先验信息约束NMF的高光谱解混
2019-09-23韩月康维新李慧
韩月,康维新,李慧
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
高光谱遥感技术是近年来非常流行的技术之一,通过遥感平台形成的图像具有高光谱分辨率、低空间分辨率的特点,这样就造成了图像中的一个像元中不仅包含一种纯粹地物,往往含有多种地物,称为混合像元[1][2]。非负矩阵分解(non-negative matrix factorization, NMF)[3]算法是基于线性光谱混合模型(linear spectral mixture model,LSMM)[4]进行展开的,是当今较为流行的盲源分离(blind signals separation, BSS)算法之一,广泛应用于图像处理。NMF最早由Paatero和Tapper[3]发现,此后,Lee和Seung[4]分别介绍和推广了它的概念。NMF是基于数据非负的条件下进行的,这样能更好的贴合实际物理意义,使研究更具现实意义。此后,多种基于NMF的改进算法相继提出,2005年Chen Z[5]提出了平滑约束的非负矩阵分解,在端元矩阵和丰度矩阵加入平滑约束(CNMF),提高了NMF算法的精度,2007年Miao Li等[6]将最小体积约束加入到非负矩阵分解(MVC-NMF),提高了分解过程的抗噪性能,2009年Qian Y等[7]提出L1/2稀疏约束的NMF,使解混结果更稀疏和精确。2014年魏一苇等[8]提出改进的MVC-NMF。有些真实地物信息通过科学测量可以获得,但以上方法都没有利用真实地物信息,浪费数据资源。Tang 等[9]将端元矩阵分成两部分,一部分代表已知端元,另一部分代表未知端元,但缺点是求解时间长且结果不稀疏。本文利用已经获得的真实地物信息作为先验信息对非负矩阵分解进行优化,改善利用先验信息求解时间长的缺陷。
1 非负矩阵分解算法
1.1 LSMM
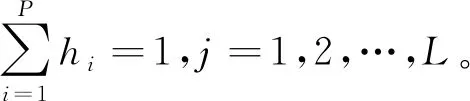
1.2 非负矩阵分解算法及改进
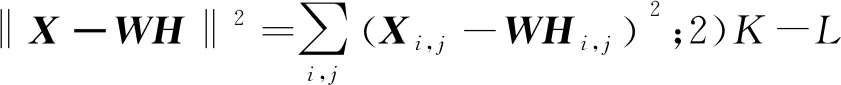
W←W·XHT·/WHHT
(1)
H←H·WTX·/WTWH
(2)
随着高光谱数据解混研究的不断深入,真实高光谱图像中的某些特征的先验知识是可以获得的。在矿区等多个场景中,铁、云母石等材料通过现场调查极易识别,因此它们的光谱特征可以从光谱库中获得。由于现今的大多数分解算法在建立模型时并没有考虑这些真实端元的已知条件,造成数据浪费及解混结果精度偏低。本文提出基于已知端元约束的非负矩阵分解的高光谱解混方法则可充分利用已知端元信息。
本文算法根据文献[10]建立基本模型为:
(3)
式中:W1、H1分别代表已知端元矩阵和丰度矩阵;W2、H2分别代表未知端元矩阵和丰度矩阵。添加约束后模型为
(4)
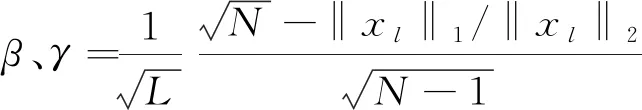
由于端元不能随意确定,当现场的测量端元与估计的端元相差太大时也会产生极大的误差,因此本文将真实端元与初始化端元之间范数相对小的数据作为已知端元,保证解混结果的精度。
本文算法步骤如下:
输入高光谱图像数据X∈RL×N
利用顶点成分分析(vertex component analysis,VCA)和全约束最小二乘(full constraint least square,FCLS)对端元和丰度进行初始化,计算真实端元与初始端元的范数,选出已知端元;根据式(4)处理数据;
输出W,H
2实验及结果分析
2.1 评价指标
在高光谱解混中,常见的评价指标有光谱角距离(spectral angle distance,SAD)和均方根误差(root mean square error, RMSE)[13]。SAD表示估计端元与初始端元之间的光谱角距离,RMSE表示端元对应的估计丰度信息与真实丰度之间的均方根误差。光谱角距离越小,均方根误差值越小,说明解混效果越好。在合成数据中可以同时利用以上两种评价指标来评判解混效果,在真实高光谱数据中,由于缺乏现场真实地物的分布图,不能利用RMSE进行衡量。
SAD表示为:
(5)
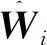
RMSE表示为:
(6)
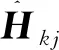
2.2 合成高数据的实验
从美国地质勘探局(USGS)测量的光谱数据库选取不同端元合成模拟数据,此光谱数据库含224个波段,501个端元,波长范围为0.38~2.5 μm,光谱分辨率达10 nm。本文选取其中5种端元作为端元矩阵;随机生成相应的丰度矩阵,同时满足 “非负”与“归一化”双重约束,且服从 Dirichlet 分布。合成数据中含有真实端元信息和真实端元分布情况,因此在对解混结果进行评价时采用SAD和RMSE。
2.2.1 不同像元的合成数据的实验
为了对比不同像元个数的高光谱数据对解混结果的影响,在本次实验中,利用不同像元个数分别为20×20、40×40、60×60、80×80、100×100的合成数据进行对比实验。当实验达到最高迭代次数停止运算。本文给出了解混所得端元矩阵的光谱角距离SAD均值和丰度矩阵的均方根误差RMSE的均值计算结果。
在这个实验中,分别进行本文算法与其他对比算法对不同像元合成高光谱数据的解混,此实验中,端元矩阵和丰度矩阵均已知,因此实验得出的SAD和RMSE结果精度较高。表1和表2分别给出了合成数据在不同像元情况下利用本文算法解混与其他对比算法的SAD和RMSE比较。
由表1可以看出,本文算法的SAD数值始终比其他对比算法要低得多,即解混得到的估计端元与真实端元信息最为靠近,在80×80像元的情况下,本文算法得出的解混效果最好;由表2可以看出本文算法得出的丰度信息更为接近真实丰度信息,解混效果最好;由表3可以看出本文提出算法相比其他算法对数据解混所需时间是最少的,但是比单纯NMF算法时间长,这是因为NMF算法模型简单,且容易陷入局部最优。
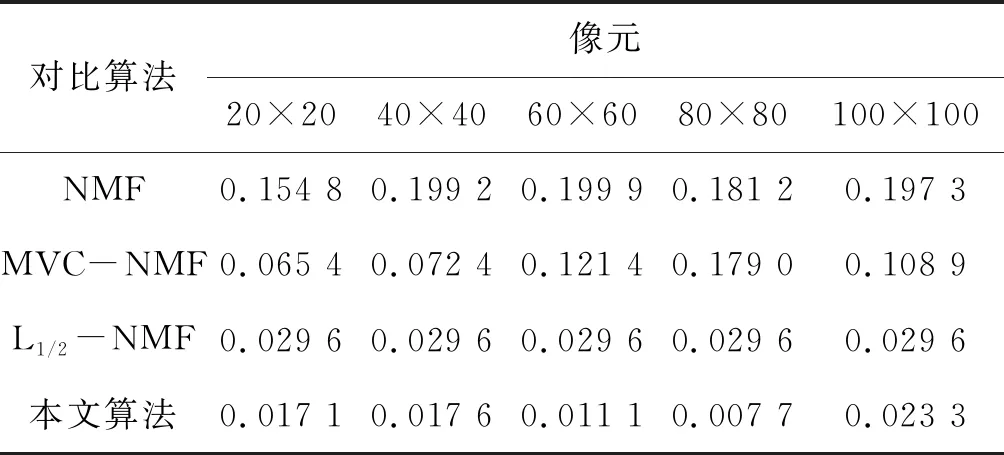
表1 不同像元合成数据解混后SAD比较 (°)
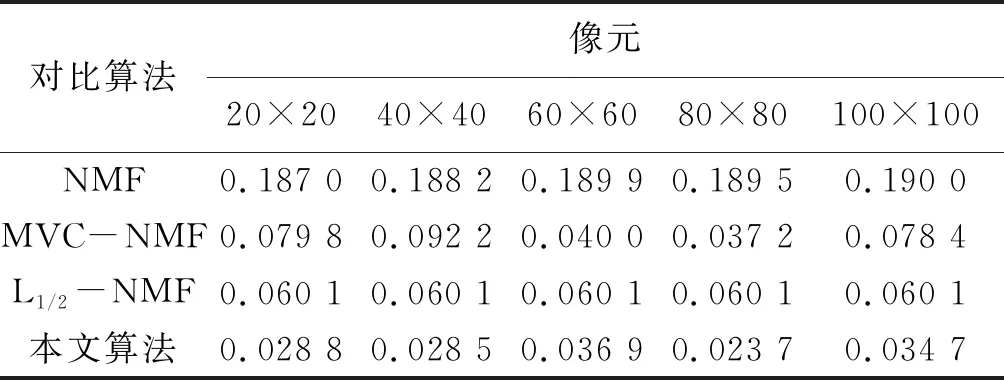
表2 不同像元合成数据解混后RMSE比较
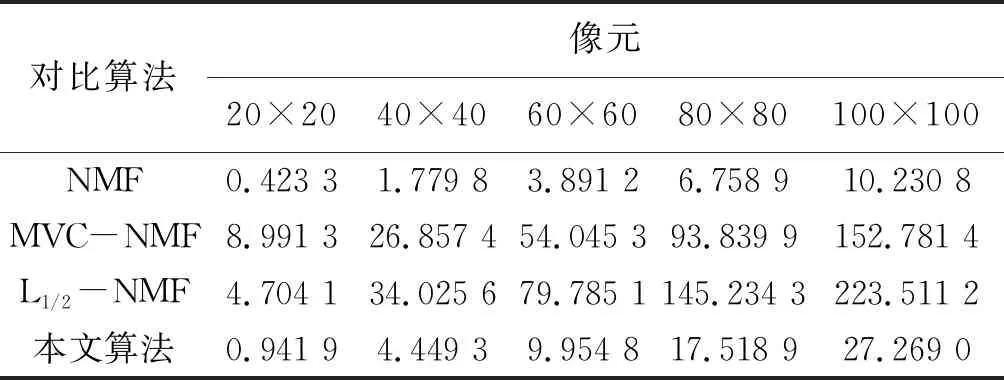
表3 不同像元合成数据解混所需时间比较 s
2.2.2 不同噪声的合成数据的实验
为了判断本文算法的抗噪性能,实验采用添加不同噪声的合成数据进行解混,并与其他算法的解混效果进行对比。合成数据分别加入25、35、45、55、65 dB的噪声,当实验达到要求或到达最大迭代次数停止迭代,本文给出了解混所得端元矩阵的光谱角距离SAD均值和丰度矩阵的均方根误差RMSE的均值计算结果。
在这个实验中,分别进行本文算法与其他对比算法对添加不同噪声的合成高光谱数据的解混,端元矩阵和丰度矩阵均已知,因此实验得出的SAD和RMSE结果精度较高。表4和表5给出了合成数据在添加不同噪声情况下利用本文算法与其他对比算法解混结果的SAD和RMSE比较。由表4可以看出,本文算法的SAD数值始终比其他对比算法要低得多,即解混得到的估计端元与真实端元信息最为靠近,在添加噪声为65 dB时,本文算法得出的解混效果最好;由表5可以看出随着噪声增大,本文算法的解混效果整体呈上升趋势,得到的估计丰度信息更为接近真实丰度信息,解混效果最好;由表6可以看出本文提出算法比其他对比约束NMF算法对数据解混所需时间更少,但是比单纯NMF算法时间长,这是因为NMF算法模型简单,容易陷入局部最优。
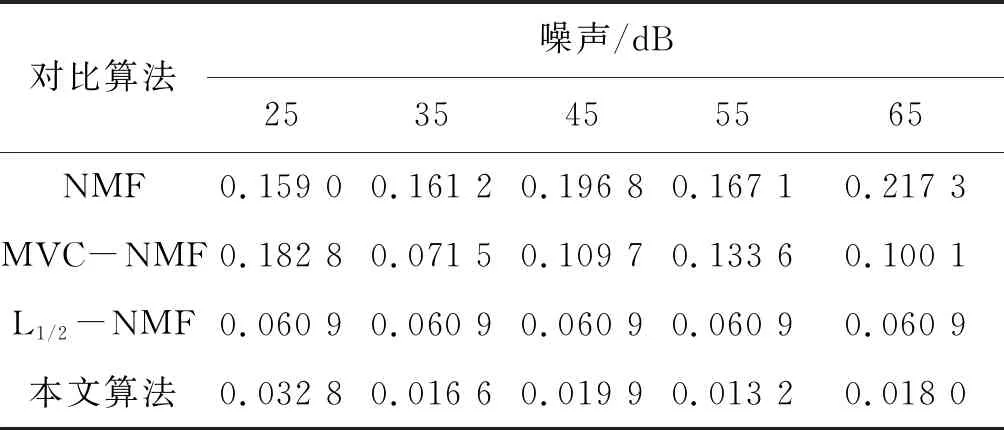
表4 不同噪声合成数据解混后SAD比较 (°)
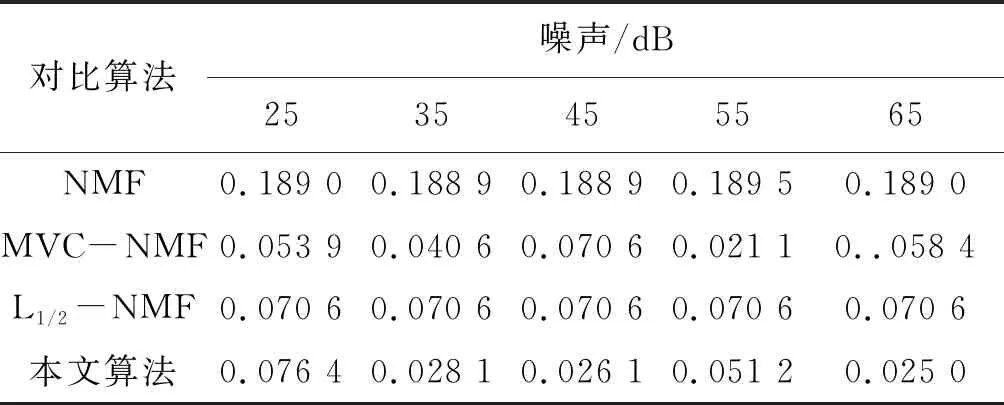
表5 不同噪声合成数据解混后RMSE比较
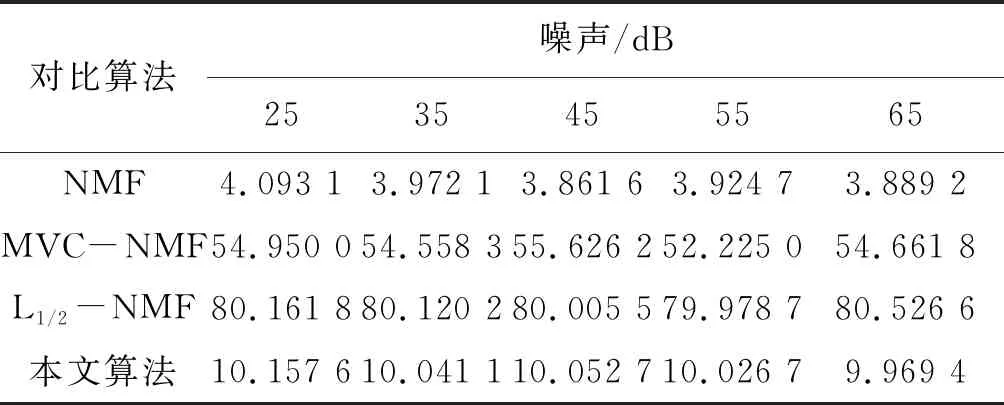
表6 不同噪声合成数据解混所需时间比较 s
2.3 真实高光谱数据的实验
真实数据选自1997年AVIRIS在美国内达华州采集的Cuprite地区的高光谱图像数据。滤除对实验不利或无用的波段后,高光谱数据为X∈RL×N,L=180,N=250×191,即共有188个波段,47 750个像元。根据实际测量的地物信息,选取其中8种地物作为真实端元进行解混。由于缺乏真实场景下的端元分布信息,利用SAD和丰度图对解混结果进行评价。真实高光谱解混后丰度如图1。

(a)地物1 (b)地物2 (c)地物3

(d)地物4 (e)地物5 (f)地物6
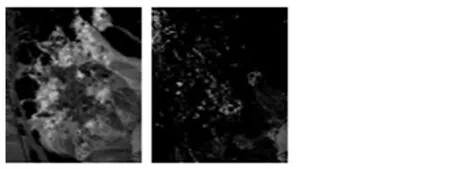
(g)地物7 (h)地物8 图1 真实高光谱解混后丰度图
图2是本文算法和其他对比算法对高光谱解混后的SAD比较。由图1、2可以看出本文算法得到的解混效果更好。
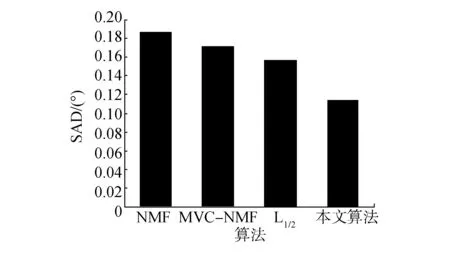
图2 各算法解混后SAD比较
通过真实数据解混实验得到各个算法所需时间分别是42.082 3 s(NMF)、2 412.759 820 s(MVC-NMF)、913.002 5 s(L1/2-NMF)、37.708 0 s(本文算法)。相比可知,本文算法对真实数据解混所需时间更短。
3 结论
本文在NMF方法来解决高光谱解混问题的基础上对其进行优化,添加先验信息约束,使解混结果更接近真实情况。根据实验数据分析,NMF及MVC-NMF算法收敛效果差,L1/2-NMF算法对空间信息利用不足,本文算法克服了以上的缺点,使计算过程中有较好的收敛效果,同时很大程度地利用了先验信息。仿真实验结果表明,相对于MVC-NMF算法和L1/2-NMF算法,本文提出的算法具有更好的抗噪性能,即使在多个像元情况下,也有较好的解混效果。如何保证算法的稳定性值得进一步研究。
