基于粒子群-遗传混合算法的函数优化研究
2019-10-11刘文英张自鲁路慎强张晓燕
刘文英,张自鲁,路慎强,张晓燕
(1.中国石油大学(华东) 计算机与通信工程学院,山东 青岛 266580;2.中国石化胜利油田分公司物探研究院,山东 东营 257000)
0 引 言
优化问题存在于日常生活中的很多领域,如时间序列预测[1]、金融经济、生产调度、模式识别、人工智能、计算机工程等,其中函数优化尤为重要,因此研究函数优化方法具有很大的价值。
遗传算法是受达尔文进化论的影响提出的一种群智能优化算法,模仿生物界的优胜劣汰机制,在进化过程中,通过评估染色体的适应度来不断淘汰较差的个体。基本操作为:选择,交叉,变异。遗传算法因其搜索简单、鲁棒性强等优点广泛应用于优化问题中,但是在解决复杂优化问题时又存在陷入局部最优、收敛速度慢等不足。对此。文献[2]提出一种动态交叉和动态变异策略操作,在保持种群多样性的同时避免种群过早收敛,并将该方法应用在物流路径的优化中;文献[3]提出一种自适应改进的遗传算法,该算法根据进化中的种群适应度非线性地自适应调节交叉概率以及变异概率,使种群摆脱局部极值搜索到全局最优解。
粒子群算法最初是由Kennedy和Eberhart等根据自然界鸟群觅食行为特点,模拟鸟群的行为特点提出的,是一种基于迭代的方法。每只鸟都被看作是一个粒子,每个粒子具有自己的位置和速度。粒子根据同伴的速度和位置调节本身,群体保存所有粒子中适应值最优的作为全局最优,通过在个体最优和全局最优的指导下飞行,期望粒子收敛到最优解。文献[4]提出采用动态惯性权重因子,并引入差分进化算法使算法拥有变异与交叉操作,算法在进化后期也保持较高的收敛精度,并成功地应用在神经网络的优化中;文献[5]提出了一种以自适应权重粒子群算法为基础,并引入遗传交叉算子的混合优化算法,用来优化SVM参数的遥感图像,能够寻找到更佳的SVM分类器参数,获得更高的分类精度。
在遗传算法中,进行变异操作的是种群中的少数个体,并且变异操作不把种群的当前状态和历史状态考虑在内,而粒子群算法能记录种群的历史状态和当前状态。针对以上问题,提出了一种新的遗传-粒子群混合算法,该算法将粒子群算法与遗传算法相结合[6-7],用速度算子替代变异算子。通过实验验证,该方法在保持种群多样性的同时具有较快的收敛速度。
1 粒子群-遗传混合算法
1.1 种群划分策略
文中借鉴小生境的思想对初始种群进行划分[8],用“产优率”来动态调整各个子种群的进化状态以避免进化孤岛的形成,使种群快速收敛的同时保证多样性。文献[9]中提出了基于个体编码的均匀分割策略,该方法可以将种群划分成若干个既不重叠又都能反映解空间整体性质的子空间。文中将借鉴文献[9]提到的种群划分策略。具体操作为:定义算法种群初始数S,依据文献[9]中均匀分割的理论,若定义种群S的阶为s,那么种群S将可以划分成2s个子种群,每个子种群内个体的右边s位编码是完全相同的。假设对某种群P,定义它的阶为2,就可以将P划分成4个子种群:P1,P2,P3,P4,那么各个子种群的最右边的编码串分别为:00,01,10,11,则编码串基本形式分别为:#00,#01,#10,#11,其中#代表任意长度的二进制编码串,具体如图1和图2所示[10-11]。

图1 种群阶为2
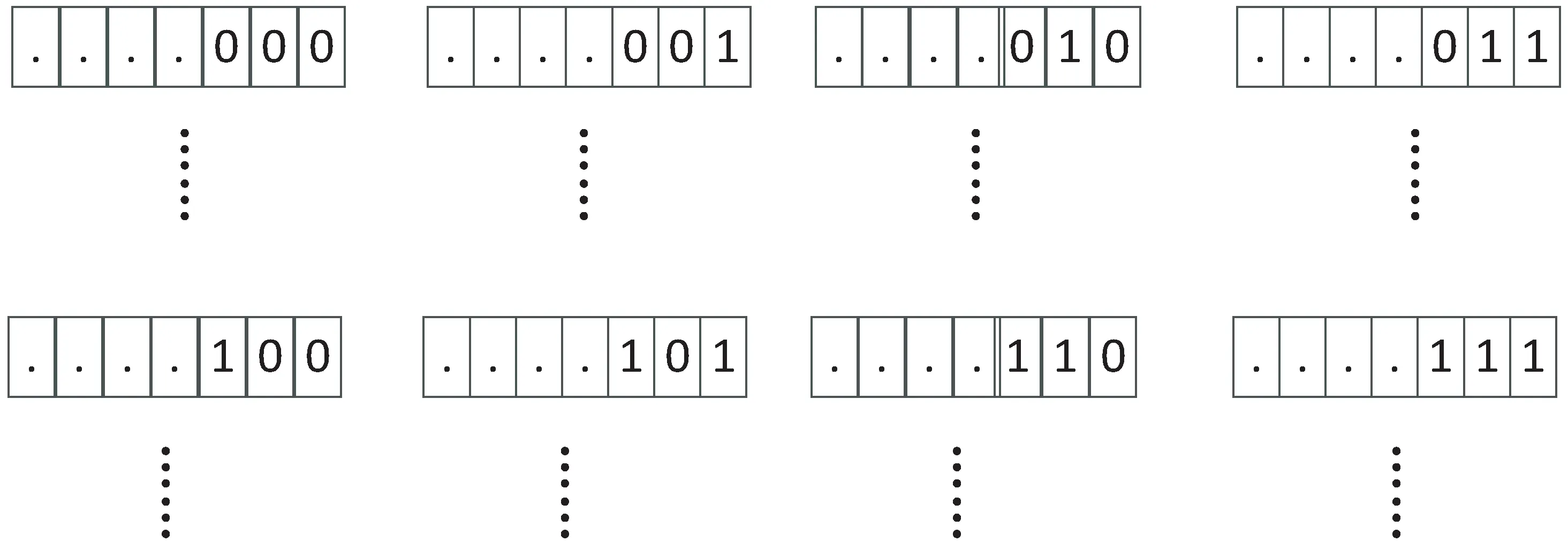
图2 种群阶为3
1.2 个体评价策略
传统的遗传算法主要是通过评价适应度函数来评价个体的好坏,适应度函数的选取跟目标函数有很大的关系。在算法运行的初始阶段,群体内存在少量适应值极高的个体A(i),若采用常规的选择方法,使这些个体大量繁殖,在群体中占有很大的比重,而一些适应值不错(比A(i)适应值低)的个体过早被淘汰,可能造成群体的多样性下降,从而可能导致算法过早收敛,即早熟收敛。文中设计一种个体评价策略,用于防止非最优个体过早淘汰,适应度函数表示为:
F(xi)=f(x)+f(xi)/N(i)
(1)
其中,f(x)为目标函数本身;f(xi)/N(i)为个体i目标函数本身与该个体被选择次数的比值;N(i)表示该子个体被选择的次数。如果一个最优个体被选择过多次,在之后的迭代中适当增加非最优个体被选择的几率,降低该个体被选择的几率,保证种群的多样性不会减少。
1.3 交叉操作
交叉操作是对父代个体进行基因交换重组,用于产生大量新的个体,从而可能产生更优的个体。文中通过判断相似度大小,设计一种新的交叉操作[12],对不同子个体采用不同的交叉操作。设进行交叉的两个父代个体为Xi和Xj,计算其相似度。对任意优化问题使用二进制编码[13-14],编码空间为{0,1},个体Xi与个体Xj之间的相似度表示如下:
(2)
其中,n表示二进制编码的长度;sm(i,j)表示在m位上的个体i,j值是否相同。假定i,j个体在m位上的值相同,则sm(i,j)为1;否则为0。如果i,j个体有很多位相同,不难算出,相应的S(i,j)也会比较大。
当i,j个体相似度S(i,j)大于预先设定的相似度阈值su时,说明i,j个体在很大程度上相似。这时采用普通的交叉操作有可能没有很大的效果,产生新个体的几率比较小,所以采用将个体i前k(k∈rand(1,n))位与个体j的后k位进行交叉的方法,如图3所示。
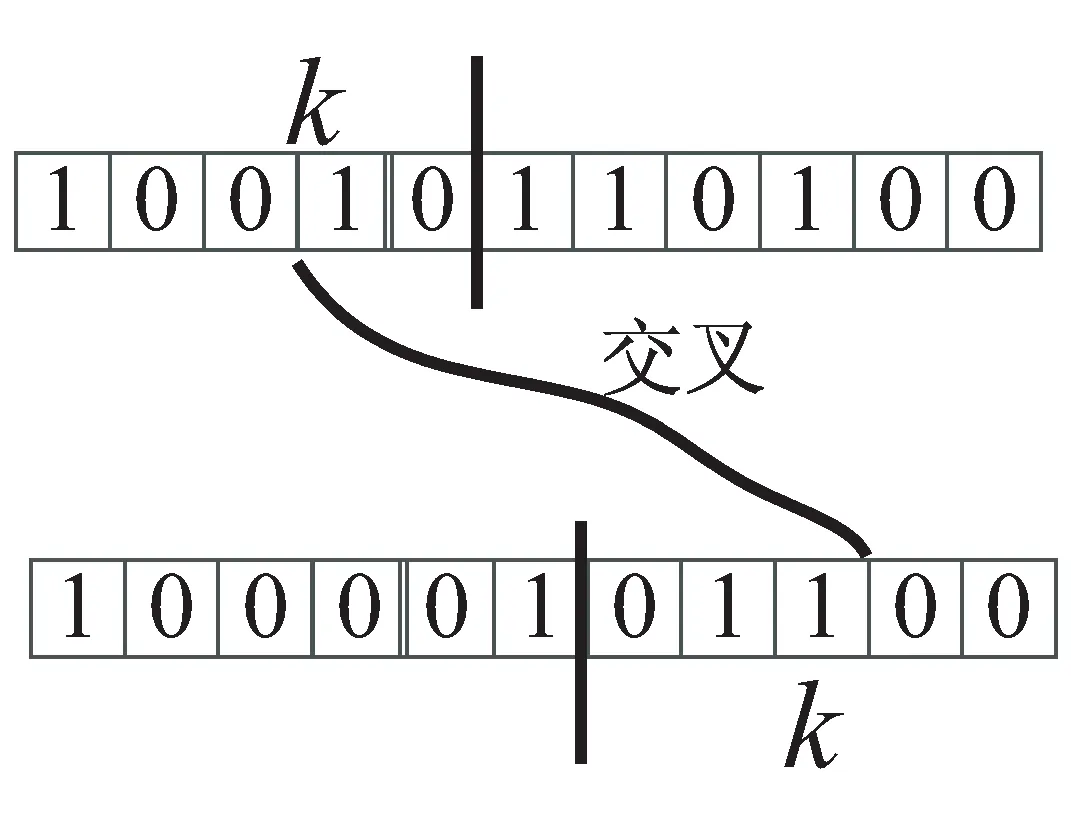
图3 交叉操作
当i,j个体相似度S(i,j)小于预先设定的相似度阈值su时,说明i,j个体本身差别较大,采用单点交叉产生新的个体,如图4所示。
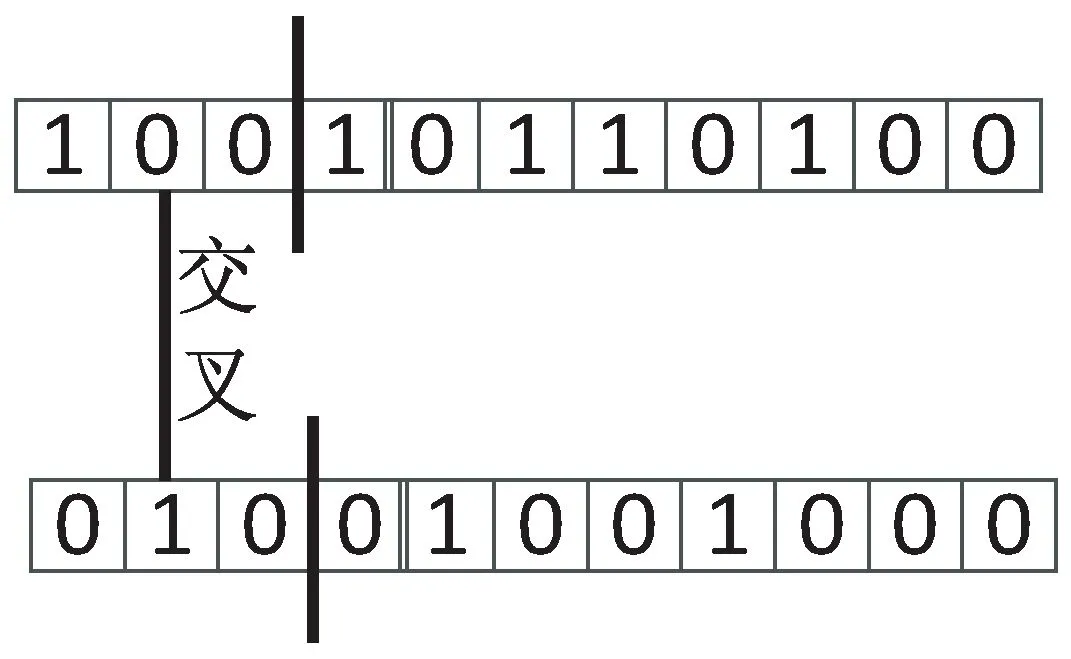
图4 单点交叉
1.4 速度更新模型改进
文中提出的混合算法是将遗传算法与粒子群算法相结合,遗传算法为主,将粒子群算法的更新方式用变异操作代替。该算法既包含由遗传算法的选择跟交叉操作主导的个体更新,也包括粒子群算法本身的自我认知和社会认知对粒子主导的个体更新。对任意子种群Pi,假设进化到第i代时,在第i代之前生成的满足条件的数据总个数为Ti,那么子种群Pi内个体的变异影响因子ρi=1-δi。其中δi为种群产优率[10]。
“产优率”[10]:在种群进化到第i代时,任意子种群j在i代之前生成的最优个体数量为Tji,整个种群在第i代之前生成的总的最优个体数量为:
(3)
那么种群t的产优率为:
(4)
由式3和式4可知,生成优秀个体越多,种群的产优率越大,相应的,变异影响因子越小,种群越稳定;生成优秀个体越少,种群产优率越低,变异影响因子越大,种群倾向于发生突变。
文中将上文提到的产优率替代传统粒子群算法中的惯性权重因子,具体更新方式如下:
(5)
Xi(t+1)=Xi(t)+Vi(t+1)
(6)
从式5和式6可以看出,子种群中个体的更新速度受种群“产优率”的影响,成正向关系。“产优率”的高低直接影响粒子更新速度的高低。
1.5 粒子群-遗传混合算法
文中混合算法流程与传统遗传算法类似[15-16],算法流程如图5所示。具体方案如下:
Step1:初始化各实验参数:种群规模、种群产优率、交叉概率、相似度阈值、加速因子、惯性权重因子等;
Step2:依据1.1节的策略,将种群划分为2s个子种群;
Step3:针对每个子种群,依据1.3的内容各自进行选择、交叉;
Step4:依据式1计算子种群的适应度值,更新存储优秀个体;
Step5:依据式3、式4,分别计算每个子种群内个体的变异概率及产优率;
Step6:依据式5、式6,对各子种群个体进行更新;
Step7:是否达到最大迭代次数或满足终止条件,若满足,算法结束;否则,重复Step2~Step6。
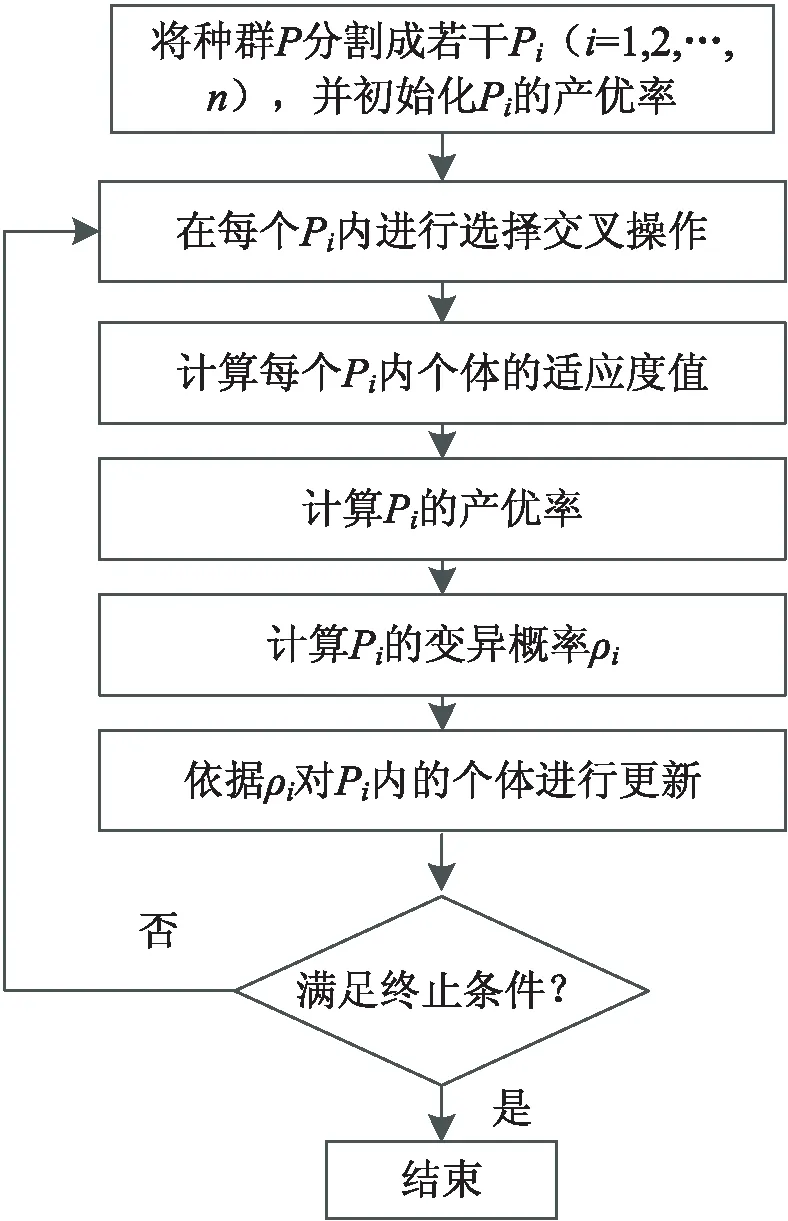
图5 算法具体流程
2 实验及结果分析
为了验证文中提出的算法在解决函数优化问题时的收敛速度以及收敛精度,实验采用表1的5个测试函数进行测试。

表1 测试函数及x相应取值
2.1 h-PSO-GA与PSO、GA算法实验
参数设置如下:将种群划分为10个子种群,子种群大小设为50,最大迭代次数maxiter设为100,c1=c2=2.0,交叉概率pc设为0.35,产优率初始值为0.1,相似度阈值su设置为0.7。实验结果如表2所示。
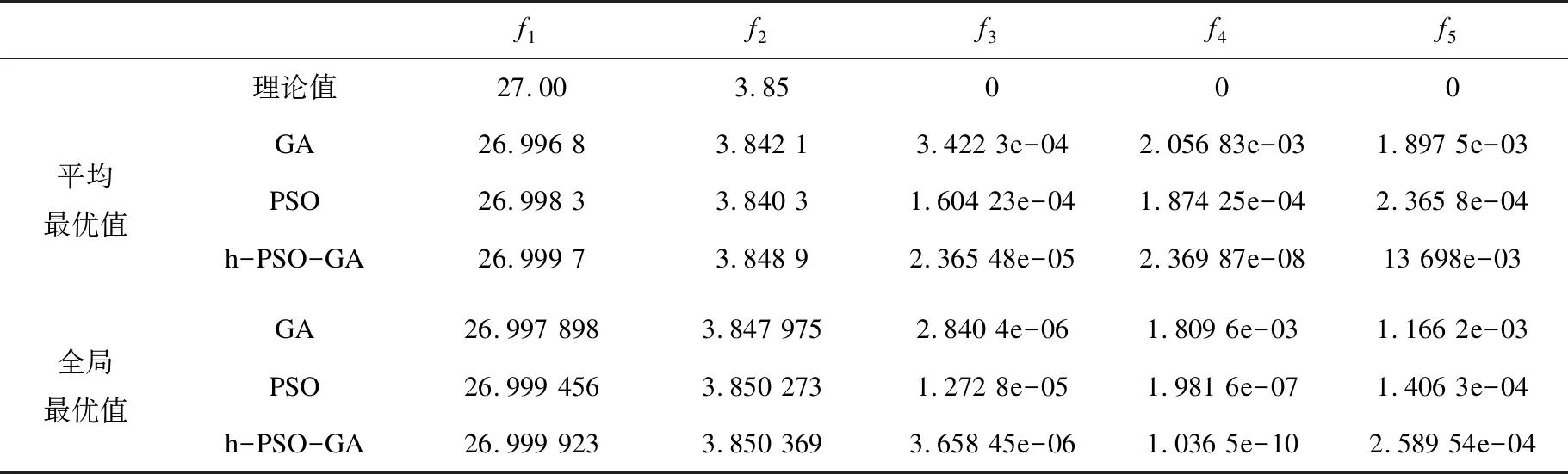
表2 对5个测试函数进行50次实验的实验结果
通过表2可以看出,该实验在重复50次之后,得到了平均最优值与全局最优值。通过与5个测试函数理论值进行比较,可以发现,提出的算法在测试函数上的效果整体来说不错,仅在f5函数上比PSO原始效果差一些,总体来看,该算法在处理函数优化问题时的效果较好。
2.2 最优解收敛变化
对上述5个测试函数比较算法的收敛情况,如图6~图10所示。从图6可以看出,提出算法在f1测试函数上经历10代左右收敛在理论值附近,而遗传算法在接近40代左右才进行收敛,PSO算法在15代左右进行收敛。从图7可以看出,文中算法与PSO算法在收敛速度上几乎差不多,但比PSO算法收敛快一些。在图8~图10中,文中算法比另外两种算法收敛速度都快,在f3,f4函数上,文中算法收敛精度比遗传算法要高。
综合比较,文中算法在几个测试函数上的收敛情况都较好,算法最终收敛精度在函数的理论最优值附近。
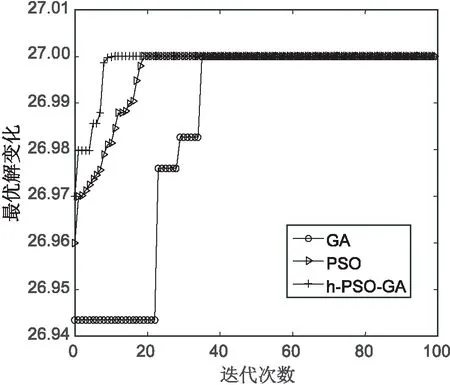
图6 函数f1的测试结果
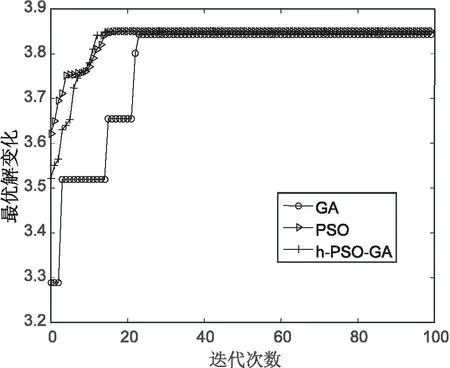
图7 函数f2的测试结果

图8 函数f3的测试结果
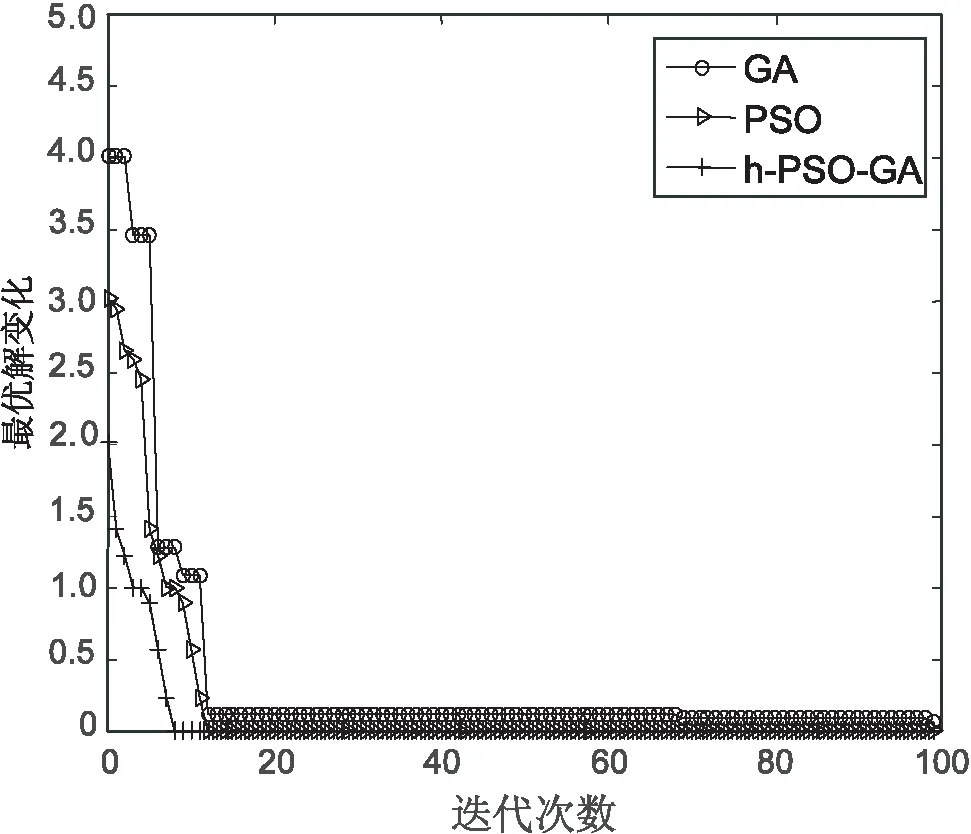
图9 函数f4的测试结果
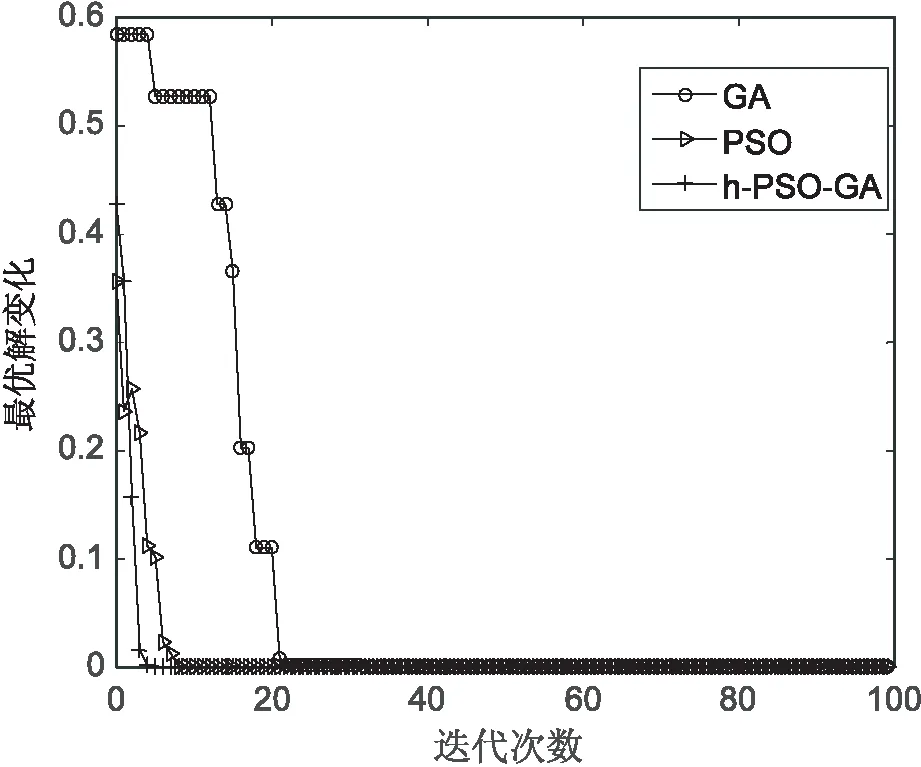
图10 函数f5的测试结果
3 结束语
文中提出一种基于粒子群-遗传混合算法的函数优化方法,通过借鉴小生境技术将种群进行划分,并且通过相似度判断,对不同的父代个体进行不同的交叉操作,并将粒子群算法与遗传算法相结合,用速度算子来替代变异算子,进而实现个体更新。通过与传统遗传算法、粒子群算法进行比较实验验证,该方法在保证种群多样性同时,避免了早熟收敛情况的发生,具有较高的效率。
