基于卷积神经网络的GFW加速调度算法
2019-10-08宋铁
宋铁


摘 要: 神经网络的广泛应用使得人们更加关注神经网络的训练,更高精度的要求给神经网络的训练带来了困难,因此加速神经网络的训练成为了研究的重点。对于神经网络的训练中卷积层占据了大部分的训练时间,所以加速卷积层的训练成为了加速神经网络的关键。本文提出了GFW加速调度算法,GFW算法通过对不同卷积图像的大小和卷积核的数量调用不同的卷积算法,以达到整体的最佳训练效果。实验中具体分析了9层卷积网络的加速训练,实验结果显示,相比于GEMM卷积算法,GFW算法实现了2.901倍的加速,相比于FFT算法GFW算法实现了1.467 倍的加速,相比于Winograd算法,GFW算法实现了1.318 倍的加速。
关键词: 卷积神经网络;GEMM;FFT;Winograd算法;GFW调度算法
【Abstract】: The wide application of neural networks makes people pay more attention to the training of neural networks. The requirement of higher precision brings difficulties to the training of neural networks. Therefore, the training of accelerated neural networks has become the focus of research. For the training of neural networks, the convolutional layer occupies most of the training time, so the training of the accelerated convolution network becomes the key to accelerate the neural network. In this paper, the GFW accelerated scheduling algorithm is proposed. The GFW algorithm calls different convolution algorithms on the size of different convolution images and the number of convolution kernels to achieve the overall optimal training effect. In the experiment, the acceleration training of the 9-layer convolutional network is analyzed in detail. The experimental results show that compared with the GEMM convolution algorithm, the GFW algorithm achieves 2.901 times acceleration; compared with the FFT algorithm, the GFW algorithm achieves 1.467 times acceleration; Compared to the Winograd algorithm, the GFW algorithm achieves a 1.318x acceleration.
【Key words】: Convolutional neural network; GEMM; FFT; Winograd algorithm; GFW scheduling algorithm
0 引言
自從深度学习被提出后,便迅速成为了研究的热点。深度神经网络的应用使得图像分类,语音识别和语言翻译等领域取得了很大的进步,并且在很多方面已经超过了人类的识别能力。卷积神经网络在图像和视频识别,推荐系统和自然语言处理等领域取得了较好的效果,在本文中主要研究了卷积网络训练与加速。
许多算法都被提出用以加速卷积神经网络的训练,但是每个算法都有各自的优点和缺点,并且没有一个算法可以处理所有情形的问题。在本文中,我们在GPU环境下测试了不同算法对卷积神经网络的加速性能。根据各个算法的特点和适合不同的卷积输入图像的大小以及卷积核数量,我们对卷积神经网络中不同的卷积层使用不用的调度策略以达到对整个神经网络的最佳训练效果。
1 相关研究
从卷积神经网络被引入到公众中以来,有很多的研究都在研究卷积神经网络的计算与加速,但很少的研究关注卷积算法之间的不同,评估卷积算法的最佳方法是实验对比不同算法之间的性能差异。Mathieu等人[1-2]实验得出了FFT算法的性能。Chetlur等人比较了隐式GEMM,显式GEMM和直接卷积算法之间的性能差异的工作[3]。Lavin等人分析了Winograd算法与GEMM和FFT算法相比的优势[4]。然而,通过这些年的发展,GPU环境中的算法实现已经变得多样化。例如,GEMM算法有三种实现方式。虽然这些实现方式执行相同的算法,但它们的性能完全不同,因此也需要对这些卷积实现算法重新进行实验评估。
有许多研究比较了不同DNN框架的性能,如文献[5]和[6]。有相关的工作研究了使用GPU在CUDA平台上并行训练神经网络。Pendlebury等人[7]提出了在NVIDIA CUDA平台上使用神经网络的并行加速程序,相比于CPU其性能提升了80%。Honghoon Jang 等人[8]在多核的CPU和GPU上实现了基于神经网路的文本检测系统。这相比于CPU上执行快15倍,相比于OpenMp的GPU执行快了4倍。相关的神经网络并行加速库被开发用于加速神经的并行训练,如cuDNN和cuFFT等。并且被广泛应用于神经网络的加速训练中。
本文的工作主要是实验分析了卷积算法GEMM、FFT和Winograd,分析卷积算法对于不同维度大小的输入图像以及卷积核的数量对卷积网络的计算效率。据此本文提出了GFW加速算法,主要根据卷积网络中不同大小的卷积特征图和卷积核的数量调用不同的卷积算法,实现整个神经网络的最佳训练效果。
2 GFW加速调度算法
2.1 GEMM
。
2.4 GFW调度算法
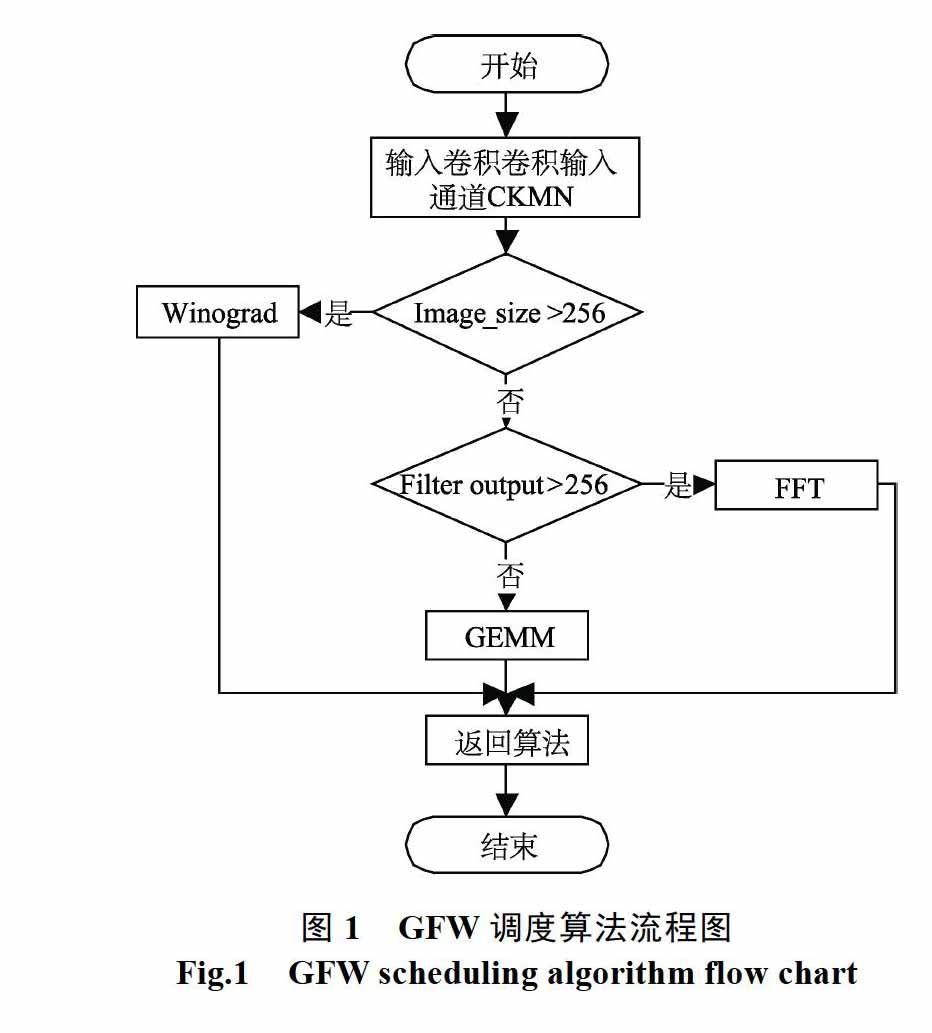
对于神经网络的加速训练过程中,通过卷积计算和池化层后,卷积层的输入特征图维度大小不断地减小,卷积核的数量也随着卷积层的变化而变化。对于不同维度的特征图和卷积核的数量适合不同的卷积算法,同一个神经网络使用一个卷积算法计算会造成内存和计算资源的浪费,这样并不能达到神经网络整体的最佳训练性能。对此,本文提出了GFW加速调度算法,GFW调度算法的思想是对不同的卷积层输入特征图维度大小卷积核的数量调度不同的卷积算法,实现每一层卷积层的最佳训练,从而提高整个神经网络的训练性能。GFW调度算法是在GEMM、FFT和Winogd卷积算法中根据特征图维度大小和卷积核的数量来调用相应的卷积算法,实现最佳的训练性能。如图1给出了GFW加速调度算法的流程图,图中Image_size为输入图像的大小,Filter output为卷积核的数量,GFW是根据这两个参数来调度相应的卷积算法,实现神经网络的最佳训练效果。
3 实验结果与分析
本实验完成对神经网络的加速实验,主要在同一实验平台上分别对卷积层的不同的卷积算法进行了加速实验。实验中使用的神经网络结构具有九层卷积层,分别使用GEMM、FFT和Winograd卷积算法对神经网络进行加速实验,并且与GFW加速调度算法进行了加速对比。实验中对神经网络结构中的每一层卷积层进行了四种卷积算法的加速实验,从实验中每一层中各个算法的执行时间可以具体分析出GFW加速调度算法的调度策略。最后,分析了每个卷积算法对整个神经网络的加速时间以及GFW加速调度算法相比其它卷积算法的加速比。
3.1 实验分析
实验中对具有九层卷积层的神经网络结构,卷积网络是由卷积层和池化层组成,输入图像经过每一层的卷积和池化层后得到的特征图都会减小,在不同卷积层的输入特征图的维度都是不同的。实验中使用的硬件平台是NVIDIA GeForce GTX1080Ti GPU,其具有11GB的显存,使用了CUDA 9.0版本对GPU计算资源进行管理。实验中分别测试了神经网络每一层在四种卷积算法下的执行时间,并且分析了每个卷积算法对神经网络的加速效率。
3.2 实验结果
实验中首先分析了GEMM、FFT和Winograd卷积算法以及DFW加速调度算法在对九层神经网络结构的加速效果。在每一层卷积层后接着池化层,输出的特征映射图都会相比输入图片减小一半,这样神经网络结构中的不同卷积层的输入图像维度大小不同。图2给出了GEMM、FFT和Winograd卷积算法对神经网络中每一层的执行时间的变化以及GFW加速调度算法对神经网络每一层的执行效率。从图中分析可知由于每一层卷积层的输入图像维度不同,因此每一层的执行时间会随着输入特征图的减小而减小。从图中可以发现,对于GEMM、FFT和Winograd卷积算法对于神经网络卷积层的计算时间都随着输入特征图维度的减小而减小,但对于不同维度大小的输入特征图,三个卷积算法的计算时间是不同的。图中黄色曲线是GFW加速调度算法在加速神经网络中每一层的时间曲线,从图中可以分析出GFW加速調度算法始终在三条曲线的最下面,这也证明了GFW加速调度算法在对神经网络进行训练时,在对每一层进行计算时都会调用三个算法中计算时间最短的算法,这样可以使得神经网络的整体训练时间最小,实现神经网络的加速 训练。
从图2分析中可知对于不同维度的输入特征图,卷积层的计算时间是不同的,并且对于相同维度输入特征图,使用不同的卷积计算算法所需要的时间也是不同的。图3分析了神经网络中九层卷积层使用三种不同卷积算法的执行时间,以及GFW加速调度算法加速卷积计算的执行时间。为了便于分析与观察,实验中将GFW对卷积层的计算时间进行了归一化处理,这样可以清晰的分析出在不同的卷积层中GFW加速调度算法相对于其它卷积算法的加速比以及GFW的调度策略。图中显示Winograd卷积算法适合于维度较大的输入特征图,而GEMM算法则比较适合维度较小的输入特征图,FFT卷积算法适合于输入特征图维度居中的卷积计算。GFW则是根据神经网络卷积层的输入特征图维度大小以及卷积核的数量来调度不同的加速算法,实现神经网络最佳的加速效果。
图3中具体分析了神经网络中每一层卷积层使用不同卷积算法的计算效率以及加速比,并分析了GFW加速调度算法的调度策略。GFW加速调度算法实现每一层卷积层的调度加速从而实现了整个神经网络的加速训练,图4中给出了几种卷积算法对整个神经网络的加速效率。图中的三幅对比图中分别展现了几种卷积算法的计算效率,使用FFT实现卷积计算加速神经网络相比于使用GEMM实验卷积计算对神经网络的训练性能提升了49.4%;使用Winograd算法实现卷积计算加速神经网络训练相比于使用FFT实验卷积计算对神经网络的训练性能提升了10.2%;本文提出的GFW加速调度算法对于神经网络的加速训练中,相比于目前加速效率最高的Winograd算法,在对神经网络的加速训练中性能提升了24.1%。
图5中直观的展示了本文提出的GFW加速调度算法相比于GEMM、FFT和Winograd算法对神经网络的加速比。在对本文具有九层卷积层的神经网络结构进行加速实验时,GFW加速调度算法是根据卷积层中输入特征图的大小以及卷积核的数量进行调度的加速算法,因此,在对神经网络训练时加速性能较高。相比于GEMM卷积算法加速GFW调度算法取得了2.901倍的加速,相比于FFT实现卷积计算对神经网络的加速GFW调度算法取得了1.467的加速,相比于Winograd算法实现卷积计算,GFW调度算法对神经网络的训练实现了1.318倍的加速。
4 结束语
神经网络中的卷积计算占据着神经网路的大部分训练时间,因此,加速卷积计算的效率是加速神经网络训练的关键。本文针对卷积计算提出了GFW加速调度算法,针对神经网络中不同卷积层的输入特征图的大小和卷积核的数量调度相应的卷积算法,实现整个神经网络的最佳训练性能。实验结果显示,GFW加速调度算法在对神经网络的加速训练中,相比于GEMM卷积算法实现了2.901倍的加速,相比于使用FFT实现卷积计算对神经网络的训练,GFW调度算法实现了1.467倍的加速,相比于对卷积网络计算效率较高的Winograd算法,GFW调度算法在加速神经网络训练中实现了1.318倍的加速。
参考文献
[1]Chen T, Li M, Li Y, et al. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems[J]. arXiv preprint arXiv: 1512. 01274, 2015.
[2]Vasilache N, Johnson J, Mathieu M, et al. Fast convolutional nets with fbfft: A GPU performance evaluation[J]. arXiv preprint arXiv: 1412. 7580, 2014.
[3]Chetlur S, Woolley C, Vandermersch P, et al. cudnn: Efficient primitives for deep learning[J]. arXiv preprint arXiv: 1410. 0759, 2014.
[4]Lavin A, Gray S. Fast algorithms for convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4013-4021.
[5]Li X, Zhang G, Huang H H, et al. Performance analysis of gpu-based convolutional neural networks[C]//2016 45th International Conference on Parallel Processing (ICPP). IEEE, 2016: 67-76.
[6]Kim H, Nam H, Jung W, et al. Performance analysis of CNN frameworks for GPUs[C]//2017 IEEE International Sympo sium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2017: 55-64.
[7]Pendlebury J, Xiong H, Walshe R. Artificial neural network simulation on CUDA[C]//Distributed Simulation and Real Time Applications (DS-RT), 2012 IEEE/ACM 16th Interna tional Symposium on. IEEE, 2012: 228-233.
[8]Jang, Honghoon, Anjin Park, and Keechul Jung. "Neural network implementation using cuda and openmp. " Digital Image Computing: Techniques and Applications. IEEE, 2008.
[9]Xu, Rui, et al. "Accelerating CNNs Using Optimized Sche du ling Strategy. " International Conference on Algorithms and Architectures for Parallel Processing. Springer, Cham, 2018.
[10]Lu W, Yan G, Li J, et al. Flexflow: A flexible dataflow accelerator architecture for convolutional neural networ ks[C]//2017 IEEE International Symposium on High Perfor mance Computer Architecture (HPCA). IEEE, 2017: 553- 564.
[11]Hill P, Jain A, Hill M, et al. Deftnn: Addressing bottlenecks for dnn execution on gpus via synapse vector elimination and near-compute data fission[C]//Proceedings of the 50th Ann ual IEEE/ACM International Symposium on Microarchite cture. ACM, 2017: 786-799.
[12]Song L, Wang Y, Han Y, et al. C-brain: A deep learning accelerator that tames the diversity of cnns through adaptive data-level parallelization[C]//2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC). IEEE, 2016: 1-6.
[13]Lin, Yu-Sheng, Wei-Chao Chen, and Shao-Yi Chien. "Unro lled memory inner-products: An abstract GPU operator for efficient vision-related computations. " Proceedings of the IEEE International Conference on Computer Vision. 2017.
[14]盧冶, 陈瑶, 李涛, 等. 面向边缘计算的嵌入式FPGA卷积神经网络构建方法[J]. 计算机研究与发展, 2018, 55(03): 551-562.
[15]李景军, 张宸, 曹强. 面向训练阶段的神经网络性能分析[J]. 计算机科学与探索, 2018, 12(10): 1645-1657.