基于BLSTM和注意力机制的电商评论情感分类模型∗
2019-10-08潘晓英
潘晓英 赵 普 赵 倩
(西安邮电大学计算机学院 西安 710121)
1 引言
随着互联网时代的来临,人们已经习惯于网上消费,在电商平台上购物并对购买的产品进行评论已经成为了日常生活的一部分,并由此产生出大量的评论信息。这些评论信息中通常包含着消费者的态度和想法,对于研究者和商家均具有极高的分析价值。因此,如何使用机器学习、自然语言处理等技术来挖掘和提取这些信息中蕴含的观点倾向性和情感信息[1],成为了自然语言处理领域中一个重要的研究方向,引起了国内外众多研究人员的广泛关注。
当前,文本情感分类主流的研究方法依然围绕着机器学习展开,通过人工构建特征工程,将文本进行数据化,以此进行后续的研究学习。例如支持向量机、KNN算法、决策树等[2]。这些方法虽然简单有效,但是算法抽象能力较弱,人们在这些方法的改进上做了大量工作,如人工建立情感词典、引入文本结构特征和语法特征等,至今仍有许多应用价值。但是新环境下,互联网文本具有数据量大、不均匀、语法结构不固定等特点,这导致上述方法难以继续发展。
随着深度学习技术的发展,卷积神经网络和基于长短时记忆模型(LSTM)也被应用于文本的情感分类中。但电商评论语言结构通常不规范,新词、组合词较多,文本多口语化,并且在对一条评论文本进行情感分类时,也并非文本中所有的部分对于其情感倾向的影响都是相同的。因此,上述方法虽然取得了一些不错的成果,但是仍然存在明显的不足。
为解决上述问题,本文提出基于双向长短时记忆网络和注意力机制的情感分类模型。为避免人工构造特征工程和不合理分词的影响,将单独的字作为文本的最小组成单元,使用预训练的字向量作为输入特征,利用双向长短时记忆网络来学习文本特征。然后通过注意力机制来计算文本各部分的影响权重,用于最终的情感分类,并将评论文本按照其影响权重进行了可视化。实验结果表明,该方法取得了比目前主流机器学习方法和深度学习方法更好的效果,验证了本文方法的有效性。
2 相关工作
情感分类通过分析文本中蕴含的情感信息,来判断用户对于某一事件或某一事物的态度。Pang[3]等早期利用词袋模型来进行文本的情感分类,后续很多人尝试设计更合理的文本特征来提高情感分类的正确率。但这些方法都是基于分析句法结构搭配情感词典的方法或者类似方法来进行构建文本特征。Pang使用了朴素贝叶斯和支持向量机等方法,在电影评论数据集上取得了不错的成绩;Taboada[4]等根据词性的不同建立包含情感极性和强度的词典,然后对句子进行加权评分然后得出情感分类;胡熠[5]等用基于n-gram的方法进行语言建模,然后使用支持向量机进行情感分析;肖红[6]等通过将句法分析和情感词典进行结合来进行网络舆情倾向性研究。
为了摆脱传统机器学习中特征工程的影响,人们开始将深度学习方法应用于自然语言处理领域。Hinton[7]提出了词向量(Word Embedding)的思想,该思想通过将词语分布式的映射到低维空间中,一方面解决了向量稀疏问题,另一方面保存了词语间语义层面的关系;随后,Bengio[8]等实现了基于三层神经网络的 n-gram语言模型;Mikolov[9]等提出了word2vec模型,实现了CBOW和Skip-gram两种方法。词向量的出现极大地促进了深度学习在自然语言领域的进展,刘政[10]等利用不同大小的卷积核来构建文本特征,以此进行谣言的分类识别;李阳辉[11]等将改进的降噪自动编码器应用于微博的情感分析;Zhou[12]等则将卷积神经网络和LSTM模型进行结合用于文本的分类;Wang[13]等利用LSTM模型来预测推特的情感极性;Tang[14]等将LSTM模型进行扩展,突出上下文对目标词情感倾向的影响来提高分类效果。
随着深度学习的不断深入,注意力机制成为神经网络研究的一个热点。注意力机制在图像处理[15]中已经取得不错的效果。随后Bahdanau[16]等将注意力机制应用于机器翻译,并取得了非常优秀的效果,目前已经被谷歌用于超大规模的神经网络翻译系统当中。而后续基于注意力机制的一系列工作,如关联提取[17]、文本摘要[18]等,均说明其理论在自然语言处理领域的先进性和适用性。
深度学习已经被证明在诸多领域的有效性,本文提出基于双向长短时记忆网络和注意力机制的模型来进行情感分类。该方法能学习到更加完整的文本特征,提升文本中关键部分的影响,从而提高情感分类的正确率。
3 模型构建
本文构建的用于情感分类的模型结构如图1所示。
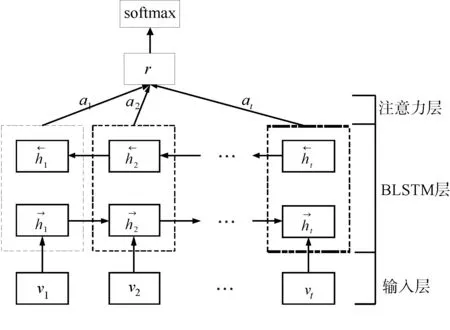
图1 基于BLSTM和注意力机制的情感分类模型
该模型主要由三个部分组成:输入层,基于BLSTM的特征提取层和注意力层。本文模型整体流程:将文本序列用字向量进行建模,得到文本的字向量表示,然后通过双向长短时记忆网络来进行语义编码得到文本语义特征,最后通过注意力层来抽取文本语义特征中重要的部分并提高这部分的权重来生成最终的文本特征,以此进行情感分类工作。
3.1 长短时记忆网络
长短时记忆网络是循环神经网络的扩展,其隐藏层神经元中构建了记忆存储单元,可以发现和建立输入特征之间的长距离依赖关系,因此可以有效处理循环神经网络(RNN)中存在的梯度消失和梯度爆炸问题。
长短时记忆网络由四个部分构成,输入门it,Wih、Wix、bi为输入门的权重矩阵:
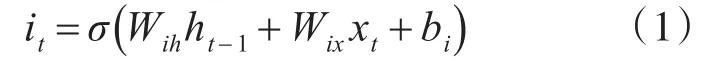
遗忘门 ft,Wfh、Wfx、bf为其权重矩阵:

以上门结构的输出将同当前的输入xt,上一时刻LSTM单元的输出ht-1,以及上一时刻的记忆单元中存储的Ct-1用于决定是否更新记忆单元的状态并遗忘之前存储的状态:
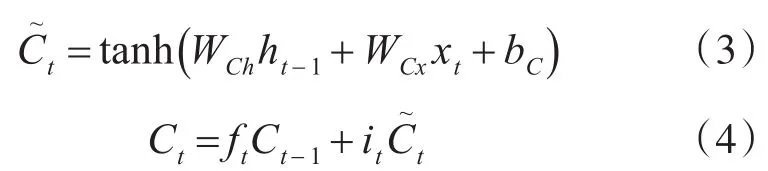
最后输出门输出记忆单元状态改变后的值:
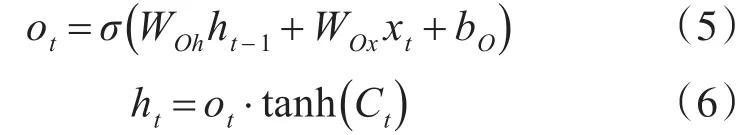
3.2 字向量表示
由于电商评论多具有新词多、合成词使用频繁等特点,如果直接本进行分词训练词向量有可能会割裂语义。例如“这家酒店真是高大上”中,“高大上”为缩写组成的合成词,对其直接进行分词会导致训练出的词向量语义信息不够准确。为了更好地得到文本的语义编码,本文将使用预训练的字向量作为输入特征。
3.3 特征提取层
为了得到包含有上下文语义信息的文本特征,本文使用双向的长短时记忆网络来进行语义特征提取。双向长短时记忆网络包含两层方向相反的网络结构。对于句子si,正向网络的学习方向从x1到xT,反向网络的学习方向从xT到x1:
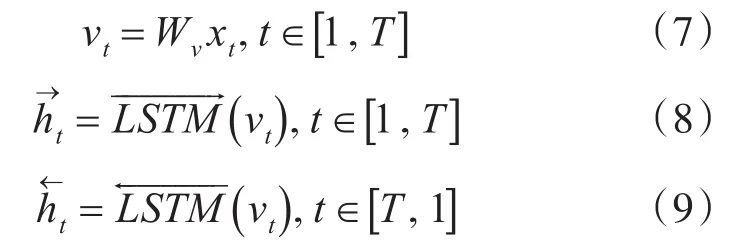
对于每个输入的字xt,将正向层的输出和反向层的输出进行拼接,得到包含该位置上下文语义的特征ht,这样ht中包含了上下文的语义信息,但焦点依然集中在字xt上:

经过双向长短时记忆神经网络的学习即可得到句子si中每个字的语义特征。
3.4 注意力层
对于评论文本而言,句子中的每个字对于其最终情感分类的影响是不同的,为了扩大关键部分的影响力,需要找到它们。因此,在双向长短时记忆网络的基础上,设计了一种注意力机制来提取文本中对于情感分类相对重要的部分,并提高其在最终生成的文本特征中的权重。
对句子si,计算其每个字的影响力权重。首先得到每个字激活后的语义特征,然后通过softmax函数来计算文本中每个字的影响权重at:
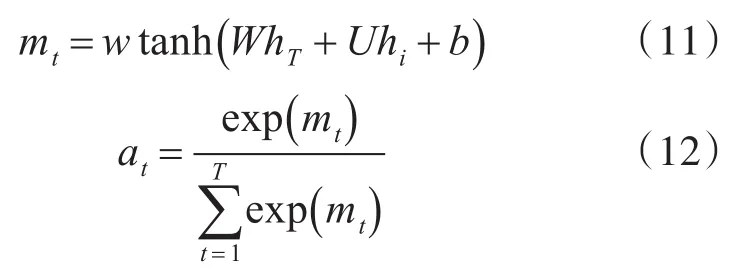
最后将经过双向长短时记忆神经网络学习到的语义表示和影响权重进行乘积求和,得到包含了句子si全部语义信息的特征Ci:

将其作为最后全连接层的输入,通过全连接层:
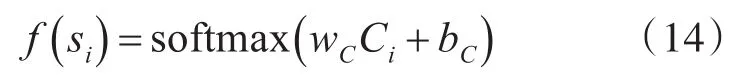
3.5 模型训练
用上文中求得的文本特征进行最终的情感分类。本文根据数据集的特点,将测试集分为正向和负向两类文本。对于句子si,通过本文模型训练得到其对应情感类别τ∈K的输出 fω()si,K表示所有的情感类别。通过softmax函数来得到每个情感类别的概率:

对上式的负似然对数来作为训练的损失函数,并使用adam算法来优化:

其中N表示训练数据集,sj和yj表示数据集中一条句子和对应的情感类别。这里加入了对参数的正则化来防止过拟合,λ为正则化系数,ω为所有参数。
4 实验设计与分析
4.1 实验环境设置
本文实验环境配置如表1所示。

表1 实验环境及配置
4.2 实验数据预处理
本文所用数据集为谭松波博士整理的携程网酒店评论数据集,并在此基础上另外使用爬虫抓取携程网正负项评论文本各2000条文本进行扩充,实验数据集规模为5000条正向评论,5000条负向评论。
在对数据进行训练字向量之前,对数据进行了预处理:
1)去除特殊字符,只留下中文字符;
2)进行繁简转换,将数据中的繁体字转换为简体字;
3)对于字向量进行分字处理。
4.3 字向量的训练
为了训练出更高质量的字向量,本文将维基百科的中文语料和实验数据集一起进行了字向量的训练,以此作为后续实验的输入数据。文本使用gensim[19]工具中的skip-gram模型进行字向量的训练,上下文窗口大小为8,词向量的维度为100。
另外,为了进行对比实验,本文在同样的语料基础上,进行了词向量的训练,训练参数保持一致,上下文窗口大小为8,词向量的维度为100。
4.4 模型参数设置
模型中各层神经单元数如果较少,则无法有效学习到句子的特征,神经单元数目过多则容易过拟合。通过多次实验,在本数据集上,设置单层长短时记忆网络的神经单元数量为50,双向长短时记忆网络进行合并后的神经单元数量为100,注意力层神经单元数量为50。为了防止过拟合现象,在训练过程中加入了L2正则化来进行参数约束,同时加入dropout策略。模型中的各权重参数进行随机初始化,采用adam算法进行迭代。由于模型较为复杂,且数据集规模不大,因此采用early stopping,根据验证集上的效果决定是否提前停止迭代。
4.5 实验与分析
为了探究本文方法和其他方法在情感分类上的性能优劣,这里加入传统机器学习方法(SVM)以及单层长短时记忆网络(LSTM)和双向长短时记忆网络(BLSTM)进行对比,并分别使用字向量和词向量作为输入特征。实验采用准确率、召回率和F1值作为评价标准,并对结果进行了可视化处理。

本文实验分为三组:第一组以字向量为输入特征,进行了3次实验,分别为:char-LSTM、char-BLSTM和char-Att-BlSTM;第二组使用词向量作为输入特征,在保持参数一致的情况,分别进行了word-LSTM、word-BLSTM和word-Att-BLSTM的实验;第三组进行了基于词向量的传统机器学习方法(word-SVM)的实验。实验结果如表2所示。
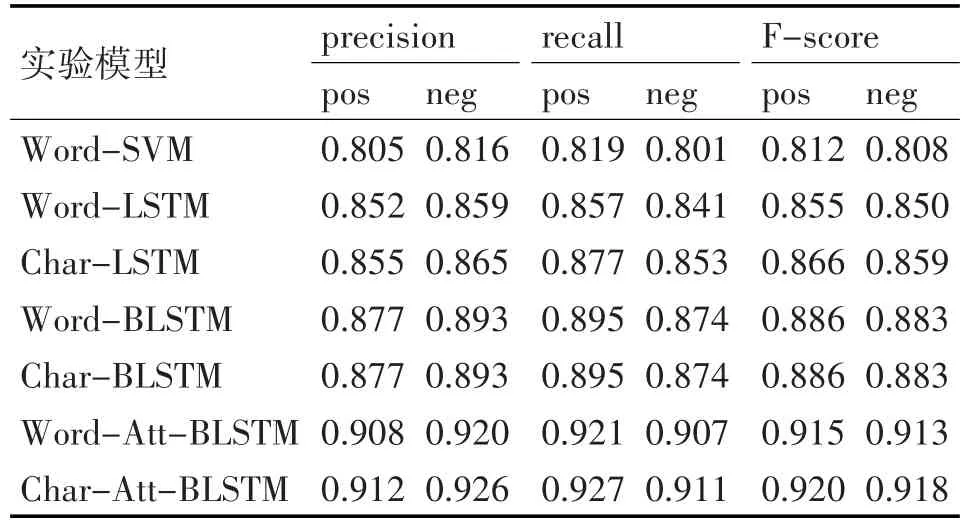
表2 各组实验结果比较
对上表实验数据进行分析:
1)比较word-SVM和word-LSTM两组实验结果,可以看出基于单层的word-LSTM模型的实验结果要大大好于word-SVM的结果,这说明在使用词向量作为输入特征时,采用单层LSTM模型可以学习到更加合理和全面的语义特征,因而其取得的效果也较好;
2)比较LSTM模型的两组实验和BLSTM模型的两组实验结果可以看出,在使用字向量和词向量作为输入特征的情况下,BLSTM模型的实验结果都要明显优于LSTM模型的结果,这说明BLSTM模型可以学习到更完整的上下文语义,因此其生成的语义特征的表达能力也更强,因此在面对电商评论文本时,使用BLSTM模型来学习句子的语义特征更加有效;
3)比较基于BLSTM模型的两组实验和基于Att-BLSTM模型的两组实验可以看出,在同样的输入特征时,注意力机制的引入,使得其在BLSTM模型学习到的语义特征基础上,根据句中不同部分对句子语义影响力的不同,动态的增加重要部分的权重,有效地降低了句子中冗余成分对于情感分类的影响,加强了句子中关键部分的影响,从而提高了分类效果;
4)对比使用不同输入特征的两组实验,使用字向量作为输入特征的3个实验的结果均要好于使用词向量的实验结果。可以看出,输入文本如果长度不固定并且合成词和新词出现的频率较多,句子的不合理切分会割裂文本语义的完整性,导致训练出的词向量质量不高,这将直接影响情感分类的结果。因此在面对互联网语境下的电商评论文本时,使用字向量作为输入文本有助于提高分类的效果。
4.6 注意力机制的可视化
为了直观地验证本文模型的有效性,这里将部分语句的实验结果按照其影响力权重进行了可视化,以标准RGB作为基准色,按照上文中求得的影响权重进行背景上色处理,结果如图2所示。图中每一行为一条评论语句,对每条句子中的每个字进行处理,按照注意力机制计算出的影响权重的不同,其颜色深浅不同,影响权重越大,其颜色越深。从图2可以看出,对于积极的评论和消极的评论,对于句子情感类别影响较大的情感评价词和程度副词均能有效的标注出来,这充分说明本文模型对于电商评论的情感分类是有效的。

图2 部分评论通过注意力机制可视化图示
5 结语
情感倾向分类是自然语言处理领域的重要研究课题之一。本文提出一种基于双向长短时记忆网络和注意力机制的情感分类模型,该方法使用预训练的字向量作为输入特征,通过双向长短时记忆网络来学习文本的语义特征,然后利用注意力机制来提高文本的关键部分的权重,进行情感分类。实验验证了该模型的可行性和有效性,同时对注意力机制的可视化结果也充分说明了该模型对于文本关键部分的判别能力。在下一步的工作中,将进一步结合其他方法提高模型的泛化能力,将其推广应用于更复杂的语言环境中去,同时提高其对于消极评论文本的分类能力。
