大数据背景下公共服务需求精准识别机制创新
2019-10-09容志
容志
摘 要: “让数据产生价值”是信息化、智慧化时代公共部门服务创新的重要方式和路径之一。大数据分析对于公共服务需求识别的意义和价值,并不仅仅停留在信息技术层面,除了能够以较低成本、更高效率的方式获得海量社会成员行为和状态数据,降低统计误差、提高需求辨识的精准度以外,对数据的结构化改造和关联性挖掘还能够发现社会个体乃至群体的行为轨迹及特征,揭示其中的一致性规律,并预测服务需求,提高决策的前瞻性和预见性。从社会层面进一步来说,信息沟通技术的广泛使用,能将公民、社会组织、市场组织都整合到公共服务的共同生产过程中来,提高社会成员和利益相关方之间的互动交流与体验感,进而提升公共服务绩效和政府信任度,乃至催生创新政策和服务的新知与理念。
关键词: 大数据;公共服务需求;精准识别
互联网、大数据等信息沟通技术(Information Communication Technology,ICT)的广泛运用已经深深改变了私人部门的管理方式、过程和绩效。出于商业目的,企业利用互联网技术、数据挖掘技术进行市场调查、客户细分、知识学习、错误识别和风险评估等活动,确保决策和服务更精确、更有效。为了创造公共价值,政府部门,如健康、教育、安全、城市管理等机构,也开始运用大数据技术提升服务效率、透明度等,帮助自身更好履行职责。可以说,在万物互联的智慧时代,任何社会组织和个人都无法忽视信息溝通技术、人工智能对组织管理以及社会管理的影响与塑造。公共服务需求是公共服务体系建设和完善的前提与基础,如果缺乏对需求的精准识别和把握,公共服务“供给不足”和“供给过度”就会同时存在,进而制约公共服务的实际绩效。大数据和人工智能等技术的快速发展,为社会层面的知识图谱构建以及个体层面的人物画像提供了可能。如何将这些技术应用于公共服务需求精准识别和预测,提高公共服务体系精细化管理水平和质量,进而提升公共服务满意度和认同度,就成为一个非常值得关注和讨论的现实课题。
一、公共服务需求及其精准识别
需求和需求管理是现代管理关注的一个重要的理论和实践问题。企业管理和市场营销一直重视顾客需求的识别和管理,并逐渐形成了系统化的知识与操作体系。例如,1980年初出现的“接触管理”(Contact Management),强调通过收集客户与公司联系的所有信息来维护客户群体;在关系营销之后,开始出现包括电话服务中心支持资料分析的“客户关怀”(Customer Care)。随着互联网技术的普及应用,客户信息处理技术(如数据库、商业智能、知识学习等技术)得到了长足的发展,20世纪90年代末期出现了客户关系管理概念(Customer Relationship Management)。CRM强调对顾客行为和特性的深入分析,以取得对顾客及其偏好、愿望和需求的完整认知,然后应用这些知识去制定营销战略、编制营销计划和发起营销活动。实践证明,CRM明显提高了企业决策和服务的精准度和有效度。
相比之下,传统的政策制定与公共服务提供对于公众的真实需求和满意度其实并不敏感,也缺乏察觉和回应,特别是对多元化、复杂化的社会需求缺少辨别力,逐渐形成了政府主导提供、公众被动接受的单向供给,因此饱受学者和社会层面的诸多批评。20世纪90年代以后,受到企业管理的影响,新公共管理和新公共服务运动强调“顾客导向”和“需求导向”,要求公共部门把服务对象放在优先考虑的位置,并依据满意度来不断改进服务质量,需求管理才逐渐被政府决策提上日程。近年来,包括公开征求意见、召开座谈会、网络化信息收集、委托专业机构开展需求调查和参与式治理在内的需求调查应运而生,这些做法无疑有助于推动公共政策和服务创新,以提高政府需求识别的主动性和灵敏度。
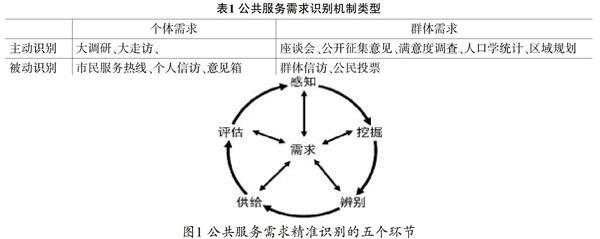
除了自上而下的识别行为之外,政府也开辟了一些自下而上的需求表达通道,如遍布全国的各类市民服务热线等,鼓励市民主动向政府“表达”需求,以提高需求识别的及时性和便捷性。同时,政府通过制定、颁布和执行类似“城市公共服务设施规划标准”,或区域卫生发展规划等服务行业规划标准,也在回应特定的群体性需求(特定治理单元中人口的总体公共服务需求量),只不过这种需求更多地表现为人口学、统计学特征。如我国建设部门发布的《城市居住区规划设计规范》要求,居住区配套公建的配建水平,必须与居住人口规模相对应,同时还对公共服务设施的面积标准做了详细规定,以保证这些公共服务设施规划能够满足日后的社区生活需求。这些不同类别的需求及其识别方式在表1中得到了概括和归纳。
总体来说,这些方式和机制有助于提高需求识别的灵敏度和政府的回应度,进而提高公共服务的绩效。但要注意的是,与商品的市场需求、消费者的服务需求相比,公共服务需求及其识别具有几个重要的特殊性:第一,企业可以瞄准某一特定人群,但政府的视野必须是全域性的,覆盖所有区域和人口,且包含教育、医疗、文化、市政等多个维度,因此,这类需求势必是一种海量信息,其收集和识别的难度远超企业销售行为。第二,在高速发展且日新月异的现代社会中,人们的公共服务需求受到经济、政治和社会多种因素的影响,在时间、空间、社会结构(年龄、阶层、群体)等维度上呈现出各类横向和纵向的差异与变化。在对“公众福利态度”的调查中就发现,即使是在一省范围内,各市县在福利需求上也存在明显差异,这就给识别提出了更加细化、动态和精准的要求。第三,由于公共服务体系中不存在市场的价格机制,人们在消费大多数的公共服务(产品)时,并不按照自己消费的数量和质量付费(或者低于市场价格付费),因此人们表达出来的需求有可能并不是其在市场状态下的真实需求,且往往会扩大或夸张其需求。第四,公共服务需求通常以社会主体的表达为主要呈现形式,因此表达机制的有效性和政府感知的准确性往往成为公共服务需求呈现的重要基础和条件。在一个开放的、多元的和民主的环境下,表达方式可能多样化,表达渠道顺畅,政府议程较为科学民主,则公共服务需求就可能更多;相反,当民众很难就自己的需求向政府发出声音,政府对这些需求的回应性也较低时,当地的公共服务需求可能会受到压制而显得较少。正因为这些原因,公共服务需求的识别过程中势必遇到比企业更加复杂的精准化难题。
一是减少误差的瓶颈。众所周知,统计中样本的数量及其代表性对结果的准确性会产生决定性影响。受制于人力成本和时间成本,现代政府对大多数公共产品和服务的需求都无法进行大规模的调查或“普查”,而只能进行抽样调查,甚至座谈会、领导调研和大走访等形式的需求调查。不仅样本量极为有限,参加者也往往因为操作者的主观选择而缺乏代表性。在市民热线、信访等个体性识别机制中,甚至还会出现“会哭的孩子有奶吃”的现象,即声音最强者(如反复打电话)往往可能得到较多关注,而其余人群则可能被弱化甚至忽视。因此,类似的局部化、点状化、运动化的需求收集机制必然存在代表性不足和准确性较差等缺陷。
二是准确辨识的瓶颈。公共部门不仅需要需求信息的全面性和完整性,还需要辨识其真实性和准确性,以保证服务提供的公平和有效。这就要求对更丰富的、多维度的客观性信息进行综合、比较和佐证。如在扶贫工作中,对于贫困户的认定就需要综合收入、财产、健康、生活等多种因素,其中“收入”一项又可细分为务农收入、务工收入、资产收入、转移性收入等多种类型,这对信息的宽度和广度提出了更多要求,传统的信息收集方式可能因为成本过高而无法完成。而且,在目前层级化和部门化的科层行政体系之下,“信息孤岛”的现象依然存在,数据的“部门化”“碎片化”弊端并未消除,这就进一步加大了信息综合和准确辨识的难度。
三是提高效率的瓶颈。由于制度化程度低,传统的需求识别机制基本是“运动式”“随机式”的,有时甚至依赖于政治性力量自上而下地推动。这种模式对于发展变化的社会需求来说无疑是滞后的,效率显然也不高。往往当“需求洪峰”来临时,公共部门显得措手不及和难以应对。另一方面,对于市民来说,由于正式表达渠道的有限,或者身体不便等客观原因(如老年人、残障人士等),通常难以便捷和快速地向公共部门表达需求并获得相应的服务供给。需求识别的长期低效会直接影响到公共决策的针对性和有效性,最终造成了公共服务供给的错位,形成公共财政资源的低效和浪费,弱化了基本公共服务均等化战略的实施效果。
四是整合需求的瓶颈。社会需求通常是个性化、多元化的,公共部门不可能无条件满足所有需求,因此,它必须对不同的社会需求进行分析、综合、比较以及筛选,根据特定的原则(如福利经济学)和具体的经济社会环境,找到最大公约数(如基本公共服务),最后确定回应哪些需求、如何回应,以及供给到什么程度。这是一个比信息收集、处理过程还要复杂的决策过程,传统的识别过程往往缺乏这样的整合工作,容易造成顾此失彼、服务不均等问题。
二、大数据及其对需求识别的功能创新
一般认为,符合5V(Volume、Variety、Velocity、Value、Veracity)特征的信息被定义为大数据。以互联网、大数据等为主的信息沟通技术在被广泛运用的同时,已经深深嵌入人类社会的行为和交往之中,并通过每时每刻制造着海量、多样、快速、有价值和真實性高的信息,影响和形塑着人们的偏好与决策。除了私营企业如连锁超市利用数据挖掘改善营销战略、网络营销战略等方式以外,在公共政策领域,大数据的重要功能逐步被人们所认知和开发,部分国家和地区甚至在公民以投票表达其倾向和意愿之前借助大数据帮助政府预测政策需求。有学者认为,通过使用互联网、云计算、物联网、智能技术,通过全方位掌握服务对象信息,及时捕捉、科学辨识、快速整合公共服务需求,解决信息不对称问题,能够实现公共服务供给的空间精准化、人群精准化和水平精准化。王玉龙等认为,对海量用户行为数据的分析,不仅可以获取考察个体层面的需求特征,而且基于用户特征的深度挖掘与聚类分析有助于增强在个体需求、群体需求内部的异质性识别能力,并有助于实现基本公共服务资源与区域发展需求之间的匹配。
从理论上说,公共服务需求识别是指公共部门收集、辨别和分析需求数据以获得全面真实的信息,为公共服务决策提供知识基础的过程。由于国家基础信息系统和社会诚信系统建设长期滞后,我国公共服务体系赖以支撑的社会信息基础较为薄弱,公共服务需求识别的灵敏度不高,公共决策和生产的科学性、精准性也受到很大影响。智能电子设备的广泛使用和多维社交媒体的深度嵌入将人类带进了数字化时代,数据密集科学(data-intensive science)的产生为解决公共服务需求信息瓶颈问题提供了新的可能。但事实上,如果我们深入分析就会发现,大数据的功能对于公共服务需求识别的意义和价值并不仅仅停留在信息技术层面,除了能够以较低成本、更高效率的方式获得海量的社会成员行为和状态数据,降低统计误差,提高需求辨识的精准度以外,对数据的结构化改造和关联性挖掘还能够探索社会个体乃至群体的行为轨迹和特征,揭示其中的一致性规律,并预测服务需求,提高决策的前瞻性和预见性,这就是超越简单技术改进的机制创新。从社会层面进一步来说,信息沟通技术的广泛使用,还能将公民、社会组织、市场组织都整合到公共服务的共同生产过程中来,提高利益相关方之间的互动交流和体验感,进而提升公共服务绩效和政府信任度,乃至催生创新政策和服务的新知与理念,这一价值就更具有政治性和社会性。具体来看,这个实践运用的过程可以分为数据化、结构化和社会化三个逻辑层面。
1.数据化过程和“现实挖掘”(reality mining)能力提升
数据是信息的载体,记载和反映着客观事物性质、状态以及相互关系。今天,海量、多维、有价值数据的生成和利用,首先得益于以互联网、物联网和智能设备为主体的信息沟通技术所快速推进的现代社会的数据化过程,越来越多的人类行为和社会状态被观察和记录,产生大量方便传输、存储和分析的数据。这大致包括三个方面:第一,任何使用网络和智能设备的行为,如搜索引擎、浏览网页、网上购物、网约车等,都会被悄无声息地记录下来,形成行为数据,这是以前无法实现的。第二,高科技和灵敏度的传感器(sensor,如热敏、光敏、气敏、力敏等)的大量使用,能够实时监测特定的物理量或化学量并将其转化为数据,满足信息的传输、处理、存储、显示、记录和控制等要求。第三,人们在网络社区可以方便表达、沟通、上传、下载各种类型的数据,如文字、音频、视频等,这些数据本身要么是意见表达,要么隐含着个人偏好与需求,都是意义丰富的信息来源。随着数据量的不断增加,人们可以从中挖掘的需求信息就会越来越多,精准度会越来越高,主要表现在:一是大幅增加了样本数量,甚至可能获知全体的数据,从而减少抽样误差,提高需求信息的准确度,这正是大数据的海量(volume)特点和优势的体现。二是明显增加了需求信息的维度(variety),除了人口的年龄、性别、学历、住址等基础静态信息,以及收入、诚信、健康、财产、流动、消费等动态信息规模都在扩大以外,各类文本文档、语音文档和医疗影像等非结构化的数据也在与日俱增,用于需求识别的基础信息更为全面和完备;例如以“12345”为代表的“市民服务热线”除了能够统计居民的满意度外,还获取到居民大量的语言和文字描述和需求表达,这种非结构化数据往往蕴含着简单满意度评价之外的大量有益信息。三是降低了数据获取成本,提高了表达和识别效率。以前,很多数据要靠人来观察、监测,如城市网格化巡查到各类专业性检测、测量等,或者依靠市民主动上报、表达,在有了自动传动器、物联网以后,随着成本降低,大量数据的获得、存储和分析的效率得到明显提升。四是能够挖掘隐性数据,获得以前很难获得或者不被注意的数据,例如每个用户一天之内用水、用电量的变化等。
因为数据是对客观事物性质、特征的记载和反映,因此巨量、多维度和多态性的数据集成,就提高了人们认知和“描述”人类行为和社会状态的能力,这正是透过大数据中数字痕迹发现内在规律和真实想法的过程,被称为“现实挖掘”(reality mining)。对这些行为和状态的准确、多维和系统的描述,正是大数据之于公共服务需求的重要意义。例如,笔者在上海调研时发现,有的区民政部门给高龄独居老人家的水表安装一种名为“水管家”的记录仪。它能够把每次用水的时间、水量等数据实时传递给社区老年人服务中心,根据对这些数据的分析,就能大致了解高龄老人在家里的活动情况,并进而判断是否需要特殊的照料服务。这个案例正是大数据“描述”功能的典型体现。另外,人们还能够通过挖掘交叉验证方法判断数据真假,以提高需求信息的真实性,从而提高政策指向的精准度。例如,个人收入的申报数据是一类重要的需求信息,但这些数据是否真实情况的反映,以前并不容易弄清楚或者识别成本太高,结果导致不符合条件的个人获得最低生活保障补贴,或者不符合条件的家庭购买到了经济适用房。如果公共部门同时掌握了个人纳税、消费、财产等方面的数据,以及其雇主申报的数据,就能够进行交叉验证辨识真伪。好比一个人名义上是低收入,住着政府提供的保障房,但近期却购买了价值不菲的名车,就显然违背了常理,即使收入正当也不应再归属于低收入群体并享受有关福利。又如,学校并不准确掌握学生的家庭收入情况,但通过对学生食堂消费数据的挖掘和分析,却能发现季度或年度消费情况明显偏离一般(如食品消费额过低)的学生群,然后进一步识别其是否属于贫困学生。类似这种交叉验证,往往能够极大地提升公共服务需求信息的精准辨识度,从而提高管理和决策的针对性和有效性。
2.结构化过程和政策知识生产优化
人们的行动和状态之间是普遍联系的,因此,记录其行动和状态的数据之间也具有一定的联系性。在这种情况下,虽然我们无法直接了解某类行动,或者衡量和识别某类需求,但可以通过“关联关系”或“因果关联”来“迂回”了解所需要的信息。这种信息之间的强烈相关性就被称为“互信息”(Mutual Information)。一个经典案例是2007年流行病学家与Google工程师合作,成功预测了流感的传播区域。专家们发现,现代社会中人们出现了流感症状后往往不是第一时间去医院看医生,而是上网搜索相关信息以做出自我判断和“诊断”。因此,符合具体特征的“网络搜索”行为就会与“感染流感”之间产生一定的“关联性”。人们通过锁定具体的“搜索”行为,就有可能了解“感染流感”这一实际状态。在实践中,工程師们从4.5亿种关键词的组合中,挑选出了与流感症状相关的45个重要的检索词条和55个次重要词条,然后通过各地区用户在Google上搜索这些词条的趋势变化来预测流感流行到了什么地方。最后发现,机器预测的结果和疾病控制与预防中心公布的数据进行对比,准确率达到了97%以上。
可见,“互信息”是大数据“预测”功能的内在机理和前提基础。通过构建特定的行为、状态的因果“链条”,就能够在“描述”和“监测”社会状态的基础上,主动“预测”和“预判”未来可能出现的社会行为和状态。如流感爆发,必然引发人们治疗的需求;车祸发生,就会有人被送急诊治疗,等等。因此,如果系统全面收集前期信息(受害事件、流行病),就可能预测特定时间段内的后期需求(如卫生需求),并进而快速地进行资源的有效配置,以应对需求的变化。例如,澳大利亚已经利用大数据开发和运用了一种名为“病人入院预测工具”(Patient Admissions Prediction Tool,PAPT)的系统。该系统能够用来预测一定时间段内有多少病人会因紧急情况进入医院,他们的医疗需求以及能够允许多少病人住院或出院,还能允许在场全体医疗人员观察病人就医量在不同时间段里的变化情况,比如在一个小时后,在一天内剩余时间里,在下周内甚至是在不同日期的节假日里,像是复活节或者当地发生特定事件的那段时间里。PAPT使人们能够设计出新的措施来应对已被预测到的重大事件。例如,研究发现,在中学毕业庆祝周那段时间里,多达20%的紧急事件都与中学生有关。有了关于这些紧急报告和入院的信息,院方可以规划照顾这些学校病人的医疗人员、医疗用品和床位的分配;同时为其他已到达医院并且身受重伤的病人安排等候时间。其他一些新的应对措施,比如和昆士兰急救服务机构合作搭建的指定医疗帐篷为很多学校内的病人提供就地治疗,这样可以为医院内更加严重的患者腾出急诊科的病床。据估计,如果澳大利亚各地医院均采用PAPT的话,那么该软件每年可能节省出2300万美元,以提高卫生系统的服务效率。
3.参与化过程和需求社会整合度提高
数据分析不仅能够“挖掘”潜在的社会现实(reality),还有助于我们发现人类互动交往行为对个体与组织的偏好和决策的“建构性”意义及其关联。美国科学家阿莱克斯·彭特兰(Alex Pentland)认为,在社会学习过程中,社会接触(包括与自己熟悉的人、朋友之间的接触互动)往往会直接影响人们的偏好、态度甚至价值观。
除了这种接触效应外,这种互动交往的“建构性”的意义和价值还有更深层次的内涵:彭特兰(Alex Pentland)认为,人们之间想法、观点的交流互动对于社会创新具有非常重要的意义,通过社会参与促使想法(idea)流动起来,并进而催生新的想法,是社会建构的重要驱动力,“新想法的传播和结合是行为转变和创新的推动力”,他的实验揭示到,从社会心理层面来看,个体所需要的东西,以及会选择怎么样的行动来满足自己的需要,都具有不断演化的与他人互动的性质,“我们的需求和偏好大多是基于我们的同伴社区对事物的价值判断,而不是直接基于以个体生物本能或者后天道德观为基础的理性思考”。这就说明,以社会交往的特征的社会学习过程事实上在“建构”着人们的偏好和兴趣,因此,公共服务需求的识别也不仅仅是单纯的自上而下的过程,倘若缺乏社会和公民的主动、清晰和富有成效的需求表达,识别也难以做到真正的精准和科学。事实上,公民、社会组织、企业等利益相关方都已经主动或被动地参与着数据的生产和使用过程,离开全社会的参与,大数据分析只能说是无源之水和无本之木。有学者提出“参与式治理”对需求整合的意义和作用,强调政府、公民和社会组织三方主体之间的良性互动,把自上而下的需求调查、自下而上的需求表达与专业性的需求整合融汇在一起,从而提高需求识别的科学化和社会化程度。这说明,需求的识别与整合不仅仅是一个专业性、技术性问题,从某种程度上说,它同样具有较强的政治和社会属性。
第一,数据规模、维度和形态的急速扩张其实意味着识别对象范围的扩大,意味着更多的公民、社会组织和市场主体的需求被表达、收集和关注,这是之前较难做到的。例如,智慧化的居家养老服务平台的建设,通过室内传感数据的集群系统、移动互联网等技术,构建出了家庭健康监测系统等,能够动态、及时地收集和分析居家老年人的身体和生活状况,发现甚至前瞻预测某些意外情形,为管理部门快速开展医疗、救助、生活服务提供需求信息和预警支持,这个覆盖面由以前的机构养老全面覆盖居家养老,带来的需求整合度是前所未有的。第二,大数据技术使得社会组织和个人的需求表达更加便捷和快速,让需求识别更加高效。今天,除了座谈会、调研会这样的传统方式之外,热线电话、网络社区、网络调查、微信群聊、网上办事,甚至网络购物等都可以成为人们直接和间接表达需求的渠道,也为政府提供了多种收集和识别需求的可能,甚至不为公民察觉的隐性的识别方式。例如,像“12345”这样的城市“非紧急救助服务系统”,每天都会接到大量市民电话、短信和网络表达,还沉淀着每项业务的办理流程和居民满意度调查数据。这些高速、海量和异构性的信息构成典型的“大数据”,对该大数据库的分析和挖掘,可以发现和识别大量的民众需求信息。第三,也是更為重要的,基于大数据的分析,人们能够建立一般性的、普遍性的行为特征模型,这其实是对社会需求的总体性描述和“画像”,而那些明显偏离一般特征的个体行为就成了个体性的“画像”,通过人工智能,公共部门能非常容易捕捉这些特殊的个体,并进一步识别是否蕴含公共服务需求。
三、大数据基础上的公共服务需求识别机制创新
从理论上说,所谓需求识别的精准度,主要包括五个方面:一是真实度,即感知的需求信息是真实可靠的;二是准确度,即信息清晰、具体,不模糊;三是全面度,即需求信息能全面地反映个体或群体的多样需求;四是及时度,即需求信息能够随着现实需求变化而变化;五是便捷度,能够以较低成本获取。需求识别其实包括感知、挖掘、辨别、供给以及评估五个环节,每个环节中都有对需求的识别、整合乃至重新定义,以及基于这种定义做出的整合统筹与服务决策。在大数据、人工智能的现代技术的辅助下,这一分析框架对于重构公共服务需求识别机制及其系统具有重要的意义和价值,公共服务需求识别机制需要进行创新与重构,从逻辑上说,包括以下五个环节。
第一,精准的需求感知机制。需求感知是需求识别的前提和基础。在数字化时代,传统的、样本量小、选择性强的需求感知方式已经难以适应形势要求,因此建立更加灵敏、精准的感知机制迫在眉睫。需要注意的是,数据来自服务,没有服务就很难获得数据。也就是说,在提供服务的过程中获得更多需求数据和信息是建立感知机制的关键。这就要求进一步利用“互联网+”、移动政务和物联网技术,改造传统的公共服务模式,提升公共服务能级,进而提高公民需求的主动与自动表达能力,扩大表达的整体性、覆盖面、及时性和完整性,为公共部门准确感知需求提供基础和条件。例如,“一网通办”“全程网办”这样的政务服务系统在某些地区已经逐步运营和成熟,网络办事能够积累巨量、多维度和真实性的数据,涉及居民、企业和社会组织等主体对行政审批、社会保障、医疗报销、出入境、住房保障、流动人口服务、社会救助等方面的需求。从前这些数据都静静地沉默在存储器中,其实,对这些数据的挖掘和分析能够了解一定区域和一定时期内社会保障、生活救助和流动人口的重要特征与要求。再比如,以“城市大脑”“社区大脑”为代表的综合性城市管理中枢的建设,包括与之配套的各类传感器的铺设,成倍地提升了公共部门自动、精准感知社会运行的能力。这些物联网、互联网所形成的海量信息正是大数据分析的“原材料”和“来源”。在这些信息化平台的建设过程中,不能仅仅满足硬件的投入和即时信息的传递,更需要先期规划数据的采集、储存和利用。
第二,精准的需求挖掘机制。研究如何利用现有的、正在收集的海量数据(包括个体、社区和城市等层面),进行深度对比、挖掘和深度学习,描绘公共服务的知识图谱,以及市民的人物画像,提取凝练需求。例如,在上文提到的“12345”热线平台,可以运用大数据分析来了解:一是公共服务需求的内容、类型、特征以及空间分布;除了信息咨询和投诉建议外,求助类需求的具体类型及其特征,在此基础上挖掘城市居民的共性需求和内容,结合区域分布、居住特征、人群特征等变量,分析城市公共服务需求的空间差异和特性,并根据时间变量预测公共服务需求变化情况。二是能对城市居民公共服务满意度及其影响因素分析,对满意度的分析能够更加精准了解其表达的(expressed)和潜在的(implicit)需求,并通过“回应—解释”模型挖掘公共服务满意度的影响因素,如“首日现行联系”“持续动态联系”等回应服务方式对需求满足感产生的效果和作用。最后,还能展示公共部门辨别、供给和评估流程及其瓶颈;从“回应时间”“回应方式”“表述方式”“再回应方式”等方面挖掘公共部门辨别、供给需求的动态过程与不同方式,用以解释效果差异的原因并识别部门协同的困境。
第三,精准的需求辨别机制。这里的“辨别”包括两层面含义:一是辨别数据所蕴含的信息的真伪。对一些主动表达的需求,公共部门往往需要进行判断和识别,以确定该需求是否真实情况的反映。如前文所说,大数据为这种判断识别提供了效率高、成本低的选择方案。这就需要公共部门在数据整合、融合的基础上,善于使用“交叉验证”的方式对大量数据进行“清洗”和“过滤”,保留真实、可靠的需求信息。二是在需求感知和凝练的基础上对需求进行整合与辨别,这里包括辨别需求是否在公共服务范畴之内,以及不同主体的不同需求的互动、博弈乃至整合,最终形成公共服务决策。从理论上说,这就需要通过大数据分析建立社会特定群体和阶层的行为和状态模型,更加精准界定基本公共服务(政府职能)的标准、方式、覆盖面和福利水平,通过与个体需求的对比来辨别需求是否属于公共服务范畴,是否应该得到回应和满足。例如,目前基于医疗物联网和大数据技术建立的远程患者监控系统,通过比对“身体状况”与“数据库”能够实现对居家老人某些病症的远程监护,当发现“状况”改变并“辨识”疾病时,提醒一声及时采取治疗措施。
第四,精准的需求供给机制。研究如何在深度学习和需求整合的基础上,完善和优化社区、城区和城市的公共服务资源配置,包括资源数量、结构、内容在空间、时间等不同维度上的配置,提高需求与供给的匹配度。以社区智慧养老为例,它力图通过信息技术将居家老人、社区、政府、服务提供者联系起来,实现对老年人健康管理、应急救助、生活照料等全方位服务。通常,“社区居家养老融合服务中心”积累了大量老年人的健康、家政需求以及日常服务供给方面的信息,也是典型的“大数据”,通过深入挖掘和分析可以达到多重目的。一是通过个体照料需求的精准识别,探讨居家养老精准化服务供给的具体方式和路径。探索如何挖掘数据信息,为居民、社区乃至更大规模的社会单元进行人物的健康画像,描述其整体性和个体性健康特征及潜在卫生需求,进而优化基层卫生资源建设与配置规划,提升基层卫生资源使用效率、效益和效能。二是针对全区居家老人保健和基础医疗需求,运用老年综合评估工具等严谨的评估量表,配以灵敏的感知设备,在标准化的老年综合评估基础上对老年人需求进行综合分析,并对全区“托老中心”“长者照料中心”空间、资源分布进行“需求—供给”分析和优化设计,提升信息的真实度、准确度、及时度和便捷度。
第五,精准的需求评估机制。这一环节的使命是,在公共服务供给之后,精准评估服务对象的满意度、认同度,以及对服务改进的综合性意见,并将此作为新的需求“感知”以启动下一轮的需求管理周期,形成管理闭环。通常我们将满意度与需求相区别,其实,人们对服务的满意度和评价承载着重要的需求信息。例如,对“市民服务热线”大量数据的挖掘就发现,人们最关心的往往是首次得到回应的“时间”和“态度”,即使有关问题还没有得到完全解决。这一发现的重要之处在于,满意度并非仅仅受到问题是否解决的影响,而可能与“是否被尊重”“是否被重视”更加直接相关。这一需求信息对于优化公共服务体系、提高回应度具有重要的指导意义和价值。
四、结语与展望
党的十九大报告提出,中国特色社会主义进入新时代,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾。这一矛盾是由“需求”和“供给”两个方面的不适应所形成的,因此要解决这一矛盾,系统提升人民群众的幸福感、获得感和安全感,不仅需要大力提升发展质量和效益,努力实现高质量发展,也需要准确把握美好生活需要的内涵,建立更科学的资源与需求匹配机制,让人民共享高品质的公共服务和发展成果。精准识别复杂多元、动态变化和分层分类的公共服务需求,正是实现这一目的的重要前提和保证。
其实,面对庞大的社会及民众,政府对社会数据的储存、处理和使用有着极为悠久的历史和传统。两千多年以来,中国政府在进行户籍造册、土地丈量、税赋统计、财政收支等活动时都会形成和产生海量的结构化和非结构化的“大数据”,这些数据构成了國家治理的基石和条件,也记录着国家治理的过程和效果。但传统公共管理中的数据使用具有时代的局限:一是种类简单,通常仅限于人口、土地、收入、犯罪情况等,且不完整、准确;二是用途单一,如人口统计用来征收税赋,土地丈量用来收租征税等,除此以外数据基本归于静止沉睡状态;三是效率较低,数据只能通过人力收集、储存和管理,成本太高、周期较长、更新太慢;四是碎片分割,各部门各自为政、难通有无,阻碍了数据的共享和共用。现代信息沟通技术的发展,在带来更多数据的同时,赋予数据使用和挖掘更低的成本,更高的效率和更多的功能。更为重要的是,小样本调查、典型案例分析和历史经验归纳为主要知识生产方式的社会科学研究方法和社会需求辨识方式已经受到了极大的挑战。大数据的运用为重塑公共服务需求识别与公共服务供给体系提供了历史性的契机。可以预见,基于大数据分析的需求识别机制具有以下特点:其一,建立覆盖面广、动态更新、微观连续性数据而非断续性或典型性数据,并能够描绘特定社会群体的整体性特征和个体性细节。其二,力图在结构化数据之外囊括包容非结构化数据,如社交网站文本、病例档案文本、群众来信来电记录等,提高数据的多样性、多态性和丰富性。其三,在传统的因果逻辑研究范式基础上,建立以“强关联关系”为核心的数据分析和知识发现路径,消除需求识别和服务决策中的不确定性,发现识别和把握服务需求的新方法,提高公共服务资源配置的科学性与前瞻性。其四,通过引导社会互动交往来建构人类的“思想流动”和“知识创新”,形成社会偏好、兴趣的整合、激励某类具有明显“正外部性”行为和选择的形成。总之,基于大数据分析的需求感知是建立在现代信息论、社会交互网络和行为相关性基础上的数据分析和辨识活动。
同时也要认识到,数据并非自动生成的,数据来自服务,数据与服务的关系是辩证的。一方面,数据是需求感知的条件,可以成为服务供给的前提;另一方面,如果公共部门不提供服务,事实上也无法从服务对象中获得丰富的、有价值的数据和信息。这就说明,服务供给与需求识别在时间序列上并非简单的先后关系,而很可能是交织互动的关系。通过提供服务,来获得更多的用户信息,再通过这些数据信息进行需求识别,以更好地提供用户所需要的服务,这是数字化时代公共服务体系创新的一个可能性趋势。
此外,数据永远是静态的,利用数据需要依靠人类的主观能动性。没有人类的主观能动性,数据的价值不可能自动显现。因此,需要建立技术运用的动力机制,进一步打破部门间在信息共享、数据挖掘、需求识别和服务供给方面的壁垒,形成高效的协同协作态势,激励公共部门激活沉睡、沉淀的大量社会数据;并研究如何让公民(citizen)在E-government建设中扮演更重要的角色和作用,如何通过数据的透明、开放与社会挖掘(social mining)功能的开发,导向更好的公共数据的利用及政府公共服务决策的优化。当然,还需要建立数据安全机制,研究如何加强个人数据的隐私保护、正确利用和适当进入,防止安全机制失灵后产生的各类安全问题,避免不当使用而造成的数据灾难和危害。
注释
Xiang, Zheng & Schwartz, Zvi & Gerdes, John H. & Uysal, Muzaffer What can big data and text analytics tell us about hotel guest experience and satisfaction?, International Journal of Hospitality Management, 2015,44: 120-130.
Desouza, Kevin C. & Jacob, Benoy Big Data in the Public Sector: Lessons for Practitioners and Scholars, Administration& Society. 2014,pp. 1-22.
杨永恒、王永贵、钟旭东:《客户关系管理的内涵、驱动因素及成长维度》,《南开管理评论》2002年第2期。
王玉龙、王佃利:《需求识别、数据治理与精准供给》,《学术论坛》2018年第2期。
蔡礼强:《政府向社会组织购买公共服务的需求表达》,《政治学研究》2018年第2期。
岳经纶、郭巍青:《精准识别群众需求》,《人民日报》2018年2月5日。
王玉龙、王佃利:《需求识别、数据治理与精准供给》,《学术论坛》2018年第2期。
顾严:《“十二五”亟需理顺公共服务需求表达机制》,《中国经贸导刊》2010年第12期。
Cecilia Fredriksson, Farooq Mubarak, Marja Tuohimaa and Ming Zhan,Big Data in the Public Sector: A Systematic Literature Review,scandinavian Journal of Public Administration, 2017,21(3):39-61.
Kim, Gang-Hoon & Trimi, Silvana & Chung, Ji-Hyong Big-data applications in the government sector, Communications of the ACM, 2014,57 (3): 78-85.
Jordan, Sara R. Beneficence and the Expert Bureaucracy, Public Integrity, 2014,16 (4): 375-394.
邓念国:《公共服务如何实现精准化供给》,《学习时报》2015年12月7日。
王玉龙、王佃利:《需求识别、数据治理与精准供给》,《学术论坛》2018年第2期。
Chen, C. L. Philip & Zhang, Chun-Yang Data-intensive applications,challenges, techniques and technologies: A survey on Big Data, InformationSciences, 2014,275 (10 August 2014): pp. 314-347.
Michele Banko, Mitigating the Paucity-of-Data Problem: Exploring the Effect of Training Corpus Size on Classifier Performance
Jeremy Ginsberg, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski and Larry Brilliant, Detecting influenza epidemics using search engine query data, Nature, 2009,Vol457, 19 Feb.
Australian Public Service Better Practice Guide for Big Data,
阿萊克斯·彭特兰著,汪晓帆、汪容译:《智慧社会:大数据与社会物理学》,浙江人民出版社,2015年第1版,第8页。
同上,第55页。
蔡礼强:《政府向社会组织购买公共服务的需求表达》,《政治学研究》2018年第2期。
于广军、杨佳泓:《医疗大数据》,上海科学技术出版社,2015年版,第42页。
董青岭:《大数据安全态势感知与冲突预测》,《中国社会科学》2018年第6期。
吴军:《智能时代:大数据与智能革命重新定义未来》,中信出版集团,2018年版,第130页。
Abstract: The significance and value of big data analysis for public service demand identification is not only at the level of information technology, but also at the level of social individuals and even groups, besides acquiring massive behavior and status data in a lower cost and more efficient way, reducing statistical errors and improving the accuracy of demand identification. Behavior trajectory and characteristics, reveal the consistency rule, and predict service demand, improve the foresight and foresight of decision-making. Further from the social level, the extensive use of information communication technology can integrate citizens, social organizations and market organizations into the common production process of public services, improve the interaction and experience among stakeholders, and then enhance public service performance and government trust.
Keywords: Big Data; Public Service Demand; Precise Identification
