加密环境下大数据特征集并行存储方法研究
2019-09-23李蓉蓉
李蓉蓉
(广东科技学院,广东 东莞 523000)
0 引 言
伴随着超大规模集成电路技术与微处理技术的发展,计算机运算能力得到明显的提升,同时,运算速度的提升也对计算机存储性能提出了更高的要求,出现了运算速度与存储速度不协调的现象,导致“存储墙”问题产生[1-2]。国内相关学者早对并行数据库技术进行了研究,指出并行数据库大多采用关系数据模型,以集群的方式来完成数据的并行存储与优化;同时能够提供SQL 查询的能力,具有较好的数据查询效果。但其主要问题在于数据处理的弹性较差,且并行数据库技术的容错能力较差,查询过程需要具有一定的连续性,在大规模数据增长的条件下容易发生错误[3-4]。戴紫彬等人对高效并行处理架构进行了研究,使用统计建模的方式,以时间综合性能为指标,建立了三路异构并行处理架构,这一研究方式提高了数据处理器的灵活性,但并未讨论数据并行存储模式等具体计算细节[5]。董振兴等人对多路高速载荷数据的自主存储和并行接收方式进行了研究,提出总线并行扩展方案,并对四级流水线操作需求进行了详细分析,该方法能够满足高速数据的存储要求,但存储容量小[6]。
针对上述研究存在的问题,本文提出一种加密环境下大数据特征集并行存储方法。实验结果表明,所提并行存储方法具有较好的性能,为数据处理深入研究提供了参考依据。
1 大数据特征集的并行化MMSE计算
对大数据特征集进行优化分布时,具有相同时间段标记的特征集可以被映射到相同的数据节点上,且这些数据能够用于MMSE 计算[7-9]。为此,采用MMSE 算法进行大数据特征集的并行化处理,具体过程如下:
假设原始数据通道数量为g,相对应的时间序列可表示为其中,i=1,2,…,g,每一维度上的时间序列对应N个数据点。将尺度因子表示为δ,以此为基础构建多变量时间特征序列则有:

式中,当δ=1 时,时间特征序列即为原始序列。
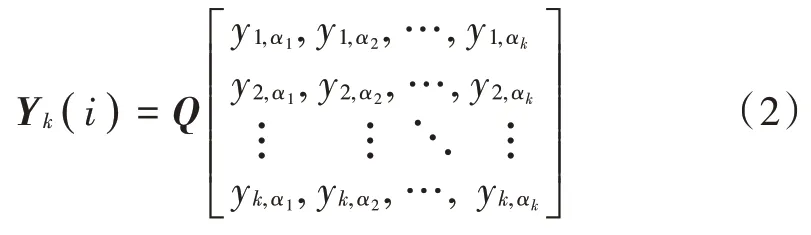
式中,i=1,2,…,n,n=max{Q}×max{α}。以某一点为原点,计算其与之间的距离,表示为:
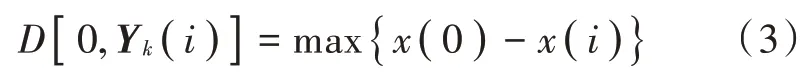
将每个i值的计算事件表示为Si,给定阈值ψ,若则事件Si发生的概率为:
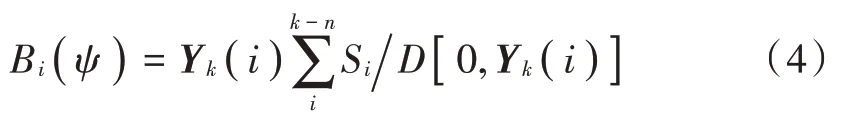
得出的事件Si发生的概率可以表示所有复合延迟数据矩阵与原点的关系,同时也可以表示多变量时间特征序列的变化规律。扩展上述i的取值为k+1,重复上述式(1)~式(4)的步骤,可以得到事件Si+1发生的概率由此则可计算得大数据特征集的并行处理结果,表示为:

式中,MME(Q,α,ψ,i)为并行样本数据特征集的熵值。
2 加密环境下批量Hash索引插入
对大数据特征集进行加密处理,将数据特征集进行分块处理,分块记为F,对每一分块进行加密,密钥M记为F的哈希值的低128位,则加密过程可以表示为:

在上述加密环境下,假定T为一次性批量插入的记录总数,K为分裂桶的阈值,b为通道容量,那么对于T条记录的插入应该增加的桶数目为:

根据当前待分裂桶的位置P0,有如下两种情况。
1)P0+BT<2N时:
①使用一个线程分裂第P0号桶到P0+BT-1号桶,其中,P0号桶的元素分裂到P0+i号桶和B+i号桶,i=0,1,2,…,BT-1;
②Pn=P0+BTmod2N;
③所有线程并行地将T条记录插入到Hash表的第0号桶到第B+BT-1号桶。
2)P0+BT≥2N时:
①使用Hash函数hN+1分裂P0到2N-1号桶,使用Hash函数hN+2分裂第0号到第BT-(2N-P0)-1号桶;
②Pn=P0+BTmod2N;
③所有线程并行地将T条记录插入到Hash表的第0号桶到第BT-(2N-P0)-1号桶。
在T个记录并行插入过程中,由磁盘缓冲区的锁保证插入相同的桶时不产生互斥问题。
3 大数据特征集并行存储
在批量Hash索引插入的基础上,对大数据特征集并行存储进行研究,给出了特征集并行存储流程如下:
实时对数据流端口进行监测,在接收到用户端存储申请时,对大数据特征集进行分类处理,基于Map 函数在空闲工作进程中对数据进行映射处理,判断映射处理是否完毕,若映射完毕,则可完成对大数据特征集的并行存储。
4 实验结果与分析
在Matlab 环境下设计仿真实验,验证本文方法的可行性和有效性。实验硬件环境采用Intel Pentium IV CPU 2.4 GHz,内存为32 GB;软件环境采用C/S 系统模式,Windows XP 操作系统。对大数据特征集采集过程中,每一个采集波门的数据设置为一帧数据,使用数据帧为单位进行存储。
选取实验分析指标为:存储通道一致性、存储速度、存储容量。
4.1 通道一致性
本文在对大数据特征集进行并行化MMSE 计算时,多通道数据分布是其中重要的步骤。在采样率为1.5 GSPS 和 500 MSPS 的情况下,计算 3 个随机数据通道之间的时间差值,如图1和图2所示。
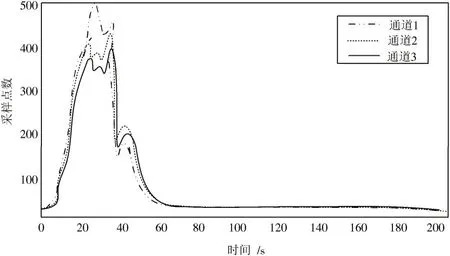
图1 1.5 GSPS 采样率下时域图Fig.1 Time domain wave diagram at sampling rate of 1.5 GSPS
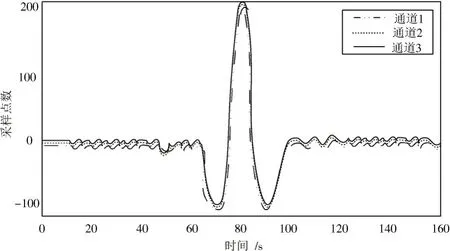
图2 500 MSPS 采样率下时域图Fig.2 Time domain wave diagram at sampling rate of 500 MSPS
分析图1、图2可以看出,在1.5 GSPS 采样率条件下,通道1、通道2 和通道3 均在20 s 时数据特征集达到第一个最大值点;而在500 MSPS 采样率条件下,通道1、通道2 和通道3 数据特征集的最大值点均为80 s。说明在不同的采样率条件下,使用本文方法进行采样,不同通道均会在同一采样时间下数据特征达到最大值,进一步表明了各通道之间的一致性,验证了本文研究方法的可行性。
4.2 存储速度对比
对本文方法与文献[6]方法的存储速度进行对比,结果如表1所示。分析表1可以看出,本文方法的最大存储速度为399 f/s,最小存储速度为299 f/s;而文献[6]方法的最大存储速度为341 f/s,最小存储速度为100 f/s。两种方法的数据存储速度具有明显的差距,证明了本文方法在数据存储速度方面具有优越性。
4.3 存储容量
为了进一步证明本文方法的实用性,对本文方法与文献[7]方法的存储容量进行对比,结果如图3所示。将存储容量划分为10 个级别,级别越高表明存储容量越大。

表1 存储速度对比Table 1 Comparison of storage speed of two methods
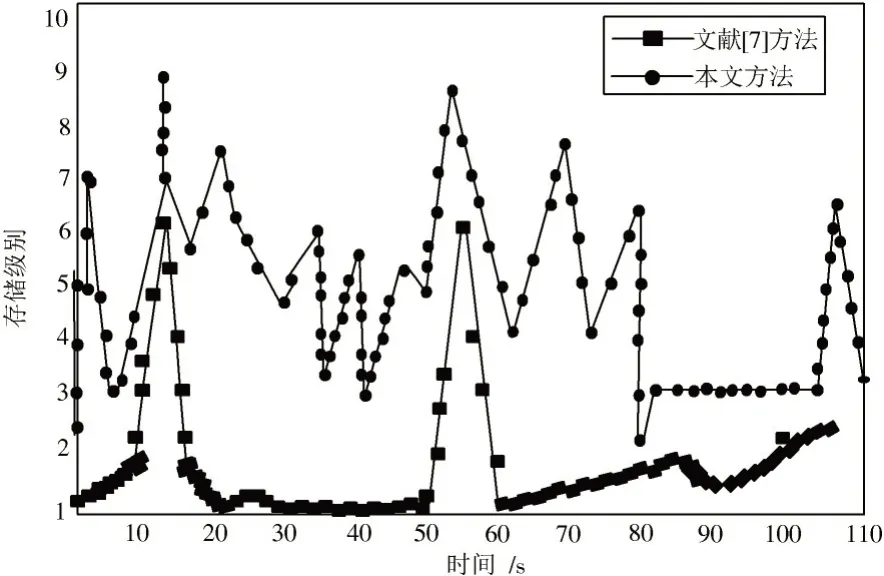
图3 存储容量对比Fig.3 Comparison of storage capacity of two methods
分析图3可以看出,本文方法的存储级别普遍高于文献[7]方法,在存储时间为20 s 时,两种方法的存储级别差距最大,本文方法的存储级别基本接近9,而文献[7]方法的存储级别约为2。由此可以看出,本文方法能够很好地完成大数据特征集的并行存储。
通过上述的实验对比分析可知,本文方法的通道一致性、存储速度以及存储容量的性能均优于其他的传统方法,说明本文方法具有较高的实际应用价值。
5 结 论
本文提出一种加密环境下大数据特征集并行存储方法,采用MMSE 算法对大数据特征集进行并行处理,在处理后的数据中插入批量Hash 索引,以此为基础,给出具体的大数据特征集并行存储流程图。实验结果表明,本文所提方法的数据通道的一致性较强,且存储速度快,容量大,表明本文方法具有较好的可行性。
