基于BLSTM-CRF的领域知识点实体识别技术
2019-10-08周海华曹春萍
周海华 曹春萍

摘 要: 传统的中文分词方法是一种基于单词标注的传统机器学习方法,但学习方法需要人工配置和提取中文文本的特征。缺点是同义词库维度较高且CPU训练模型较长。本文针对以上问题进行了研究,构建了内嵌条件随机场的长短时神经网络模型,使用长短时神经网络隐含层的上下文向量作为输出层标注的特征,使用内嵌的条件随机场模型表示标注之间的约束关系采用双向 LSTM和CRF相结合的训练方法进行特定领域知识点的中文分词。对中文分词测试常用语料库的实验比较表明,基于BLSTM和CRF网络模型的方法可以获得比传统机器学习方法更好的性能;使用六字标记并添加预训练的字嵌入向量可以实现相对较好的分词性能;BLSTM-CRF网络模型方法更易于推广并应用于其他自然语言处理中的序列标注任务。
关键词: 实体识别;神经网络;BLSTM;CRF
中图分类号: TP391. 41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.02.001
【Abstract】: The traditional Chinese word segmentation method is a traditional machine learning method based on word annotation, but the learning method requires manual configuration and extraction of Chinese text features. The disadvantage is that the thesaurus has a higher dimension and the CPU training model is longer. In this paper, the above problems are studied, and the long-term and short-term neural network model of embedded conditional random field is constructed. The context vector of the hidden layer of the long-term neural network is used as the feature of the output layer annotation, and the embedded conditional random field model is used to represent the annotation. The constraint relationship between the two-way LSTM and CRF combined training methods for Chinese word segmentation of specific domain knowledge points. The experimental comparison of the common corpus of Chinese word segmentation test shows that the method based on BLSTM-CRF network model can obtain better performance than the traditional machine learning method; using six-character mark and adding pre-trained word embedding vector can achieve relatively good segmentation Performance; BLSTM-CRF network model methods are easier to generalize and apply to sequence annotation tasks in other natural language processing.
【Key words】: Entity recognition; Neural Networks; BLSTM; CRF
0 引言
互聯网应用的爆发式增长,对海量数据的分类和知识发现提出了新的要求,知识图谱在自然语言处理(Natural Language Processing, NLP)领域的作用越来越大,其中知识库就是构建知识图谱的重中之重,然而这些知识库往往缺乏一定的领域通用性,不能满足特定领域下的需求,对于一个特定领域的知识图谱,领域实体与实体关系的数量庞大,若以人力统计构建,耗时且费力,更重要的是,特定区域中的数据源并非全部是结构化的或半结构化的,并且在大多数情况下以非结构化形式存在。这也大大增加了特定领域知识的获取难度。
知识是客观事物的属性和联系的反映,是人脑中客观世界的主观形象。人的学习是以知识点为单位的,对于考生来说,时间是最为宝贵的资源,如何高效准确的找出题目中的关键知识点并加以攻克对于考生针对性复习具有重大意义。文献[1]使用正则表达式来匹配知识点的类型并扫描整个文本数据,解决了如何让计算机快速自动提取教科书中的知识点的问题;文献[2]在知识组织与管理相关理论基础上,建立知识元描述模型,提出基于知识元的向导信息提取方法和知识元标引方法;文献[3]提出将科学研究领域置于其背景学科中,并从全球视角检验该领域内外关键词的统计特征。并依此提出关键词领域度的概念和计算方法。然而上述研究大多耗时耗力,且涉及主观判断,影响实验结果。因此本文提出将神经网络模型和学科知识点提取相结合,准确而高效的获取试题中的知识点,因此,本文的研究问题可以理解为特定领域中的生命关键实体识别技术。
1 相关研究
命名实体识别是自然语言处理领域的关键任务。目前,命名实体识别主要利用有监督的机器学习方法,然而监督学习的训练数据大多来源于人工标识,样本数据缺乏且样本数据的约束性较弱,这使得难以在小样本数据上生成广义命名实体识别结果。此外,由于中文语法的特殊性,词与词之间缺少明确的分割符。中文分词领域有三种常用的手段:基于词表的方法、基于传统统计模型的方法和基于深度学习神经网络的方法。
基于词汇的分词方法有多种表现形态。刘元[4]做了一些总结性的工作,介绍了包括前向最大匹配、反向最大匹配和双向扫描在内的三种方法。基于词汇的分词方法非常依赖于词汇,在中文分词命名实体上识别效果较差。
基于传统的分词概率统计模型,自Bakeoff竞赛以来,涌现出大量相关工作论文。最常见的做法是将中文分词问题视为序列标注问题,将中文字符标记为4位标签集(B,M,E,S)之一,然后使用标记规则进行分词。彭等人或者他们的联合模型,其性能受到功能集的限制。在实际使用中,通常有太多的特征导致模型出现过度拟合的情况。
基于深度学习神经网络的分词方法,通过从源数据中自主学习,挖掘出更深层次、更抽象的文本特征。由于该特征并不是人工标识的,因此它克服了传统统计模型的局限性,在NLP任务中展现出更佳的性能。Collobert等人[7]就是利用神经网络这一天然优势,摈弃了传统的人工特征设定及提取的方式,在英文文本标注方面取得了较好效果。Zheng 等人[8]按照文献[7]中提出的思路,首次将深度学习方法运用到中文分词任务上,并用感知器算法替换原本的神经网络训练算法,加速了模型的训练过程。之后,Chen等人[9-10]提出了具有上下文记憶单元的LSTM(Long Short-Term Memory)模型用于中文分词,实现的结果可与传统的统计模型分割方法相媲美。但是单向LSTM模型只记忆上文信息,对下文信息却不予处理。中文语句结构较为复杂,而中文大意需要联系上下文方能知其大意,因此Yao等人[11]提出了双向LSTM(BLSTM)模型,大大提高了分词的准确率。2018年Jing等人[12],将双向的LSTM模型运用到中文分词任务中,并创新地引入了贡献率α,通过α对隐藏层的权重矩阵进行调节,进一步提高了分词正确率。上述大多数神经网络都是基于四字位置标注方法,不能完全表达单词中每个单词的词汇信息。尽管这些深度神经网络模型的分词方法已取得不错的效果,但为了应对日益增长的用户需求,准确率还需亟待提高。
鉴于上述问题,本文提出建立一种基于LSTM神经网络的BLSTM-CRF分词模型。通过使用六个字位置注释并添加预训练字嵌入向量来执行中文分词。通过对Bakeoff2015数据集进行的性能测试,实验结果表明在相同的分词模型下,与LSTM模型和BLSTM模型相比,BLSTM-CRF分割模型在简体中文和繁体中文中都有很好的表现。在NLP任务中更容易推广到其他序列标记问题,并具备一定程度的范化能力。
2 模型介绍
2.1 BLSTM
模型的第一层是双向LSTM层,用于自动提取语句级别的特征。LSTM循环单元模块具有不同的结构,并且有四个神经网络层以特殊方式相互作用。主要有三种门结构(忘记门,输入门,输出门)和存储单元。另外LSTM网络特性在于提出了单元细胞状态的概念。
2.2 CRF
CRF是基于概率图的统计模型。由于可以手动添加多种特征,因此可以利用更丰富的上下文信息。该模型实现了全局归一化,可以获得全局最优解,有效地解决了标记偏差问题。这种考虑状态前后影响的序列标记的处理办法与BLSTM模型利用上下文特征的思想极为相似。
在中文分词中有两种序列标注思想。第一种是根据时间顺序预测从前到后的序列标签分布,例如最大熵Markov模型。第二是从句子层面考虑标签问题。它也将受到未来状态的影响,例如线性随机场模型(CRF),如图1所示。
2.3 BLSTM-CRF
BLSTM-CRF是将BLSTM模型和CRF模型组合起来,即在BLSTM网络的输出层后加一层CRF线性层,有效地解决了传统的循环神经网络存在梯度消失或梯度爆炸问题[13],模型结构如图2所示。
模型中X表示输入层,A表示LSTM记忆单元,y表示输出层,即每个字的标注信息。该模型拥有两个相反方向的隐藏层,其运行方式与常规神经网络的运行方式相同,这两个层分别从句子的前后两端分别工作,存储来自两个方向的文本信息,结合上下文的特征,并且经由CRF层充分地考虑上下文的标签信息。从而使得BLSTM-CRF在中文分词中拥有更佳表现。
3 实验
3.1 实验环境,数据集及评价标准
(1)硬件环境及操作系统
处理器:intel@Corei7CPU@3.60GHz*8,内存:16G,GPU:TITAN X (Pascal),操作系统:Ubuntu16.04。
为了公正的评估模型的分词性能,实验采用了 SIGHAN规定的“封闭测试”原则,其评价指标有:准确率(P),召回率(R),综合指标值(F)。
(2)实现中使用的工具包
本文设计实现的高中物理学科知识点命名实体识别程序,开发语言为Python,开发过程中调用了下面的工具包。jieba-0.38。结巴分词模块可支持精确模式、全模式、搜索引擎模式三种分词方式,支持基于概率的用户词典。实验过程中使用精确模式并结合加载外部用户词典,从原文本产生分词语料。词典格式设计为一个词占一行,涵盖常用物理学上的专有名词即确定的实体边界。
3.2 实验设计及结果分析
(1)數据处理
数据处理的第一步是分割文本,然后使用word2vec进行单词矢量训练,并使用训练过的单词矢量作为神经网络模型的输入。使用LSTM等神经网络处理数据,需要对文本进行向量化处理。文本向量化的方式主要有两种:集中式表示和分布式表示[18]。集中表示将每个单词表示为非常长的向量。分布式表示的方式由低维向量表示,使得相关单词在语义上更接近,通常称为嵌入。以前的研究表明,添加预训练的单词嵌入向量可以提高自然语言处理任务的性能。
(2)实验设计
首先准备一些历年高考物理题目,通过word2vec进行单词向量训练,并使用训练过的单词向量作为BLSTM模型的输入。再将BLSTM模型的输出作为CRF层的输入。
在物理学专家指导下人工标注了100×4条实体语料,并建立字典,字典中包括实体和实体类型。 其次,利用模型生成部分实体标注语料,并设计程序自动校对,校对程序判断模型生成的语料是否与字典中的一致,包括实体和实体类型是否一致。 最后,生成深度学习模型需要的 BIO字标签形式语料。反复迭代下去,不断优化模型生成语料,直至建立好模型需要的语料。
(3)实验结果
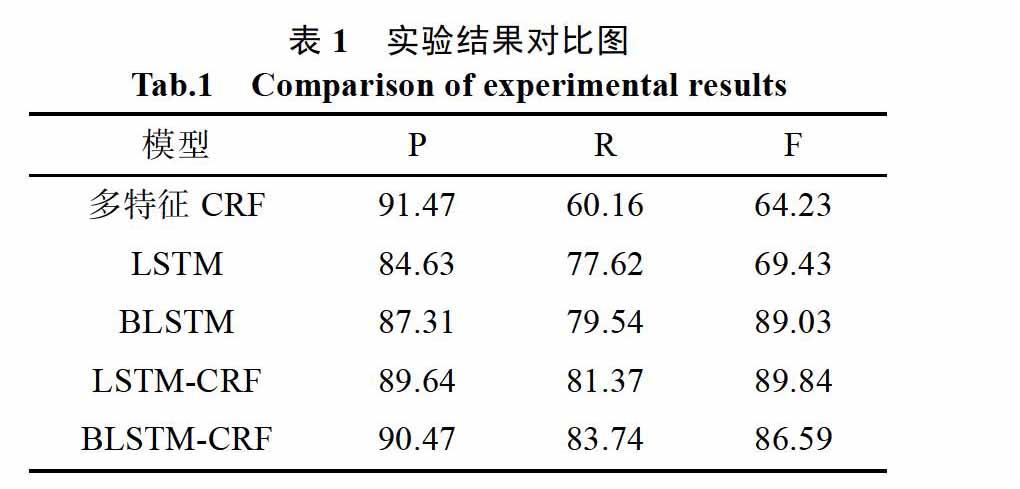
将通过分词工具得到的词向量分别输入到多特征CRF、LSTM、BLSTM、LSTM-CRF和 BLSTM- CRF模型,我们比较这几种不同模型得到的实体识别效果,具体结果如表1所示。
从上表可以看出,文献[19]中采用的多特征CRF模型准确率和召回率相对较低,其原因在于模型的效果取决于手工设计的特征,找出的有效特征越多则模型越好。LSTM-CRF模型准确率达到 89.64%,采用的BLSTM-CRF模型准确率达到 90.47%,召回率达到83.74%,说明双向递归神经网络的效果优于单向递归神经网络。
4 结论
本文的工作是建立一个基于LSTM神经网络的BLSTM-CRF分词模型,并将其应用于知识点识别和提取。通过使用不同的单词位置注释并添加训练前的单词嵌入向量来执行中文分词。通过比较Bakeoff 2005数据集上的分词性能测试,并与之前的研究结果进行比较:在相同的分词模型下,六字标记比四字标记具有更好的分词性;与LSTM模型和BLSTM模型相比较,在中文分词任务上,BLSTM- CRF模型在各种指标上具有更加优良的性能。在自然语言处理中更容易推广到其他序列标注问题,并具备一定程度的泛化能力。
参考文献
[1] 孙勤红, 朱颖文. 正则表达式在计算机类教材知识点提取的应用[J]. 计算机与现代化, 2009(7): 110-112.
[2] 蒋玲. 面向学科的知识元标引关键技术研究[D]. 华中师范大学, 2011.
[3] 陈果. 全局视角下的科研领域特色知识点提取[J]. 图书情报工作, 2014(14): 98-102.
[4] 刘源. 信息处理用现代汉语分词规范及自动分词方法[M]. 北京: 清华大学出版社, 1994.
[5] Nianwen Xue. Chinese word segmentation as character tagging[J]. Computational Linguistics and Chinese Language Processing, 2003, 8(1): 29-48.
[6] Peng F, Feng F, Mccallum A. Chinese segmentation and new word detection using conditional random fields[C]. Proceedings of Coling, 2004: 562-568.
[7] Collobert R. Weston J. Bottou L. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1): 2493-2537.
[8] Zheng X, Chen H, Xu T. Deep learning for Chinese word segmentation and POS tagging[C]. Conference on Empirical Methods in Natural Language Processing, 2013: 647-657.
[9] Chen X, Qiu X, Zhu C, et al. Gated recursive neu- ral network for Chinese word segmentation[C]. Proc of Annual Meeting of the Association for Computational Linguistics,2015: 1744-1753.
[10] Chen X, Qiu X, Zhu C, et al. Long short-term memory neural networks for Chinese word seg- mentation[C]. Conference on Empirical Methods in Natural Language Processing, 2015: 1197-1206.
[11] Yushi Yao, Zheng Huang. Bi-directional LSTM recurrent neural network for Chinese word segmentation[C]. International Conference on Neural Information Processing, 2016: 345- 353.
[12] 金宸, 李维华, 姬晨, 等. 基于双向LSTM神经网络模型的中文分词[J]. 中文信息学报, 2018, 32(2).
[13] 李洋, 董红斌. 基于CNN和BiLSTM网络特征融合的文本情感分析[J]. 计算机应用, 2018, 38(11): 3075-3080.
[14] 田生偉, 胡伟, 禹龙, 等. 结合注意力机制的Bi-LSTM维吾尔语事件时序关系识别[J]. 东南大学学报: 自然科学版, 2018, 48(3): 393-399.
[15] 李婷婷, 姬东鸿. 基于SVM和CRF多特征组合的微博情感分析[J]. 计算机应用研究, 2015, 32(4): 978-981.
[16] Tong F, Luo Z, Zhao D. A deep network based integrated model for disease named entity recognition[C]// IEEE International Conference on Bioinformatics and Biomedicine. IEEE Computer Society, 2017: 618-621.
[17] Li L, Jiang Y. Biomedical named entity recognition based on the two channels and sentence-level reading control conditioned LSTM- CRF[C]// IEEE International Conference on Bioinformatics and Biomedicine. IEEE Computer Society, 2017: 380-385.
[18] Bengio Y, Schwenk H, Sene?cal J S, et al. Neural probabilistic language models[M]// Innovations in Machine Learning. Berlin: Springer, 2006: 137-186.
[19] 苏娅, 刘杰, 黄亚楼. 在线医疗文本中的实体识别研究[J]. 北京大学学报(自然科学版), 2016, 52(1): 1-9.
[20] 金留可. 基于递归神经网络的生物医学命名实体识别[D]. 大连理工大学, 2016.
[21] 谢铭, 吴产乐. 用户信息保护下的学习资源知识点自动提取[J]. 计算机科学, 2011, 38(3): 203-205.
[22] 徐浩煜, 任智慧, 施俊, 等. 基于链式条件随机场的中文分词改进方法[J]. 计算机应用与软件, 2016, 33(12): 210- 213.
[23] 张聪品, 方滔, 刘昱良. 基于LSTM-CRF命名实体识别技术研究与应用[J/OL]. 计算机技术与发展, 2019(2): 1-4 [2018-12-03].
