基于深度学习算法的藏文微博情感计算研究
2019-10-11孙本旺
孙本旺,田 芳
(1.青海大学 计算机技术与应用系,青海 西宁 810016;2.青海大学 信息化技术中心,青海 西宁 810016)
0 引 言
随着互联网技术的成熟和发展,藏族网民的数量越来越多,微博等成为藏民对社会热点关注和情感表达的平台。藏族网民在网络上发表意见、表达情感已成为一种日常习惯,由此产生了大量的藏文情感信息,其中的信息包含各种各样的情感特征。因此,如何通过复杂的信息抓取分析藏民的情感变化,便成为一项极为重要的研究课题。
近来年,深度学习模型已经广泛应用于文本分类。文中将CNN-LSTM深度学习算法模型引入藏文文本情感分析领域,对于推动藏文文本情感分析研究具有十分重要的意义。
1 相关研究
2006年Geoffrey Hinton[1-2]等首次提出了深度信念网络(deep belief network,DBN)深度学习算法的思想,并以其较强的学习能力和最大限度提取特征的特点,成为其后深度学习算法的主要框架。随着深度学习技术的发展,之后出现了堆栈自编码[3]、卷积神经网络(convolution neural networks,CNN)[4]、长短时记忆网络(long short-term memory,LSTM)[5]等深度学习模型。
麻省理工学院的Picard教授最早提出了情感分析的概念。Picard教授在1995年发表了论文《Affective Computing》[6],并在两年后在此基础上撰写了的有关情感计算的最早同名论著[7]。Richard Socher等提出深度递归自编码算法,在中文[8]和英文[9]的情感分析中,都取得了不错的结果。Socher R等将Matrix-Vector融入循环神经网络(RNN)模型来学习逻辑命题和运算符含义,对电影评论的情感标签进行分类[10]。Tang D等通过卷积神经网络和循环神经网络相结合的算法进行情感分析,自动推荐适当的表情符号,取得了优异的成效[11]。B. Sun等提取了声学特征、lbptop、密集SIFT和CNN-LSTM特征,用LSTM和GEM模型来识别电影人物的情感[12]。J Huang等提取其他声学音频特征集、外观特征和深层视觉特征作为补充特征。每种特征类型分别使用长时记忆递归神经网络(LSTM-RNN)进行训练,而且用于每个维的情感预测,要分别考虑注释延迟和时间池[13]。宋梦姣结合双向LSTM和卷积神经网络构建的CNN-LSTM模型在情感计算的性能上有所提升,在此模型的基础上又设计了使用注意力机制的CNN-BLSTM-Attention模型;注意力机制能帮助模型得到含有注意力概率分布的语义编码,有效突出文本中对情感分析任务更关键的词语,在文本情感分类任务上取得了更高的准确率[14]。焦晨晨提出基于横向卷积和纵向卷积相结合的卷积神经网络(HV_CNN),结合动态卷积神经网络(DCNN)的网络模型[15]。
在藏文情感分析方面,闫晓东等通过人工方法构建了一个全面、高效的极性词典,包括基础词词典、否定词词典、双重否定词词典、程度副词词典以及转折词词典,并提出了基于极性词典的藏语文本句子情感分析方法[16]。张俊等通过借鉴中文微博情感分析中比较常见的基于统计的方法和基于词典的方法对藏文微博进行情感分析,实验结果表明基于藏文词典的藏文微博情感分析的准确率明显高于基于TF-IDF的藏文微博情感分析的准确率[17]。杨志根据藏文微博的行文特征,提出了基于情感词典与机器学习算法多特征融合的藏文微博情感分类方法[18]。袁斌针对藏文微博中存在的藏汉混排问题,提出了一种基于语义空间的藏文微博情感表示方法。该方法通过句法树实现了语义向量化,提高了情感特征中的语义成分,并解决了多语言混合文本处理问题[19]。李苗苗提出了藏文文本情感分析的词语级、句子级、篇章级三层框架,提出了利用情感词典和规则集分析藏文句子情感的一种方法,采用SVM算法对篇章级进行情感分析[20]。普次仁等将藏文分词后,把深度领域内的递归自编码算法引入到藏文情感分析中,以更深层次提取语义情感信息,有监督地训练输出层分类器以预测藏文语句的情感倾向[21]。
2 藏文微博的情感倾向分析方法
情感分析首先要对藏文微博数据进行预处理:去除xml和@符号,去停用词等,将单词条内容处理成单行数据。然后对藏文微博进行分词,文中主要结合人工和情感词典进行藏文分词。最后利用规则和统计的方法进行情感计算。
2.1 基于情感词典的方法
由于藏文情感词典都不公开,也没有统一标准用于藏文情感分析的藏文情感词典,故使用文中自动构建的藏文情感词典。该藏文情感词典总词量达27 361个,包括程度副词220个、基础情感词(积极10 670个、消极10 402个、中性5 711个)、停用词385个,相比其他藏文情感词典多了双重否定词。
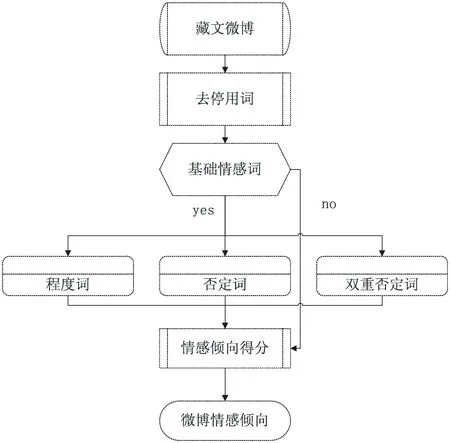
图1 基于情感词典的情感计算流程
基于情感词典的藏文微博情感分析的方法主要用于实验结果对比。通过微博中情感词或情感短语的权值叠加计算来判断某条微博的情感倾向。如果微博包含转折词,取转折词后面的部分微博进行情感计算,还要考虑微博中的程度词和否定词等。情感计算流程如图1所示。
2.2 基于CNN-LSTM模型的方法
微博文本向量化为文本处理提供了基础。结合CNN和LSTM的模型特点,提出了CNN-LSTM算法模型。该模型以CNN的第三层输出作为LSTM第一层的输入,在每一层的输出都做归一化处理。该模型既能保留CNN对文本的全局度量,又能保留LSTM对文本的上下深层语义信息,挖掘出更深层次的语义关系,取得了较好的分类效果。
2.2.1 Word2vec词向量
神经网络的输入需要将藏文微博语料映射成为向量,Word2vec使用的模型分为CBOW和Skip-gram,文中使用Skip-gram模型实现词向量化,最终得到词向量字典。
Skip-gram:是用中心词来预测周围的词。在Skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent不断调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。每个词在作为中心词时,都要进行K次的预测、调整,这种多次的调整会使得词向量相对更加准确。
2.2.2 CNN-LSTM模型
CNN可以保留文本的全局度量特征,但无法解决文本上下文的长期依赖问题和上下文语义关系问题。而LSTM具有学习长期上下文记忆依赖的能力,能有效利用和记忆很宽范围的上下文语义关系。结合两者的结构特点,文中构建CNN-LSTM模型用于藏文微博的情感计算。
CNN-LSTM的网络层包括卷积层、Batch Normalization层、池化层、时序层、输出层,如图2所示。
卷积层:经过词向量表达的藏文微博文本为一维数据,文中利用三层一维卷积,抽取藏文微博的局部特征,经过卷积核运算产生微博文本特征。
Batch Normalization层:作用在每层卷积层之后。不仅极大提升了训练速度,收敛过程大大加快,还能增加分类效果,类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率。
池化层:采用max-pooling,池化层作用在每层卷积层和Batch Normalization层之后,是一种非线性降维的方法。用来缩减输入数据的规模进行特征映射层,此阶段保留K个最大的信息,保留了全局的序列信息。
时序层:将两层LSTM作为文中模型的时序层。其能够解决远距离上下文依赖特性关系、存储和挖掘出上下文深层语义信息。
输出层:采用Softmax分类器。
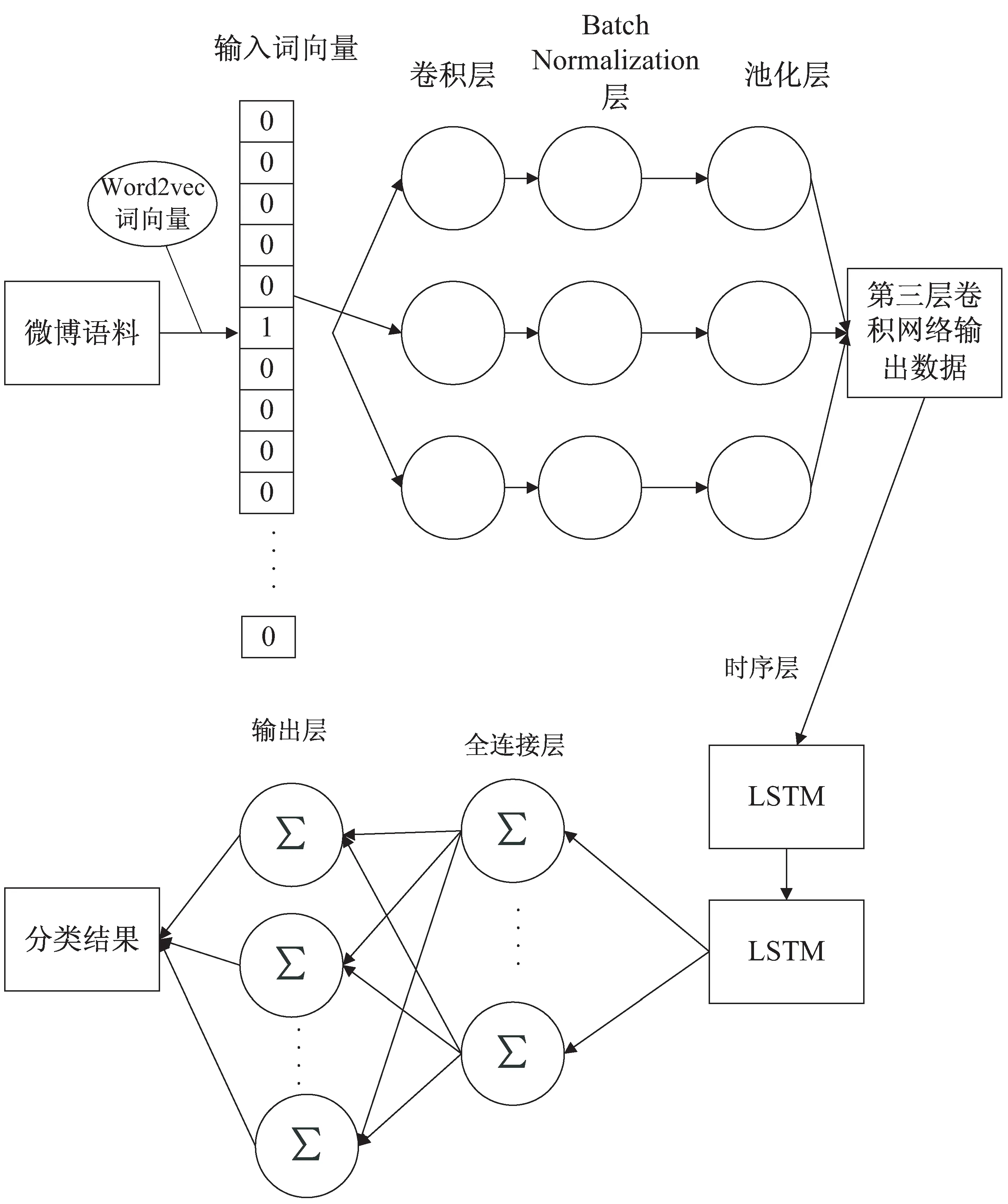
图2 CNN-LSTM网络模型结构
3 实验结果分析
利用标注好的藏文微博语料,经过微博中词语的同反义词替换来扩充语料,增加的语料基本满足了深度学习对数据量的需求。为了验证算法的准确性,对基于情感词典,LSTM和CNN-LSTM的深度学习算法进行藏文微博情感倾向分析进行对比。深度学习模型LSTM和CNN-LSTM激活函数为softsign,优化函数为Adam(学习速率为0.01)同样的语料库,结果如图3~图5所示。
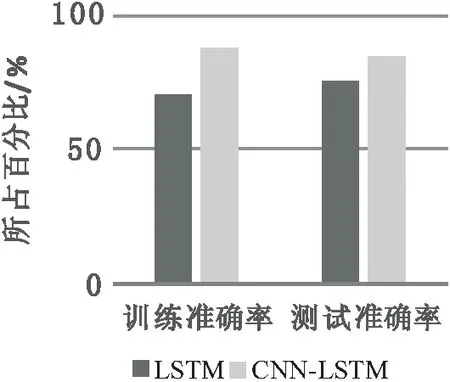
图3 LSTM和CNN-LSTM准确率对比
从图3可以看出,CNN-LSTM比单独的LSTM模型的测试准确率高约10.2%,训练准确率高约18.3%。CNN-LSTM模型能够保证每条微博的全局结构不变,又能挖掘出更深层次语义信息结构,所以其训练测试率都比较优异。
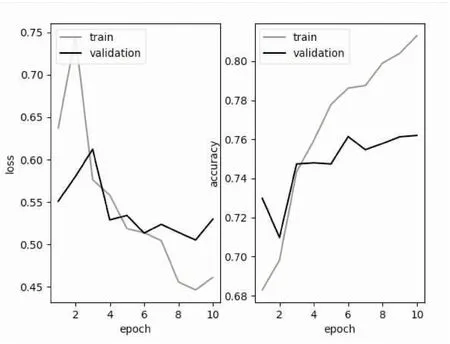
图4 LSTM的loss和accuracy趋势变化
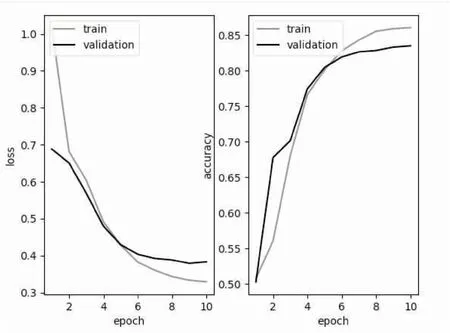
图5 CNN-LSTM的loss和accuracy趋势变化
从图4和图5得出,CNN-LSTM模型的训练集损失率下降比较平稳,训练集的准确率又能稳定上升,此模型相对其他算法模型具有良好的稳定性。
接着将基于藏文情感词典、LSTM和CNN-LSTM的准确率进行对比,如表1所示。

表1 分类准确率对比
从表1可以看出,基于CNN-LSTM情感分类比LSTM模型高10.2%。卷积神经网络注重于对全局的度量,RNN侧重于每一相邻信息的重构,而LSTM要比传统RNN对文本深层语义信息的处理更加有效。模型能够保证每条微博的全局度量,又能挖掘出更多的深层次语义信息,做出更精准的情感分类。
4 结束语
文中将深度学习算法的CNN-LSTM模型引入到藏文的情感倾向分析。同时,研究了藏文微博中情感倾向分类的LSTM、CNN-LSTM等方法,对于每个微博情感特征,训练分类器,不同情感分类具有不同的判别能力。CNN-LSTM利用卷积层和LSTM层融合网络来处理情感特征,保留文本的全局度量又能挖掘出更深层次的语义关系,取得了较好的分类效果。此外,该模型也存在一定的不足,如藏文语料分词困难等,这些还有待进一步研究。
