基于TF-IDF及LSI模型的主观题自动评分系统研究
2019-10-08周洲侯开虎姚洪发
周洲 侯开虎 姚洪发
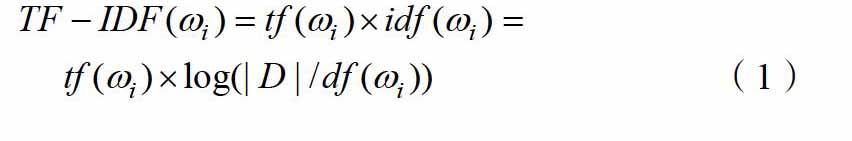
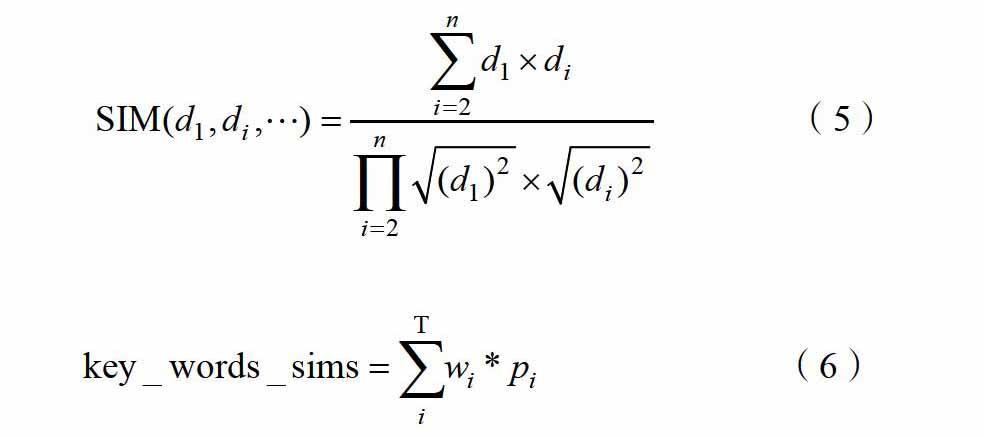
摘 要: 随着计算机辅助教学,多媒体处理以及计算机网络技术的发展与成熟,目前已经有许多考试都采用无纸化考试,即机考的形式进行。采取电子化考试的优点在于考试可监控性强,考试效率高,考试标准化和程序化。并且对于选择题判断题这样的客观题自动化批改技术已经十分成熟,极大的缩减了改卷时间,提高了改卷效率。但是,由于受到自然语言理解的限制,至今没有比较完善的主观题自动批改系统对主观题进行批改和评分。本文采用TF-IDF及LSI两种模型作为文本分析模型,使用jieba中文分词工具进行文本预处理,使用Python语言实现该系统。通过考生答案与标准答案的语义相似度分析,对考生作答的主观题进行批改和评分。之后随机抽取5份大学考试中的考生试卷,使用该主观题自动评分系统进行测试,与改卷老师所给出的评分进行对比分析和说明。实验结果表明,本文所提出的主观题自动评分系统在一般情况下可以满足主观题自动评分的功能,是一种值得继续深入研究的可行方法。
关键词: 无纸化考试;主观题;自动评分;Python;TF-IDF;LSI
【Abstract】: With the development and maturity of computer aided instruction, multimedia processing and computer network technology, many examinations have been conducted in the form of paperless tests, that is, computer tests. The advantage of electronic examination is that it can be monitored well, the efficiency of examination is high, the examination is standardized and programmed. And for the multiple choice judgment questions such as automatic marking technology has been very mature, greatly reduced the time to correct the paper, improve the efficiency of paper correction. However, due to the limitation of natural language understanding, there is no perfect automatic subjective question marking system. In this paper, TF-IDF and LSI models are used as text analysis models, jieba Chinese word segmentation tools are used for text preprocessing, and Python language is used to implement the system. By analyzing the semantic similarity between the test answers and the standard answers, the subjective questions are corrected and graded. Then 5 college examination papers were randomly selected and compared with the real scores of teachers. The experimental results show that the automatic scoring system of subjective questions proposed in this paper can meet the function of automatic scoring of subjective questions under general circumstances and is a feasible method worthy of further study.
【Key words】: Paperless test; Subjective questions; Automatic scoring; Python; TF-IDF; LSI
0 引言
主观题自动评分系统,是指使计算机能够“理解”人类自然语言,在此基础上,对自然语言构成的句子,段落进行评价,评分的系统。虽然近几年人工智能、大数据等技术日益成熟,但是国内应用计算机技术进行的考试还停留在只有选择题可以进行自动评分的程度,对于填空、简答、论述等题目尚未出现比较实用可靠的自动评分技术,而在一般情况下,批改试卷的老师往往需要在极短的时间下对一份试卷中的一个或几个题目进行打分。因此在试卷数量多达成千上万份的时候,不仅会使得人工评分因为评分老师的主观因素(包括情绪,生理等方面)的影响,造成评分的误差和不公平性。基于以上问题,研究如何通过利用现有的计算机技术,对填空、简答等主观类型的问题实现自动评分,是一个值得我们研究的问题。
早在20世纪60年代,世界上第一个自动评分系统PEG(Project Essay Grader)被研发出来,用于作文评分。之后,IEA,IntelliMetric,E-rater,BETSY等作文评分系统被提出,并且都投入到了实际使 用中[1]。
近幾年来,对于主观题自动评分技术的研究主要集中在考生答案与标准答案之间的相似度比较上。如南铉国通过提出新的相似度计算公式,实现考生答案与标准答案之间的比较,设定得分阀值。从而自动得出评分[2]。吴巧玲采用改进的匈牙利算法完成考生答案与标准答案之间的语义相似度计算,从而实现自动评分[3]。袁军使用计算字符串之间的单向贴近度方法对考生答案与标准答案进行对比,从而实现自动评分[4]。查卫亮使用最大正向匹配法将考生答案的句子切分然后与标准答案进行比较,从而自动得出评分[5]。
以上不同系统所使用的算法都各有优势,比如南铉国通过提出新的相似度计算公式所设计的自动评分系统把基于词表面信息的相似度和基于语义信息的相似度计算很好的结合在了一起,充分发挥了采用词性和词义方法的长处。而查卫亮使用的基于最大正向匹配法所设计的系统可以根据调整相似度阀值得到最优的评分结果。当然,各个系统也存在一定的局限性和不足之处需要改进和完善。
本文通过对前人研究结果的学习总结,提出一种基于TF-IDF与LSI模型的主观题自动评分系统。使用Python工具实现该系统,其中界面部分使用PyQt5进行设计,分词部分选择jieba中文分词技术,设计出适合的主观题自动评分系统。
首先,使用jieba中文分词工具将待测文本进行分词,再通过关键词和核心词抽取模型、使用TF-IDF及LSI模型对待测文本与标准文本之间进行相似度度量计算,最后将之前通过模型计算得到的文本相似度与该题分值相乘得到待测文本的最后得分。
1 Jieba分词技术
jieba分词一开始是国外比较常见的一种英语分词技术,因其原理较容易理解,分词效果适用于一般情况。因此随后被开发成可以进行中文分词的技术。jieba分词技术目前支持3种分词模式:精确分词模式、全分词模式和搜索引擎分词模式。精确分词模式适合拆分单句,比较适用于文本分析;全分词模式可以把文本中所有可能成为词的词语都扫描出来,速度快,但是会出现歧义词的问题;搜索引擎分词模式是在精确分词模式的基础上对长词再次进行切分,相对于精确分词模式,区别在于提高了召回率,适用于搜索引擎模式。
2 TF-IDF及LSI模型相似度计算
2.1 TF-IDF模型
TF-IDF模型是文本相似度度量方法中最具有代表性的方法之一,TF-IDF方法一开始应用于信息检索领域,随着数据挖掘的发展,现在也经常应用于文本数据挖掘中。一般情况下来说,文本在计算机中的表示是将其转化为文本向量,从而实现将无法量化的文本转化为可量化计算指标的问题。而文本向量的计算则是由在文本中出现(标注)的N个加权词项所计算得来的。而TF-IDF模型是建立在这样一个假设上提出的:如果一个词或字与文本主题的相关性越强,那么该词在这个文本中出现的频率就会越高,因此在数量上就会显示出其重要性,所以词与文本主题两者之间的关系成正相关,这种关系就将其称作词频(Term Frequency,简称TF)。如果某个词或字在语料库中出现的频率越大,那么就说明它们的区分能力越差,两者成负相关,这种关系就将其称作逆文本频率(Inverse Document Frequency,简称IDF)。通过上述基本思想得出计算某一个词项TF-IDF的值,通常情况下会采用公式(1)及(2)。
2.2 LSI模型
LSI是基于文档和词共现关系以及奇异值分解(SVD)方法来得到文本主题的一种模型,LSI的基本原理是利用矩阵的奇异值分解,把高维空间中
的词和文档向量投影到更低维的空间使之降维并更易于得到两者之间的关系,将在高维空间中没有关系的文本(高维度文本向量不重合),在没有相同的词的情况下也可以用同样的向量进行表达。LSI模型主要有3個步骤:
(1)模型构建与优化
LSI模型首先需要用词-文档矩阵(Term- Document Matrix)来表示整个文本库,词-文档矩阵是指由不同词在不同文本中的数量构成的矩阵。在中,m表示文本库中不同词的数量,中的每一行对应一个词;n表示文本库中的文本总数量,中的每一列则对应一个文本。则根据以上定义,矩阵中的某个元素就表示第i个词在第j个文本中出现的次数。但是因为的数量级可能会很大,也有可能为“0”,所以并不能采用的原始值,需要对其进行优化以后,再采用其值。对于优化值,本文使用局部权值计算函数和全局权值计算函数的乘积来表示。
3 主观题自动评分系统设计
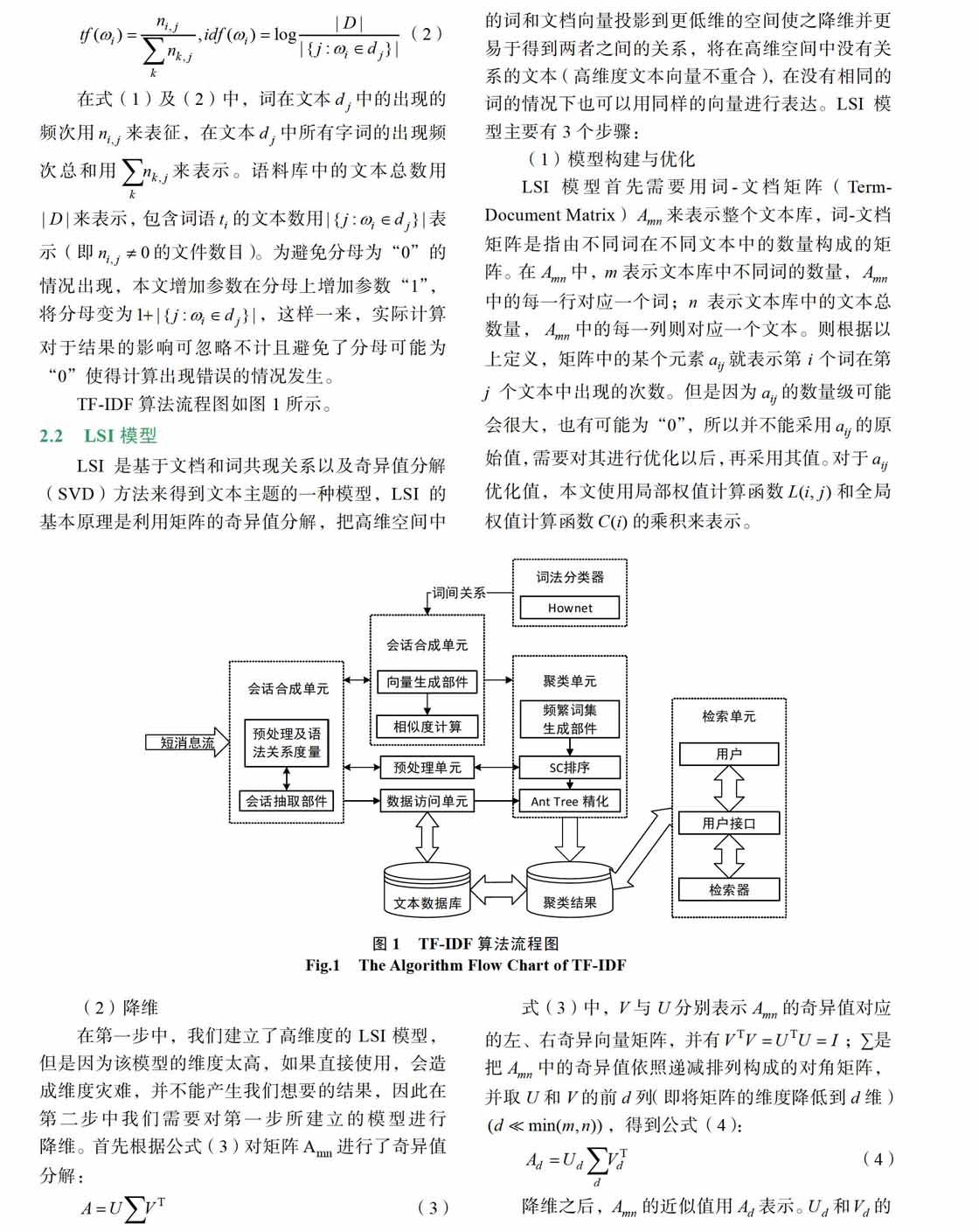
本文分三个阶段对基于TF-IDF模型及LSI模型的主观题自动评分系统进行设计,各个阶段的内容归纳并为3个模块,分别是输入模块、文本处理模块、输出模块,如图2所示。
系统的输入部分由题目分值、标准答案文本、模型权重、关键词权重、核心词权重与待检测文本构成,在输入部分,首先需要对模型的权重参数进行设置,然后再根据实际情况和需要设置所有关键词与核心词的权重值,但是在设置时每个关键词或核心词的权重之和必须为1。
而在文本处理部分由分词算法、关键词抽取、核心词抽取、关键词相似度计算。核心词相似度计算。词语相似度计算与句子相似度计算构成。通过jieba分词之后,待处理文本去除掉停用词,包括标点符号、数量词、代词、助词和介词等。
在输出部分,通过模型进行标准答案与待测文本的文本相似度计算,所得到的文本相似度值取整并与本题总分值相乘就可以输出本题得分了。系统中还加入了一个小功能,即当待测文本与标准答案之间的相似度达到95%以上时,计算结果会变为红色并提示“疑似作弊”。
4 实验结果及分析
在完成基于TF-IDF及LSI的主观题自动评分系统后,为更好地测试该系统的评分性能。从某学科考试的试题中随机抽取5个主观类型的题目,最后抽取了2个名词解释题,5分一题,共10分;3个简答题,第一题8分、第二题10分、第三题10分。再从学习过该门课程的学生中随机抽取30名学生,采用标准考试的方式作答抽取到的题目,完成之后由授课老师对30名学生的答案进行打分。
在30名学生的答卷中随机抽取5份试卷,输入系统让系统对这5份试卷进行评分。系统的参数设置参考改卷老师的评分方式进行设置。
最后用教师评分与系统评分进行对比计算,得出两种评分之间差值的绝对值,以此为依据分析自动评分系统评分结果的可靠性与误差。
4.1 评分结果
从图3、4中可以看出,TF-IDF模型的自动评分系统所计算得到的分数与教师评分的拟合度较高,与真实情况更加接近。但LSI模型的自动评分系统最后输出得到的分数与真实评分偏差较大,与真实情况存在一定的出入。实验结果说明同种参数设置和实验环境条件下,TF-IDF算法模型计算得到的评分更接近真实评分,且评分的准确率较高,因此TF-IDF相对于LSI模型是一个更优的算法模型。
5 结论
本文利用TF-IDF模型和LSI模型,通过Python程序设计语言实现了一种新的主观题自动评分系统。其次,设计了对应的验证方法和措施来证明所设计的自动评分系统的有效性。完成之后请授课老师人工评分,再与本文提出的系统计算得到的评分进行对比的实验,对本文所提出的系统进行了验证。通过对结果的对比分析,得出采用TF-IDF模型设计的自动评分系统相比采用LSI模型设计的自动评分系统更加有效真实,且准确率更高的结果。本文主要得出以下结论:
(1)本文所设计实现的主观题评分系统可以根据实际情况调整设置不同的关键词权重与模型权重。适用于不同的评分要求和情况,具有较强的泛化能力;
(2)本文分别通过TF-IDF算法模型与LSI算法模型实现了主观题自动评分,并且将两个模型算法的输出结果与真实评分进行了对比,并进行了分析说明。得到了TF-IDF模型比LSI模型得到的评分更加接近实际评分的结论;
(3)TF-IDF模型的自动评分系统所输出的评分结果与实际评分的拟合度是较高的,因此在实际应用该系统时,可以有效防止人为打分时因为心理或生理等条件的影响而错误打分的情况出现,规避了人为主观因素对于评分的影响。
6 结束语
本文提出、设计实现并分析验证了基于TF-IDF
及LSI模型的主观题自动评分系统。通过对系统的理论分析、过程说明和实验设计,说明了本文所提出的主观题自动评分系统是具有理论意义和实际使用价值的,是值得推广和继续深入研究的问题。
参考文献
王金铨, 朱周晔. 近五十年来国内外翻译自动评分系统的发展与应用[J]. 扬州大学学报(人文社会科学版), 2016, 20(02): 123-128.
吴巧玲. 主观题自动评分系统的设计与实现[J]. 数字技术与应用, 2012(01): 113-114.
袁军. 网络主观题评分系统的算法设计与实现[J]. 职业时空, 2011, 7(10): 145-146.
查卫亮. 主观题自动评分算法分析与实现[J]. 软件导刊, 2011, 10(09): 43-44.
南铉国. 基于语句相似度计算的主观题自动评分技术研究[D]. 延边大学, 2007.
Foltz P W. Using latent semantic indexing for information filtering[C]//Proc. of ACM Conference on Office Information Systems. 1990: 40-47.
鲁松, 李晓黎, 白硕. 文档中词语权重计算方法的改进[J]. 中文信息学报, 2000, 14(6): 8-13.
林鴻飞, 李业丽. 中英文双语交叉过滤的逻辑模型[J]. 计算机工程与应用, 2000, 36(8): 48-50.
林鸿飞, 高仁璟. 基于潜在语义索引的文本摘要方法[J]. 大连理工大学学报, 2001, 41(6): 744-748.
任纪生, 王作英. 一种新的潜在语义分析语言模型[J]. 高技术通讯, 2005, 15(8): 1-5.
牛伟霞, 张永奎. 潜在语义索引方法在信息过滤中的应用[J]. 计算机工程与应用, 2001, 37(9): 57-60.
高思丹, 袁春风. 主观试题的计算机自动批改技术研究[J]. 计算机应用研究, 2004, 21(2): 181-185.
李彬, 刘挺, 秦兵, 等. 基于语义依存的汉语句子相似度计算[J]. 计算机应用研究, 2003, 20(12): 15-17.
乌庆敏, 杨思春. 概念向量空间模型在智能答疑系统中的应用[J]. 安徽工业大学学报(自科版), 2008, 25(2): 193-196.
丁振国, 陈海霞. 一种基于知网的主观题阅卷算法[J]. 微电子学与计算机, 2008, 25(5): 108-109.
