基于朴素贝叶斯的高校教师工作量考核分类预测研究
2019-10-08刘占波闫实王晓丽
刘占波 闫实 王晓丽

摘 要: 本文服务于高校教师管理系统,为高校教师的工作量考核提供决策支持,借助朴素贝叶斯分类模型预测高校教师的教学负担。本文以某大学16年某学院的教师工作量作为数据基础,通过实验证明了朴素贝叶斯分类过程是一种简单易行且容易被程序实现的方法,可以对高校教师工作量考核分类做预测辅助考核决策。
关键词: 朴素贝叶斯;分类预测;高校信息系统
【Abstract】: The article predicts teaching workload of college teachers with help of naive Bayesian classification model, to provide decision support for workload assessment of college teachers, and serve management system of college teachers. Based on workload data college teachers grade 16 of a university, the article proves naive Bayes classification process is a simply and easied programmed method based on practice, which can assist assessment decision-making of workload assessment classification of college teachers.
【Key words】: Naive Bayes; Classified prediction; College information system
0 引言
当前信息化建设已经进入到高校的每一个角落,高校的信息系统也是日趋完善。在高校的教师管理信息化工作中利用信息化手段提高管理工作效率,改善工作流程,实现现代化信息化的管理方法已经成为普遍的共识。但是随着信息化的深入,信息技术的发展尤其是近年来的人工智能技术的发展,给高校教师管理系统带来了巨大的机遇[1]。从统计意义上来讲,高校教师的工作量是存在统计规律的,那么就有可能通过分类预测工作量。常见的分类预测方法有:决策树、贝叶斯、遗传算法、传统神经网络等方法。
本文将借助分类预测技术,尝试在高校教师工作量上进行分类预测,起到对工作量考核的辅助决策作用。以某大学16年某学院的教师工作量作为数据基础,以教师工作量数据作为研究对象,采用朴素贝叶斯模型作为分类工具。通过对现存的高校教师管理系统数据库抽取数据维度,设计一个数据向量来刻画一个高校教师的教学负担。通过这个教学负担分类来预测安排教学的合理性,从而为课程安排的决策起到支撑作用。
1 理论分析
分类预测就是要通过已知的数据分类去预测未知的数据属于那一个已知的类别。这中间的过程就是对已经有标签的数据,通过数据训练产生一个描述这个类别的模型,通过这个模型去预测没有分类标签的未知数据。贝叶斯分类器,在机器学习里属于有监督学习方法,因为其样本的分类是已经有标签明确的分类。其假设所分类的数据,数据中的各个属性都是独立的,即相互不影响的,因此称为朴素贝叶斯分类。而实际应用中,往往这种假设并不成立,但是实践过程中即使假设不成立,朴素贝叶斯分类器依然良好的工作。
那么结果是89%的几率发生,所以此时系统可以建议降低该教师的工作强度。显然,上面的例子比较简单,所考虑的因素仅仅只有教师的工作负荷,对于所授课程的难度,教师的经验等因素均为纳入模型。而在朴素贝叶斯分类中,将会以属性的形式来考虑更多的因素,这里假定属性是独立的,即属性间不存在相互影响。朴素贝叶斯分类器算法可以简单的通过下述五步实现:
(1)通过N维向量表示样本的N个属性,对于本文就是要考虑的评价因素;
(2)事先给定几个类别,对样本分类,而未知样本是没有分类的样本;
(3)由于樣本的属性有N个,只有假定属性间是独立的,计算量才能最小;
(4)所求样本的N个属性,均可以通过训练数据集求得其先验概率;
(5)根据贝叶斯公式计算所求未知样本属于每个类别的概率,其中概率最大的类别作为其类别,即所求分类。
由于朴素贝叶斯分类器,有着实现简单性能良好的特点,因此适合在大数据环境下实践,因此本文采用朴素的贝叶斯分类对高校教师工作量考核进行分类做预测研究。
2 分类预测研究
本文以某大学2006年至2016年共计十年某学院的教师工作量作为数据基础,以教师工作量数据作为研究对象,采用朴素贝叶斯模型作为分类工具,找到针对教师的工作量饱和度和教学质量的平衡。
2.1 训练样本准备
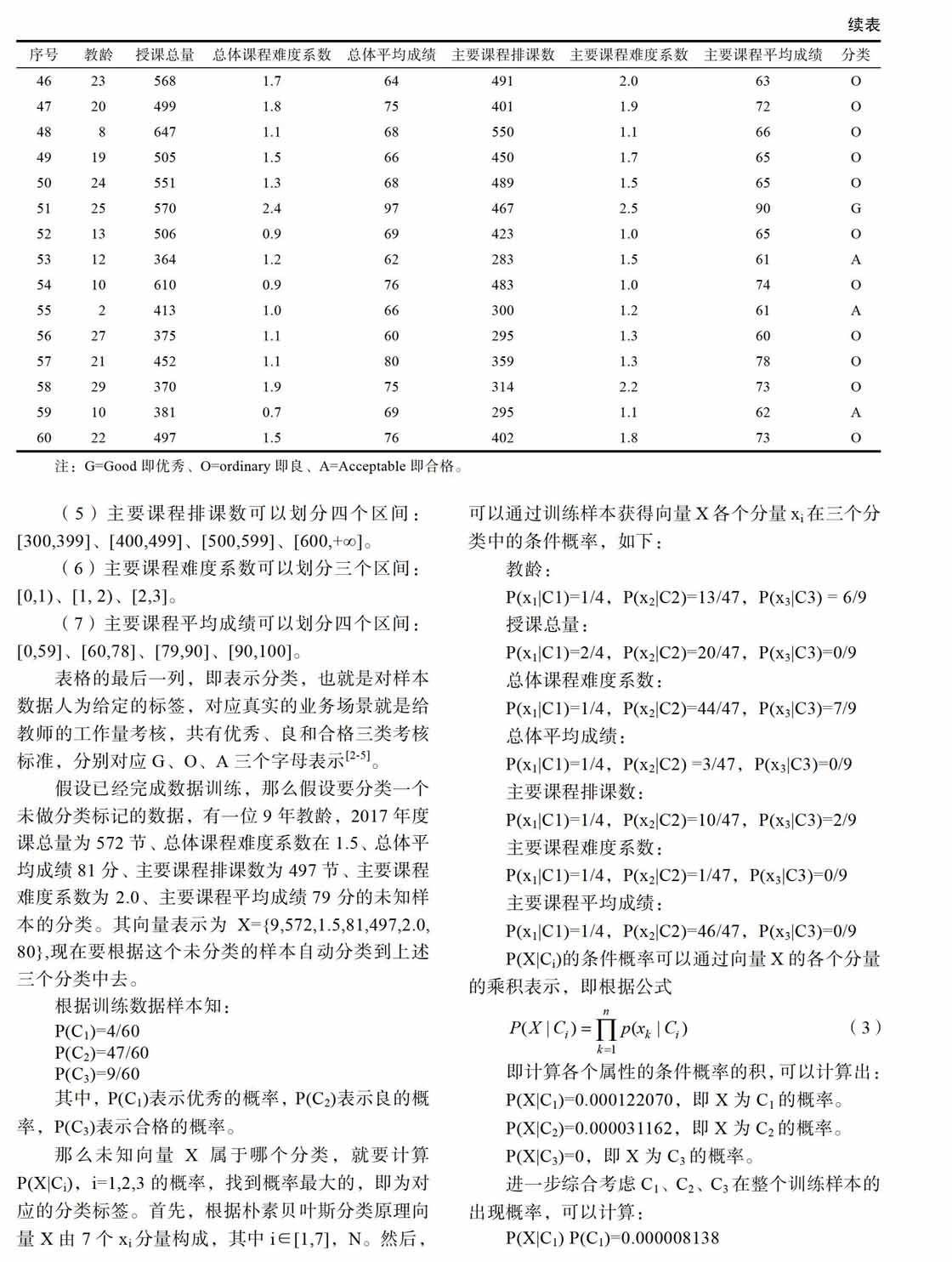
结合朴素贝叶斯分类器算法,首先要根据以往信息系统里搜索的教学基础数据,合理选取评价,本文结合实际工作与教学特点,选取了七个维度描述一个样本(教龄、授课总量、总体课程难度系数、总体平均成绩、主要课程排课数、主要课程难度系数、主要课程平均成绩)。对于教师工作的评价类别可以给定(C1:优秀、C2:良、C3:合格)这三个分类。
根据某大学某学院从2006年至2016年教学管理信息系统所积累的教师工作量作为基础数据。在实际工作中,要分析的数据维度来自不同业务数据表的汇总和统计,本研究通过从信息系统里的多张业务表里统计汇总获取60笔记录作为训练样本,样本数据见表1。
2.2 数据分析与预测
根据上述训练样本表格中设计的七个维度所描述的向量,即可表示一个样本,针对向量内的数据可以进一步做区间分类让数据内聚,具体操作如下:
(1)教龄可以划分四个区间:[1,8]、[9,16]、[17,24]、[24,30]。
(2)授课总量可以划分四个区间:[300,399]、[400,499]、[500,599]、[600,+∞]。
(3)总体课程难度系数可以划分三个区间:[0,1]、[1,2]、[2,3]。
(4)总体平均成绩可以划分四个区间:[0,59]、[60,80]、[80,90]、[90,100]。
(5)主要课程排课数可以划分四个区间:[300,399]、[400,499]、[500,599]、[600,+∞]。
(6)主要课程难度系数可以划分三个区间: [0,1)、[1, 2)、[2,3]。
(7)主要课程平均成绩可以划分四个区间: [0,59]、[60,78]、[79,90]、[90,100]。
表格的最后一列,即表示分类,也就是对样本数据人为给定的标签,对应真实的业务场景就是给教师的工作量考核,共有优秀、良和合格三类考核标准,分别对应G、O、A三个字母表示[2-5]。
假设已经完成数据训练,那么假设要分类一个未做分类标记的数据,有一位9年教龄,2017年度课总量为572节、总体课程难度系数在1.5、总体平均成绩81分、主要课程排课数为497节、主要课程难度系数为2.0、主要课程平均成绩 79分的未知样本的分类。其向量表示为X={9,572,1.5,81,497,2.0, 80},现在要根据这个未分类的样本自动分类到上述三个分类中去。
3 结论
本文的设计主要是针对性决策安排教师的授课量达到一个比较均衡的工作量分配方案,既能保障教学质量,又可以最大化的保证工作饱和度[6-8]。本文在样本的选取上尽量做到了同时兼顾较大范围的普遍意义,又尽可能满足教师工作量均衡安排的特定场景。在这一实践基础上,本文调整了贝叶斯分类假定数据的各个属性都是独立的这一假设,因为本文的选取维度在单个属性间存在一定的关联,譬如,主要课程难度系数和主要课程平均成绩。但是,从实验结果上分析,朴素贝叶斯依然在实验中获得了良好的效果[9-10]。
参考文献
包小兵. 基于朴素贝叶斯的Web文本分类及其应用[J]. 电脑知识与技术, 2016(30): 226-227+236.
詹毅. 朴素贝叶斯算法和SVM算法在Web文本分类中的效率分析[J]. 成都大学学报(自然科学版), 2013, 32(1): 50-53.
陈甜远. 大数据时代的高校信息管理中心对策[J]. 无线互联科技, 2013(5): 8-9.
陳亚静. 大数据时代下高校教学的几点启示[J]. 信息与电脑(理论版), 2015(22): 192-194.
孙玫, 张森, 聂培尧, 等. 基于朴素贝叶斯的网络查询日志session划分方法研究[J]. 南京大学学报(自然科学), 2018, 54(06): 1132-1140.
邱宁佳, 李娜, 胡小娟, 等. 基于粒子群优化的朴素贝叶斯改进算法[J]. 计算机工程, 2018, 44(11): 27-32+39.
张俊飞. 基于改进朴素贝叶斯算法实现评教评语情感分析[J]. 现代计算机(专业版), 2018(32): 3-6.
陈娅婷, 鲁凌云. 大规模混合网络中基于朴素贝叶斯分类的TCP自适应鉴别器[J]. 通信学报, 2018, 39(S1): 189-194.
于营. 基于朴素贝叶斯的旅游网情感分类研究[J]. 信息与电脑(理论版), 2018(18): 50-51+55.
王占孔, 王学丽. 基于贝叶斯网络的分层网络故障诊断[J]. 软件, 2011, 32(04): 87-90.