基于卷积高斯混合模型的统计压缩感知*
2019-10-09汪韧郭静波惠俊鹏王泽刘红军许元男刘韵佛
汪韧 郭静波 惠俊鹏 王泽 刘红军 许元男 刘韵佛
1) (中国运载火箭技术研究院研究发展部,北京 100076)
2) (清华大学电机工程与应用电子技术系,北京 100084)
1 引 言
压缩感知[1,2]实现了以远低于奈奎斯特的采样频率去采样稀疏信号,并以高概率实现原信号的准确恢复.贝叶斯压缩感知[3]从统计学的角度描述了信号的压缩采样与恢复过程.根据稀疏贝叶斯学习理论,需要对信号的先验分布进行建模.高斯混合模型(Gaussian mixture models,GMM)因其具有强大且灵活的拟合能力被广泛应用于信号先验分布的建模中[4−6].从主成分分析(principal components analysis,PCA)的角度来说,GMM模型中每一类高斯分布的协方差矩阵的PCA基张成了信号稀疏分解的子空间[7].压缩感知自提出以后被广泛应用于物理成像领域,如光谱成像[8]、太赫兹成像[9]、图像加密[10]、图像重建[11,12]等.
尽管GMM具有简单灵活的优点,但由于图像包含了丰富的信息,GMM对图像(或视频每一帧)的概率分布进行建模时先将整幅图像分割成多个重叠或者不重叠的图像块(patches),对每一小块的先验分布函数进行建模,再独立恢复图像中的每一小块,最后按其在图像中对应的位置组合成一整幅图像,其中重叠区域的像素取平均,这样做的缺点是容易产生图像的分割效应.另外,在硬件实现时,压缩感知是对整幅图像直接进行压缩测量[13].一种直观的想法是能不能直接对整幅图像的先验分布进行建模,但该想法实现的困难体现在两方面: 一是整幅图像的信息量相比于图像块要丰富得多,拟合其先验分布函数的难度会大大增加,简单的GMM对于整幅图像先验分布函数的建模效果不佳; 二是整幅图像的维数比图像块的维数大得多,若对整幅图像的概率分布进行建模,计算量将大大增加.
针对上述问题,本文提出卷积高斯混合模型(convolutional Gaussian mixture models,convGMM)对整幅图像的概率分布进行建模.本文的立意如下:
1) 将整幅图像包含的复杂信息分为两部分:背景信息(background information)和细节信息(detail information).由于背景信息的内容相对较少,这里延续GMM的思想,将不同均值的线性加权求和来拟合背景信息.针对复杂的细节信息,本文从卷积稀疏编码(convolutional sparse coding,CSC)[14]和解卷积网络(deconvolutional networks,DN)[15−17]中得到启发,利用多个滤波器(filter)与特征图(feature map)卷积的线性加权求和来拟合整幅图像的细节信息.从图像块到整幅图像建模的关键是使用了解卷积网络.从直观的角度来说,解卷积神经网络中滤波器的作用类似于传统压缩感知中的稀疏基.同时,本文将GMM与解卷积网络相结合,使得该模型兼具了多个解卷积网络线性加权的灵活性.
2) 考虑到对整幅图像的模型参数进行训练时,计算复杂度高,本文在信号模型和压缩测量模型中都引入了循环卷积,根据循环卷积所对应的含有循环块的块循环矩阵(block circulant matrix with circulant blocks,BCCB)的数学性质[18],所有的训练和恢复过程都可以利用二维快速傅里叶变换(two-dimensional fast Fourier transforms,2DFFTs)实现快速运算.
本文的主要研究内容如下: 1)首先提出convGMM对整幅图像的先验分布进行建模; 2)针对模型中未知参数的学习,本文采用经典的期望极大化(expectation maximization,EM)算法求解极大边缘似然估计(maximizing the marginal loglikelihood estimation,MMLE); 3)针对信号的恢复过程,首先基于先验分布函数和似然函数推导出信号的后验分布函数,并将后验分布的数学期望作为原信号的估计,该估计是最小均方误差意义下的估计; 4)最后在CIFAR-10数据集、Caltech 101数据集和CelebA数据集上验证本文的MMLE-conv GMM算法相比于传统压缩感知算法的优越性.
2 convGMM
令X表示任意的图像,传统的GMM为

其中,p(X|z) 服从高斯分布,p(z) 表示第z个高斯分布所占的权重.使用GMM时需要先将整幅图像分割成多个图像块,再对每一图像块的概率分布函数进行建模.
本文在此基础上提出convGMM对整幅图像X的概率分布进行建模:

其中,

如果将图像X向量化,x=vec(X) ,则它的分布为

需要特别指出的是,(3)式中的卷积是循环卷积,而不是线性卷积.使用循环卷积的目的是为了在整幅图像上实现快速有效的运算.如果图像的大小为对于灰度图像Nc=1,对于彩色图像Nc=3),每个滤波器的大小为(一般情况下则在循环卷积的框架下特征图与图像X有着相同的大小,即根据卷积滤波器与卷积矩阵之间的对应关系,卷积矩阵是一个有着循环块的块循环矩阵:
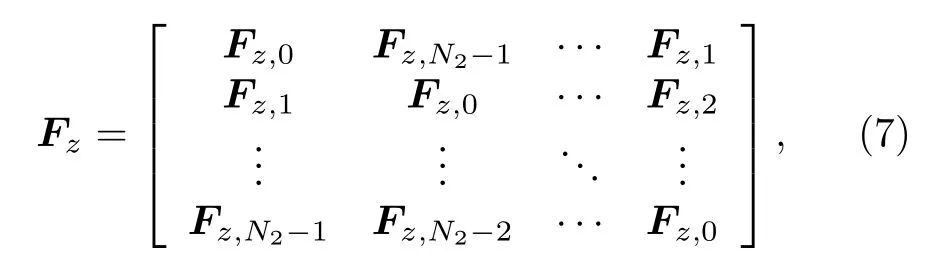
其中,每一块Fz,j,j=0,1,···,N2−1是1个N1×N1的循环矩阵,根据BCCB的性质,可得

其中,WN1表示N1×N1大小的离散傅里叶变换矩阵,⊗表示Kronecker积,是卷积矩阵的第一行.因此,循环卷积运算可以利用(8)式中的一次二维快速傅里叶逆变换(twodimensional inverse fast Fourier transforms,2DIFFTs)、两次2D-FFTs和频域上简单的分量式运算实现快速运算.为了表示简洁,这里令W2d=WN2⊗WN1表示相应维度的2D-FFTs矩阵,则(8)式可以简写为

将循环卷积运算从时域转化到频域是算法能够快速运算的关键.为了更好地理解提出的模型,需要指出的两点是:
1)类似于传统压缩感知中多幅图像被同一组稀疏基或稀疏字典表示,在这里N幅图像共同被K组卷积滤波器与特征图的循环卷积表示;
3 从训练集中学习convGMM

基于(9)式中Fz的频域性质,可得
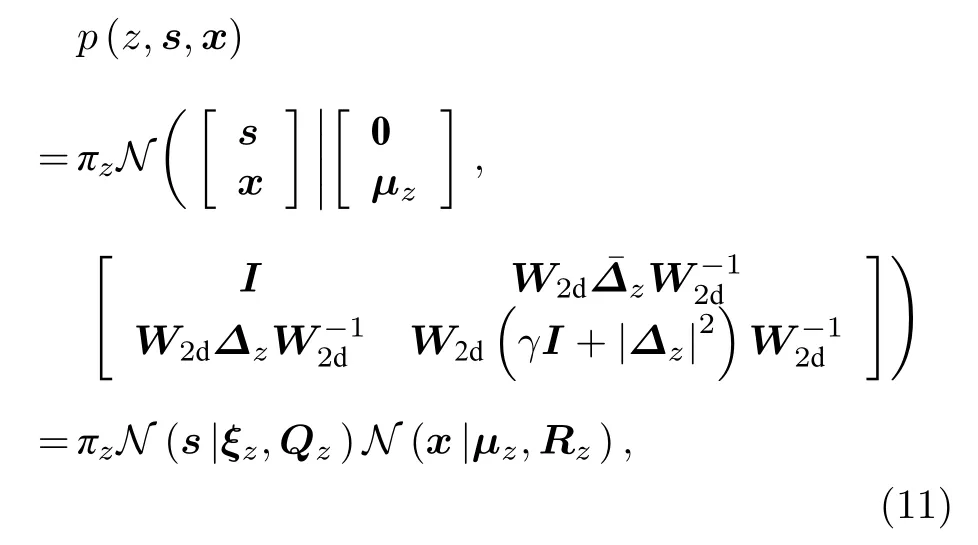

上述这些参数均可利用2D-FFTs和2D-IFFTs实现快速运算.由(11)式可得信号x的边缘分布

和给定x时的(z,s)的后验分布
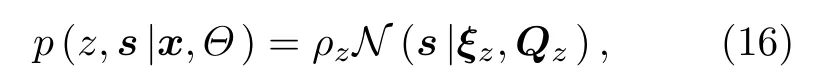
其中,

本文将未知变量 {zi,si} 看作隐变量,基于MMLE从训练数据集中学习convGMM:

其中,联合分布p(zi,si,xi|Θ) 由(10)式给出.通过EM算法[19]求解上述的目标函数,具体步骤如下.
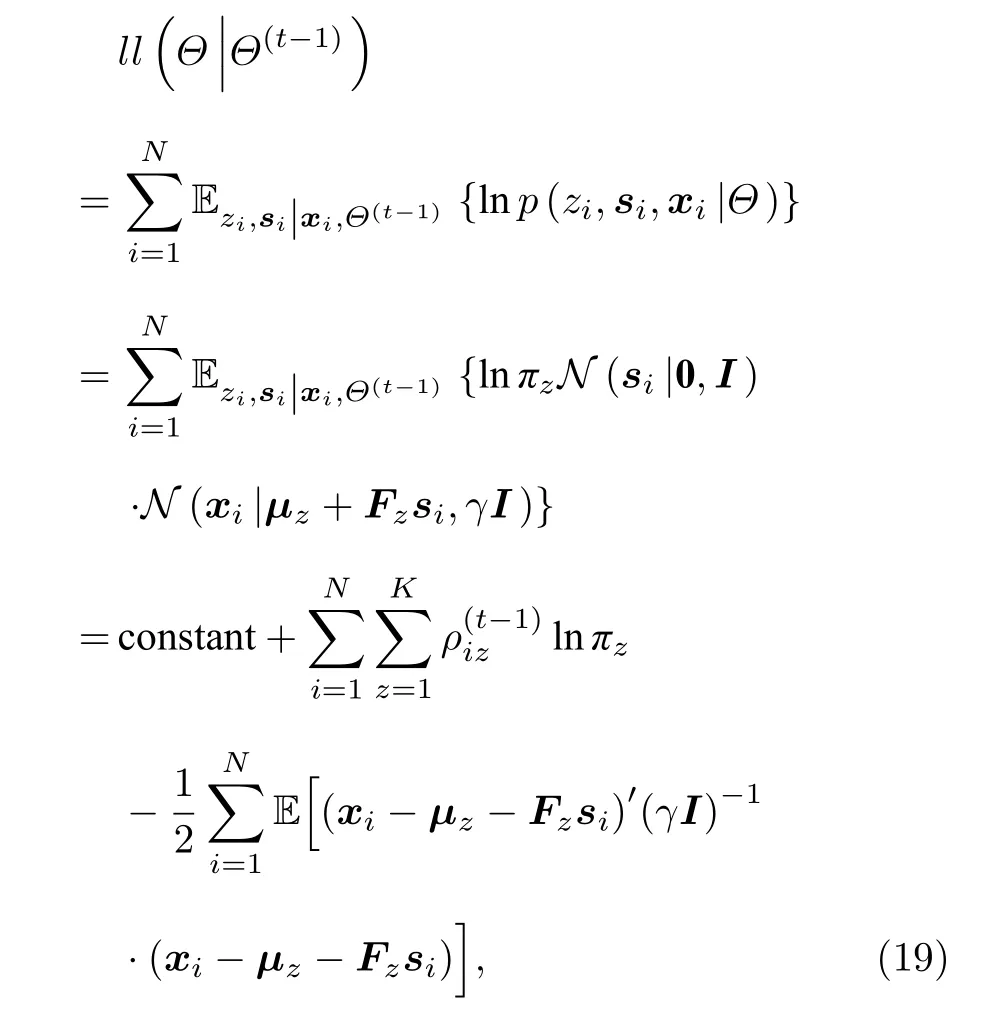
从直观上看,接下来可以直接推导(19)式最后一行的期望,从而完成整个期望的计算.但在卷积运算转化为乘积运算的过程中大的卷积矩阵是由小的卷积滤波器按照循环卷积的对应关系生成的,且Fz中大部分元素都是0.所以在接下来EM算法的M-step中,本文不能直接更新Fz,而应更新滤波器在本步中需要将(19)式最后一行的Fz转化为用(或fz,因为来表示.为了使后续的结论更加具有普适性,这里将协方差矩阵γI拓展为任意矩阵Γ的一般情形.(19)式最后一行可进一步化简为
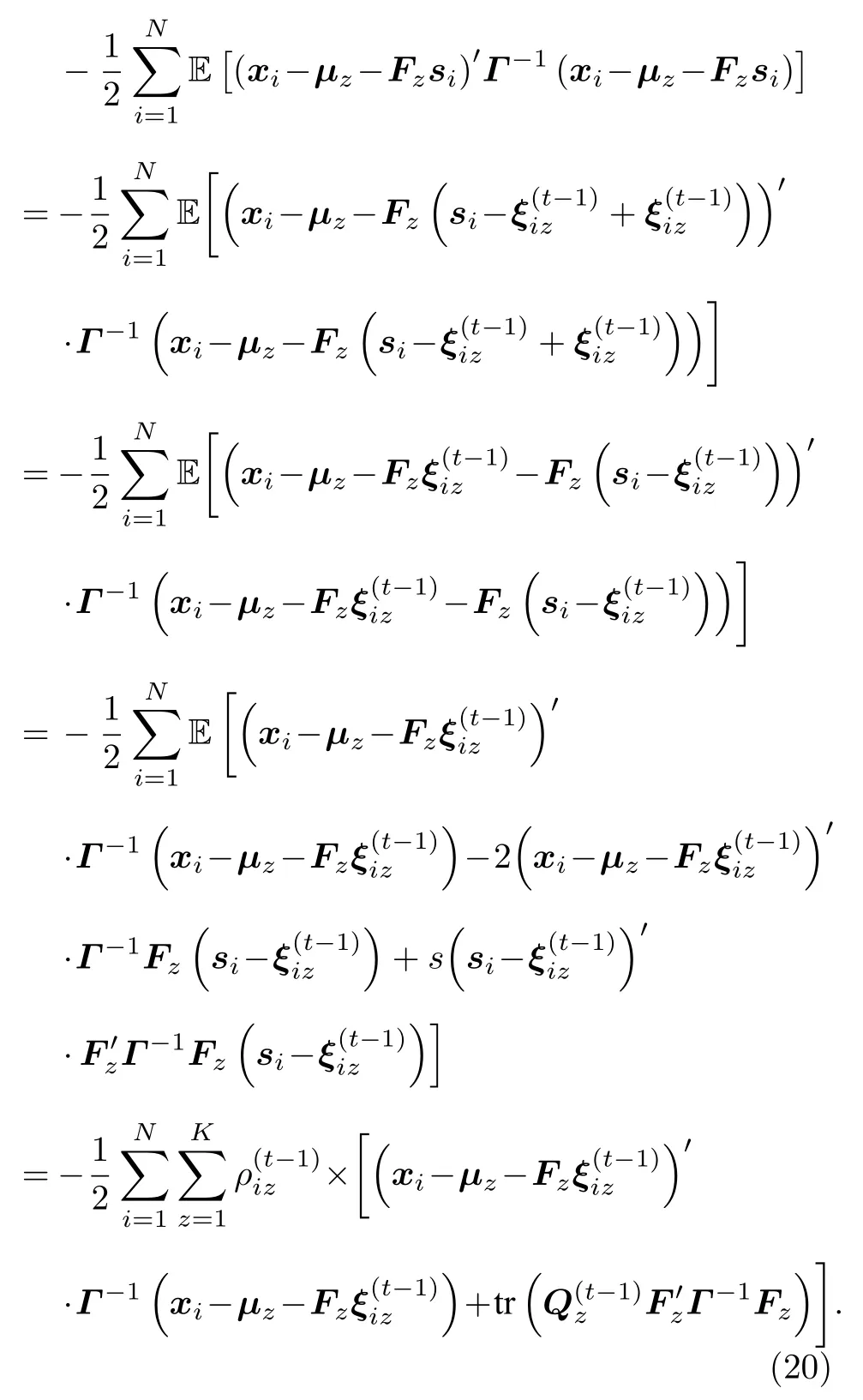


(20)式最后一行的第二项为
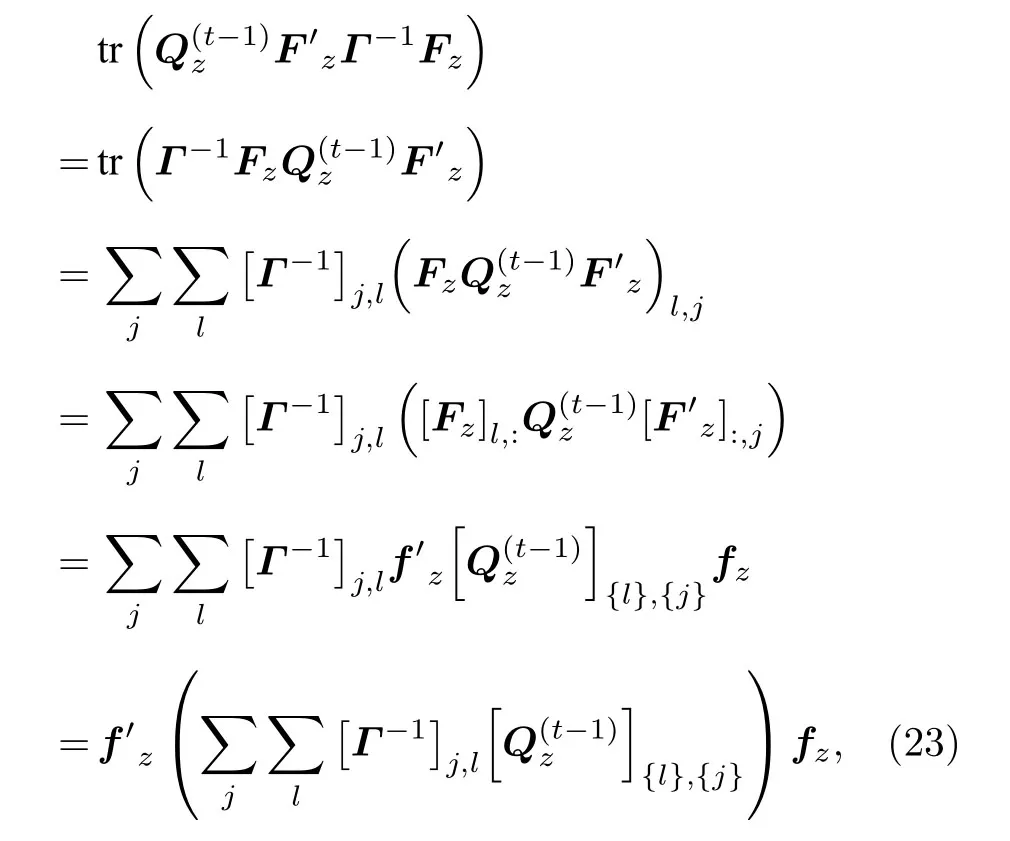
如果Γ=γI,则

将(22)和(24)式代入(19)和(20)式中,可得对数似然函数的期望为



在(12)—(14)式和(26),(27)式之间交替迭代组成了整个MMLE-convGMM算法的迭代过程.根据EM算法的性质[19],边缘似然函数将随迭代次数逐渐增加直至收敛.
4 基于convGMM的压缩测量
在压缩测量过程中,本文考虑将原图像与随机核矩阵进行循环卷积,再依据采样率对循环卷积的结果进行降采样.该过程的模型为
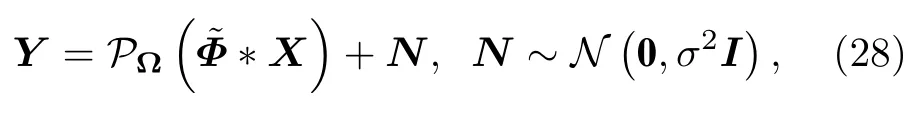

其中,PΩ是降采样算子PΩ对应的降采样矩阵,Φ是由卷积核生成的有着循环块的块循环矩阵,其结构如(7)式所示,故Φ可表示为

基于convGMM的压缩测量如图1所示,本文的目标是基于极大后验估计,从压缩测量结果y中恢复原信号x.
(z,s,x,y)的联合分布为
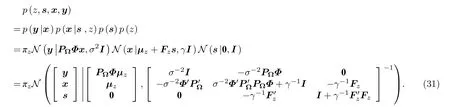
根据贝叶斯理论,(z,s,x,y)的联合分布还可写为

其中的参数满足

化简可得

图1 基于convGMM的压缩测量Fig.1.Structure of convGMM with application to compressive sensing.

从(32)式的最后一行可得y的边缘分布

以及给定y时,(z,s,x)的后验分布

其中,

由(43)式可得信号x的后验分布为
可以看出信号x的后验分布也是一个GMM,各高斯分布的期望、协方差矩阵和权重都与压缩测量结果以及未知参数有关.


由此可得信号x后验分布的期望恰好是最小均方误差(minimum mean square error,MMSE)意义下的估计[20],即

5 计算复杂度分析
由于本文所提的convGMM对整幅图像的概率分布进行建模,因而存在矩阵维数大,计算复杂的问题,为了提高MMLE-convGMM算法运算的效率,本文做了如下两个重要的降低计算复杂度的工作.
1)在convGMM中采用循环卷积((2)和(3)式),因而循环卷积运算可以利用有着循环块的块循环矩阵的数学性质,基于(8)式中的一次2D-IFFTs、两次2D-FFTs和频域上简单的分量式运算实现快速运算.计算复杂度从减小到
更重要的是,在第3节convGMM模型的训练中,(12)—(14)式中参数的计算,以及第4节从压缩测量结果y中恢复原信号x,(48)式中参数的计算,均可利用(8)式中的2D-FFTs和2D-IFFTs实现快速运算.
2)在MMLE-convGMM算法的迭代过程中,(27)式中矩阵求逆的计算复杂度较大.令

其中,


为了降低矩阵A求逆的复杂度,本文考虑分块矩阵求逆

其中,

再根据Woodbury矩阵恒等式,将矩阵M化简为

6 仿真结果及分析
本节将在三个标准数据集上验证MMLE-convGMM算法的有效性.此外,还与其他的压缩感知算法相比较,包括基于GMM的MMLEGMM算法[6],贪婪算法中的正交匹配追踪算法(orthogonal matching pursuit,OMP)[21],凸优化算法中的YALL1算法[22]以及通过极小化l2,1范数求解群基追踪(group basis pursuit)问题的广义交替投影(generalized alternating projection,GAP)算法[23].每一种算法的恢复性能通过峰值信噪比(peak signal to noise ratio,PSNR)来评价.对于OMP,YALL1和GAP,这里选取离散余弦变换(discrete cosine transform,DCT)矩阵作为稀疏基,记为“DCT-OMP”,“DCT- YALL1”和“DCT-GAP”.此外,文献[24]还提供了KSVDYALL1算法用于整幅图像的恢复,该算法首先利用KSVD算法在图像块上学习稀疏表示的字典,再将图像块上学习的稀疏字典构建出整幅图像的稀疏字典,因此本文也增加了KSVD-YALL1算法作为比较.
6.1 CIFAR-10数据集
首先在CIFAR-10数据集[25]上验证MMLE-convGMM算法的有效性.CIFAR-10数据集是由10类 32×32 大小的自然图像组成的数据集,每一类图像有60000张,其中50000张训练图像、10000张测试图像.这里随机从中选取了3000张图像(每一类图像约300张)并将其转化为灰度图像用于压缩感知.基于第4节的压缩测量方法,首先将每张图像与高斯核矩阵做循环卷积,再对卷积的结果进行降采样.采样率(sampling rate)定义为压缩采样数m与图像的像素n之比,这里设定采样率从0.05增加到0.4,增加的步长为0.05,即m/n∈{0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4}.压缩测量噪声的标准差设为σ=10−4.
图2给出了在CIFAR-10图像中,不同压缩感知算法恢复出图像的PSNR随采样率的变化情况,可以看出MMLE-convGMM明显优于传统的压缩感知算法,MMLE-GMM算法的性能次之.DCTYALL1与DCT-GAP两大类凸优化算法的恢复性能相当.贪婪算法DCT-OMP的计算速度较快,但其恢复性能比凸优化算法要差.
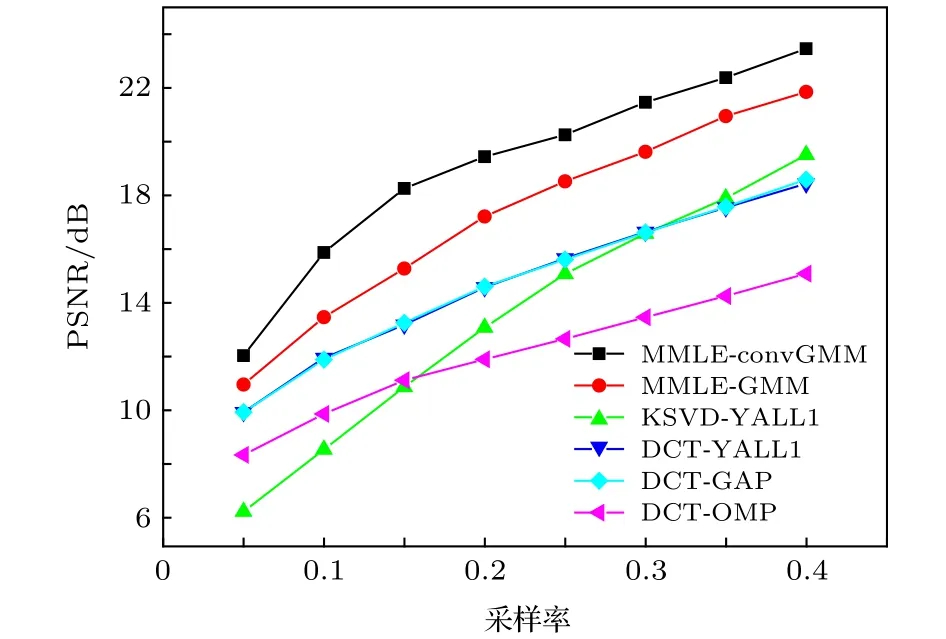
图2 CIFAR-10图像,不同算法下恢复图像的PSNR随采样率的变化Fig.2.Averaged PSNR of reconstructed images from CIFAR-10 dataset as a function of sampling rate.
6.2 Caltech 101数据集
为了进一步在大一些的图像数据集上测试MMLE-convGMM算法的有效性,本节选取Caltech 101数据集[26].Caltech 101数据集由101类自然图像所组成,每一类图像有40—800张,且每一张图像的大小约为 300×200.这里选取其中“飞机”图像,共800张.首先将它们转化为灰度图像,再将其统一成 128×128 的像素.所有其他的设置,包括采样率、测量矩阵、噪声水平同CIFAR-10数据集的仿真.图3是不同压缩感知算法的恢复PSNR随着采样率的变化情况.此外,在图4中展示了随机选取的12张Caltech 101“飞机”图像在不同算法下的恢复情况,采样率设定为0.4.
由图3和图4可以看出,类似于CIFAR-10的仿真结果,MMLE-convGMM算法明显优于其他的压缩感知恢复算法,且在采样率为0.4时,恢复图像的PSNR达到了28 dB.
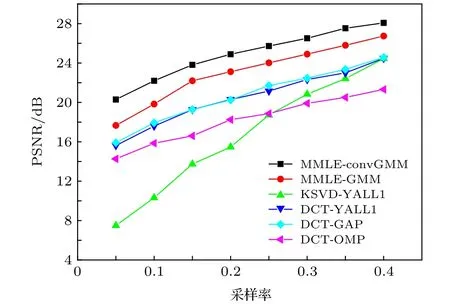
图3 Caltech 101图像,不同算法下恢复图像的PSNR随采样率的变化Fig.3.Averaged PSNR of reconstructed images from Caltech 101 dataset as a function of sampling rate.

图4 采样率为0.4时,12张Caltech 101“飞机”图像在不同算法下的恢复情况 (a)原图像; (b) MMLE-convGMM下的恢复图像; (c) MMLE-GMM下的恢复图像; (d) KSVD-YALL1下的恢复图像; (e) DCT-YALL1下的恢复图像; (f) DCT-GAP下的恢复图像; (g) DCT-OMP下的恢复图像Fig.4.Reconstructed performance comparison of 12 randomly selected “airplane” images from Caltech 101: (a) Original images;(b) images reconstructed by MMLE-convGMM; (c) images reconstructed by MLE-GMM; (d) images reconstructed by KSVDYALL1; (e) images reconstructed by DCT-YALL1; (f) images reconstructed by DCT-GAP; (g) images reconstructed by DCT-OMP.All of the sampling rates are 0.4.
6.3 CelebA数据集
最后在含有更大图像的CelebA (Large-scale CelebFaces Attributes)数据集[27]上验证MMLE-convGMM算法的有效性.CelebA数据集含有超过200000张的名人图像,每幅图像有40个属性注释.该数据集中的图像包含了各种人物的姿势和背景.这里将图像统一为 256×256 的像素.图5是CelebA图像的恢复PSNR随着采样率的变化情况.图6展示了随机选取的CelebA图像的恢复情况,采样率设定为0.4,可以看出MMLE-convGMM算法在大图像数据集上有着很好的恢复效果.当采样率为0.4时,恢复图像的PSNR为30 dB.

图5 MMLE-convGMM算法恢复CelebA图像的PSNR随采样率的变化Fig.5.Averaged PSNR of reconstructed images from CelebA dataset as a function of sampling rate by MMLE-convGMM.

图6 随机选取的CelebA图像的恢复情形 (a)原图像; (b) MMLE-convGMM算法恢复的图像,采样率为0.4Fig.6.Reconstructed performance of randomly selected CelebA face images: (a) Original images; (b) images reconstructed by MMLE-convGMM.The sampling rates are 0.4.
7 结 论
本文提出了convGMM对整幅图像的概率分布进行建模,该模型不仅利用了解卷积神经网络的思想,对于整幅图像先验分布的建模具有非常好的效果,而且兼具GMM的灵活性.对于convGMM中未知参数的学习,本文提出了通过EM算法求解MMLE.基于后验分布的期望从压缩测量结果中估计原信号,且该估计是最小均方误差意义下的估计.为解决对整幅图像直接进行计算时的维数较大、计算复杂度较高的问题,在convGMM和压缩测量模型中都使用了循环卷积,所有的训练和恢复过程都可以利用2D-FFTs实现快速运算.仿真实验表明,本文所提的MMLE-convGMM算法明显优于传统的压缩感知算法.
