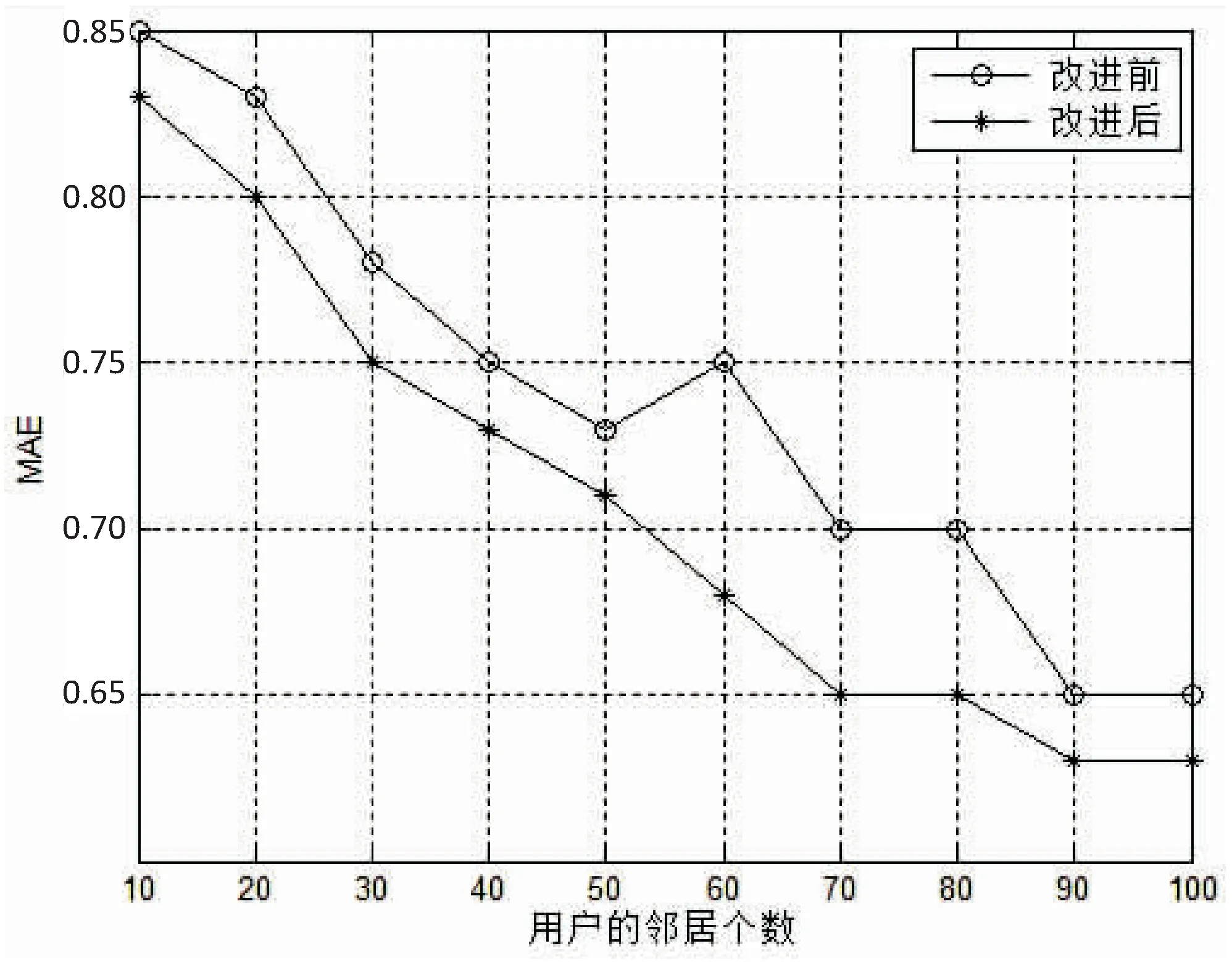
图2 改进前和改进后的MAE误差曲线
5 结束语
由于传统的余弦复杂度计算公式只是从商品评分本身出发,没有考虑到用户的评价体系不同和用户自身的特征属性对商品评分的影响,因此在计算用户相似度时出现了极大的偏差。文中提出了一种改进型的协同过滤算法。第一,提出了一个余弦相似度修正参数α,通过该参数修正后,在计算评分差异大的用户之间相似度时,能够有比较好的修正作用;第二,提出了用户特征属性向量,该向量能够考虑到用户自身的特征属性,避免在计算相似度时出现较大偏差。通过上述的融合性相似度计算公式,能够解决相似度计算偏大过大的问题。
根据TipDM-HB平台的仿真数据来看,算法能够根据历史的电影评分估计出某用户未评分电影的得分,同时推送给用户评分比较高的电影。根据实验的推荐结果和MAE曲线可知,改进型的协同过滤算法的推荐性能有了一定的提升。
尽管该算法改善了传统的基于用户的协同过滤算法中出现的余弦相似度计算偏差的问题,但是也存在以下问题:第一,引入的用户特征向量带来了一定的计算复杂度;第二,修正参数α和用户特征向量能否进行扩展,用于改善皮尔森相似度计算方法。另外,根据对待计算数据的观察,发现有些数据预处理不到位,简单的预处理只是将数据格式进行调整,并没有对有些缺乏主要字段的数据进行舍弃。同时考虑到数据的复杂度,可以将数据分为合理评分记录和不合理评分记录,前者使用传统的相似度进行计算,后者使用改进型的相似度进行计算,以有效提升数据复杂度。因此,该算法有待进一步完善。
